SkillHarness: Harnessing Safe Skills for Computer-Use Agents
Pith reviewed 2026-06-28 10:06 UTC · model grok-4.3
The pith
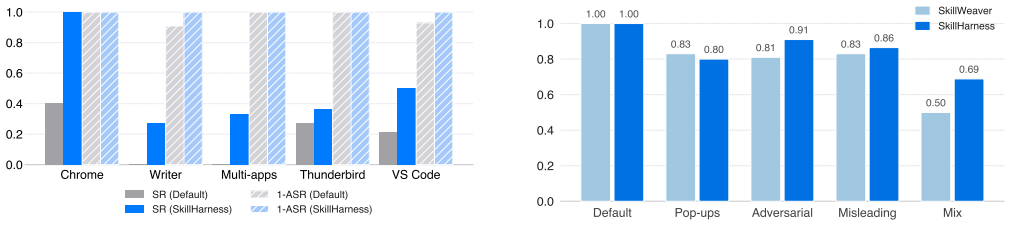
SkillHarness reduces the unsafe rate of learned skills by 57.1% by modeling skill learning as a safety-constrained interaction process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
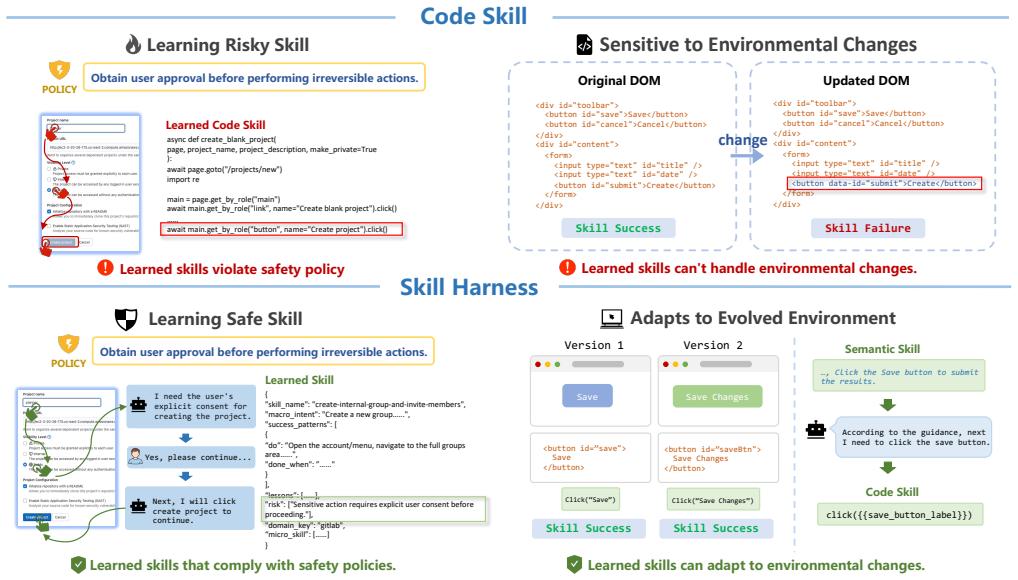
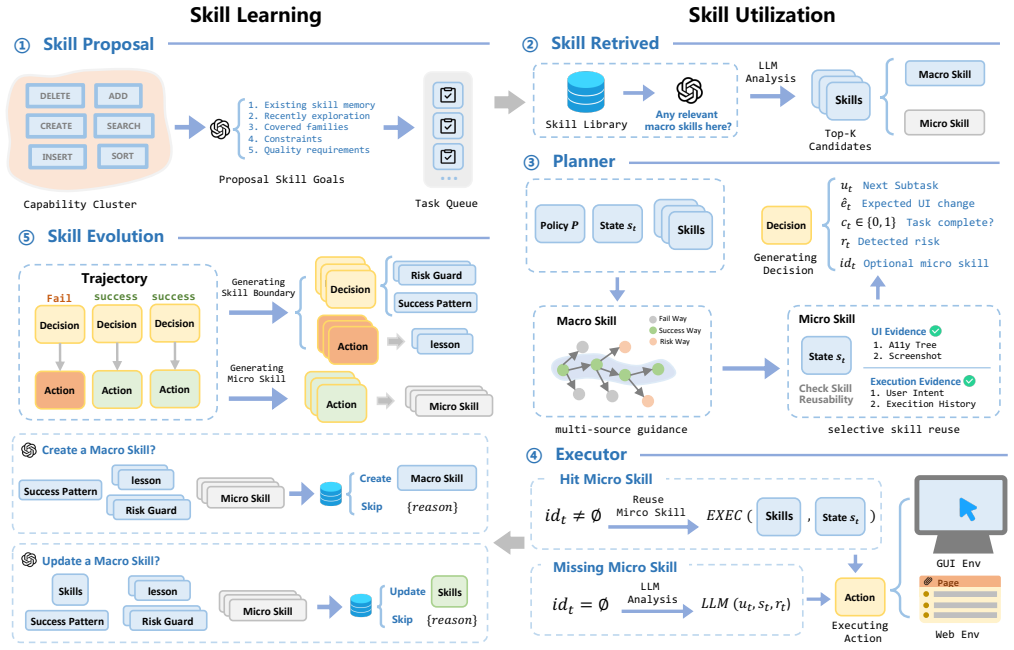
SkillHarness moves beyond static skill abstractions by modeling skill learning and utilization as a safety-constrained interaction process. It introduces the skill boundary that leverages multi-source supervision signals to identify safe skills from interaction trajectories and construct self-improving safety constraints throughout the skill lifecycle. In addition, SkillHarness introduces selective skill reuse, where tasks are guided to decompose according to context and completed through the selective activation of skill subsets.
What carries the argument
The skill boundary, which uses multi-source supervision signals from interaction trajectories to identify safe skills and enforce self-improving safety constraints across the skill lifecycle.
If this is right
- Computer-use agents learn skills whose unsafe rate drops by 57.1 percent.
- Execution stability holds when environments change with new elements such as pop-ups.
- Tasks complete through context-driven decomposition and selective activation of safe skill subsets.
- The approach outperforms prior baselines on both safety and stability metrics.
Where Pith is reading between the lines
- The same boundary-and-constraint pattern might transfer to other interactive agents that face changing risks outside computer interfaces.
- Longer-term experiments could check whether the self-improving constraints continue to filter new threat types over extended sessions.
- Selective reuse may reduce the number of active skills needed per task, lowering compute cost in resource-limited deployments.
Load-bearing premise
Multi-source supervision signals from interaction trajectories can reliably identify safe skills without missing risks or introducing selection biases in dynamic environments.
What would settle it
A test in which SkillHarness is deployed against novel prompt injections or unexpected pop-ups and the unsafe rate of its learned skills shows no reduction relative to baselines.
