Critical Percolation as a Synthetic Data Model for Interpretability
Pith reviewed 2026-06-26 17:39 UTC · model grok-4.3
The pith
Critical percolation clusters with taxonomic latents produce synthetic data whose ground-truth hierarchy is linearly decodable from neural network activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
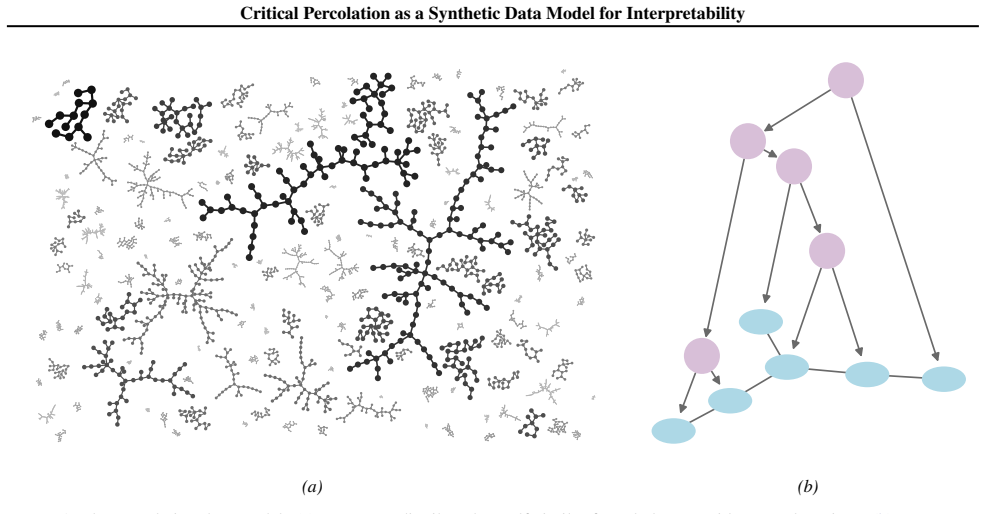
By placing critical percolation clusters in high-dimensional space and generating labels from a taxonomic hierarchy of latent variables, the resulting data exhibits sparsity, self-similarity, and power-law statistics while remaining analytically tractable; linear probes recover the ground-truth latents from network activations.
What carries the argument
The mapping from percolation clusters to random trees via additive coalescence that jointly samples the tree and its hierarchical latent decomposition in almost linear time.
If this is right
- The dataset supplies a scalable testbed with known ground truth for evaluating interpretability methods.
- Because critical exponents fix all statistical properties, experiments can be reproduced without hidden tuning.
- The same generative process can be used to create data at any desired scale while preserving the hierarchy.
- Sparsity and fractal geometry allow direct study of how networks handle multi-scale features.
Where Pith is reading between the lines
- The linear decodability result suggests that future work could test whether other interpretability techniques, such as feature visualization, also align with the known hierarchy.
- The tree-coalescence construction may connect this model to generative processes used in other areas of network science.
- If the power-law statistics prove essential, the same percolation backbone could be reused with different label hierarchies to isolate the role of each property.
Load-bearing premise
The multi-scale hierarchical structure produced by critical percolation is close enough to natural data that interpretability conclusions transfer.
What would settle it
A linear probing experiment on networks trained on this data that recovers the latent variables at no better than chance accuracy would falsify the decodability claim.
Figures

read the original abstract
Neural networks learn features that reflect the hierarchical, multi-scale structure of natural data. Synthetic datasets used to evaluate interpretability methods typically lack this structure, limiting their value as realistic toy models. To close this gap, we introduce a family of synthetic datasets consisting of hierarchical functions defined on critical mean-field percolation clusters embedded in a high-dimensional data space. The percolation data consists of sparse, low-dimensional fractal clusters with a power-law size distribution. Latent variables modeling a taxonomic hierarchy generate each data point's target value. The data model is analytically tractable with known critical exponents that fix its properties without requiring hyperparameter tuning. We leverage a mapping between percolation clusters, random trees, and additive coalescence to propose an almost linear-time algorithm to jointly sample a random tree and its hierarchical latent decomposition, enabling data generation at arbitrary scale. Using probing experiments, we find that the model's ground-truth latent variables can be linearly decoded from neural network activations. Together, sparsity, self-similarity, power-law statistics, and analytical tractability make critical percolation a principled testbed for interpretability research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a family of synthetic datasets generated from hierarchical latent variables defined on critical mean-field percolation clusters embedded in high-dimensional space. These clusters exhibit sparsity, self-similarity, and power-law size distributions fixed by known critical exponents, eliminating the need for hyperparameter tuning. A sampling algorithm is derived from mappings between percolation clusters, random trees, and additive coalescence, enabling near-linear-time generation at scale. Probing experiments are reported to show that the ground-truth taxonomic latent variables are linearly decodable from neural network activations, positioning the model as a tractable testbed for interpretability research.
