HiFiVe: High-Fidelity Vehicle Generation Leveraging Auto-Regressive 2D Generative Priors
Pith reviewed 2026-06-30 09:40 UTC · model grok-4.3
The pith
Coarse 3D geometry anchors 2D generative priors in an auto-regressive pipeline to produce consistent high-resolution vehicle textures and refined meshes from arbitrary viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
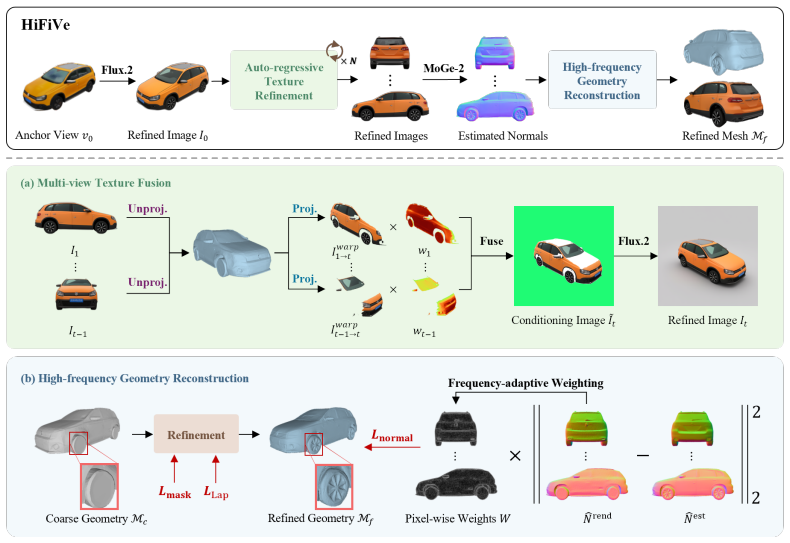
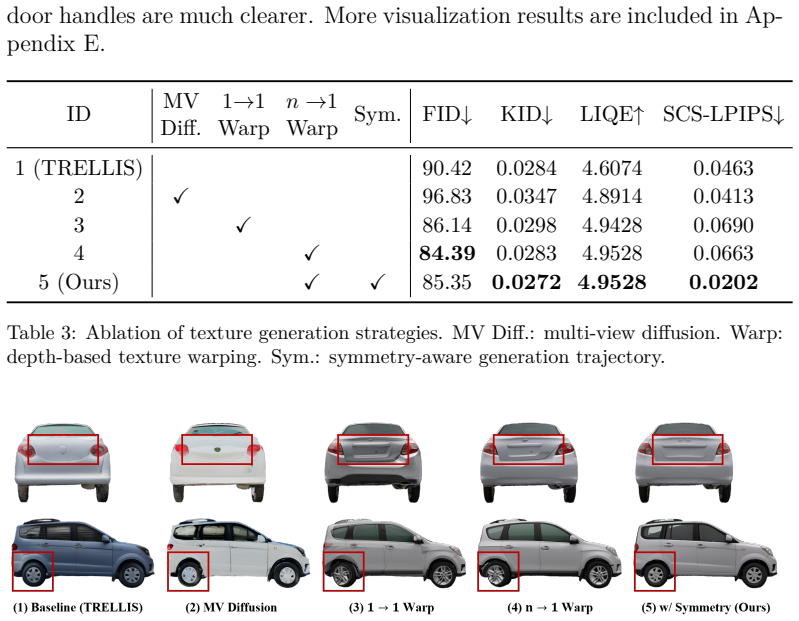
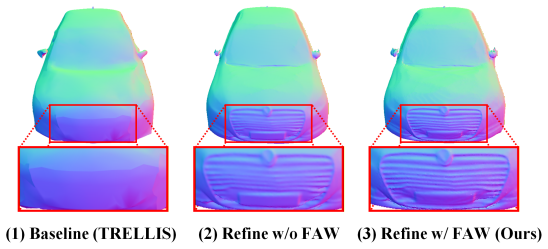
The central claim is that imposing 3D geometric constraints anchors 2D generative priors so that an auto-regressive texture refinement pipeline, synchronized by depth-based warping and multi-view fusion on the coarse geometry, plus symmetry exploitation and normal-map mesh refinement, yields vehicle models with measurably better geometric detail and texture quality than prior methods on both synthetic and real-world datasets.
