CourseBlueprint: A Structured Pipeline for Adaptive Pedagogical Video Generation Grounded in Course Corpora
Pith reviewed 2026-06-30 15:16 UTC · model grok-4.3
The pith
Explicit typed instructional contracts for scaffolding and engagement produce higher-quality pedagogical videos than surface-fluent generation alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
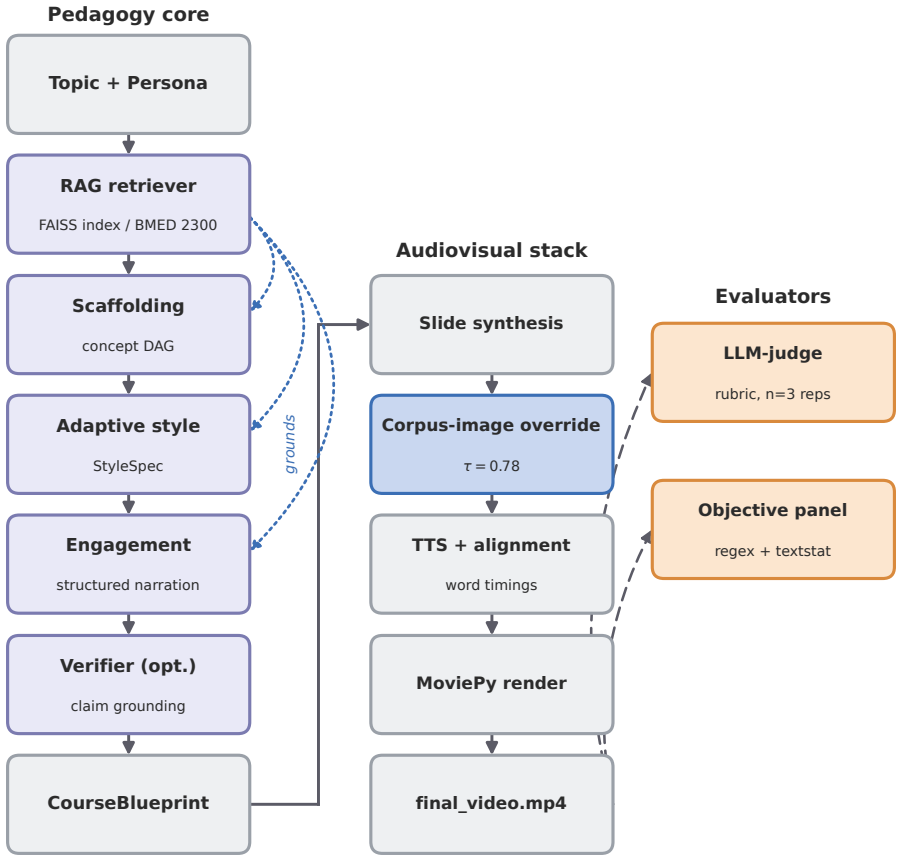
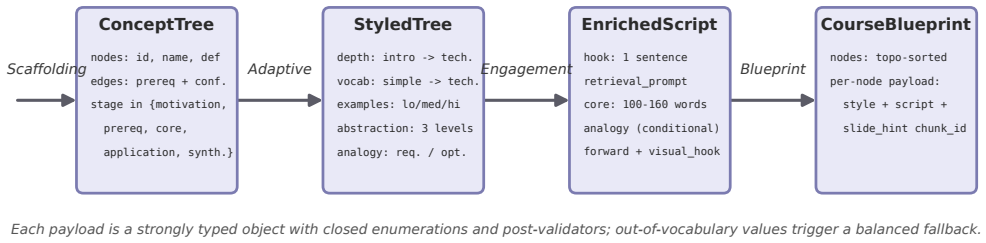
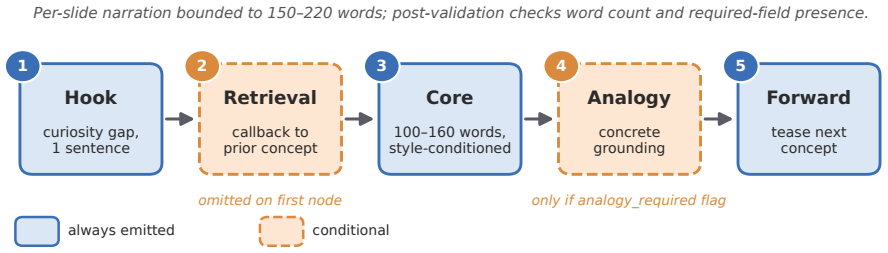
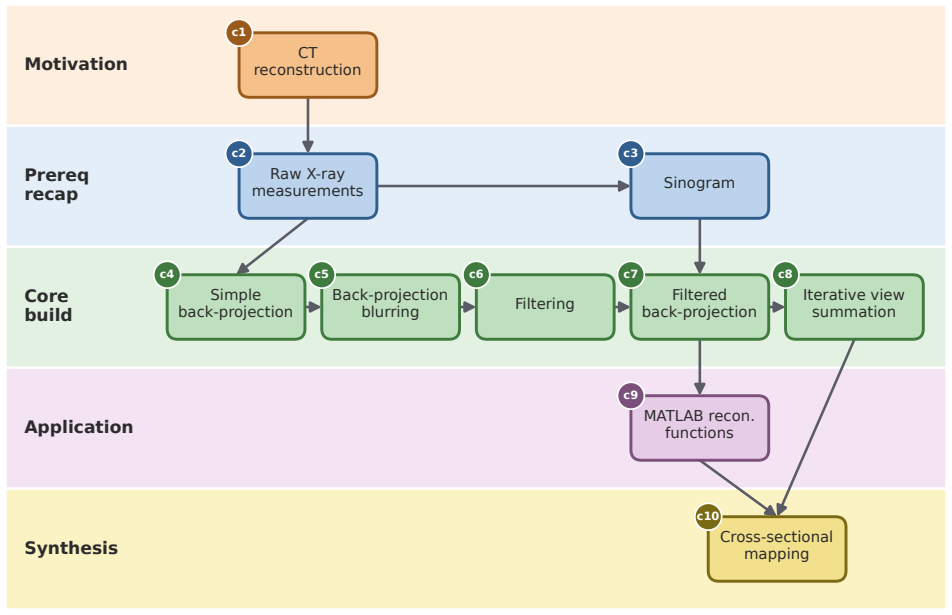
CourseBlueprint generates a structured teaching blueprint in a single forward pass over an undergraduate biomedical-imaging corpus using typed intermediate representations with validation: a scaffolding module builds a stage-labeled prerequisite concept graph with