RE4: Transformation-aware Imitation of Object Interactions Using Manipulation Modes
Pith reviewed 2026-06-26 00:03 UTC · model grok-4.3
The pith
RE4 composes self-supervised pose estimation with mode-aware retrieval, transformation, replanning, and rollout to imitate object interactions while preserving interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
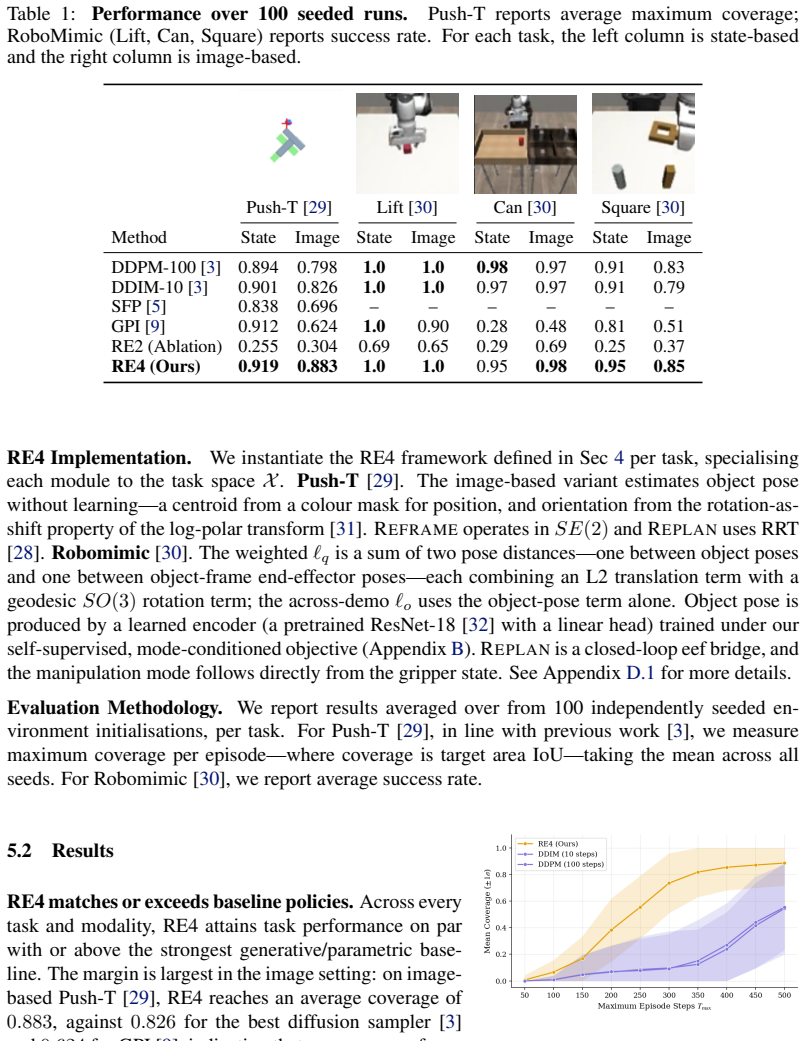
The RE4 framework consists of model-free pose estimation trained via self-supervision over the demonstration data, followed by mode-aware retrieval of a demonstration, a mode-aware transformation, a replan step that connects to the retrieval point while preserving mode constraints, and rollout of the transformed demonstration; this composition is shown to work on state-based and image-based versions of Push-T and Robomimic, including an adversarial sparse-data benchmark.
What carries the argument
The RE4 sequence of four steps: self-supervised pose estimation informing mode-aware retrieval and transformation, followed by constraint-preserving replan and rollout.
If this is right
- RE4 achieves results on both state and image observations across Push-T and Robomimic benchmarks.
- The framework shows robustness on an adversarial benchmark targeting sparse data regions in image-based Push-T.
- Low-data regime experiments further support the approach.
- The method retains interpretability through its use of simple, explicit building blocks.
Where Pith is reading between the lines
- The modular design could be extended by swapping in other pose estimators or mode definitions for new manipulation domains.
