A Model-Driven Approach for Developing Families of Reinforcement Learning Environments
Pith reviewed 2026-06-26 16:11 UTC · model grok-4.3
The pith
A hybrid genetic algorithm generates families of reinforcement learning environments by treating mutations and constraints as model transformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
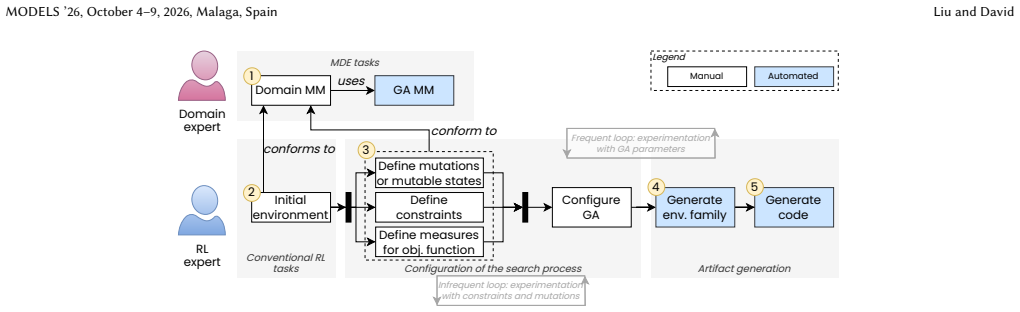
The paper claims that a hybrid genetic algorithm, which combines population-based global search with heuristic local search, can generate families of RL environments when mutations and constraints are expressed as model transformations and executed by a state-of-the-art model transformation engine, with soundness shown through application to wildfire mitigation and curriculum learning.
What carries the argument
The hybrid genetic algorithm that operationalizes mutations and constraints as model transformations executed by a model transformation engine.
If this is right
- Development of RL environment families shifts from labor-intensive manual work to an automated search process.
- Environment variants become available at scale for any RL problem that needs multiple similar but distinct training settings.
- Curriculum learning setups can be produced by generating sequences of environments with controlled increases in difficulty.
- The same transformation-based search applies to other domains that require families of simulation environments, such as wildfire mitigation training.
Where Pith is reading between the lines
- The approach could be combined with existing RL frameworks so that generated environments are directly usable for training runs.
- Model-based representation of environments might allow additional checks for safety or consistency before training begins.
- The method could be tested on other RL domains, such as robotics or game playing, to see whether the same transformation encoding works without redesign.
- Extending the search objective to include measured convergence speed or sample efficiency would produce environment families tuned for faster learning.
Load-bearing premise
That expressing mutations and constraints as model transformations is sufficient to produce environment families that support RL convergence without requiring substantial additional manual intervention or domain-specific tuning.
What would settle it
Running the generated environment families on the wildfire mitigation task and finding that RL agents fail to converge to meaningful behavior unless the environments or search process receive extra manual adjustments.
Figures




read the original abstract
Virtual training environments are software-intensive systems in which reinforcement learning (RL) agents learn, adapt, and demonstrate meaningful behavior. Virtual training environments offer a safe and cost-efficient alternative to training agents in real-world settings. However, to converge, most realistic RL problems require training in multiple, mostly similar but slightly different environments - i.e., families of environment variants. The typical development process of environment families is a labor-intensive and error-prone manual endeavor that does not scale well. To alleviate these issues, in this paper, we propose a model-driven approach for developing families of RL training environments. To obtain the family of environments, we develop an approach and prototype tool. In our approach, a hybrid genetic algorithm - a combination of population-based global search and heuristic local search - generates environment families. Mutations and constraints are expressed as model transformations and are operationalized into a search process by a state-of-the-art model transformation engine. We demonstrate the soundness of our approach in a wildfire mitigation scenario and curriculum learning - a particular learning paradigm that relies on environment families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a model-driven approach to generate families of RL training environments via a hybrid genetic algorithm that encodes mutations and constraints as model transformations executed by a model transformation engine. The approach is demonstrated for soundness on a wildfire mitigation scenario and on curriculum learning, with the claim that it reduces the labor-intensive manual development of environment variants.
