Decoupling the Declarative from the Procedural in Vision-Language-Action Models
Pith reviewed 2026-06-26 14:28 UTC · model grok-4.3
The pith
Restructuring information flow in vision-language-action models decouples declarative from procedural knowledge for zero-shot object transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
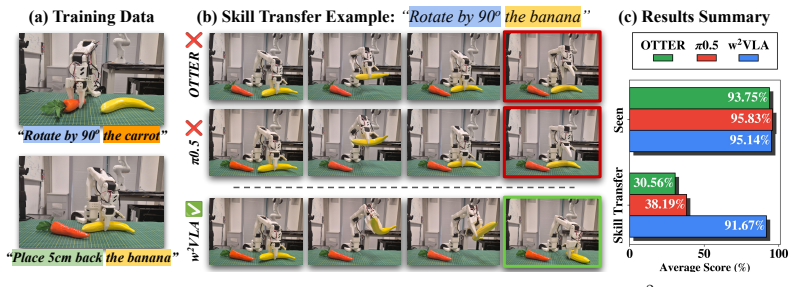
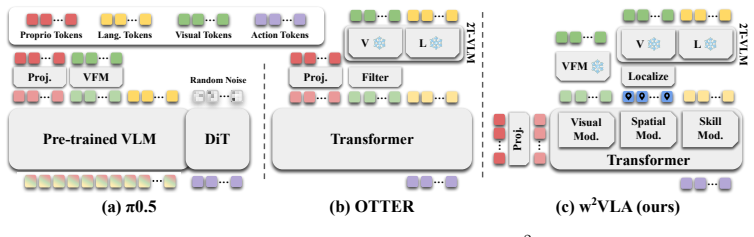
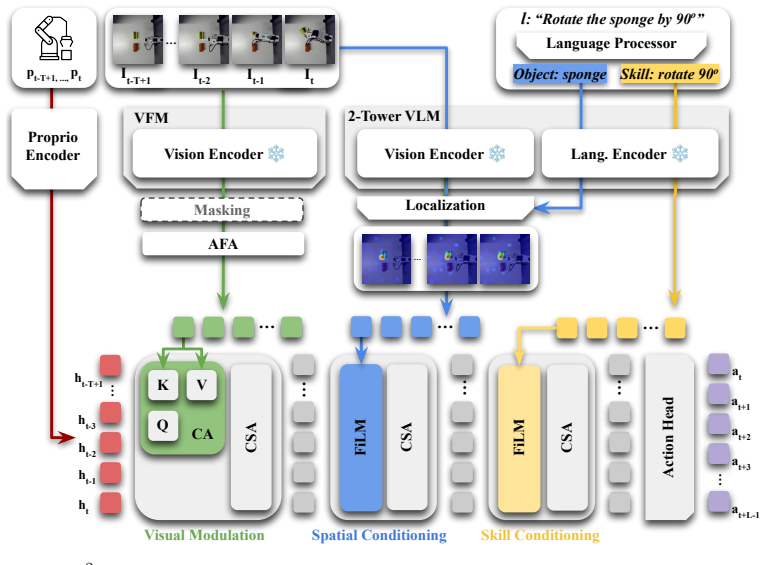
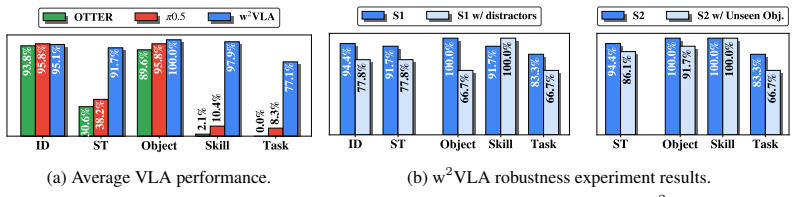
By modulating the robot state sequence with visual, spatial, and skill information in a compositional and interpretable manner rather than feeding all multimodal tokens from the VLM encoder into a large transformer-based action expert, the w²VLA model decouples declarative knowledge of concepts and entity semantics from procedural knowledge of how to perform actions, resulting in robust behavior cloning and zero-shot skill transfer to dissimilar unseen objects.
What carries the argument
The restructured information flow in w²VLA that modulates the robot state sequence with visual, spatial, and skill information in a compositional manner.
If this is right
- Policies achieve robust behavior cloning from object-specific demonstrations.
- Zero-shot skill transfer becomes possible across dissimilar unseen objects.