deterministic cycle removal, an adaptive controller assigns per-concept style specifications, and an engagement generator produces narration following a fixed hook-retrieval-core-analogy-forward contract, together with a deterministic slide-image override that reuses instructor slides when retrieval is high.
What carries the argument
The typed intermediate representations and instructional contracts (scaffolding graph, adaptive style assignments, fixed engagement sequence, and slide override) that enforce and make auditable the pedagogical elements of the generated video.
If this is right
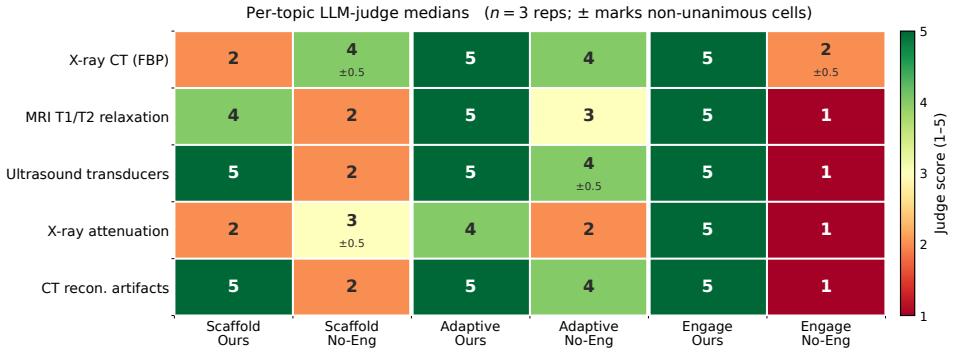
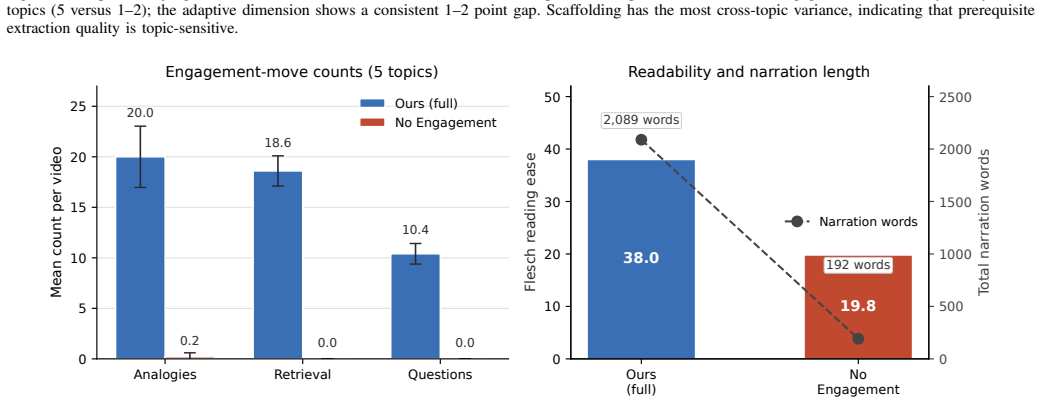
- Removing the engagement contract reduces engagement score from 5.00 to 1.20 and adaptive score from 4.80 to 3.40.