Significance. If the generated families demonstrably support RL convergence with substantially lower manual effort than conventional methods, the work would address a practical bottleneck in RL engineering. The model-transformation framing and hybrid GA are technically coherent, but the significance hinges on evidence that the automation yields measurable gains in development effort or learning performance; without such evidence the contribution remains primarily methodological.
major comments (2)
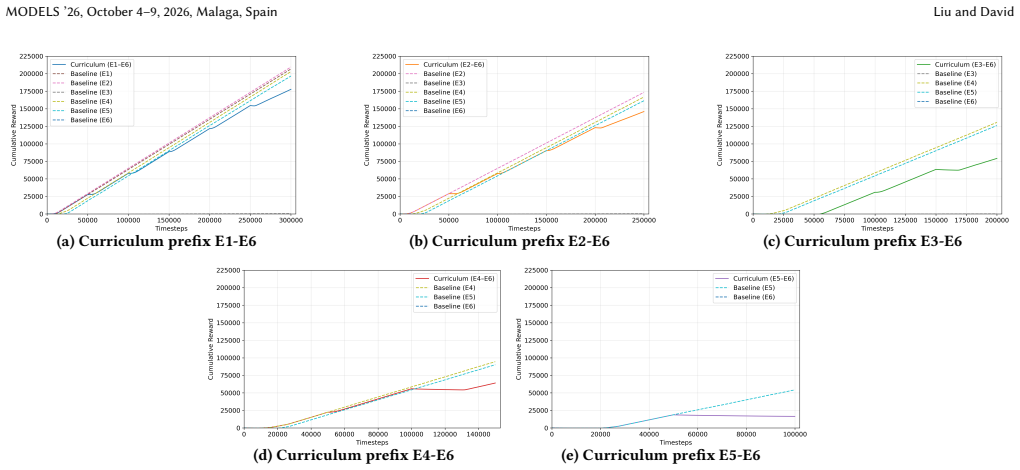
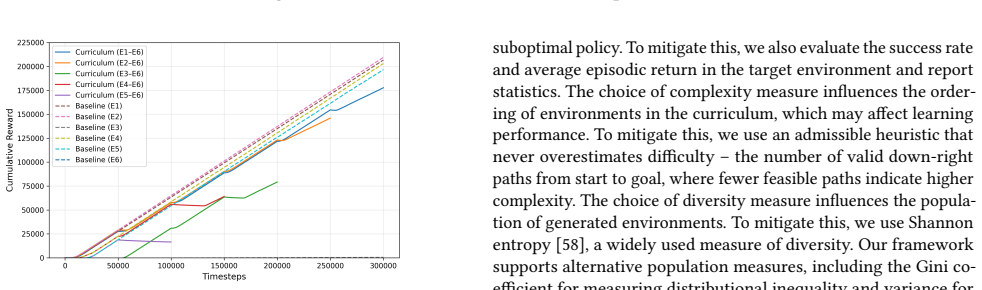
- [Evaluation] Evaluation section (wildfire mitigation and curriculum learning demonstrations): the paper shows that the hybrid GA produces environment families but reports no quantitative metrics comparing development effort (e.g., person-hours, number of hand-tuned parameters), RL convergence (success rate, sample efficiency, learning curves), or post-generation manual intervention against manually constructed baseline families. This absence directly undermines the central claim that the transformation-based approach alleviates labor-intensive manual development.
- [Approach] Approach description (hybrid GA and model-transformation operationalization): while mutations and constraints are expressed as model transformations, the manuscript does not specify how domain-specific RL convergence requirements (e.g., reward shaping, state-space coverage) are encoded or validated within the transformation rules, leaving open whether substantial expert knowledge is still required to define the initial metamodel and constraints.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'soundness' for the demonstrations; clarify whether this refers to syntactic validity of generated environments, semantic correctness for RL, or empirical convergence.
