Artic-O: End-to-End Articulated Object Reconstruction via Latent Geometry Learning
Pith reviewed 2026-06-26 12:12 UTC · model grok-4.3
The pith
Artic-O reconstructs articulated objects end-to-end by mapping sparse multi-state images into a pretrained latent geometry space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
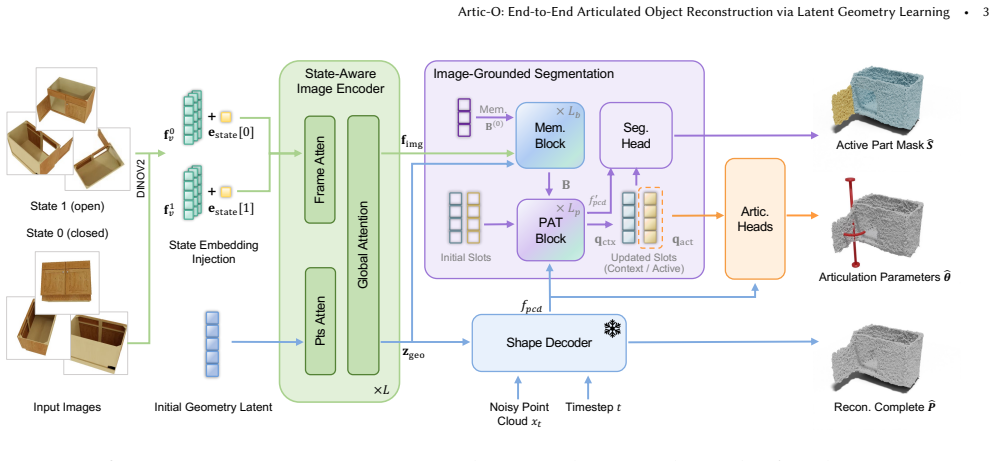
Artic-O maps sparse multi-state observations into a pretrained latent geometry space, where a frozen flow-matching decoder provides a complete-shape prior for recovering visible and occluded structures, and fuses visual tokens, geometry latents, and point-wise decoder features in an image-grounded part-reasoning module for active-part segmentation and articulation prediction, trained via a geometry-to-articulation curriculum and decoupled two-pass strategy.
What carries the argument
The pretrained latent geometry space equipped with its frozen flow-matching decoder, together with the image-grounded part-reasoning module that fuses visual tokens, geometry latents, and point-wise decoder features.
Load-bearing premise
The pretrained latent geometry space and its frozen flow-matching decoder supply accurate complete-shape priors for articulated objects without domain-specific fine-tuning.
What would settle it
Re-training or testing the model after replacing the frozen flow-matching decoder with a randomly initialized one and measuring whether Chamfer Distance and part segmentation accuracy degrade substantially on PartNet-Mobility.
Figures





read the original abstract
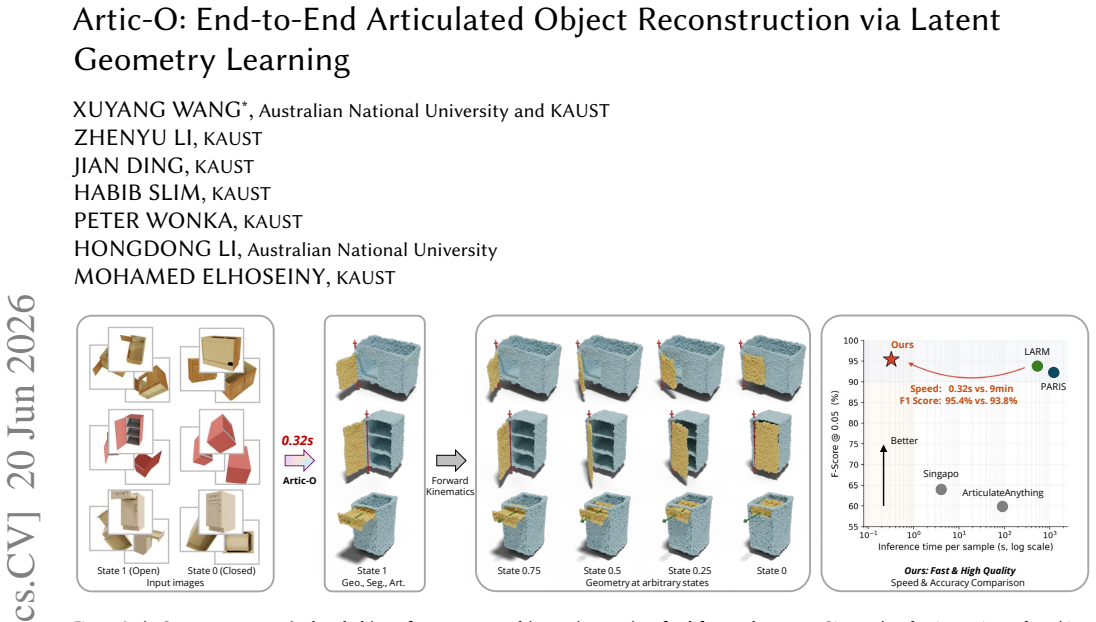
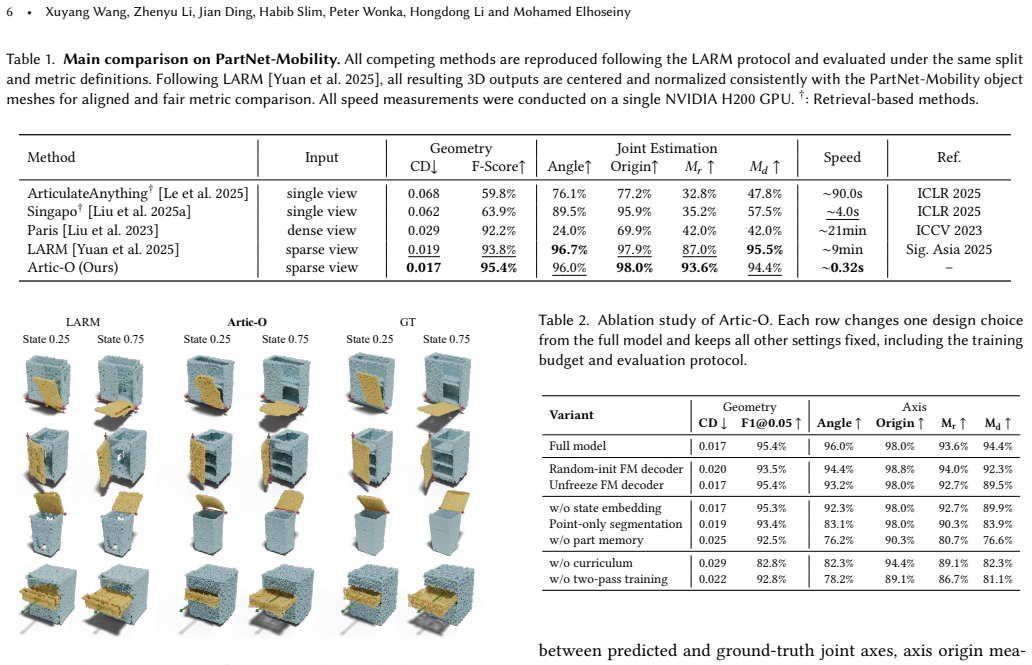
Reconstructing articulated objects from sparse images requires recovering complete geometry, movable parts, and motion parameters. Recent methods typically separate geometry reconstruction, part reasoning, and articulation estimation into different stages. This separation can weaken consistency between shape, active parts, and