CoDMD: Copula-aware Distribution Matching Distillation for Fast Video Generation
Pith reviewed 2026-06-26 12:50 UTC · model grok-4.3
The pith
Matching pairwise relation matrices from existing scores prevents DMD collapse in few-step video distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
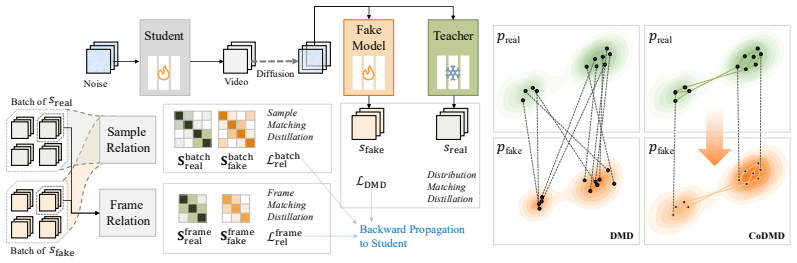
The paper claims that DMD's reverse-KL objective combined with its intra-sample nature causes the model to collapse into local optima under low NFE budgets because the copula across samples and frames remains unconstrained; the proposed CoDMD regularizer corrects this by constructing pairwise relation matrices from frozen-teacher and online-student scores and matching their distributions through an additional term that requires no extra parameters or sampling.
What carries the argument
The copula-aware relational regularizer that reuses existing score estimates to construct and match pairwise relation matrices across samples and temporal frames.
If this is right
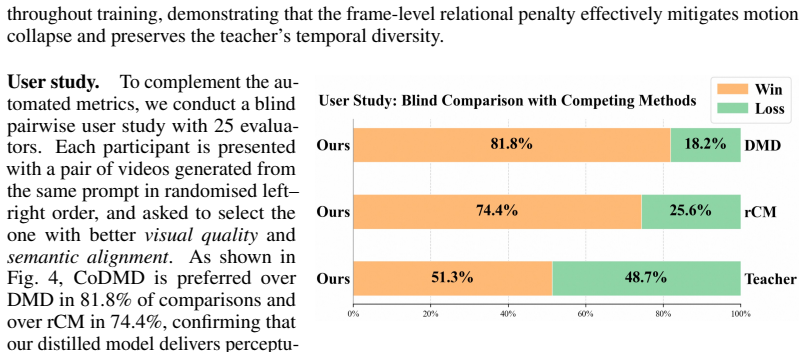
- 50-step teachers can be distilled to 4-step students with an approximate 25 times inference speedup on 1.3B and 14B video models.
- The resulting 4-step models attain VBench scores of 84.46 and 84.87, exceeding both trajectory-based and standard distribution-based distillation baselines.
- Layout stability, color saturation, and motion dynamics improve because the joint distribution across frames and batch elements is now explicitly regularized.
- The added regularizer introduces no extra networks, datasets, or sampling trajectories during training.
Where Pith is reading between the lines
- The same relation-matrix construction could be tested on image or audio diffusion models to check whether copula regulation improves few-step quality outside video.
- If the copula term proves decisive, distillation pipelines might shift from purely marginal matching toward explicit joint-distribution objectives as a default design choice.
- Future work could examine whether the benefit scales to even fewer steps, such as 2-step or 1-step regimes, where relational collapse would be expected to be more severe.
Load-bearing premise
The performance drop in few-step DMD occurs specifically because relational constraints across elements are absent, and explicitly matching pairwise relation matrices will restore quality without creating new failure modes.
What would settle it
An ablation that disables the pairwise relation-matrix matching term while keeping all other components identical, then measures whether VBench scores and artifact rates revert to those of standard DMD on the same 4-step video models.