Significance. If the linear decodability result is robust, the model supplies a scalable, analytically tractable synthetic data source whose multi-scale hierarchical structure is fixed by external percolation theory rather than fitted parameters. The efficient sampling procedure and explicit use of critical exponents constitute concrete strengths that could support reproducible, large-scale interpretability experiments.
major comments (2)
- [Probing experiments section] Probing experiments section: the central claim that ground-truth latent variables are linearly decodable from network activations is load-bearing for the utility as an interpretability testbed, yet the manuscript provides no details on network architecture (depth/width), training objective, probe training protocol (held-out sets, regularization), baseline comparisons, or controls for confounders arising from the data-generation procedure itself.
- [Data model section] Data model section: the claim that the constructed hierarchical structure is sufficiently similar to natural data for interpretability conclusions to transfer rests on the overlay of taxonomic latents onto percolation clusters, but no quantitative comparison (e.g., matching of multi-scale correlation functions or power-law exponents against real datasets) is supplied to support transferability.
minor comments (2)
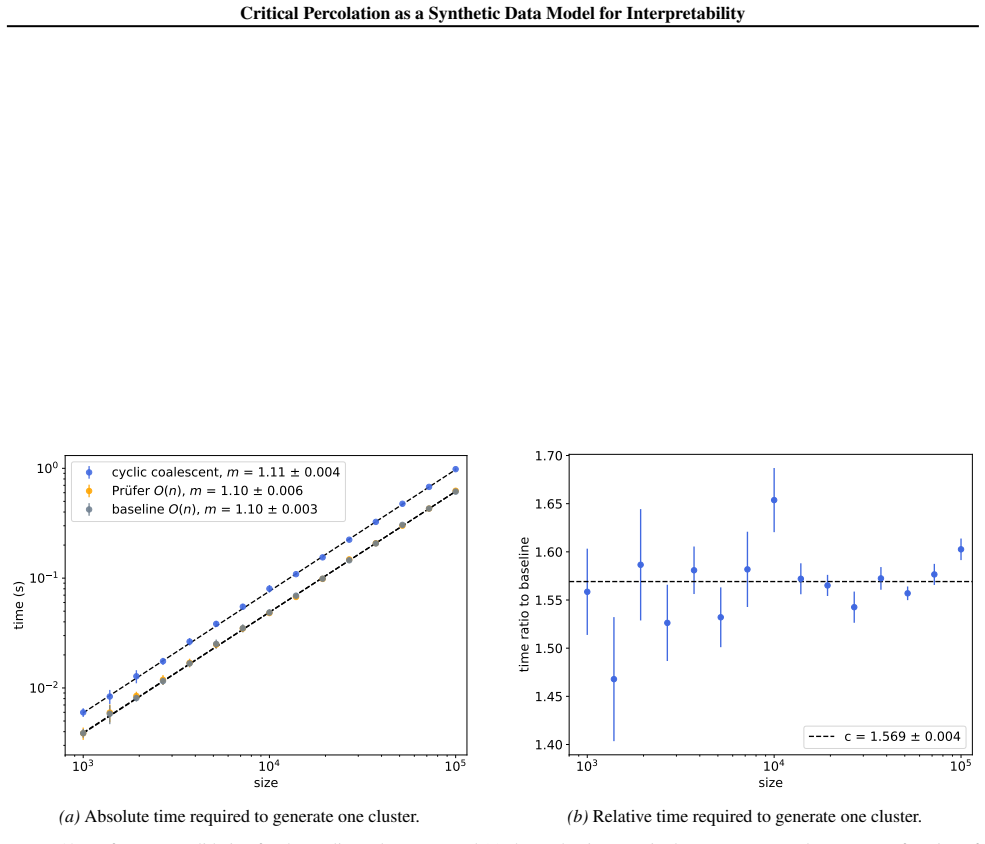
- [Abstract] The abstract states the algorithm is 'almost linear-time' without providing the precise complexity bound or empirical scaling measurements.