motion, while also incurring substantial inference cost. We introduce Artic-O, an end-to-end, feed-forward framework for articulated object reconstruction via latent geometry learning. Instead of fitting geometry in image or view space, Artic-O maps sparse multi-state observations into a pretrained latent geometry space, where a frozen flow-matching decoder provides a complete-shape prior for recovering visible and occluded structures. To connect geometry with articulation, Artic-O fuses visual tokens, geometry latents, and point-wise decoder features in an image-grounded part-reasoning module for active-part segmentation and articulation prediction. We further train the model with a geometry-to-articulation curriculum and a decoupled two-pass strategy to balance reconstruction and part-level supervision. On PartNet-Mobility, Artic-O achieves strong reconstruction quality while being substantially more efficient than LARM, a strong prior method. It reduces Chamfer Distance, improves F-score, and achieves comparable or better articulation accuracy across most joint metrics, while reducing inference time from 9 minutes to about 0.3 seconds per object.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Artic-O, an end-to-end feed-forward framework for articulated object reconstruction from sparse multi-state images. It maps observations into a pretrained latent geometry space where a frozen flow-matching decoder acts as a complete-shape prior for visible and occluded structures. Visual tokens, geometry latents, and point-wise decoder features are fused in an image-grounded part-reasoning module for active-part segmentation and articulation prediction. Training employs a geometry-to-articulation curriculum and decoupled two-pass strategy. On PartNet-Mobility, the method claims reduced Chamfer Distance, improved F-score, comparable or better articulation accuracy, and inference time reduced from 9 minutes to 0.3 seconds versus LARM.