- The model handles spatial, semantic, and task variations more reliably than standard VLAs.
- Knowledge representations become more compositional and interpretable.
Where Pith is reading between the lines
- The same separation of information types could reduce the volume of robot demonstration data needed for new tasks.
- Explicit modulation of state sequences might generalize to other sequential decision systems that combine perception and action.
- Testing whether internal activations show clearer separation between semantic and motor features would directly probe the claimed decoupling.
Load-bearing premise
That modulating the robot state sequence with separate visual, spatial, and skill information will cause the learned parameters to separate declarative knowledge from procedural knowledge.
What would settle it
Train the model on behavior demonstrations with one set of objects then test whether the same skills succeed at high rates on a set of dissimilar unseen objects with no additional training or fine-tuning.
Figures

read the original abstract
Deploying generalist robotic agents in the real world requires transferable skills. Specifically, a policy trained to clone a behavior from object-specific demonstrations must generalize beyond that object, otherwise data collection requirements become intractable. Recently, fine-tuning of pre-trained billion-parameter Vision-Language Models (VLMs), initially on large-scale robot datasets and then on fewer scenario-specific demonstrations, has emerged as the predominant paradigm for designing Vision-Language-Action (VLA) models. While these policies achieve state-of-the-art manipulation performance in-distribution, they remain brittle to minor spatial, semantic, and task variations. In this work, we address the inability of current models to decouple the declarative (i.e., concepts and entity semantics) from the procedural knowledge (i.e., how to do something) encoded in their parameters, which is a fundamental bottleneck for zero-shot skill transfer to novel objects. To address this, we propose w$^{2}$VLA, a new VLA model with restructured information flow. Rather than feeding all multimodal tokens from the VLM encoder into a large, opaque transformer-based action expert, our approach modulates the robot state sequence with visual, spatial, and skill information in a compositional and interpretable manner. Unlike popular, state-of-the-art VLAs, we show that our modular approach successfully decouples knowledge representations, enabling robust behavior cloning and unprecedented zero-shot skill transfer capabilities across dissimilar, unseen objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes w²VLA, a Vision-Language-Action model that restructures information flow by modulating the robot state sequence with visual, spatial, and skill information in a compositional manner, rather than feeding all multimodal tokens into a large transformer action expert. It claims this modular design decouples declarative (entity semantics) from procedural (action execution) knowledge in the parameters, enabling robust behavior cloning and unprecedented zero-shot skill transfer to dissimilar unseen objects.
Significance. If the decoupling claim and transfer results hold with supporting evidence, the work would address a central limitation of current VLA models (brittleness to object variations) and could reduce data collection needs for new scenarios. The interpretable modulation approach offers a potential alternative to opaque fine-tuning of billion-parameter VLMs.
major comments (2)
- [Abstract] Abstract: The manuscript asserts empirical success ('we show that our modular approach successfully decouples knowledge representations, enabling robust behavior cloning and unprecedented zero-shot skill transfer') but supplies no experimental setup, datasets, metrics, baselines, ablations, or quantitative results. The central claim therefore cannot be evaluated.
- [Abstract] Abstract: The design choice of modulating the robot state sequence is presented as sufficient to produce decoupling of declarative and procedural knowledge in the learned parameters, yet no diagnostic evidence (e.g., representation probing, weight analysis, or controlled transfer metrics) is referenced to substantiate that the modulation actually enforces the claimed separation.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on the abstract and the evidence for our decoupling claim. We address each point below and indicate where revisions to the manuscript are appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts empirical success ('we show that our modular approach successfully decouples knowledge representations, enabling robust behavior cloning and unprecedented zero-shot skill transfer') but supplies no experimental setup, datasets, metrics, baselines, ablations, or quantitative results. The central claim therefore cannot be evaluated.
Authors: The abstract is a concise summary; the full manuscript provides the requested details. Section 4 describes the datasets (including robot demonstration collections for training and held-out novel objects), evaluation metrics (success rate for behavior cloning and zero-shot transfer), baselines (standard VLA fine-tuning approaches), and ablations on the modulation components. Quantitative results appear in Section 5 with tables and figures. We will revise the abstract to include a brief clause referencing the evaluation protocol for improved self-containment. revision: yes
-
Referee: [Abstract] Abstract: The design choice of modulating the robot state sequence is presented as sufficient to produce decoupling of declarative and procedural knowledge in the learned parameters, yet no diagnostic evidence (e.g., representation probing, weight analysis, or controlled transfer metrics) is referenced to substantiate that the modulation actually enforces the claimed separation.