- The same removal drops Flesch readability from 38.0 to 19.8 and eliminates most analogy and retrieval prompts.
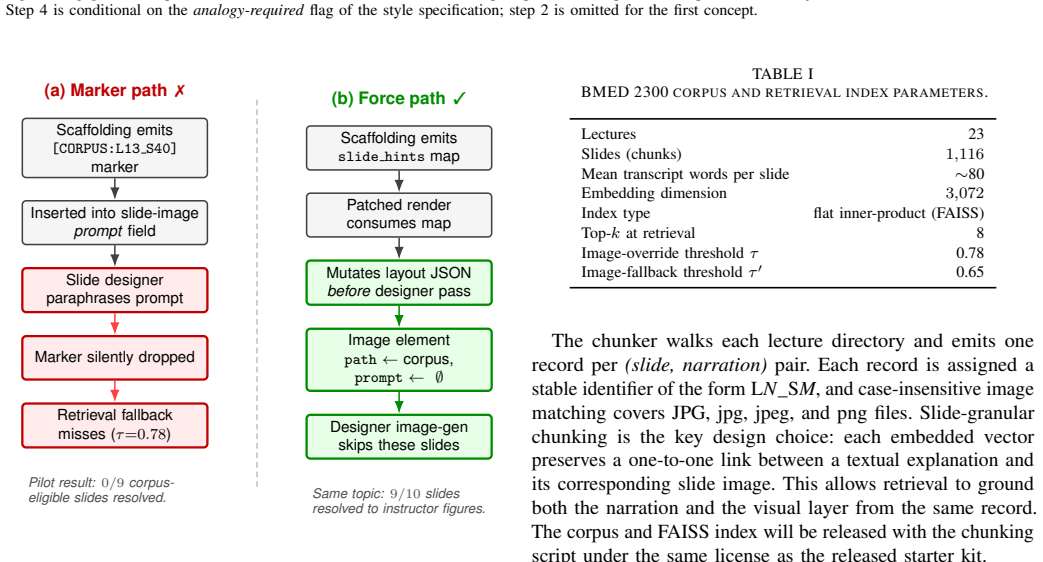
- The slide-image override converts a 0/9 grounding failure rate into 9/10 successful slide matches on the tested topic.
- The pipeline produces the full blueprint in one forward pass over the given 23-lecture corpus without ad-hoc chaining.
Where Pith is reading between the lines
- The same typed-contract approach could be tested on corpora from other undergraduate subjects to check whether the gains generalize beyond biomedical imaging.
- If the contracts prove effective, they might support automated generation of personalized video sequences that adapt depth and pacing to individual learner histories.
- The released benchmark and harness could serve as a shared testbed for comparing future video-generation pipelines on measurable instructional dimensions.
- One could examine whether the prerequisite graph produced by the scaffolding module aligns with expert instructor sequencing on the same course.
Load-bearing premise
That LLM-judge scores combined with regex-grounded objective metrics serve as a reliable proxy for actual pedagogical effectiveness and learner outcomes.