Significance. If the quantitative results hold with proper ablations, the work demonstrates that leveraging a pretrained latent geometry prior with a frozen decoder, combined with feature fusion and curriculum training, can deliver consistent shape-articulation reconstruction at substantially lower inference cost than multi-stage baselines. This addresses consistency and efficiency limitations in prior methods and could enable practical applications in robotics and AR where real-time performance is required. The explicit positioning of the frozen decoder as a prior and the feed-forward design are notable strengths.
major comments (2)
- [Abstract] Abstract: the claims of reduced Chamfer Distance, improved F-score, and comparable articulation accuracy are presented only qualitatively with no numerical values, tables, error bars, or references to specific experimental results. This is load-bearing for the central claim of achieving 'strong reconstruction quality' because the magnitude and reliability of the improvements cannot be assessed from the given information.
- [Abstract] Abstract: the geometry-to-articulation curriculum and decoupled two-pass strategy are described at a high level without implementation details, loss formulations, or ablation studies showing how they balance shape and part supervision. This is load-bearing for the claim that the training 'successfully balances reconstruction and part-level supervision' without degrading either.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that quantitative results should be referenced explicitly and will revise the abstract accordingly. The training strategy details are provided in the main text and ablations, consistent with standard abstract conventions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of reduced Chamfer Distance, improved F-score, and comparable articulation accuracy are presented only qualitatively with no numerical values, tables, error bars, or references to specific experimental results. This is load-bearing for the central claim of achieving 'strong reconstruction quality' because the magnitude and reliability of the improvements cannot be assessed from the given information.
Authors: We agree that the abstract would benefit from explicit numerical references. In the revised version, we will incorporate specific values from our PartNet-Mobility experiments (e.g., the exact Chamfer Distance reduction and F-score improvement relative to LARM) along with pointers to the relevant tables and figures. This directly addresses the concern about assessing the magnitude of improvements. revision: yes
-
Referee: [Abstract] Abstract: the geometry-to-articulation curriculum and decoupled two-pass strategy are described at a high level without implementation details, loss formulations, or ablation studies showing how they balance shape and part supervision. This is load-bearing for the claim that the training 'successfully balances reconstruction and part-level supervision' without degrading either.
Authors: Abstracts are designed as high-level summaries; the geometry-to-articulation curriculum, decoupled two-pass strategy, loss formulations, and supporting ablations are fully detailed in Section 3.4 and Section 4.3, including evidence that reconstruction and part supervision are balanced without degradation. We will add a brief clause in the abstract noting that these components enable effective balancing as validated by our experiments, but we maintain that full technical details belong in the body rather than the abstract. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an end-to-end feed-forward model that maps sparse observations into a pretrained latent geometry space using a frozen flow-matching decoder as an external prior, followed by fusion in an image-grounded module and training via curriculum and decoupled passes. No equations or fitting procedures are presented that reduce any claimed prediction or result to the inputs by construction. The evaluation against the external baseline LARM on PartNet-Mobility supplies independent grounding. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation are visible in the abstract or description. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers
Freeart3d: Training-free articulated object generation using 3d diffusion. InProceedings of the SIGGRAPH Asia 2025 Conference Papers. 1–13. Weirong Chen, Chuanxia Zheng, Ganlin Zhang, Andrea Vedaldi, and Daniel Cremers
2025
-
[2]
Lian Fu, Ryoichi Ishikawa, Yoshihiro Sato, and Takeshi Oishi
Urdformer: A pipeline for constructing articulated simulation environments from real-world images.arXiv preprint arXiv:2405.11656(2024). Lian Fu, Ryoichi Ishikawa, Yoshihiro Sato, and Takeshi Oishi
-
[3]
17578–17602. Ruining Li, Yuxin Yao, Chuanxia Zheng, Christian Rupprecht, Joan Lasenby, Shangzhe Wu, and Andrea Vedaldi. 2025a. Particulate: Feed-Forward 3D Object Articulation. arXiv preprint arXiv:2512.11798(2025). Xiaolong Li, He Wang, Li Yi, Leonidas J Guibas, A Lynn Abbott, and Shuran Song
-
[4]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Category-level articulated object pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3706–3715. Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. 2025b. Triposg: High-fidelity 3d shape synthesis using large-scale rectifi...