Authors: The zero-shot transfer results to dissimilar unseen objects serve as the primary controlled evidence: success rates remain high only when declarative and procedural components are separated via modulation, while non-modular baselines fail. This is quantified in the transfer experiments. We acknowledge that explicit representation probing or weight analysis is not included; if the referee believes these would strengthen the claim, we can add them as additional diagnostics in a revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The manuscript presents an architectural proposal for a new VLA model (w²VLA) that restructures information flow by modulating robot state sequences rather than feeding all multimodal tokens into a transformer action expert. No equations, loss functions, fitted parameters, or derivation chains appear in the abstract or description that could reduce a claimed prediction or result to an input by construction. The central claim concerns empirical decoupling via a modular design, with no self-citation load-bearing steps, uniqueness theorems, or ansatzes invoked to justify the architecture. This is a standard case of a self-contained design proposal without mathematical self-reference.
Axiom & Free-Parameter Ledger
invented entities (1)
-
w²VLA modular information flow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alab- dulmohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[2]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[3]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models. InInternational Conference on Robotics and Automation (ICRA), 2024
2024
-
[4]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InRSS 2024 Workshop: Data Generation for Robotics, 2024
2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2025
2025
-
[6]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[7]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control. InRobotics: Science and S...
2024
-
[8]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. InConference on Robot Learning (CoRL), 2025
2025
-
[9]
Intelligence.π ∗ 0.6: a vla that learns from experience.arXiv:2511.14759, 2025
P. Intelligence.π ∗ 0.6: a vla that learns from experience.arXiv:2511.14759, 2025. 9
Pith/arXiv arXiv 2025
-
[10]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
- [11]
-
[12]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[14]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models. arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[15]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[16]
Huang, F
H. Huang, F. Liu, L. Fu, T. Wu, M. Mukadam, J. Malik, K. Goldberg, and P. Abbeel. Otter: A vision-language-action model with text-aware feature extraciton. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[17]
X. Yang, R. Dagli, A. Zook, H. Hadfield, A. Goyal, S. Birchfield, F. Ramos, and J. Trem- blay. Robolab: A high-fidelity simulation benchmark for analysis of task generalist policies. arXiv:2604.09860, 2026
Pith/arXiv arXiv 2026
- [18]
-
[19]
Chuang, Y
Y .-S. Chuang, Y . Li, D. Wang, C.-F. Yeh, K. Lyu, R. Raghavendra, J. Glass, L. Huang, J. We- ston, L. Zettlemoyer, et al. Meta clip 2: A worldwide scaling recipe.Advances in Neural Information Processing Systems (NeurIPS), 2026
2026
-
[20]
M. A. Goodale and A. Milner. Separate visual pathways for perception and action.Trends in Neurosciences, 1992
1992
-
[21]
M. A. Goodale, A. D. Milner, L. S. Jakobson, and D. P. Carey. A neurological dissociation between perceiving objects and grasping them.Nature, 1991
1991
-
[22]
Milner and M
D. Milner and M. Goodale.The visual brain in action, volume 27. Oxford University Press, 2006
2006
-
[23]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation. InConference on Robot Learning (CoRL), 2021
2021
-
[24]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[25]
N. Tsagkas, A. Sochopoulos, D. Danier, S. Vijayakumar, A. Kouris, O. Mac Aodha, and C. X. Lu. Attentive feature aggregation or: How policies learn to stop worrying about robustness and attend to task-relevant visual cues.arXiv:2511.10762, 2025. 10
arXiv 2025
-
[26]
L. Fu, H. Huang, G. Datta, L. Y . Chen, W. C.-H. Panitch, F. Liu, H. Li, and K. Goldberg. In- context imitation learning via next-token prediction. InInternational Conference on Robotics and Automation (ICRA), 2025
2025
-
[27]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. Film: visual reasoning with a general conditioning layer. InAssociation for the Advancement of Artificial Intelligence (AAAI), 2018
2018
-
[28]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems (RSS), 2023
2023
-
[29]
Xiong, Y
R. Xiong, Y . Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y . Lan, L. Wang, and T. Liu. On layer normalization in the transformer architecture. InInternational Conference on Machine Learning (ICML), 2020