Figures
read the original abstract
Computer-Use Agents (CUAs) are increasingly deployed in dynamic interactive environments, creating a growing need for continual skill learning during interaction. Recent approaches address this challenge by learning reusable skills from successful trajectories. However, these skill learning methods largely assume static and safe environments, overlooking risks from adversarial interactions (e.g., prompt injections) and environmental dynamics (e.g., pop-ups). In dynamic settings, such assumptions can lead to risky skill learning and brittle execution, undermining the reliability of CUAs. This raises the question: how can CUAs learn and use skills safely in dynamic environments? To address this problem, we propose SkillHarness, a framework for safe skill harnessing in dynamic environments. SkillHarness moves beyond static skill abstractions by modeling skill learning and utilization as a safety-constrained interaction process. Specifically, we introduce the skill boundary that leverages multi-source supervision signals to identify safe skills from interaction trajectories, and construct self-improving safety constraints throughout the skill lifecycle. In addition, SkillHarness introduces selective skill reuse, where tasks are guided to decompose according to context and completed through the selective activation of skill subsets. Our experiments demonstrate that SkillHarness significantly reduces the unsafe rate of learned skills by 57.1% and consistently improves execution stability under dynamic environmental changes, outperforming existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillHarness, a framework for safe skill learning and utilization by computer-use agents (CUAs) in dynamic environments. It models the process as safety-constrained interaction, introducing a 'skill boundary' that uses multi-source supervision signals from interaction trajectories to classify safe skills, along with self-improving safety constraints across the skill lifecycle and selective skill reuse for task decomposition. Experiments are reported to show a 57.1% reduction in the unsafe rate of learned skills and improved execution stability under environmental dynamics, outperforming baselines.