What carries the argument
The auto-regressive texture refinement pipeline that conditions each new high-resolution view on prior frames through depth-based warping and multi-view texture fusion, with the coarse geometry serving as the synchronization anchor.
If this is right
- Textures can be generated at high resolution from arbitrary viewpoints while cross-view consistency is maintained through the warping and fusion mechanism.
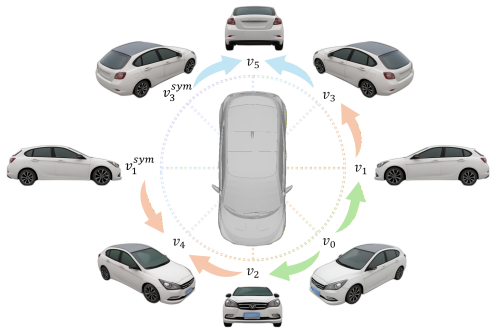
- Error buildup across sequential views is reduced by exploiting the left-right symmetry typical of vehicles.
- High-frequency surface details become recoverable on the final mesh once normal maps are estimated from the refined textures.
- The same pipeline delivers measurable gains on both synthetic and real-world vehicle data without requiring per-dataset retraining.
Where Pith is reading between the lines
- The same synchronization idea could be tested on other rigid objects that have approximate symmetry, such as furniture or mechanical parts, to see whether the vehicle-specific symmetry step is essential.
- If the coarse geometry comes from single-image reconstruction instead of multi-view input, the method might still produce usable results, opening a path to lighter data requirements.
- Downstream rendering or physics simulation pipelines could accept these models directly because the texture and geometry improvements are produced in one pass rather than as separate post-processing stages.
Load-bearing premise
The coarse geometry is accurate enough to serve as a reliable synchronization prior that keeps each new texture generation step consistent with earlier ones without any fine-tuning or fixed viewpoints.
What would settle it
Producing a set of output models in which texture seams or blurring remain visible across viewpoints even after the warping and fusion steps would indicate that the coarse geometry failed to provide sufficient synchronization.
Figures




read the original abstract
Existing 3D vehicle generation methods often suffer from low geometric fidelity and blurry textures, hindering their downstream applications. While recent works adopt multi-view diffusion models for high-fidelity texture, they are often constrained by fixed viewpoints, limited resolution, and a reliance on costly fine-tuning to achieve cross-view consistency. In this paper, we propose HiFiVe, a training-free framework for high-fidelity vehicle modeling through joint texture and geometry enhancement by imposing 3D geometric constraints to anchor 2D generative priors. Specifically, we propose an auto-regressive texture refinement pipeline that progressively synthesizes high-resolution textures from arbitrary viewpoints. To ensure cross-view consistency, the coarse geometry serves as a synchronization prior, conditioning each generation step on previously synthesized frames via depth-based warping and multi-view texture fusion. Moreover, the inherent symmetry of vehicles is exploited to mitigate error accumulation. Finally, high-frequency surface details are recovered by refining the mesh geometry using normal maps estimated from the enhanced textures. Extensive experiments on synthetic and real-world vehicle datasets demonstrate that our method significantly improves both geometric detail and texture quality compared to state-of-the-art baselines. Project page: https://honglixiao.github.io/hifive.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HiFiVe, a training-free framework for high-fidelity 3D vehicle modeling. It introduces an auto-regressive texture refinement pipeline that progressively synthesizes high-resolution textures from arbitrary viewpoints. Coarse geometry acts as a synchronization prior, conditioning each generation step on prior frames via depth-based warping and multi-view texture fusion; vehicle symmetry mitigates error accumulation. High-frequency surface details are recovered by refining mesh geometry using normal maps estimated from the enhanced textures. Extensive experiments on synthetic and real-world vehicle datasets are claimed to show significant improvements in geometric detail and texture quality over state-of-the-art baselines.
Significance. If the central mechanism holds without fine-tuning, the approach would be significant for 3D generation by anchoring 2D generative priors with lightweight 3D constraints, avoiding fixed viewpoints and costly adaptation. The auto-regressive design combined with symmetry exploitation represents a practical strength for consistent multi-view synthesis in the vehicle domain.
major comments (2)
- [Method (auto-regressive pipeline and consistency mechanism)] The central claim that the method is training-free and achieves cross-view consistency rests on the assumption that coarse geometry provides a reliable synchronization prior via depth-based warping and multi-view fusion (described in the method overview and pipeline). No ablations or sensitivity tests are reported that isolate performance under realistic depth errors typical of SfM or monocular estimates on real data, which directly bears on whether the warping produces usable conditioning signals without drift or holes.