Figures


read the original abstract
Few-step distillation for video diffusion models has attracted significant attention, driven by the urgent demand for efficient deployment in real-world scenarios. However, Distribution Matching Distillation (DMD), a leading paradigm, tends to degrade under limited NFE budgets, manifesting in video generation as layout instability, oversaturation, and broken motion dynamics. We trace this failure to a structural limitation: standard DMD is an intra-sample distribution-matching objective with coordinate-wise gradients, and thus imposes no explicit constraint on the relational geometry across batch elements or temporal frames, leaving the underlying copula largely unregulated. Combined with the mode-seeking tendency of its reverse-KL objective, this absence of relational guidance makes DMD prone to collapsing into local optima in the few-step regime. Motivated by this insight, we propose Copula-aware DMD (CoDMD), a lightweight relational regularizer that reuses score estimates already produced by the frozen teacher and the online fake model to construct pairwise relation matrices across samples and frames. These are matched through a supplementary distributional objective that requires no additional networks, datasets, or sampling trajectories. On the Wan-2.1-T2V model series at 1.3B & 14B scales, CoDMD distills 50-step teachers into 4-step students, achieving an approximate 25$\times$ speed-up while attaining VBench scores of 84.46 & 84.87, outperforming prior trajectory-based (rCM 82.81 & 84.05) and distribution-based (DMD 83.38 & 83.81) methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard DMD for video diffusion degrades in the few-step regime due to its intra-sample, coordinate-wise nature that leaves relational (copula) structure across batch elements and temporal frames unregulated, combined with reverse-KL mode-seeking. It introduces CoDMD, a lightweight supplementary distributional objective that reuses already-computed teacher and fake scores to build and match pairwise relation matrices, requiring no extra networks or trajectories. On the Wan-2.1-T2V series (1.3B and 14B), 50-step teachers are distilled to 4-step students yielding VBench scores of 84.46 and 84.87, outperforming rCM (82.81/84.05) and DMD (83.38/83.81) while delivering ~25× speedup.
Significance. If the reported gains are reproducible and causally linked to the copula regularizer, the method would be a low-overhead, parameter-free improvement to DMD that directly targets relational geometry in video generation; this is practically significant for real-time deployment of large video models.
major comments (2)
- [Abstract] Abstract: the central performance claims (VBench scores, outperformance over DMD/rCM, 25× speedup) are presented without any description of experimental protocol, training details, dataset, number of runs, or statistical significance; this is load-bearing because the superiority assertion cannot be evaluated from the given information.
- [Abstract] Abstract: the mechanistic premise that DMD degradation stems specifically from absent relational constraints (and that matching pairwise matrices from existing scores will correct it without new failure modes) is asserted but not supported by ablations or controlled experiments isolating the copula term; this is load-bearing for the motivation and novelty of CoDMD.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the motivation for CoDMD. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (VBench scores, outperformance over DMD/rCM, 25× speedup) are presented without any description of experimental protocol, training details, dataset, number of runs, or statistical significance; this is load-bearing because the superiority assertion cannot be evaluated from the given information.
Authors: We agree that the abstract would benefit from additional context on the experimental setup to allow readers to better evaluate the claims. In the revised manuscript we will insert a concise clause noting the models (Wan-2.1-T2V 1.3B/14B), the distillation dataset, the evaluation benchmark (VBench), and that results are reported from the primary experimental runs with full protocol and training details provided in Section 4. Given typical abstract length limits we will keep the addition brief while ensuring the superiority statement is better grounded. revision: yes
-
Referee: [Abstract] Abstract: the mechanistic premise that DMD degradation stems specifically from absent relational constraints (and that matching pairwise matrices from existing scores will correct it without new failure modes) is asserted but not supported by ablations or controlled experiments isolating the copula term; this is load-bearing for the motivation and novelty of CoDMD.