What would settle it
A controlled study that measures real student learning gains or retention after watching videos generated with versus without the typed engagement contract and slide override on the same topics.
Figures


read the original abstract
Generative text-to-video systems can produce visually fluent educational clips, but they rarely encode the pedagogical content knowledge (PCK) needed for effective instruction, including prerequisite-aware sequencing, learner-adaptive depth, and sustained cognitive engagement. We present CourseBlueprint, a course-grounded pipeline for adaptive pedagogical video generation. Given a topic and learner persona, the system generates a structured teaching blueprint in a single forward pass over an undergraduate biomedical-imaging corpus (BMED 2300; twenty-three lectures, 1,116 slides). Instead of ad-hoc prompt chaining, the pipeline uses typed intermediate representations with validation: a scaffolding module builds a stage-labeled prerequisite concept graph with deterministic cycle removal, an adaptive controller assigns per-concept style specifications, and an engagement generator produces narration following a fixed hook->retrieval->core->analogy->forward contract. A deterministic slide-image override further grounds the rendered video by reusing instructor slides whenever retrieval confidence is high. We also release a reusable benchmark corpus and an evaluation harness combining repeated LLM-judge scoring with regex-grounded objective metrics. In a five-topic ablation, removing the engagement contract reduces the engagement score from 5.00 to 1.20, the adaptive score from 4.80 to 3.40, Flesch readability from 38.0 to 19.8, and analogy and retrieval-prompt counts to near zero. The slide-image override converts a 0/9 corpus-grounding failure into 9/10 successful slide matches on the same topic. These results show that pedagogical video quality depends less on surface fluency than on explicit, typed instructional contracts that make scaffolding, adaptation, engagement, and grounding auditable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CourseBlueprint, a pipeline that takes a topic and learner persona and produces a structured teaching blueprint in one forward pass over an undergraduate biomedical-imaging corpus (23 lectures, 1,116 slides). It employs typed intermediate representations with validation: a scaffolding module builds a stage-labeled prerequisite graph with deterministic cycle removal, an adaptive controller assigns per-concept styles, and an engagement generator follows a fixed hook-retrieval-core-analogy-forward contract. A deterministic slide-image override reuses instructor slides on high-confidence retrieval. The authors release the benchmark corpus and an evaluation harness that combines repeated LLM-judge scoring with regex-grounded objective metrics. A five-topic ablation shows that removing the engagement contract drops LLM-judge engagement from 5.00 to 1.20, adaptivity from 4.80 to 3.40, Flesch readability from 38.0 to 19.8, and analogy/retrieval-prompt counts to near zero; the slide override raises grounding success from 0/9 to 9/10. The central claim is that pedagogical video quality depends less on surface fluency than on explicit, typed instructional contracts that render scaffolding, adaptation, engagement, and grounding auditable.
Significance. If the proxy metrics track actual pedagogical effectiveness, the work supplies a reproducible, auditable method for injecting pedagogical content knowledge into generative video pipelines and contributes open benchmark resources that future studies can reuse. The explicit release of the corpus and harness is a concrete strength that supports reproducibility.
major comments (1)
- [Abstract] Abstract (evaluation harness description): The claim that the ablation results demonstrate pedagogical video quality depends less on surface fluency than on the typed instructional contracts is load-bearing for the paper's contribution. However, all reported metrics (LLM-judge engagement, adaptivity, Flesch, analogy counts, slide-match success) are produced by the same LLM-judge + regex harness; no human learner study, pre/post knowledge test, expert pedagogical rating, or correlation with any external outcome measure is described. This leaves the interpretation that metric movement equals pedagogical quality unsupported.
Simulated Author's Rebuttal
We thank the referee for highlighting the gap between our proxy metrics and direct evidence of pedagogical effectiveness. We agree that the central claim in the abstract overreaches given the evaluation design and will revise the manuscript to moderate the language, clarify the scope of the metrics, and add an explicit limitations discussion.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation harness description): The claim that the ablation results demonstrate pedagogical video quality depends less on surface fluency than on the typed instructional contracts is load-bearing for the paper's contribution. However, all reported metrics (LLM-judge engagement, adaptivity, Flesch, analogy counts, slide-match success) are produced by the same LLM-judge + regex harness; no human learner study, pre/post knowledge test, expert pedagogical rating, or correlation with any external outcome measure is described. This leaves the interpretation that metric movement equals pedagogical quality unsupported.