- [Abstract and Experiments] The abstract states that 'extensive experiments ... demonstrate that our method significantly improves both geometric detail and texture quality' yet supplies no quantitative metrics, baselines, dataset sizes, or error bars in the provided description; without these in the experiments section, the magnitude and statistical reliability of the claimed gains cannot be assessed.
minor comments (2)
- [Method] Notation for the warping and fusion steps could be clarified with a diagram or pseudocode to make the conditioning process explicit.
- [Abstract] The project page is referenced but no mention of code or model release; adding this would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [Method (auto-regressive pipeline and consistency mechanism)] The central claim that the method is training-free and achieves cross-view consistency rests on the assumption that coarse geometry provides a reliable synchronization prior via depth-based warping and multi-view fusion (described in the method overview and pipeline). No ablations or sensitivity tests are reported that isolate performance under realistic depth errors typical of SfM or monocular estimates on real data, which directly bears on whether the warping produces usable conditioning signals without drift or holes.
Authors: We agree that explicit sensitivity analysis to depth errors is a valuable addition. While our real-world experiments rely on estimated depths from SfM/monocular methods, we did not isolate this factor with controlled noise ablations. We will add such tests in the revision, reporting performance under increasing depth perturbation levels to quantify robustness of the warping and fusion steps. revision: yes
-
Referee: [Abstract and Experiments] The abstract states that 'extensive experiments ... demonstrate that our method significantly improves both geometric detail and texture quality' yet supplies no quantitative metrics, baselines, dataset sizes, or error bars in the provided description; without these in the experiments section, the magnitude and statistical reliability of the claimed gains cannot be assessed.
Authors: The current experiments section emphasizes qualitative comparisons and visual results on synthetic and real datasets. To address the request for quantitative support, we will expand the experiments section with specific metrics (e.g., texture quality scores and geometric fidelity measures), explicit baseline names, dataset sizes, and error bars. The abstract will be revised to reference these quantitative outcomes. revision: yes
Circularity Check
No circularity: method pipeline is self-contained with no reductions to fitted inputs or self-citations
full rationale
The paper presents a descriptive pipeline for auto-regressive texture refinement conditioned on coarse geometry via depth warping and fusion, plus symmetry exploitation and normal-map refinement. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or method summary. The central claim rests on the described synchronization prior and experimental validation rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for a methods paper whose contributions are algorithmic rather than theorem-based.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Liu, H. Yu, B. Zou, J. Lyu, Q. Mei, J. Chen, H. Ma, Protocar: Learning 3d vehicle prototypes from single-view and unconstrained driv- ing scene images, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 5460–5468
2025
-
[2]
Z. Yang, J. Wang, H. Zhang, S. Manivasagam, Y. Chen, R. Urtasun, Genassets: Generating in-the-wild 3d assets in latent space, in: Pro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22392–22403
2025
-
[3]
X. Li, Y. Zhang, X. Ye, Drivingdiffusion: layout-guided multi-view driv- ing scenarios video generation with latent diffusion model, in: European Conference on Computer Vision, Springer, 2024, pp. 469–485
2024
-
[4]
Z. Yang, Y. Chen, J. Wang, S. Manivasagam, W.-C. Ma, A. J. Yang, R. Urtasun, Unisim: A neural closed-loop sensor simulator, in: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1389–1399
2023
-
[5]