- The emphasis on explicit modes may connect to planning methods that reason over discrete interaction types.
- If the pose estimation step scales, the same pipeline might apply to tasks with partial observability beyond the current benchmarks.
Load-bearing premise
Self-supervised pose estimation trained only on the demonstration data will be accurate and robust enough to support reliable mode-aware retrieval and transformation without introducing errors that break later steps.
What would settle it
Frequent failures in mode retrieval or task success caused by pose estimation errors on the image-based Push-T or Robomimic test sets.
Figures


read the original abstract
Object interaction tasks have been a focus of advances in imitation learning. End-to-end methods, dominated by diffusion and flow-based variants have shown leaps in performance while sacrificing interpretability. Object-centric and pose-informed variants have had a role in learning from demonstration in manipulation tasks. In this paper, we revisit a few modern imitation learning benchmarks for object interactions, with the aim of composing a framework that repurposes principled theories of manipulation, preserving both performance and interpretability. For image observations, lightweight training is proposed for model-free pose estimation of the target object, using self-supervision over the demonstration data available for imitation learning. This information is then used to inform a manipulation mode-aware retrieval of a demonstration, a mode-aware transformation, a replan step that connects to the retrieval point while preserving mode constraints, and finally rolling out the transformed demonstration. These compose four key steps of the proposed RE4 framework, evaluated over state-based and image-based benchmarks in Push-T and Robomimic. An adversarial benchmark that evaluates sparse data regions of image-based Push-T showcases the robustness, further bolstered by indications from low-data regime experiments. The current work shows promise in using simple interpretable building blocks to learn manipulation skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the RE4 framework for imitation learning on object interaction tasks. It composes four steps for image observations: lightweight self-supervised model-free pose estimation trained only on the available demonstration trajectories, mode-aware retrieval of a demonstration, mode-aware rigid transformation of the demonstration, and a replan step that reconnects to the retrieval point while preserving mode constraints, followed by rollout. The approach is evaluated on state- and image-based Push-T and Robomimic benchmarks, including an adversarial sparse-data subset of image-based Push-T and low-data regimes, with the claim that the modular, interpretable pipeline achieves robustness without sacrificing performance relative to end-to-end diffusion methods.
Significance. If the quantitative results and ablations hold, the work would demonstrate that simple, theory-grounded building blocks (pose estimation + mode-aware retrieval/transformation) can deliver competitive manipulation performance with greater interpretability than black-box policies. The explicit testing on adversarial sparse-data regions and low-data regimes would be a strength, as would the avoidance of learned dynamics or heavy end-to-end training.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the central robustness claim for the full pipeline rests on the self-supervised pose estimator being sufficiently accurate on the same limited demonstration data used for imitation. No pose-estimation error metrics, success-rate breakdowns conditioned on pose accuracy, or error-propagation analysis are reported; without these, it is impossible to verify that pose errors do not corrupt mode selection and the subsequent transformation step.
- [§3] §3 (RE4 Framework): the replan step is described as preserving mode constraints rather than correcting upstream pose-induced errors. If the mode definitions have limited tolerance (as implied by the adversarial benchmark), any unquantified pose error directly undermines the interpretability and performance claims; an ablation isolating pose accuracy from end-to-end success is required.
minor comments (2)
- [§3] Notation for manipulation modes and the exact form of the mode-aware transformation should be formalized with equations rather than prose descriptions.
- [§3] The abstract mentions 'lightweight training' for pose estimation; the precise self-supervision loss and network architecture need to be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit validation of the pose estimator's accuracy and its impact on the pipeline. We agree that these elements are important for substantiating the robustness claims and will revise the manuscript accordingly. Below we address each major comment point by point.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central robustness claim for the full pipeline rests on the self-supervised pose estimator being sufficiently accurate on the same limited demonstration data used for imitation. No pose-estimation error metrics, success-rate breakdowns conditioned on pose accuracy, or error-propagation analysis are reported; without these, it is impossible to verify that pose errors do not corrupt mode selection and the subsequent transformation step.
