Attacking the Trusted Imagination: Oracle-Level Integrity Attacks on Imagine-then-Act World Models
Pith reviewed 2026-06-26 08:55 UTC · model grok-4.3
The pith
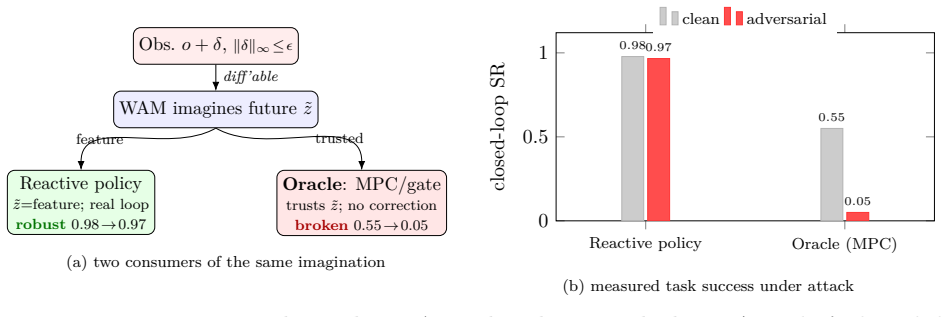
Small observation perturbations easily displace the imagined future in VLA policies, breaking systems that trust those predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
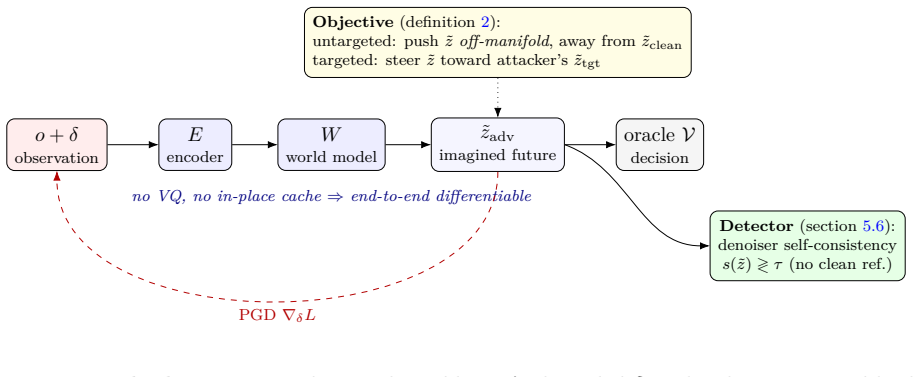
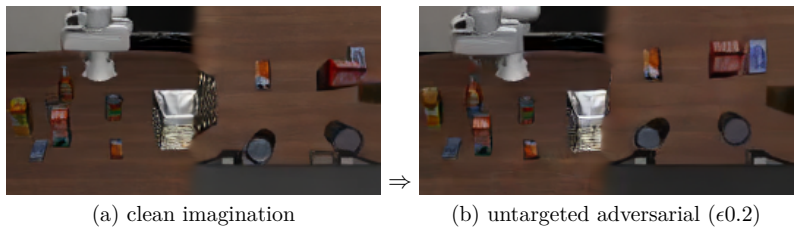
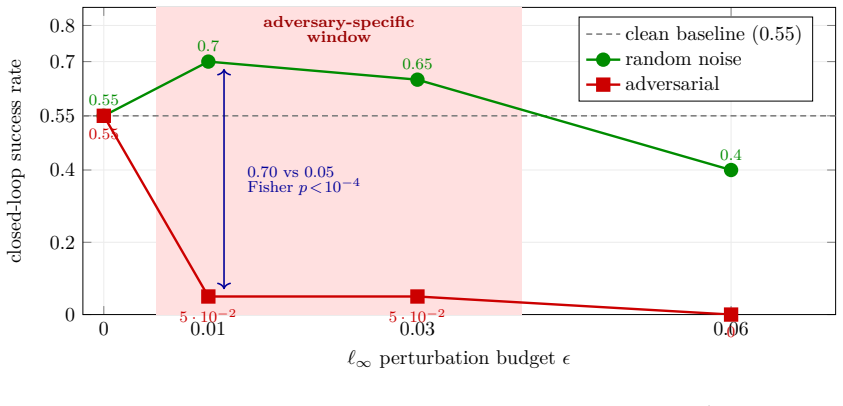
The paper establishes that the imagine-then-act design creates an asymmetry in which displacing the imagined latent trajectory z~ from its natural-future manifold requires only modest observation perturbations, while reaching a specific on-manifold target is bounded. Under a capability-based L-infinity observation threat model the attacker applies projected gradient descent directly through the observation-to-imagination map. Untargeted corruption is detected at AUC 1.0 and is roughly 60 times stronger than random; targeted control stays limited. A parameter-free denoiser detector works unless the attacker forgoes corruption. The reactive policy remains unaffected, but a native imagination-d
What carries the argument
The fully differentiable observation-to-imagination map, which lets an attacker apply projected gradient descent to displace the latent future trajectory z~ off its natural manifold.