- Figure captions and pseudocode for the hybrid GA should explicitly label the population-based and local-search components to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the evaluation would benefit from quantitative comparisons and will revise the manuscript to include them. We also clarify the encoding of domain-specific requirements in the approach description.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (wildfire mitigation and curriculum learning demonstrations): the paper shows that the hybrid GA produces environment families but reports no quantitative metrics comparing development effort (e.g., person-hours, number of hand-tuned parameters), RL convergence (success rate, sample efficiency, learning curves), or post-generation manual intervention against manually constructed baseline families. This absence directly undermines the central claim that the transformation-based approach alleviates labor-intensive manual development.
Authors: We acknowledge that the demonstrations focus on soundness and feasibility without direct quantitative baselines. To strengthen the central claim, we will revise the evaluation section to report metrics on development effort (person-hours and hand-tuned parameters) and RL performance (success rates, sample efficiency, learning curves) against manually constructed families, along with any post-generation interventions required. revision: yes
-
Referee: [Approach] Approach description (hybrid GA and model-transformation operationalization): while mutations and constraints are expressed as model transformations, the manuscript does not specify how domain-specific RL convergence requirements (e.g., reward shaping, state-space coverage) are encoded or validated within the transformation rules, leaving open whether substantial expert knowledge is still required to define the initial metamodel and constraints.
Authors: Domain expertise is required to define the initial metamodel and constraints that capture RL requirements such as reward shaping and state-space coverage. Once established, the transformations and hybrid GA automate variant generation and validation. We will revise the approach section to explicitly detail how these RL-specific elements are encoded in the transformation rules and validated during search, clarifying the division between initial expert input and subsequent automation. revision: yes
Circularity Check
No circularity; methodological proposal with external demonstration
full rationale
The paper presents a model-driven engineering method using a hybrid genetic algorithm operationalized via model transformations to generate families of RL environments. It demonstrates the prototype on wildfire mitigation and curriculum learning scenarios. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or self-citation chains appear in the provided text. The central claim rests on the soundness of the prototype tool and empirical demonstration rather than any self-referential reduction of outputs to inputs by construction. This is a standard non-circular software engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hani Abdeen, Dániel Varró, Houari Sahraoui, András Szabolcs Nagy, Csaba Debreceni, Ábel Hegedüs, and Ákos Horváth. 2014. Multi-objective optimization in rule-based design space exploration. InProceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering (ASE ’14). ACM, 289–300. doi:10.1145/2642937.2643005
-
[2]
OpenAI: Marcin Andrychowicz et al . 2020. Learning dexterous in-hand ma- nipulation.The International Journal of Robotics Research39, 1 (2020), 3–20. doi:10.1177/0278364919887447
-
[3]
Angela Barriga, Rogardt Heldal, Adrian Rutle, and Ludovico Iovino. 2022. PAR- MOREL: a framework for customizable model repair.Soft. Sys. Mod.21, 5 (2022), 1739–1762
2022
-
[4]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning (ICML ’09). ACM, 41–48. doi:10.1145/1553374.1553380
-
[5]
Gábor Bergmann, Istvan David, Ábel Hegedüs, Ákos Horváth, István Ráth, Zoltán Ujhelyi, and Dániel Varró. 2015. VIATRA 3: A Reactive Model Transformation Platform. InTheory and Practice of Model Transformations - 8th International Conference, ICMTSTAF 2015, L’Aquila, Italy, July 20-21, 2015. Proceedings (LNCS, Vol. 9152). Springer, 101–110. doi:10.1007/978...
-
[6]
Dimitris Bertsimas and John Tsitsiklis. 1993. Simulated Annealing.Statist. Sci.8, 1 (1993), 10 – 15. doi:10.1214/ss/1177011077
-
[7]
Alexandru Burdusel, Steffen Zschaler, and Stefan John. 2021. Automatic genera- tion of atomic multiplicity-preserving search operators for search-based model engineering.Soft. Sys. Mod.20, 6 (2021), 1857–1887
2021
-
[8]
Thomas Chaffre, Julien Moras, Adrien Chan-Hon-Tong, and Julien Marzat. 2020. Sim-to-Real Transfer with Incremental Environment Complexity for Reinforce- ment Learning of Depth-Based Robot Navigation. InProceedings of the 17th International Conference on Informatics, Automation and Robotics, ICINCO 2020. 314–323. https://ensta.hal.science/hal-02958155
2020
-
[9]
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. 2020. Leveraging Procedural Generation to Benchmark Reinforcement Learning. InProc of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119). PMLR, 2048–2056
2020
-
[10]
2011.Measuring Inequality(3 ed.)