Authors: We agree that the absence of these metrics limits verification of the claims. In the revised version we will add, in §4, quantitative pose-estimation error metrics (mean translation/rotation error on held-out demonstration trajectories), success-rate tables conditioned on pose-accuracy bins, and a short error-propagation discussion showing how pose deviations affect mode retrieval and rigid transformation. These additions will directly support the robustness statements in the abstract and evaluation section. revision: yes
-
Referee: [§3] §3 (RE4 Framework): the replan step is described as preserving mode constraints rather than correcting upstream pose-induced errors. If the mode definitions have limited tolerance (as implied by the adversarial benchmark), any unquantified pose error directly undermines the interpretability and performance claims; an ablation isolating pose accuracy from end-to-end success is required.
Authors: We acknowledge that the current §3 description focuses on mode preservation without explicitly quantifying upstream pose effects. We will revise the text in §3 to clarify how the replan step interacts with potential pose-induced mode mismatches. In addition, we will include in §4 an ablation that isolates pose accuracy (by injecting controlled noise into estimated poses and measuring end-to-end success) to demonstrate the framework's sensitivity and robustness under the adversarial sparse-data conditions. revision: yes
Circularity Check
No circularity: RE4 is a procedural composition of standard imitation steps with no self-referential reductions
full rationale
The paper presents RE4 as a four-step pipeline (self-supervised pose estimation on demo data, mode-aware retrieval, mode-aware transformation, replan+rollout) evaluated on Push-T and Robomimic. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The pose estimation is described as lightweight self-supervision over available demonstrations, which is a standard technique and does not reduce the overall framework output to its inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. T. Mason. Toward robotic manipulation.Annual Review of Control, Robotics, and Au- tonomous Systems, 1(1):1–28, 2018
2018
-
[2]
Correia and L
A. Correia and L. A. Alexandre. A survey of demonstration learning.Robotics and Au- tonomous Systems, 182:104812, 2024
2024
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
2024
-
[4]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt. Equivariant diffusion policy. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=wD2kUVLT1g
2024
-
[5]
Jiang, X
S. Jiang, X. Fang, N. Roy, T. Lozano-P ´erez, L. P. Kaelbling, and S. Ancha. Streaming flow policy: Simplifying diffusion/flow policies by treating robot trajectories as flow trajectories. InICRA 2025 Workshop: Beyond Pick and Place, 2025. URLhttps://openreview.net/ forum?id=ay5lYpmywr
2025
-
[6]
Bonnaire, R
T. Bonnaire, R. Urfin, G. Biroli, and M. M ´ezard. Why diffusion models don’t memorize: The role of implicit dynamical regularization in training.Advances in Neural Information Processing Systems, 38:141266–141286, 2026
2026
- [7]
-
[8]
Vitiello, K
P. Vitiello, K. Dreczkowski, and E. Johns. One-shot imitation learning: A pose estimation per- spective. In7th Annual Conference on Robot Learning, 2023. URLhttps://openreview. net/forum?id=w5ONmpgnfG
2023
- [9]
-
[10]
Kuffner and J
J. Kuffner and J. Xiao. Motion for manipulation tasks. InSpringer Handbook of Robotics, pages 897–930. Springer, 2016
2016
-
[11]
Hauser and J.-C
K. Hauser and J.-C. Latombe. Multi-modal motion planning in non-expansive spaces.The International Journal of Robotics Research, 29(7):897–915, 2010
2010
-
[12]
Kingston, M
Z. Kingston, M. Moll, and L. E. Kavraki. Decoupling constraints from sampling-based plan- ners. InRobotics Research: The 18th International Symposium ISRR, pages 913–928. Springer, 2019
2019
-
[13]
Dogar and S
M. Dogar and S. Srinivasa. A framework for push-grasping in clutter.Robotics: Science and systems VII, 1:65–72, 2011