Z. Zhao, Z. Lai, Q. Lin, Y. Zhao, H. Liu, S. Yang, Y. Feng, M. Yang, S. Zhang, X. Yang, et al., Hunyuan3d 2.0: Scaling diffusion mod- els for high resolution textured 3d assets generation, arXiv preprint arXiv:2501.12202 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Z. Lai, Y. Zhao, H. Liu, Z. Zhao, Q. Lin, H. Shi, X. Yang, M. Yang, S. Yang, Y. Feng, et al., Hunyuan3d 2.5: Towards high-fidelity 3d as- sets generation with ultimate details, arXiv preprint arXiv:2506.16504 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkuehler, G. Drettakis, 3d gaussian splat- ting for real-time radiance field rendering, ACM Transactions on Graph- ics (TOG) 42 (4) (2023) 1–14
2023
-
[8]
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, Z. Liu, Lgm: Large multi-view gaussian model for high-resolution 3d content creation, in: European Conference on Computer Vision, Springer, 2024, pp. 1–18
2024
-
[9]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, Ad- vances in neural information processing systems 33 (2020) 6840–6851. 30
2020
-
[10]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High- resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2022, pp. 10684–10695
2022
-
[11]
Poole, A
B. Poole, A. Jain, J. T. Barron, B. Mildenhall, Dreamfusion: Text- to-3d using 2d diffusion, in: The Eleventh International Conference on Learning Representations, 2023
2023
-
[12]
Long, Y.-C
X. Long, Y.-C. Guo, C. Lin, Y. Liu, Z. Dou, L. Liu, Y. Ma, S.-H. Zhang, M. Habermann, C. Theobalt, et al., Wonder3d: Single image to 3d using cross-domain diffusion, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9970–9980
2024
-
[13]
Structured 3D Latents for Scalable and Versatile 3D Generation
J. Xiang, Z. Lv, S. Xu, Y. Deng, R. Wang, B. Zhang, D. Chen, X. Tong, J. Yang, Structured 3d latents for scalable and versatile 3d generation, arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
R. Chen, Y. Chen, N. Jiao, K. Jia, Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation, in: Pro- ceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 22246–22256
2023
- [15]
-
[16]
Deitke, D
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, A. Farhadi, Objaverse: A universe of annotated 3d objects, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13142–13153
2023
-
[17]
Deitke, R
M. Deitke, R. Liu, M. Wallingford, H. Ngo, O. Michel, A. Kusupati, A. Fan, C. Laforte, V. Voleti, S. Y. Gadre, et al., Objaverse-xl: A universeof10m+3dobjects, AdvancesinNeuralInformationProcessing Systems 36 (2023) 35799–35813
2023
-
[18]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, et al., Scaling rectified flow transformers for high-resolution image synthesis, in: Forty-first interna- tional conference on machine learning, 2024. 31
2024
-
[19]
B. F. Labs, Flux,https://github.com/black-forest-labs/flux (2024)
2024
-
[20]
Y. Yang, X. Long, Z. Dou, C. Lin, Y. Liu, Q. Yan, Y. Ma, H. Wang, Z. Wu, W. Yin, Wonder3d++: Cross-domain diffusion for high-fidelity 3d generation from a single image, IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2025)
2025
- [21]
-
[22]
B. F. Labs, FLUX.2: Frontier Visual Intelligence, https://bfl.ai/blog/flux-2(2025)
2025
-
[23]
X. Shen, Y. Zhou, Y.-H. Yuan, X. Yang, L. Lan, Y. Zheng, Contrastive transformer hashing for compact video representation, IEEE Transac- tions on Image Processing 32 (2023) 5992–6003
2023
-
[24]
X. Shen, Y. Chen, W. Liu, Y. Zheng, Q.-S. Sun, S. Pan, Graph convolu- tional multi-label hashing for cross-modal retrieval, IEEE Transactions on Neural Networks and Learning Systems 36 (5) (2024) 7997–8009
2024
-
[25]
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y. Liu, T.-Y. Lin, Magic3d: High-resolution text-to-3d content creation, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2023, pp. 300–309
2023
-
[26]
G. Qian, J. Mai, A. Hamdi, J. Ren, A. Siarohin, B. Li, H.-Y. Lee, I. Skorokhodov, P. Wonka, S. Tulyakov, et al., Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors, in: The Twelfth International Conference on Learning Representations
-
[27]
Z. Zhou, S. Tulsiani, Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12588–12597
2023
-
[28]
X. Shen, Y. Tang, Y. Zheng, Y.-H. Yuan, Q.-S. Sun, Unsupervised mul- tiview distributed hashing for large-scale retrieval, IEEE Transactions on Circuits and Systems for Video Technology 32 (12) (2022) 8837–8848. 32