- [Algorithm description] Notation for the hierarchical latent decomposition and the coalescence mapping could be introduced with an explicit diagram or pseudocode to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below, agreeing where additional details or clarifications are warranted and outlining specific revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Probing experiments section] Probing experiments section: the central claim that ground-truth latent variables are linearly decodable from network activations is load-bearing for the utility as an interpretability testbed, yet the manuscript provides no details on network architecture (depth/width), training objective, probe training protocol (held-out sets, regularization), baseline comparisons, or controls for confounders arising from the data-generation procedure itself.
Authors: We agree that these experimental details are necessary for reproducibility and to substantiate the central claim. The revised manuscript will expand the probing experiments section to specify the network architecture (depth and width), training objective, probe training protocol (including held-out sets and regularization), baseline comparisons, and controls for any confounders from the data-generation procedure. revision: yes
-
Referee: [Data model section] Data model section: the claim that the constructed hierarchical structure is sufficiently similar to natural data for interpretability conclusions to transfer rests on the overlay of taxonomic latents onto percolation clusters, but no quantitative comparison (e.g., matching of multi-scale correlation functions or power-law exponents against real datasets) is supplied to support transferability.
Authors: The manuscript positions the model primarily as an analytically tractable testbed whose hierarchical structure is fixed by known critical exponents rather than as a direct proxy for natural data whose conclusions transfer via similarity. We do not make a strong claim of transferability based on quantitative matching. That said, we will add a brief discussion or appendix noting relevant power-law statistics from percolation theory and any available comparisons to real datasets to clarify the model's intended scope and limitations. revision: partial
Circularity Check
No significant circularity; derivation draws on external percolation theory
full rationale
The paper constructs a synthetic data model by embedding critical mean-field percolation clusters (with known external critical exponents) into high-dimensional space and overlaying a taxonomic latent hierarchy. The sampling algorithm is derived from a mapping to random trees and additive coalescence, presented as a new contribution rather than a reduction of fitted quantities. Linear decodability is reported from probing experiments, not from any closed-form derivation or self-referential fit. No equations or claims reduce by construction to the paper's own inputs; critical exponents and percolation properties are cited as independent, analytically fixed facts from established theory. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Critical mean-field percolation clusters possess known critical exponents that determine sparsity, fractality, and power-law size distribution without hyperparameter tuning.
invented entities (1)
-
Hierarchical latent variables defined on percolation clusters
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alabdulmohsin, I. and Steiner, A. A tale of two struc- tures: Do llms capture the fractal complexity of language? arXiv preprint arXiv:2502.14924,
-
[2]
Understanding intermediate layers using linear classifier probes
Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The continuum random tree
Aldous, D. The continuum random tree. i.The annals of probability, pp. 1–28, 1991a. Aldous, D. The continuum random tree. ii. an overview. Stochastic analysis (Durham, 1990), 167:23–70, 1991b. Aldous, D. The continuum random tree iii.The annals of probability, pp. 248–289,
1990
-
[4]
Allen-Zhu, Z. and Li, Y . Physics of language models: Part 1, learning hierarchical language structures.arXiv preprint arXiv:2305.13673, 2023a. Allen-Zhu, Z. and Li, Y . Physics of language models: Part 3.1, knowledge storage and extraction.arXiv preprint arXiv:2309.14316, 2023b. Atanasov, A., Zavatone-Veth, J. A., and Pehlevan, C. Scal- ing and renormali...
-
[5]
Mechanistic Interpretability for AI Safety -- A Review
Bereska, L. and Gavves, E. Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A., Dłotko, P., Harvey, J., Malinowski, J., and Yim, K
Binnie, J. A., Dłotko, P., Harvey, J., Malinowski, J., and Yim, K. M. A survey of dimension estimation methods. arXiv preprint arXiv:2507.13887,
-
[7]
An Expectation-Maximization Algorithm for the Fractal Inverse Problem
Bloem, P. and de Rooij, S. An expectation-maximization algorithm for the fractal inverse problem.arXiv preprint arXiv:1706.03149,
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
A model for scaling laws of general intelligence
Brill, A. A model for scaling laws of general intelligence. InILIAD 2: ODYSSEY, 2025a. Brill, A. Representation learning on a random lattice.arXiv preprint arXiv:2504.20197, 2025b. Brinkmann, J., Sheshadri, A., Levoso, V ., Swoboda, P., and Bartelt, C. A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task. InFindings of t...