Authors: We agree that the current evidence does not support equating movement on the LLM-judge and regex metrics with actual pedagogical quality. The ablation demonstrates that the typed contracts produce measurable differences on the harness-defined dimensions (engagement score, adaptivity score, Flesch, analogy/retrieval counts, slide grounding), but these remain internal proxies. In revision we will (1) rewrite the abstract sentence to state that the contracts improve the targeted, auditable dimensions as scored by the harness rather than claiming direct pedagogical superiority, (2) add a dedicated limitations subsection that explicitly notes the absence of human learner studies, pre/post tests, or expert ratings, and (3) qualify all result interpretations accordingly. These changes directly address the load-bearing claim. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
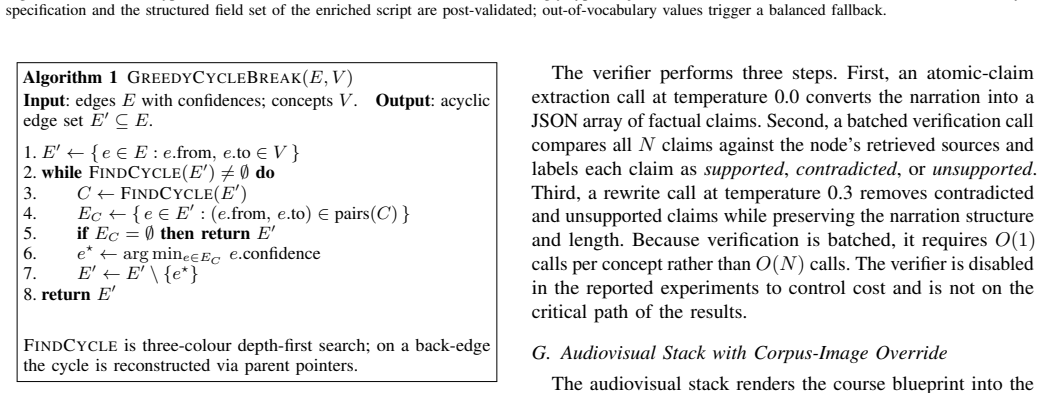
The paper describes a pipeline with typed modules (scaffolding graph, adaptive controller, engagement contract, slide override) and reports ablation results on LLM-judge scores plus regex counts. No equations, fitted parameters, or self-citations appear in the provided text. The ablation metrics (engagement score drop from 5.00 to 1.20, slide-match improvement from 0/9 to 9/10) are generated by an independent evaluation harness rather than being definitionally identical to the removed components. The central claim therefore rests on observable metric movement rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The undergraduate biomedical-imaging corpus (BMED 2300) contains the prerequisite structure and content knowledge needed to build accurate stage-labeled concept graphs.
- domain assumption LLM-judge scores and regex-grounded objective metrics are valid proxies for pedagogical effectiveness.
invented entities (1)
-
typed intermediate representations with validation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators,
OpenAI, “Video generation models as world simulators,” 2024, technical Report
2024
-
[2]
Openvid-1m: A large-scale high-quality dataset for text-to-video generation,
K. Nan, R. Xie, P. Zhou, T. Fan, Z. Yang, Z. Chen, X. Li, J. Yang, and Y . Tai, “Openvid-1m: A large-scale high-quality dataset for text-to-video generation,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 1045–1064
2025
-
[3]
Lumiere: A space-time diffusion model for video generation,
O. Bar-Tal, H. Chefer, O. Tovet al., “Lumiere: A space-time diffusion model for video generation,” inSIGGRAPH Asia, 2024
2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulalet al., “Stable video diffu- sion: Scaling latent video diffusion models to large datasets,” 2023, arXiv:2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
VideoPoet: A large language model for zero-shot video generation,
D. Kondratyuk, L. Yu, X. Guet al., “VideoPoet: A large language model for zero-shot video generation,” inICML, 2024
2024
-
[6]
Those who understand: Knowledge growth in teaching,
L. S. Shulman, “Those who understand: Knowledge growth in teaching,” Educational Researcher, vol. 15, no. 2, pp. 4–14, 1986