Frank Cowell. 2011.Measuring Inequality(3 ed.). Oxford University Press, London, England
2011
-
[11]
Kyanna Dagenais and Istvan David. 2025. Complex Model Transformations by Reinforcement Learning with Uncertain Human Guidance. In2025 ACM/IEEE 28th International Conference on Model Driven Engineering Languages and Systems (MODELS). doi:10.1109/MODELS67397.2025.00025
-
[12]
Istvan David and Eugene Syriani. 2022. DEVS Model Construction as a Rein- forcement Learning Problem. In2022 Annual Modeling and Simulation Conference (ANNSIM). IEEE, 30–41. doi:10.23919/ANNSIM55834.2022.9859369
-
[13]
2024.Automated Inference of Simulators in Digital Twins
Istvan David and Eugene Syriani. 2024.Automated Inference of Simulators in Digital Twins. CRC Press, Chapter 8, 122–148. doi:10.1201/9781003425724-11
-
[14]
Michael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Rus- sell, Andrew Critch, and Sergey Levine. 2020. Emergent Complexity and Zero- shot Transfer via Unsupervised Environment Design. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., 13049–13061
2020
-
[15]
2015.Introduction to evolutionary computing
Agoston E Eiben and James E Smith. 2015.Introduction to evolutionary computing. Springer
2015
-
[16]
Martin Eisenberg, Hans-Peter Pichler, Antonio Garmendia, and Manuel Wimmer
-
[17]
In2021 ACM/IEEE 24th Intl Conf
Towards Reinforcement Learning for In-Place Model Transformations. In2021 ACM/IEEE 24th Intl Conf. on Model Driven Engineering Languages and Systems (MODELS). 82–88
-
[18]
Tarek A El-Mihoub, Adrian A Hopgood, Lars Nolle, and Alan Battersby. [n. d.]. Hybrid Genetic Algorithms: A Review. ([n. d.])
-
[19]
Maged Elaasar, Nicolas Rouquette, David Wagner, Bentley James Oakes, Abdel- wahab Hamou-Lhadj, and Mohammad Hamdaqa. 2023. openCAESAR: Balancing Agility and Rigor in Model-Based Systems Engineering. In2023 ACM/IEEE Interna- tional Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C). 221–230. doi:10.1109/MODELS-C59198.2023.00051
-
[20]
Rafael Figueiredo Prudencio, Marcos R. O. A. Maximo, and Esther Luna Colombini
-
[21]
doi:10.1109/TNNLS.2023.3250269
A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems.IEEE Trans Neural Netw Learn Syst35, 8 (2024), 10237–10257. doi:10.1109/TNNLS.2023.3250269
-
[22]
Carlos Florensa, David Held, Markus Wulfmeier, Michael Zhang, and Pieter Abbeel. 2017. Reverse Curriculum Generation for Reinforcement Learning. In Proceedings of the 1st Annual Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 78). PMLR, 482–495
2017
-
[23]
Nicola Gatto, Evgeny Kusmenko, and Bernhard Rumpe. 2019. Modeling Deep Reinforcement Learning Based Architectures for Cyber-Physical Systems. In2019 ACM/IEEE 22nd International Conference on Model Driven Engineering Languages and Systems Companion. 196–202. doi:10.1109/MODELS-C.2019.00033
-
[24]
Timothy Hospedales et al. 2022. Meta-Learning in Neural Networks: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence44, 9 (2022), 5149–
2022
-
[25]
doi:10.1109/TPAMI.2021.3079209
-
[26]
Mengkang Hu et al. 2025. AgentGen: Enhancing Planning Abilities for Large Lan- guage Model based Agent via Environment and Task Generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (KDD ’25). ACM, 496–507. doi:10.1145/3690624.3709321
-
[27]
Xuemin Hu, Shen Li, Tingyu Huang, Bo Tang, Rouxing Huai, and Long Chen
-
[28]
How Simulation Helps Autonomous Driving: A Survey of Sim2real, Digital Twins, and Parallel Intelligence.IEEE Transactions on Intelligent Vehicles9, 1 (2024), 593–612. doi:10.1109/TIV.2023.3312777