-
[10]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
1901
-
[11]
Bussmann, B., Nabeshima, N., Karvonen, A., and Nanda, N. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
-
[12]
Cagnetta, F., Kang, H., and Wyart, M. Learning curves the- ory for hierarchically compositional data with power-law distributed features.arXiv preprint arXiv:2505.07067,
-
[13]
Cagnetta, F., Ravent´os, A., Ganguli, S., and Wyart, M. De- riving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488,
-
[14]
Chanin, D. and Garriga-Alonso, A. Synthsaebench: Evalu- ating sparse autoencoders on scalable realistic synthetic data.arXiv preprint arXiv:2602.14687,
-
[15]
Chanin, D., Wilken-Smith, J., Dulka, T., Bhatnagar, H., Golechha, S., and Bloom, J. A is for absorption: Studying feature splitting and absorption in sparse autoencoders. arXiv preprint arXiv:2409.14507,
-
[16]
Costa, V ., Fel, T., Lubana, E. S., Tolooshams, B., and Ba, D. From flat to hierarchical: Extracting sparse representations with matching pursuit.arXiv preprint arXiv:2506.03093,
-
[17]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly inter- pretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Dropout Neural Network Training Viewed from a Percolation Perspective
Devlin, F. and Sanders, J. Dropout neural network training viewed from a percolation perspective.arXiv preprint arXiv:2512.13853,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., et al. Toy models of superposition.arXiv preprint arXiv:2209.10652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Font-Clos, F. and Moloney, N. R. Percolation on trees as a brownian excursion: From gaussian to kolmogorov- smirnov to exponential statistics.arXiv preprint arXiv:1606.03764,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Scaling and evaluating sparse autoencoders
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., and Wu, J. Scal- ing and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2408.15138 , year=
Garnier-Brun, J., M ´ezard, M., Moscato, E., and Saglietti, L. How transformers learn structured data: insights from hierarchical filtering.arXiv preprint arXiv:2408.15138,
-
[23]
Greenspan, L., Berman, D., Brill, A., Jefferson, R., Kolchin- sky, A., Lin, J., Mack, A., Maiti, A., Rosas, F. E., Staple- ton, A., et al. Towards worst-case guarantees with scale- aware interpretability.arXiv preprint arXiv:2602.05184,
-
[24]
arXiv preprint arXiv:2305.01610 , year=
Gurnee, W., Nanda, N., Pauly, M., Harvey, K., Troit- skii, D., and Bertsimas, D. Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610,
-
[25]
Scaling Laws for Autoregressive Generative Modeling
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T. B., Dhariwal, P., Gray, S., et al. Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M. M. A., Yang, Y ., and Zhou, Y . Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Training Compute-Optimal Large Language Models
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
Hutter, M. Learning curve theory.arXiv preprint arXiv:2102.04074,
-
[29]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[30]
Sparse autoencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878, 2025
Leask, P., Bussmann, B., Pearce, M., Bloom, J., Tigges, C., Moubayed, N. A., Sharkey, L., and Nanda, N. Sparse au- toencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878,
-
[31]
arXiv preprint arXiv:2502.05475 , year=
Lehalleur, S. P., Hoogland, J., Farrugia-Roberts, M., Wei, S., Oldenziel, A. G., Wang, G., Carroll, L., and Murfet, D. You are what you eat–ai alignment requires understand- ing how data shapes structure and generalisation.arXiv preprint arXiv:2502.05475,
-
[32]
arXiv preprint arXiv:2210.10749 , year=
Liu, B., Ash, J. T., Goel, S., Krishnamurthy, A., and Zhang, C. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