2011
-
[14]
E. R. Vieira, D. Nakhimovich, K. Gao, R. Wang, J. Yu, and K. E. Bekris. Persistent homology for effective non-prehensile manipulation. In2022 International Conference on Robotics and Automation (ICRA), pages 1918–1924. IEEE, 2022
1918
-
[15]
Kingston, C
Z. Kingston, C. Chamzas, and L. E. Kavraki. Using experience to improve constrained plan- ning on foliations for multi-modal problems. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6922–6927. IEEE, 2021
2021
-
[16]
A. J. Ijspeert, J. Nakanishi, H. Hoffmann, P. Pastor, and S. Schaal. Dynamical movement primitives: learning attractor models for motor behaviors.Neural computation, 25(2):328– 373, 2013. 9
2013
-
[17]
Sobti, R
S. Sobti, R. Shome, S. Chaudhuri, and L. E. Kavraki. A sampling-based motion planning framework for complex motor actions. In2021 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS), pages 6928–6934. IEEE, 2021
2021
-
[18]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[19]
H. Shen, J. Zhang, B. Xiong, R. Hu, S. Chen, Z. Wan, X. Wang, Y . Zhang, Z. Gong, G. Bao, C. Tao, Y . Huang, Y . Yuan, and M. Zhang. Efficient diffusion models: A survey.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/ forum?id=wHECkBOwyt. Survey Certification
2025
-
[20]
Prasad, K
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation. InRobotics: Science and Systems, 2024
2024
-
[21]
J. Pari, N. Shafiullah, S. Arunachalam, and L. Pinto. The surprising effectiveness of represen- tation learning for visual imitation. 06 2022. doi:10.15607/RSS.2022.XVIII.010
-
[22]
Di Palo and E
N. Di Palo and E. Johns. On the effectiveness of retrieval, alignment, and replay in manipula- tion.IEEE Robotics and Automation Letters, 9(3):2032–2039, 2024
2032
-
[23]
Huang, J
Y . Huang, J. Silv ´erio, L. Rozo, and D. G. Caldwell. Generalized task-parameterized skill learning. In2018 IEEE international conference on robotics and automation (ICRA), pages 5667–5674. IEEE, 2018
2018
-
[24]
Franzese, R
G. Franzese, R. Prakash, C. Della Santina, and J. Kober. Generalizable motion policies through keypoint parameterization and transportation maps.IEEE Transactions on Robotics, 2025
2025
-
[25]
Sosa and D
J. Sosa and D. Hogg. Self-supervised 3d human pose estimation from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4788–4797, 2023
2023
-
[26]
T. Pan, R. Shome, and L. E. Kavraki. Task and motion planning for execution in the real.IEEE Transactions on Robotics, 40:3356–3371, 2024
2024
-
[27]
Shome, W
R. Shome, W. N. Tang, C. Song, C. Mitash, H. Kourtev, J. Yu, A. Boularias, and K. E. Bekris. Towards robust product packing with a minimalistic end-effector. InIEEE International Con- ference on Robotics and Automation (ICRA), 2019
2019
-
[28]
S. M. LaValle and J. J. Kuffner Jr. Randomized kinodynamic planning.The international journal of robotics research, 20(5):378–400, 2001
2001
-
[29]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mor- datch, and J. Tompson. Implicit behavioral cloning. InConference on robot learning, pages 158–168. PMLR, 2022
2022
-
[30]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[31]
Wolberg and S
G. Wolberg and S. Zokai. Robust image registration using log-polar transform. URLhttp: //www-cs.engr.ccny.cuny.edu/~wolberg/pub/icip00.pdf
-
[32]
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. InEuropean conference on computer vision, pages 630–645. Springer, 2016
2016
-
[33]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019. 10
2019
-
[34]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[35]
Sridhar, S
K. Sridhar, S. Dutta, D. Jayaraman, J. Weimer, and I. Lee. Memory-consistent neural networks for imitation learning. InInternational Conference on Learning Representations, volume 2024, pages 45160–45185, 2024. 11 A RE4 Algorithms Algorithm 2REFRAME Require:framej ⋆ with(o j⋆ , x j⋆ , a j⋆ 1:h); queryqwith(o q, x q); modem 1:δ←o q (oj⋆ )−1 ▷object-pose de...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.