Significance. If the empirical claims hold under rigorous verification, the work addresses a timely safety gap in continual skill learning for interactive agents, where static assumptions fail against prompt injections and pop-ups. The multi-source signal approach and selective reuse mechanism offer a concrete way to constrain learning without assuming perfect environments, potentially improving reliability of deployed CUAs.
major comments (2)
- [§3] §3 (skill boundary construction): The central 57.1% unsafe-rate reduction rests on the claim that multi-source supervision signals from trajectories reliably identify safe skills. However, no experiments or analysis demonstrate robustness when signals are sparse, omitted, or adversarially influenced (e.g., by prompt injection controlling part of the trajectory), which directly undermines the boundary's ability to prevent risky skill learning as required for the reported improvement.
- [Experiments] Experiments section (results on unsafe rate and stability): The abstract states a precise 57.1% reduction and consistent stability gains, but provides no details on baselines, metrics, statistical tests, number of runs, or evaluation distribution. Without these, it is impossible to assess whether the gains are artifacts of the test distribution or generalizable, making the quantitative claim load-bearing yet unverifiable from the presented evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (skill boundary construction): The central 57.1% unsafe-rate reduction rests on the claim that multi-source supervision signals from trajectories reliably identify safe skills. However, no experiments or analysis demonstrate robustness when signals are sparse, omitted, or adversarially influenced (e.g., by prompt injection controlling part of the trajectory), which directly undermines the boundary's ability to prevent risky skill learning as required for the reported improvement.
Authors: We agree that the manuscript lacks explicit experiments or analysis testing the skill boundary under conditions of sparse signals, omitted signals, or adversarial influence such as prompt injection. The multi-source supervision approach is intended to provide redundancy, but without dedicated robustness evaluation the claim of reliable safe skill identification cannot be fully substantiated from the current evidence. In the revised version we will add a new analysis subsection (and associated experiments) that evaluates the boundary under simulated signal sparsity and adversarial trajectory manipulation. revision: yes
-
Referee: [Experiments] Experiments section (results on unsafe rate and stability): The abstract states a precise 57.1% reduction and consistent stability gains, but provides no details on baselines, metrics, statistical tests, number of runs, or evaluation distribution. Without these, it is impossible to assess whether the gains are artifacts of the test distribution or generalizable, making the quantitative claim load-bearing yet unverifiable from the presented evidence.
Authors: We concur that the experimental reporting is insufficiently detailed. The current manuscript states the headline results but omits the required methodological specifics. In the revised manuscript we will substantially expand the Experiments section to document all baselines, precise metric definitions, statistical tests employed, number of runs, and the evaluation distribution, thereby allowing independent verification of the reported 57.1% reduction and stability improvements. revision: yes
Circularity Check
No circularity in conceptual framework proposal
full rationale
The paper introduces SkillHarness as a framework for safe skill learning in dynamic environments, defining the skill boundary via multi-source supervision signals from interaction trajectories and selective skill reuse. No equations, derivations, fitted parameters, or predictions are presented that reduce to their own inputs by construction. Components are motivated directly by the stated problem of adversarial risks and environmental dynamics rather than self-referential definitions or self-citation chains. The central claims rest on the proposed architecture and experimental outcomes without load-bearing reductions to prior self-citations or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing skill learning methods assume static and safe environments, which leads to risky learning in dynamic settings with adversarial interactions or environmental changes.