-
[33]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Lubana, E. S., Kawaguchi, K., Dick, R. P., and Tanaka, H. A percolation model of emergence: Analyzing trans- formers trained on a formal language.arXiv preprint arXiv:2408.12578,
-
[35]
A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
Maloney, A., Roberts, D. A., and Sully, J. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859,
-
[36]
Menon, A., Shrivastava, M., Krueger, D., and Lubana, E. S. Analyzing (in) abilities of saes via formal languages. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 4837–4862,
2025
-
[37]
J., Gorton, L., and McGrath, T
Michaud, E. J., Gorton, L., and McGrath, T. Understanding sparse autoencoder scaling in the presence of feature manifolds.arXiv preprint arXiv:2509.02565,
-
[38]
Progress measures for grokking via mechanistic interpretability
Nanda, N., Chan, L., Lieberum, T., Smith, J., and Stein- hardt, J. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Pan, Z., Wang, S., and Li, J. Understanding llm behaviors via compression: Data generation, knowledge acquisition and scaling laws.arXiv preprint arXiv:2504.09597,
-
[40]
Sclocchi, A., Favero, A., and Wyart, M
doi: 10.1017/9781009305129. Sclocchi, A., Favero, A., and Wyart, M. A phase transition in diffusion models reveals the hierarchical nature of data. Proceedings of the National Academy of Sciences, 122 (1):e2408799121,
-
[41]
There Will Be a Scientific Theory of Deep Learning
Simon, J., Kunin, D., Atanasov, A., Boix-Adser`a, E., Borde- lon, B., Cohen, J., Ghosh, N., Guth, F., Jacot, A., Kamb, M., et al. There will be a scientific theory of deep learning. arXiv preprint arXiv:2604.21691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Asymptotic learning curves of kernel methods: empirical data versus teacher– student paradigm.Journal of Statistical Mechanics: The- ory and Experiment, 2020(12):124001,
Spigler, S., Geiger, M., and Wyart, M. Asymptotic learning curves of kernel methods: empirical data versus teacher– student paradigm.Journal of Statistical Mechanics: The- ory and Experiment, 2020(12):124001,
2020
-
[43]
Wang, X., Wang, L., Wu, Y ., et al
URL https: //transformer-circuits.pub/2024/ scaling-monosemanticity/index.html. Wang, X., Wang, L., Wu, Y ., et al. An optimal algorithm for prufer codes.J. Softw. Eng. Appl., 2(2):111–115,
2024
-
[44]
Wentworth, J. and Lorell, D. Natural latents: La- tent variables stable across ontologies.arXiv preprint arXiv:2509.03780,
-
[45]
Data is split 80/10/10 into training, validation, and test sets
Both models are implemented in PyTorch and share the same architecture and optimisation scheme, differing only in model width and number of training epochs. Data is split 80/10/10 into training, validation, and test sets. 13 Critical Percolation as a Synthetic Data Model for Interpretability Table 5.Neural network training hyperparameters. Hyperparameter ...
2024
-
[46]
10 and Eq
,(12) Eq. 10 and Eq. 12 can be combined to give an expression for ns for general s. We can write this expression in terms of Gamma functions and simplify it using the beta function, ns = Γ(s)Γ(y) Γ(s+y) p01 1−p 01 =B(s, y) p01 1−p 01 .(13) 15 Critical Percolation as a Synthetic Data Model for Interpretability For larges,B(s, y)≈s −yΓ(y), giving ns = p01 1...
1999
-
[47]
The process is Markov, so it suffices to consider the conditional probability thatF k−1 =f k−1 givenF k =f k
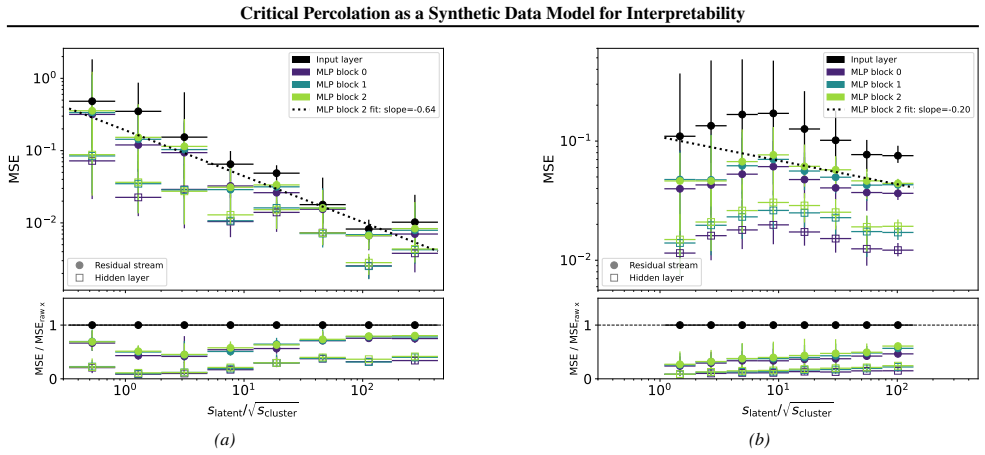
Next, we show that description (ii) is equivalent to (i). The process is Markov, so it suffices to consider the conditional probability thatF k−1 =f k−1 givenF k =f k. One approach is as follows (Sheth & Pitman, 1997). Using Bayes’ rule, P(F k−1 =f k−1 |F k =f k) = P(F k−1 =f k−1) P(F k =f k) P(F k =f k |F k−1 =f k−1).(21) From Eq. 19 and the fact that in...