2025
-
[5]
Jiayi Liu, Denys Iliash, Angel Chang, Manolis Savva, and Ali Mahdavi Amiri
Partcrafter: Structured 3d mesh generation via com- positional latent diffusion transformers.Advances in neural information processing systems38 (2026), 35387–35415. Jiayi Liu, Denys Iliash, Angel Chang, Manolis Savva, and Ali Mahdavi Amiri. 2025a. Singapo: Single image controlled generation of articulated parts in objects. InInter- national Conference on...
2026
-
[6]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193(2023). Xiaowen Qiu, Jincheng Yang, Yian Wang, Zhehuan Chen, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, and Chuang Gan
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu
Articulate AnyMesh: Open-vocabulary 3D Articulated Objects Modeling.arXiv preprint arXiv:2502.02590(2025). Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu
-
[8]
TripoSR: Fast 3D Object Reconstruction from a Single Image
TripoSR: Fast 3D Object Reconstruction from a Single Image.arXiv preprint arXiv:2403.02151 (2024). Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
MeshLRM: Large Reconstruction Model for High- Quality Meshes.arXiv preprint, 2404.12385, 2024
Meshlrm: Large reconstruction model for high-quality meshes.arXiv preprint arXiv:2404.12385(2024). Yijia Weng, He Wang, Qiang Zhou, Yuzhe Qin, Yueqi Duan, Qingnan Fan, Baoquan Chen, Hao Su, and Leonidas J Guibas
-
[10]
Zihao Yan, Ruizhen Hu, Xingguang Yan, Luanmin Chen, Oliver Van Kaick, Hao Zhang, and Hui Huang
X-part: high fidelity and structure coherent shape decomposition.arXiv preprint arXiv:2509.08643(2025). Zihao Yan, Ruizhen Hu, Xingguang Yan, Luanmin Chen, Oliver Van Kaick, Hao Zhang, and Hui Huang
-
[11]
RPM-Net: recurrent prediction of motion and parts from point cloud.ACM Transactions on Graphics (TOG)38, 6 (2019), 1–15. Xianghui Yang, Huiwen Shi, Bowen Zhang, Fan Yang, Jiacheng Wang, Hongxu Zhao, Xinhai Liu, Xinzhou Wang, Qingxiang Lin, Jiaao Yu, et al. 2024b. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation.arXiv preprint a...
-
[12]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers
Omnipart: Part-aware 3d generation with semantic decoupling and structural cohesion. InProceedings of the SIGGRAPH Asia 2025 Conference Papers. 1–12. Sylvia Yuan, Ruoxi Shi, Xinyue Wei, Xiaoshuai Zhang, Hao Su, and Minghua Liu
2025
-
[13]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers
LARM: A Large Articulated Object Reconstruction Model. InProceedings of the SIGGRAPH Asia 2025 Conference Papers. 1–12. Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka
2025
-
[14]
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG)42, 4 (2023), 1–16. Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu
2023
-
[15]
Mandi Zhao, Yijia Weng, Dominik Bauer, and Shuran Song
Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM Transactions on Graphics (TOG)43, 4 (2024), 1–20. Mandi Zhao, Yijia Weng, Dominik Bauer, and Shuran Song. 2025b. Real2code: Re- construct articulated objects via code generation. InInternational Conference on Learning Representations, Vol
2024
-
[16]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
668–686. Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. 2025a. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202(2025). Yuchen Zhou, Jiayuan Gu, Tung Yen Chiang, Fanbo Xiang, and Hao Su
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Qualitative comparison between Artic-O and LARM [Yuan et al . 2025]. Both methods take sparse two-state images as input and reconstruct the articulated object across intermediate motion states. Red circles highlight representative regions where LARM produces incomplete or inconsistent geometry, such as missing top surfaces, noisy lids, and broken interior...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.