1986
-
[7]
Nature, sources, and devel- opment of pedagogical content knowledge for science teaching,
S. Magnusson, J. Krajcik, and H. Borko, “Nature, sources, and devel- opment of pedagogical content knowledge for science teaching,” pp. 95–132, 1999
1999
-
[8]
Technological pedagogical content knowledge: A framework for teacher knowledge,
P. Mishra and M. J. Koehler, “Technological pedagogical content knowledge: A framework for teacher knowledge,”Teachers College Record, vol. 108, no. 6, pp. 1017–1054, 2006
2006
-
[9]
Teaching monster challenge: Baseline and starter kit,
Teaching Monster Organising Committee, “Teaching monster challenge: Baseline and starter kit,” 2026, https://github.com/Teaching-Monster
2026
-
[10]
The role of tutoring in problem solving,
D. Wood, J. S. Bruner, and G. Ross, “The role of tutoring in problem solving,”Journal of Child Psychology and Psychiatry, vol. 17, no. 2, pp. 89–100, 1976
1976
-
[11]
L. S. Vygotsky,Mind in Society: The Development of Higher Psycho- logical Processes. Harvard University Press, 1978
1978
-
[12]
C. A. Tomlinson,The Differentiated Classroom: Responding to the Needs of All Learners. ASCD, 1999
1999
-
[13]
The knowledge-learning- instruction framework: Bridging the science-practice chasm to enhance robust student learning,
K. R. Koedinger, A. T. Corbett, and C. Perfetti, “The knowledge-learning- instruction framework: Bridging the science-practice chasm to enhance robust student learning,”Cognitive Science, vol. 36, no. 5, pp. 757–798, 2012
2012
-
[14]
The psychology of curiosity: A review and reinterpre- tation,
G. Loewenstein, “The psychology of curiosity: A review and reinterpre- tation,”Psychological Bulletin, vol. 116, no. 1, pp. 75–98, 1994
1994
-
[15]
The critical role of retrieval practice in long-term retention,
H. L. Roediger and J. D. Karpicke, “The critical role of retrieval practice in long-term retention,”Trends in Cognitive Sciences, vol. 15, no. 1, pp. 20–27, 2011
2011
-
[16]
The ICAP framework: Linking cognitive engagement to active learning outcomes,
M. T. H. Chi and R. Wylie, “The ICAP framework: Linking cognitive engagement to active learning outcomes,”Educational Psychologist, vol. 49, no. 4, pp. 219–243, 2014
2014
-
[17]
Intelligent tutoring goes to school in the big city,
K. R. Koedinger, J. R. Anderson, W. H. Hadley, and M. A. Mark, “Intelligent tutoring goes to school in the big city,”International Journal of Artificial Intelligence in Education, vol. 8, pp. 30–43, 1997
1997
-
[18]
The behavior of tutoring systems,
K. VanLehn, “The behavior of tutoring systems,”International Journal of Artificial Intelligence in Education, vol. 16, no. 3, pp. 227–265, 2006
2006
-
[19]
ChatGPT for good? on opportunities and challenges of large language models for education,
E. Kasneci, K. Sessler, S. Kuechemannet al., “ChatGPT for good? on opportunities and challenges of large language models for education,” Learning and Individual Differences, vol. 103, p. 102274, 2023
2023
-
[20]
Ai tutors: Hype or hope for education?