1997
-
[48]
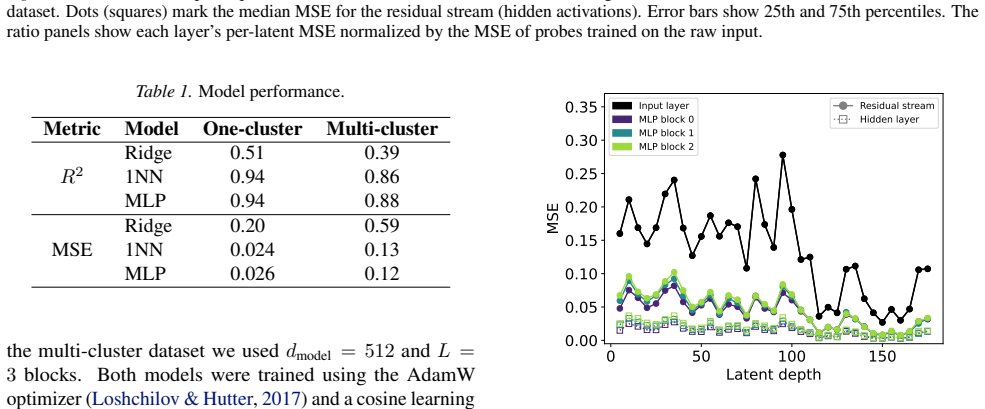
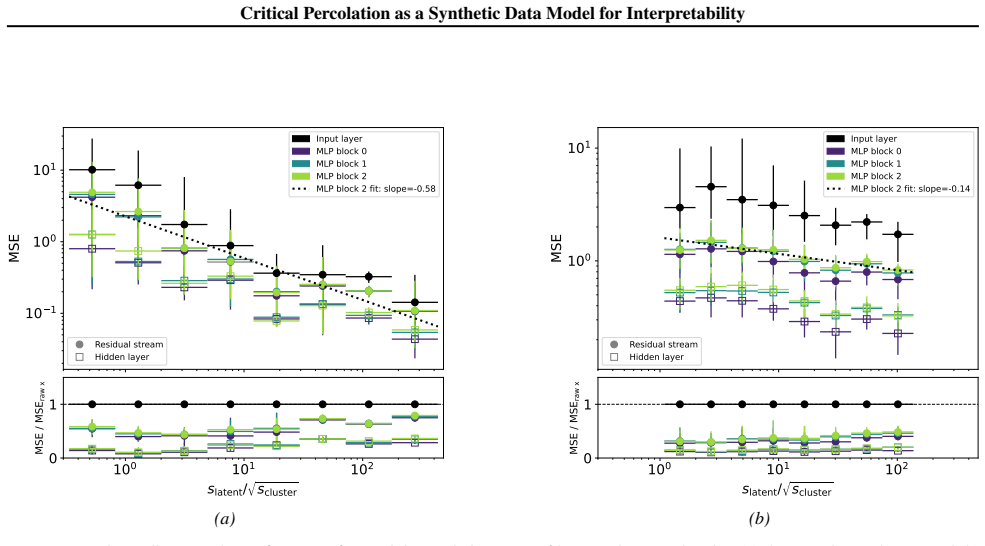
Dots (squares) mark the median MSE for the residual stream (hidden activations)
18 Critical Percolation as a Synthetic Data Model for Interpretability 10 1 100 101 MSE Input layer MLP block 0 MLP block 1 MLP block 2 MLP block 2 fit: slope=-0.58 Residual stream Hidden layer 100 101 102 slatent/ scluster 0 1MSE / MSEraw x (a) 100 101 MSE Input layer MLP block 0 MLP block 1 MLP block 2 MLP block 2 fit: slope=-0.14 Residual stream Hidden...
1918
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.