If this is right
- Untargeted attacks on imagination succeed at rates roughly 60 times higher than random noise.
- A parameter-free denoiser detector identifies the corrupted imagination at AUC 1.0.
- An adaptive attacker can evade detection only by abandoning the corruption attempt.
- The reactive policy component stays robust, isolating failure to downstream consumers of the imagination such as MPC planners.
Where Pith is reading between the lines
- Systems that treat the imagined trajectory as an oracle input will require separate verification layers beyond policy robustness.
- The observed asymmetry suggests that defenses focused on precise targeting may be less urgent than defenses against any off-manifold displacement.
- Non-differentiable imagination modules or explicit manifold projection steps could limit the attack surface identified here.
Load-bearing premise
The map from input observations to the imagined latent trajectory is fully differentiable, allowing direct gradient-based attacks under bounded observation perturbations.
What would settle it
Measure whether an imagination-driven MPC planner on RynnVLA-002 or similar drops from 0.70 to 0.05 success rate at epsilon=0.01 under the described observation perturbations.
Figures

read the original abstract
Many recent vision-language-action (VLA) policies adopt an imagine-then-act design. A world-action model (WAM) first imagines a short future as a latent trajectory z~, on which the action is then conditioned. We identify this trusted imagination, rather than the reactive policy, as the exposed attack surface. A downstream oracle, such as a safety gate, a visual model-predictive-control (MPC) planner, or an imagine-then-check verifier, consumes z~ as a prediction of the future. The robustness of the policy therefore does not entail the robustness of systems that rely on the WAM. The underlying phenomenon is an asymmetry. Corrupting the imagination is easy, since it requires only displacing z~ from its natural-future manifold. Steering it precisely is hard, since it must reach a specified on-manifold target. We adopt a capability-based threat model with an L-infinity-bounded observation perturbation. The attacker applies projected gradient descent through the fully differentiable observation-to-imagination map. The same off-manifold property motivates a parameter-free denoiser detector. We evaluate three targets: RynnVLA-002, LingBot-VA, and LaDi-WM. Untargeted corruption is roughly 60x stronger than random and is detected at AUC 1.0. Targeted control remains bounded. An adaptive attacker evades detection only by forgoing corruption. The reactive policy remains robust to corrupted imagination. A native imagination-driven MPC, however, exhibits the first adversary-specific task failure (at epsilon=0.01, success 0.70 versus 0.05; Fisher p < 10^-4).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that imagine-then-act VLA policies expose their world model's latent imagination (z~) as an attack surface to oracle-level integrity attacks. It identifies an asymmetry—untargeted corruption of z~ off its natural manifold is easy while targeted on-manifold steering is hard—under an L-infinity observation perturbation threat model. The attacker uses PGD through the claimed fully differentiable observation-to-imagination map. Evaluations on RynnVLA-002, LingBot-VA, and LaDi-WM report untargeted corruption ~60x stronger than random with AUC 1.0 detection via a parameter-free denoiser, bounded targeted control, evasion only by forgoing corruption, robust reactive policies, and first adversary-specific failure in imagination-driven MPC (epsilon=0.01: success 0.70 vs. 0.05, Fisher p<10^-4).
Significance. If the empirical results hold, the work identifies a previously under-examined attack surface in emerging VLA architectures that separate imagination from action, with direct implications for safety oracles, MPC planners, and verifiers. The parameter-free denoiser detector and the explicit asymmetry between corruption and steering are concrete contributions. The multi-model evaluation and the MPC task-failure result provide falsifiable evidence that could guide defenses in robotics and planning systems.
major comments (2)
- [Abstract] Abstract: The central method relies on the claim that 'the attacker applies projected gradient descent through the fully differentiable observation-to-imagination map.' No verification is provided that the three evaluated models (RynnVLA-002, LingBot-VA, LaDi-WM) admit end-to-end gradients or that latent trajectory sampling introduces no non-differentiable operations. If gradients cannot flow, the reported untargeted success rates, 60x strength claim, AUC 1.0 detection, and MPC task failure cannot be produced by the described PGD procedure.