-
[29]
Stefan John, Alexandru Burdusel, Robert Bill, Daniel Struber, Gabriele Taentzer, Steffen Zschaler, and Manuel Wimmer. 2019. Searching for optimal models: Comparing two encoding approaches. In12th International Conference on Model Transformations ICMT 2019. 1–22
2019
-
[30]
Stefan John, Jens Kosiol, Leen Lambers, and Gabriele Taentzer. 2023. A graph- based framework for model-driven optimization facilitating impact analysis of mutation operator properties.Soft. Sys. Mod.22, 4 (2023), 1281–1318
2023
-
[31]
Lawrence Johnson, Georgios N Yannakakis, and Julian Togelius. 2010. Cellular automata for real-time generation of infinite cave levels. InProceedings of the 2010 Workshop on Procedural Content Generation in Games. 1–4
2010
-
[32]
Joerg Kienzle et al . 2023. Global Decision Making Over Deep Variability in Feedback-Driven Software Development. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE ’22). ACM, Article 178, 6 pages. doi:10.1145/3551349.3559551
-
[33]
Taewoo Kim, Minsu Jang, and Jaehong Kim. 2021. A survey on simulation environments for reinforcement learning. In2021 18th International Conference on Ubiquitous Robots (UR). IEEE, 63–67
2021
-
[34]
Thomas Kühne, Gergely Mezei, Eugene Syriani, Hans Vangheluwe, and Manuel Wimmer. 2010. Explicit Transformation Modeling. InModels in Software Engi- neering. Springer, 240–255
2010
-
[35]
Evgeny Kusmenko et al . 2022. A Model-Driven Generative Self Play-Based Toolchain for Developing Games and Players. InProceedings of the 21st ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences (GPCE 2022). ACM, 95–107. doi:10.1145/3564719.3568687
-
[36]
Marta Kwiatkowska and Xiyue Zhang. 2023. When to Trust AI: Advances and Challenges for Certification of Neural Networks. In2023 18th Conference on Com- puter Science and Intelligence Systems (FedCSIS). 25–37. doi:10.15439/2023F2324
-
[37]
Hartmut Lackner and Bernd-Holger Schlingloff. 2017. Chapter Four - Advances in Testing Software Product Lines. Advances in Computers, Vol. 107. Elsevier, 157–217. doi:10.1016/bs.adcom.2017.07.001
-
[38]
José Lameh, Alexandra Dubray, and Marija Jankovic. 2025. Modeling variability in product line engineering (PLE) for systems engineering (SE).Proceedings of the Design Society5 (2025), 2491–2500. doi:10.1017/pds.2025.10263
-
[39]
William Liang, Sam Wang, Hung-Ju Wang, Osbert Bastani, Dinesh Jayaraman, and Yecheng Jason Ma. 2024. Eurekaverse: Environment curriculum generation via large language models.arXiv preprint arXiv:2411.01775(2024)
arXiv 2024
-
[40]
Khan, John Mylopoulos, and Reza Golipour
Sotirios Liaskos, Shakil M. Khan, John Mylopoulos, and Reza Golipour. 2025. Model-Driven Design and Generation of Training Simulators for Reinforcement Learning. InConceptual Modeling. Springer, 170–191
2025
-
[41]
Jiashuo Liu, Zheyan Shen, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. 2023. Towards Out-Of-Distribution Generalization: A Survey. arXiv:2108.13624 [cs.LG] https://arxiv.org/abs/2108.13624
arXiv 2023
-
[42]
Xiaoran Liu and Istvan David. 2025. AI Simulation by Digital Twins: Systematic Survey, Reference Framework, and Mapping to a Standardized Architecture. Software and Systems Modeling(2025). doi:10.1007/s10270-025-01306-0
-
[43]
Xiaoran Liu and Istvan David. 2026. A Reference Architecture of Reinforcement Learning Frameworks. In2026 IEEE 23rd International Conference on Software Architecture (ICSA). doi:10.1109/ICSA66085.2026.00016
-
[44]
Viktor Makoviychuk et al . 2021. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning. doi:10.48550/arXiv.2108.10470