Authors: The manuscript motivates the copula regularizer via analysis of DMD’s coordinate-wise objective and reverse-KL behavior (Section 3) and demonstrates empirical gains over DMD on the same teacher-student pairs. However, we did not include a controlled ablation that isolates the copula-matching term while holding all other loss components fixed. We acknowledge this weakens the causal claim. In the revision we will add an ablation study that removes only the copula regularizer (keeping the DMD objective and training protocol identical) and report the resulting VBench degradation to directly support the premise. revision: yes
Circularity Check
No significant circularity
full rationale
The paper traces DMD degradation to absent relational constraints and introduces CoDMD as a supplementary distributional objective that reuses already-computed teacher/fake scores to match pairwise relation matrices. This construction adds an independent regularizer without reducing the claimed VBench gains or speed-up to a fitted parameter renamed as prediction, a self-definitional equation, or a load-bearing self-citation chain. No uniqueness theorems, ansatzes smuggled via prior author work, or renaming of known results are invoked; the derivation chain from premise to method remains externally falsifiable via reported metrics on Wan-2.1 and comparisons to rCM/DMD baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Springer, 2006
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learning, volume 4. Springer, 2006
2006
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[4]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[5]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion, 2025. URLhttps://arxiv.org/abs/2506.08009
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[8]
Distribution matching distillation meets reinforcement learning
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Changsheng Lu, Zhen Li, et al. Distribution matching distillation meets reinforcement learning. arXiv preprint arXiv:2511.13649, 2025
-
[9]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[10]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Flow matching for generative modeling
Yaron Lipman et al. Flow matching for generative modeling. InICLR, 2023
2023
-
[12]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Instaflow: One step is enough for high- quality diffusion-based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high- quality diffusion-based text-to-image generation. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[14]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[16]
Ma, Xiaohua Xie, and Jian-Huang Lai
Yanzuo Lu, Yuxi Ren, Xin Xia, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Andy J. Ma, Xiaohua Xie, and Jian-Huang Lai. Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis, 2025. URLhttps://arxiv.org/abs/2507.18569
-
[17]
Dual-expert consistency model for efficient and high-quality video generation
Zhengyao Lv, Chenyang Si, Tianlin Pan, Zhaoxi Chen, Kwan-Yee K Wong, Yu Qiao, and Ziwei Liu. Dual-expert consistency model for efficient and high-quality video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14983–14993, 2025
2025
-
[18]
Springer, 2006
Roger B Nelsen.An introduction to copulas. Springer, 2006
2006
-
[19]
Relational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3967–3976, 2019
2019
-
[20]
Correlation congruence for knowledge distillation
Baoyun Peng, Xiao Jin, Jiaheng Liu, Dongsheng Li, Yichao Wu, Yu Liu, Shunfeng Zhou, and Zhaoning Zhang. Correlation congruence for knowledge distillation. InProceedings of the IEEE/CVF international conference on computer vision, pages 5007–5016, 2019. 10
2019
-
[21]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[22]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity. arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Fonctions de répartition à n dimensions et leurs marges
M Sklar. Fonctions de répartition à n dimensions et leurs marges. InAnnales de l’ISUP, volume 8, pages 229–231, 1959
1959
-
[25]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021
2021
-
[26]
Improved Techniques for Training Consistency Models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
2021
-
[28]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[29]
Learning to compare: Relation network for few-shot learning
Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. Learning to compare: Relation network for few-shot learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1199–1208, 2018
2018
-
[30]
Contrastive representation distillation.arXiv preprint arXiv:1910.10699, 2019
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation.arXiv preprint arXiv:1910.10699, 2019
-
[31]
Similarity-preserving knowledge distillation
Frederick Tung and Greg Mori. Similarity-preserving knowledge distillation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1365–1374, 2019
2019
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2305.16213 , year=
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolific- dreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.arXiv preprint arXiv:2305.16213, 2023
-
[34]
Diversity-Preserved Distribution Matching Distillation for Fast Visual Synthesis
Tianhe Wu, Ruibin Li, Lei Zhang, and Kede Ma. Diversity-preserved distribution matching distillation for fast visual synthesis.arXiv preprint arXiv:2602.03139, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
arXiv preprint arXiv:2502.15681 , year=
Yilun Xu, Weili Nie, and Arash Vahdat. One-step diffusion models withf-divergence distribution matching. arXiv preprint arXiv:2502.15681, 2025
-
[36]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[39]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[40]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025. 11
2025
-
[41]
Yuyang You, Yongzhi Li, Jiahui Li, Yadong Mu, Quan Chen, and Peng Jiang. Adaptive video distillation: Mitigating oversaturation and temporal collapse in few-step generation.arXiv preprint arXiv:2603.21864, 2026
-
[42]
Fast sampling of diffusion models with exponential integrator.arXiv preprint arXiv:2204.13902, 2022
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator.arXiv preprint arXiv:2204.13902, 2022
-
[43]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Kaiwen Zheng, Yuji Wang, Qianli Ma, Huayu Chen, Jintao Zhang, Yogesh Balaji, Jianfei Chen, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Large scale diffusion distillation via score-regularized continuous-time consistency.arXiv preprint arXiv:2510.08431, 2025. 12 Appendixfor Copula-aware Distribution Matching Distillation §AMore Visual Comparisons §BTraining ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.