2020
-
[30]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked autoencoders are scalable vision learners. InComputer Vision and Pattern Recognition (CVPR), 2022
2022
-
[31]
Cadene, S
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Ar- actingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf. Lerobot: State-of-the-art machine learning for real-world robotics in pytorch. https://github.com/huggingface/lerobot, 2024
2024
-
[32]
A. Xie, L. Lee, T. Xiao, and C. Finn. Decomposing the generalization gap in imitation learning for visual robotic manipulation. InInternational Conference on Robotics and Automation (ICRA), 2024
2024
-
[33]
Hansen, Z
N. Hansen, Z. Yuan, Y . Ze, T. Mu, A. Rajeswaran, H. Su, H. Xu, and X. Wang. On pre- training for visuo-motor control: Revisiting a learning-from-scratch baseline. InInternation Conference on Machine Learning (ICML), 2023
2023
-
[34]
Burns, Z
K. Burns, Z. Witzel, J. I. Hamid, T. Yu, C. Finn, and K. Hausman. What makes pre-trained visual representations successful for robust manipulation? InConference on Robot Learning (CoRL), 2024
2024
-
[35]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. At- tariyan, and S. Gelly. Parameter-efficient transfer learning for NLP. InInternation Conference on Machine Learning (ICML), 2019
2019
-
[36]
X. Lin, J. So, S. Mahalingam, F. Liu, and P. Abbeel. Spawnnet: Learning generalizable visuo- motor skills from pre-trained network. InInternational Conference on Robotics and Automa- tion (ICRA), 2024
2024
- [37]
-
[38]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[39]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control.arXiv:2602.13193, 2026
Pith/arXiv arXiv 2026
-
[40]
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu. Any- grasp: Robust and efficient grasp perception in spatial and temporal domains.Transactions on Robotics (T-RO), 2023. 11
2023
-
[41]
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Ba- tra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[42]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[43]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[44]
M. Lan, C. Chen, Y . Ke, X. Wang, L. Feng, and W. Zhang. Clearclip: Decomposing clip representations for dense vision-language inference. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[45]
Sundaresan, S
P. Sundaresan, S. Belkhale, D. Sadigh, and J. Bohg. KITE: Keypoint-conditioned policies for semantic manipulation. InConference on Robot Learning (CoRL), 2023
2023
-
[46]
Zhang, M
J. Zhang, M. Memmel, K. Kim, D. Fox, J. Thomason, F. Ramos, E. Bıyık, A. Gupta, and A. Li. Peek: Guiding and minimal image representations for zero-shot generalization of robot manipulation policies. InInternational Conference on Robotics and Automation (ICRA), 2026
2026
-
[47]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning (CoRL), 2023
2023
-
[48]
W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola. Distilled feature fields enable few-shot language-guided manipulation. InConference on Robot Learning (CoRL), 2023
2023
-
[49]
Tsagkas, J
N. Tsagkas, J. Rome, S. Ramamoorthy, O. Mac Aodha, and C. X. Lu. Click to grasp: Zero- shot precise manipulation via visual diffusion descriptors. InInternational Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[50]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning (CoRL), 2023
2023
-
[51]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS), 2024
2024
-
[52]
Driess, J
D. Driess, J. Springenberg, B. Ichter, L. Yu, A. Li-Bell, K. Pertsch, A. Ren, H. Walke, Q. Vuong, L. X. Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.Advances in Neural Information Processing Systems (NeurIPS), 2026
2026
-
[53]
X. Guo, B. Xie, W. Chai, X. Deng, T. Wang, Z. Wu, and X. Chen. Priorvla: Prior-preserving adaptation for vision-language-action models.arXiv:2605.10925, 2026
Pith/arXiv arXiv 2026
-
[54]
S. Chen, P. Pacaud, and C. Schmid. Pointact: Vision-language-action models with multi-scale point-action interaction.arXiv:2605.21414, 2026
Pith/arXiv arXiv 2026
-
[55]
Sochopoulos, N
A. Sochopoulos, N. Malkin, N. Tsagkas, J. Moura, M. Gienger, and S. Vijayakumar. Fast flow-based visuomotor policies via conditional optimal transport couplings. InConference on Robot Learning (CoRL), 2025
2025
-
[56]
poke” and “pour
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Confer- ence on Learning Representations (ICLR), 2019. 12 Appendix A.1 Related Work Vision-Language-Action Models. Inspired by the broad success that LLMs and VLMs have achieved by scaling both model size and training data, the robotics community has increasingly adopted t...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.