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.10470 2021
-
[45]
Dhruv Malik, Yuanzhi Li, and Pradeep Ravikumar. 2021. When Is Generalizable Reinforcement Learning Tractable?. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., 8032–8045
2021
-
[46]
Tambet Matiisen, Avital Oliver, Taco Cohen, and John Schulman. 2019. Teacher– student curriculum learning.IEEE transactions on neural networks and learning systems31, 9 (2019), 3732–3740
2019
-
[47]
Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro
Reginald McLean, Evangelos Chatzaroulas, Luc McCutcheon, Frank Röder, Tianhe Yu, Zhanpeng He, K.R. Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro. 2025. Meta-World+: An Improved, Standardized, RL Benchmark. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[48]
Marjan Mernik, Jan Heering, and Anthony M. Sloane. 2005. When and how to develop domain-specific languages.ACM Comput. Surv.37, 4 (Dec. 2005), 316–344. doi:10.1145/1118890.1118892
-
[49]
Tim Molderez, Bjarno Oeyen, Coen De Roover, and Wolfgang De Meuter. 2019. Marlon: A domain-specific language for multi-agent reinforcement learning on networks. InProc of the 34th ACM/SIGAPP Symposium on Applied Computing. ACM, 1322–1329. doi:10.1145/3297280.3297413
-
[50]
Pablo Moscato et al. [n. d.]. On evolution, search, optimization, genetic algorithms and martial arts: Towards memetic algorithms. ([n. d.]). MODELS ’26, October 4–9, 2026, Malaga, Spain Liu and David
2026
-
[51]
Dirk Muthig and Colin Atkinson. 2002. Model-Driven Product Line Architectures. InSoftware Product Lines. Springer, 110–129
2002
-
[52]
Taylor, and Peter Stone
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E. Taylor, and Peter Stone. 2020. Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey.J Machine Learning Research21, 181 (2020), 1–50
2020
-
[53]
Sanmit Narvekar, Jivko Sinapov, Matteo Leonetti, and Peter Stone. 2016. Source task creation for curriculum learning. InProceedings of the 2016 international conference on autonomous agents & multiagent systems. 566–574
2016
-
[54]
Hira Naveed, Chetan Arora, Hourieh Khalajzadeh, John Grundy, and Omar Haggag. 2024. Model driven engineering for machine learning components: A systematic literature review.Inf Softw Technol169 (2024), 107423
2024
-
[55]
Evangelos Ntentos, Stephen John Warnett, and Uwe Zdun. 2024. Supporting architectural decision making on training strategies in reinforcement learning architectures. In21st Intl Conf on Software Architecture (ICSA). IEEE, 90–100
2024
-
[56]
Maria Joao Varanda Pereira, Joao Fonseca, and Pedro Rangel Henriques. 2016. Ontological approach for DSL development.Computer Languages, Systems & Structures45 (2016), 35–52
2016
-
[57]
Andrei Pitkevich and Ilya Makarov. 2024. A Survey on Sim-to-Real Transfer Methods for Robotic Manipulation. InIEEE Intl Symposium on Intelligent Systems and Informatics (SISY). 000259–000266. doi:10.1109/SISY62279.2024.10737545
-
[58]
Martin L Puterman. 1990. Markov decision processes.Handbooks in operations research and management science2 (1990), 331–434
1990
-
[59]
2022.Simulation
Sheldon M Ross. 2022.Simulation. academic press
2022
-
[60]
Oszkár Semeráth, Aren A Babikian, Boqi Chen, Chuning Li, Kristóf Marussy, Gábor Szárnyas, and Dániel Varró. 2021. Automated generation of consistent, diverse and structurally realistic graph models.Soft. Sys. Mod.20, 5 (2021), 1713–1734. doi:10.1007/s10270-021-00884-z
-
[61]