- [Abstract] Abstract (MPC result): The adversary-specific task failure in 'a native imagination-driven MPC' (success 0.70 versus 0.05 at epsilon=0.01, Fisher p<10^-4) is load-bearing for the practical significance of the asymmetry. The manuscript provides no description of the MPC implementation, how corrupted z~ is consumed by the planner, or the baseline success rate definition, preventing assessment of whether the failure is specific to the attack or an artifact of the planner design.
minor comments (1)
- [Abstract] The abstract reports concrete metrics (60x, AUC 1.0, p<10^-4) without referencing the corresponding tables, figures, or sections that contain the full experimental details, error bars, or statistical methods.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and the identification of areas where additional clarification is needed. We address the major comments below, agreeing that further details on differentiability and the MPC implementation are warranted and will be incorporated in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central method relies on the claim that 'the attacker applies projected gradient descent through the fully differentiable observation-to-imagination map.' No verification is provided that the three evaluated models (RynnVLA-002, LingBot-VA, LaDi-WM) admit end-to-end gradients or that latent trajectory sampling introduces no non-differentiable operations. If gradients cannot flow, the reported untargeted success rates, 60x strength claim, AUC 1.0 detection, and MPC task failure cannot be produced by the described PGD procedure.
Authors: We thank the referee for this important observation. The manuscript asserts that the observation-to-imagination map is fully differentiable for the evaluated models, but we acknowledge that explicit verification and details on the absence of non-differentiable operations in sampling are not provided. In the revised manuscript, we will add an appendix or section providing this verification for RynnVLA-002, LingBot-VA, and LaDi-WM, including confirmation that gradient flow is possible end-to-end and that sampling uses differentiable methods. This will substantiate the PGD-based attacks and the reported results. revision: yes
-
Referee: [Abstract] Abstract (MPC result): The adversary-specific task failure in 'a native imagination-driven MPC' (success 0.70 versus 0.05 at epsilon=0.01, Fisher p<10^-4) is load-bearing for the practical significance of the asymmetry. The manuscript provides no description of the MPC implementation, how corrupted z~ is consumed by the planner, or the baseline success rate definition, preventing assessment of whether the failure is specific to the attack or an artifact of the planner design.
Authors: We agree that the lack of detailed description of the MPC setup limits the interpretability of this key result. The revised manuscript will include a comprehensive description of the native imagination-driven MPC implementation, specifying how the corrupted latent trajectory z~ is consumed by the planner, the exact definition of success rates and baselines, and any other implementation details. This addition will enable readers to assess the specificity of the observed task failure to the attack. revision: yes
Circularity Check
No circularity: empirical attack results on differentiable maps
full rationale
The paper's core claims rest on direct empirical application of projected gradient descent through an explicitly assumed fully differentiable observation-to-imagination map, with results measured on three concrete models (RynnVLA-002, LingBot-VA, LaDi-WM). No equations, predictions, or first-principles derivations are presented that reduce to fitted parameters, self-definitions, or self-citation chains. The asymmetry between untargeted corruption and targeted steering is demonstrated via measured success rates and statistical tests rather than derived by construction from inputs. The differentiability assumption is stated outright as a threat-model premise and is not justified via any internal reduction or prior self-work. This is a standard empirical security evaluation with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RynnVLA-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Bohan Hou, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. RynnVLA-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Pith/arXiv arXiv 2025
-
[2]
Reinforcement learning-based resource reservation for mobile edge computing with probable failure