2022
-
[29]
X. Shen, W. Wu, X. Wang, Y. Zheng, Multiple riemannian kernel hash- ing for large-scale image set classification and retrieval, IEEE Transac- tions on Image Processing 33 (2024) 4261–4273
2024
-
[30]
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, C. Vondrick, Zero-1-to-3: Zero-shot one image to 3d object, in: Proceedings of the IEEE/CVFinternationalconferenceoncomputervision, 2023, pp.9298– 9309
2023
-
[31]
Y. Shi, P. Wang, J. Ye, L. Mai, K. Li, X. Yang, Mvdream: Multi-view diffusion for 3d generation, arXiv:2308.16512 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
S. Tang, J. Chen, D. Wang, C. Tang, F. Zhang, Y. Fan, V. Chan- dra, Y. Furukawa, R. Ranjan, Mvdiffusion++: A dense high-resolution multi-viewdiffusionmodelforsingleorsparse-view3dobjectreconstruc- tion, in: European Conference on Computer Vision, Springer, 2024, pp. 175–191
2024
- [33]
-
[34]
B. Shen, X. Yan, C. R. Qi, M. Najibi, B. Deng, L. Guibas, Y. Zhou, D. Anguelov, Gina-3d: Learning to generate implicit neural assets in the wild, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4913–4926
2023
-
[35]
X. Du, H. Sun, M. Lu, T. Zhu, X. Yu, Dreamcar: Leveraging car- specific prior for in-the-wild 3d car reconstruction, IEEE Robotics and Automation Letters (2024)
2024
-
[36]
T. Liu, H. Zhao, Y. Yu, G. Zhou, M. Liu, Car-studio: Learning car radiance fields from single-view and unlimited in-the-wild images, IEEE Robotics and Automation Letters (2024)
2024
- [37]
-
[38]
Zheng, A
C. Zheng, A. Vedaldi, Free3d: Consistent novel view synthesis without 3d representation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9720–9731. 33
2024
- [39]
-
[40]
Laine, J
S. Laine, J. Hellsten, T. Karras, Y. Seol, J. Lehtinen, T. Aila, Modular primitives for high-performance differentiable rendering, ACM Transac- tions on Graphics 39 (6) (2020)
2020
-
[41]
R. Wang, S. Xu, Y. Dong, Y. Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, J. Yang, Moge-2: Accurate monocular geometry with metric scale and sharp details, arXiv preprint arXiv:2507.02546 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
-
[43]
J. Xu, W. Cheng, Y. Gao, X. Wang, S. Gao, Y. Shan, Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models, arXiv preprint arXiv:2404.07191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
T. Hunyuan3D, S. Yang, M. Yang, Y. Feng, X. Huang, S. Zhang, Z. He, D. Luo, H. Liu, Y. Zhao, et al., Hunyuan3d 2.1: From images to high- fidelity 3d assets with production-ready pbr material, arXiv preprint arXiv:2506.15442 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Xiang, Z
J. Xiang, Z. Lv, S. Xu, Y. Deng, R. Wang, B. Zhang, D. Chen, X. Tong, J. Yang, Structured 3d latents for scalable and versatile 3d generation, in: Proceedings of the Computer Vision and Pattern Recognition Con- ference, 2025, pp. 21469–21480
2025
-
[46]
M. Bińkowski, D. J. Sutherland, M. Arbel, A. Gretton, Demystifying mmd gans, arXiv preprint arXiv:1801.01401 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
S. Yang, T. Wu, S. Shi, S. Lao, Y. Gong, M. Cao, J. Wang, Y. Yang, Maniqa: Multi-dimensionattentionnetworkforno-referenceimagequal- ity assessment, in: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2022, pp. 1191–1200. 34
2022
-
[48]
Zhang, G
W. Zhang, G. Zhai, Y. Wei, X. Yang, K. Ma, Blind image quality assess- ment via vision-language correspondence: A multitask learning perspec- tive, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 14071–14081
2023
-
[49]
L. Xue, M. Gao, C. Xing, R. Martín-Martín, J. Wu, C. Xiong, R. Xu, J. C. Niebles, S. Savarese, Ulip: Learning a unified representation of lan- guage, images, and point clouds for 3d understanding, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 1179–1189
2023
- [50]
-
[51]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreason- able effectiveness of deep features as a perceptual metric, in: Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
- [52]
-
[53]
N. Ryu, J. Won, J. Son, M. Gong, J.-H. Lee, S. Cho, Elevating 3d mod- els: High-quality texture and geometry refinement from a low-quality model, in: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, 2025, pp. 1–12. 35
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.