Oszkár Semeráth, Rebeka Farkas, Gábor Bergmann, and Dániel Varró. 2020. Diversity of graph models and graph generators in mutation testing.Int J Softw Tools Technol Transf22, 1 (2020), 57–78. doi:10.1007/s10009-019-00530-6
-
[62]
C. E. Shannon. 1948. A mathematical theory of communication.The Bell System Technical Journal27, 3 (1948), 379–423. doi:10.1002/j.1538-7305.1948.tb01338.x
-
[63]
Ronald W. Shephard and Rolf Färe. 1974. The Law of Diminishing Returns. In Production Theory. Springer, 287–318. doi:10.1007/978-3-642-80864-7_17
-
[64]
Daniele F Silva, Rafael P Torchelsen, and Marilton S Aguiar. 2025. Procedural game level generation with GANs: potential, weaknesses, and unresolved challenges in the literature.Multimedia Tools and Applications(2025), 1–27
2025
-
[65]
Natalie Sinani et al. 2024. Towards a Domain-Specific Modelling Environment for Reinforcement Learning.arXiv preprint arXiv:2410.09368(2024)
arXiv 2024
-
[66]
Shagun Sodhani, Amy Zhang, and Joelle Pineau. 2021. Multi-task reinforce- ment learning with context-based representations. InInternational conference on machine learning. PMLR, 9767–9779
2021
-
[67]
Petru Soviany et al. 2022. Curriculum Learning: A Survey.International Journal of Computer Vision130, 6 (2022), 1526–1565. doi:10.1007/s11263-022-01611-x
-
[68]
1998.Reinforcement learning: An intro- duction
Richard S Sutton and Andrew G Barto. 1998.Reinforcement learning: An intro- duction. MIT press Cambridge
1998
-
[69]
Jordan Terry et al. 2021. PettingZoo: Gym for Multi-Agent Reinforcement Learn- ing. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Asso- ciates, Inc., 15032–15043
2021
-
[70]
2011.Graphs: theory and algorithms
Krishnaiyan Thulasiraman and Madisetti NS Swamy. 2011.Graphs: theory and algorithms. John Wiley & Sons
2011
-
[71]
Massimo Tisi, Frédéric Jouault, Piero Fraternali, Stefano Ceri, and Jean Bézivin
-
[72]
On the Use of Higher-Order Model Transformations. InProceedings of the 5th European Conference on Model Driven Architecture - Foundations and Applications (ECMDA-FA ’09). Springer, 18–33. doi:10.1007/978-3-642-02674-4_3
-
[73]
Cover and Joy A Thomas
T.M. Cover and Joy A Thomas. 1991.Elements of Information Theory(99 ed.). John Wiley & Sons, Nashville, TN
1991
-
[74]
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. 2017. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 23–30
2017
-
[75]
Julian Togelius, Alex J Champandard, Pier Luca Lanzi, Michael Mateas, Ana Paiva, Mike Preuss, and Kenneth O Stanley. 2013. Procedural content generation: Goals, challenges and actionable steps
2013
-
[76]
Mark Towers et al. 2025. Gymnasium: A Standard Interface for Reinforcement Learning Environments. doi:10.48550/arXiv.2407.17032
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.17032 2025
-
[77]
Y.R. Tsoy. 2003. The influence of population size and search time limit on genetic algorithm. In7th Korea-Russia International Symposium on Science and Technology, Proceedings KORUS 2003. (IEEE Cat. No.03EX737), Vol. 3. 181–187 vol.3
2003
-
[78]
Dejin Wang and Seyede Fatemeh Ghoreishi. 2025. RGDR: Reward-Guided Do- main Randomization for Autonomous Driving. In2025 IEEE 28th International Conference on Intelligent Transportation Systems (ITSC 2025), IEEE
2025
-
[79]
Xin Wang et al. 2022. A Survey on Curriculum Learning.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 9 (2022), 4555–4576. doi:10.1109/ TPAMI.2021.3069908
arXiv 2022
-
[80]
Christopher JCH Watkins and Peter Dayan. 1992. Q-learning.Machine learning 8, 3 (1992), 279–292
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.