Qiuli Dai, Honglong Chen, Zhichen Ni, Yubin Yang, Linghan Chen, Xinglong Fan, and Xiangyu Li. Reinforcement learning-based resource reservation for mobile edge computing with probable failure. IEEE Transactions on Vehicular Technology, 74(5):7985–7996, 2025
2025
-
[3]
A dual stealthy backdoor: From both spatial and frequency perspectives.Proceedings of the AAAI Conference on Artificial Intelligence, 38(3):1851–1859, 2024
Yudong Gao, Honglong Chen, Peng Sun, Junjian Li, Anqing Zhang, Zhibo Wang, and Weifeng Liu. A dual stealthy backdoor: From both spatial and frequency perspectives.Proceedings of the AAAI Conference on Artificial Intelligence, 38(3):1851–1859, 2024
2024
-
[4]
Energy-based backdoor defense without task-specific samples and model retraining
Yudong Gao, Honglong Chen, Peng Sun, Zhe Li, Junjian Li, and Huajie Shao. Energy-based backdoor defense without task-specific samples and model retraining. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235 ofProceedings of Machine Learning Research, pages 14611–14637, 2024
2024
-
[5]
A triple stealthy backdoor: Hidden in spatial, frequency, and feature domains.IEEE Transactions on Dependable and Secure Computing, 22(6):7746–7758, 2025
Yudong Gao, Honglong Chen, Peng Sun, Junjian Li, Yangxu Yin, Zhibo Wang, and Weifeng Liu. A triple stealthy backdoor: Hidden in spatial, frequency, and feature domains.IEEE Transactions on Dependable and Secure Computing, 22(6):7746–7758, 2025
2025
-
[6]
SkillReducer: Optimizing LLM agent skills for token efficiency
Yudong Gao, Zongjie Li, Yuanyuan Yuan, Zimo Ji, Pingchuan Ma, and Shuai Wang. SkillReducer: Optimizing LLM agent skills for token efficiency. arXiv preprint arXiv:2603.29919, 2026
Pith/arXiv arXiv 2026
-
[7]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations (ICLR), 2015
2015
-
[8]
LaDi-WM: A latent diffusion-based world model for predictive manipulation
Yuhang Huang, Jiazhao Zhang, Shilong Zou, Xinwang Liu, Ruizhen Hu, and Kai Xu. LaDi-WM: A latent diffusion-based world model for predictive manipulation. InConference on Robot Learning (CoRL), 2025. arXiv:2505.11528; PMLR vol. 305
arXiv 2025
-
[9]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[10]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning (CoRL), 2024. arXiv:2405.05941
Pith/arXiv arXiv 2024
-
[11]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks, 2023. 12
2023
-
[12]
JailWAM: Jailbreaking world action models in robot control.arXiv preprint arXiv:2604.05498, 2026
Hanqing Liu, Songping Wang, Jiahuan Long, Jiacheng Hou, Jialiang Sun, Chao Li, Yang Yang, Wei Peng, Xu Liu, Tingsong Jiang, Wen Yao, and Yao Mu. JailWAM: Jailbreaking world action models in robot control.arXiv preprint arXiv:2604.05498, 2026
Pith/arXiv arXiv 2026
-
[13]
To- wards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. To- wards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[14]
James C. Spall. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE Transactions on Automatic Control, 37(3):332–341, 1992
1992
-
[15]
Defending against attribute inference attacks in post-training of recommendation systems via unlearning
Wenhan Wu, Yili Gong, Jiawei Jiang, Chuang Hu, Xiaobo Zhou, and Dazhao Cheng. Defending against attribute inference attacks in post-training of recommendation systems via unlearning. In2025 IEEE 41st International Conference on Data Engineering (ICDE), pages 2656–2669, 2025
2025
-
[16]
Mimir: Data-free federated unlearning through client-specific prompt generation for personalized models.IEEE Transactions on Mobile Computing, 24(10):10537–10556, 2025
Wenhan Wu, Huanghuang Liang, Tianyu Tu, Jiawei Jiang, Chuang Hu, and Dazhao Cheng. Mimir: Data-free federated unlearning through client-specific prompt generation for personalized models.IEEE Transactions on Mobile Computing, 24(10):10537–10556, 2025
2025
-
[17]
Jimiao Yu, Honglong Chen, Junjian Li, Linghan Chen, Yudong Gao, Weifeng Liu, and Lei Zhang. Black-box adversarial defense based on image decomposition and reconstruction.IEEE Transactions on Multimedia, 27:5909–5921, 2025. doi: 10.1109/TMM.2025.3565987
-
[18]
Do world action models generalize better than VLAs? a robustness study
Zhanguang Zhang, Zhiyuan Li, Behnam Rahmati, Rui Heng Yang, Yintao Ma, Amir Rasouli, Sajjad Pakdamansavoji, Yangzheng Wu, Lingfeng Zhang, Tongtong Cao, Feng Wen, Xinyu Wang, Xingyue Quan, and Yingxue Zhang. Do world action models generalize better than VLAs? a robustness study. arXiv preprint arXiv:2603.22078, 2026. 13
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.