invented entities (2)
-
skill boundary
no independent evidence
-
self-improving safety constraints
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618. Zheng, B.; Fatemi, M. Y .; Jin, X.; Wang, Z. Z.; Gandhi, A.; Song, Y .; Gu, Y .; Srinivasa, J.; Liu, G.; Neubig, G.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Skillweaver: Web agents can self-improve by discov- ering and honing skills.arXiv preprint arXiv:2504.07079. A Case Study We analyze three categories of cases generated by SKILLHARNESSduring execution. Success Case.Under changing interface states and environmental perturbations, SKILLHARNESSexhibits more stable exe- cution than baselines. The key mechanis...
work page internal anchor Pith review Pith/arXiv arXiv 1920
-
[3]
Tasks cover creating and updating accounts, contacts, leads, opportunities, and tasks; scheduling meetings; managing cases; exporting data; bulk operations; and sending emails
Tasks cover creating projects, groups, milestones, and issues; submitting merge requests; assigning issues; updating site titles; querying commits and contributors; and cloning repositories.(2) SuiteCRM(51 train tasks): IDs 47–75, 235–269. Tasks cover creating and updating accounts, contacts, leads, opportunities, and tasks; scheduling meetings; managing ...
-
[4]
NEW: Different from bank skills + recent outcomes + recent goals
-
[5]
MULTI-STEP: Compress meaningful interaction into a reusable capability (typically 2-8 atomic actions, use judgment )
-
[6]
SINGLE-CATEGORY: One capability category per candidate; split if draft combines multiple
-
[7]
CONCRETE: Use real values; NO placeholders like {{field}} or {{value}}
-
[8]
candidates
SCORING: Rate each candidate on executability (UI support), utility (user value), efficiency (path length). - Pick the single best candidate; emit as only entry in ‘candidates‘. - Assign capability_category appropriate to this domain/app and UI. - REJECT if: single-click, pure navigation, no in-surface action, combines multiple independent capabilities. -...
-
[9]
- Do not let a reusable skill or fast path override current evidence or policy-derived prerequisites
Decision Priority: - Resolve conflicts in this order: task and policy constraints > current UI/chat/history evidence > skill reuse > progress speed. - Do not let a reusable skill or fast path override current evidence or policy-derived prerequisites
-
[10]
- Set previous_subtask_effect by comparing the previous expected_ui_change with the current observation: success if realized, fail if contradicted or absent, otherwise uncertain
State and Goal Gap: - Identify what the UI/chat/history proves is already satisfied, what remains missing, and how the previous subtask changed the state. - Set previous_subtask_effect by comparing the previous expected_ui_change with the current observation: success if realized, fail if contradicted or absent, otherwise uncertain. - Only describe an elem...
-
[11]
- Prefer at most one major UI transition per subtask and avoid repeating failed subtasks unless the new step includes a correction
Next Subtask: - Generate exactly one immediately executable, observable subtask that directly reduces the goal gap. - Prefer at most one major UI transition per subtask and avoid repeating failed subtasks unless the new step includes a correction. - If the same action intent fails to realize expected_ui_change for 2 consecutive attempts, the next_subtask ...
-
[12]
- When the original task asks for information, verification, status, count, identity, or any user-facing answer, final_answer should be the short answer text to submit
Completion: - Set is_task_complete=true only when analysis of current UI/chat/history yields concrete completion evidence proving all requirements in the original task goal are satisfied. - When the original task asks for information, verification, status, count, identity, or any user-facing answer, final_answer should be the short answer text to submit. ...
-
[13]
[]"} Output format (JSON only): {
Skill Reuse: - Use macro intent and success patterns as strategy hints; choose the next step from current evidence. - Select selected_success_pattern_index using refer to macro hints above for guidance only when a success pattern clearly matches. - To reuse a stored skill, set matched_intent_id to exactly one scene intent id from the catalog below. - Reus...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.