J. Bailey and J. Warner, “Ai tutors: Hype or hope for education?” Education Next, vol. 25, no. 1, 2025
2025
-
[21]
Tutor CoPilot: A human-AI approach for scaling real-time expertise,
R. E. Wang, A. T. Ribeiro, C. Robinson, S. Loeb, and D. Demszky, “Tutor CoPilot: A human-AI approach for scaling real-time expertise,” arXiv preprint arXiv:2410.03017, 2024
-
[22]
Experiences from using code explanations generated by large language models in a web software development E-book,
S. MacNeil, A. Tran, A. Hellaset al., “Experiences from using code explanations generated by large language models in a web software development E-book,” 2023
2023
-
[23]
One year in the classroom with chatgpt: empirical insights and transformative impacts,
F. Guo, T. Li, and C. J. Cunningham, “One year in the classroom with chatgpt: empirical insights and transformative impacts,” inFrontiers in education, vol. 10. Frontiers Media SA, 2025, p. 1574477
2025
-
[24]
The AI teacher test: Measuring the pedagogical ability of Blender and GPT-3 in educational dialogues,
A. Tack and C. Piech, “The AI teacher test: Measuring the pedagogical ability of Blender and GPT-3 in educational dialogues,” inProc. 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA), 2022
2022
-
[25]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in NeurIPS, 2020
2020
-
[26]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. O ˘guz, S. Minet al., “Dense passage retrieval for open-domain question answering,” inEMNLP, 2020
2020
-
[27]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-RAG: Learning to retrieve, generate, and critique through self-reflection,” inICLR, 2024
2024
-
[28]
RAFT: Adapting language model to domain specific RAG,
T. Zhang, S. G. Patil, N. Jainet al., “RAFT: Adapting language model to domain specific RAG,” 2024, arXiv:2403.10131
-
[29]
Billion-scale similarity search with GPUs
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,” 2017, arXiv:1702.08734
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
DOC2PPT: Automatic presentation slides generation from scientific documents,
T.-J. Fu, W. Y . Wang, D. McDuff, and Y . Song, “DOC2PPT: Automatic presentation slides generation from scientific documents,” inProc. AAAI, 2022
2022
-
[31]
Bruinsma, Ana Lucic, Megan Stanley, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A
S. Mondalet al., “Multi-modal slide generation from long documents with large language models,” 2024, arXiv:2405.13063
-
[32]
Efficient Guided Generation for Large Language Models
B. T. Willard and R. Louf, “Efficient guided generation for large language models,” 2023, arXiv:2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Synchromesh: Reliable code generation from pre-trained language models,
G. Poesia, O. Polozov, V . Le, A. Tiwari, G. Soares, C. Meek, and S. Gulwani, “Synchromesh: Reliable code generation from pre-trained language models,” inICLR, 2022
2022
-
[34]
Grammar- constrained decoding for structured NLP tasks without finetuning,
S. Geng, M. Josifoski, M. Peyrard, and R. West, “Grammar- constrained decoding for structured NLP tasks without finetuning,” 2023, arXiv:2305.13971
-
[35]
How video production affects student engagement: An empirical study of MOOC videos,
P. J. Guo, J. Kim, and R. Rubin, “How video production affects student engagement: An empirical study of MOOC videos,” inProc. 1st ACM Conference on Learning at Scale (L@S), 2014
2014
-
[36]
Cognitive theory of multimedia learning,
R. E. Mayer, “Cognitive theory of multimedia learning,”The Cambridge Handbook of Multimedia Learning, pp. 43–71, 2014
2014
-
[37]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” inNeurIPS Datasets and Benchmarks Track, 2023
2023
-
[38]
G-Eval: NLG evaluation using GPT-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-Eval: NLG evaluation using GPT-4 with better human alignment,” inEMNLP, 2023
2023
-
[39]
Chatbot Arena: An open platform for evaluating LLMs by human preference,
W.-L. Chiang, L. Zheng, Y . Shenget al., “Chatbot Arena: An open platform for evaluating LLMs by human preference,” inICML, 2024
2024
-
[40]
LLM evaluators recognize and favor their own generations,
A. Panickssery, S. R. Bowman, and S. Feng, “LLM evaluators recognize and favor their own generations,” inNeurIPS, 2024
2024
-
[41]
Prometheus 2: An open source language model specialized in evaluating other language models,
S. Kim, J. Suk, S. Longpreet al., “Prometheus 2: An open source language model specialized in evaluating other language models,” 2024, arXiv:2405.01535
-
[42]
AlpacaEval: An automatic evaluator of instruction- following models,
X. Li, T. Zhang, Y . Dubois, R. Taori, I. Gulrajani, C. Guestrin, P. Liang, and T. B. Hashimoto, “AlpacaEval: An automatic evaluator of instruction- following models,” 2023, https://github.com/tatsu-lab/alpaca eval
2023
-
[43]
A new readability yardstick,
R. Flesch, “A new readability yardstick,”Journal of Applied Psychology, vol. 32, no. 3, pp. 221–233, 1948
1948
-
[44]
Computing Krippendorff’s alpha-reliability,
K. Krippendorff, “Computing Krippendorff’s alpha-reliability,”University of Pennsylvania Annenberg School Departmental Papers, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.