MAPL: Multi-Objective Preference Learning for Robot Locomotion
Pith reviewed 2026-06-25 21:09 UTC · model grok-4.3
The pith
MAPL learns quadruped locomotion policies from LLM preferences on multiple generic objectives that match or exceed expert-designed rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
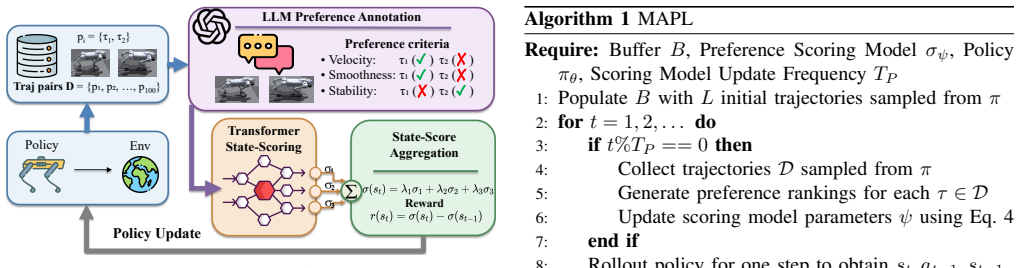
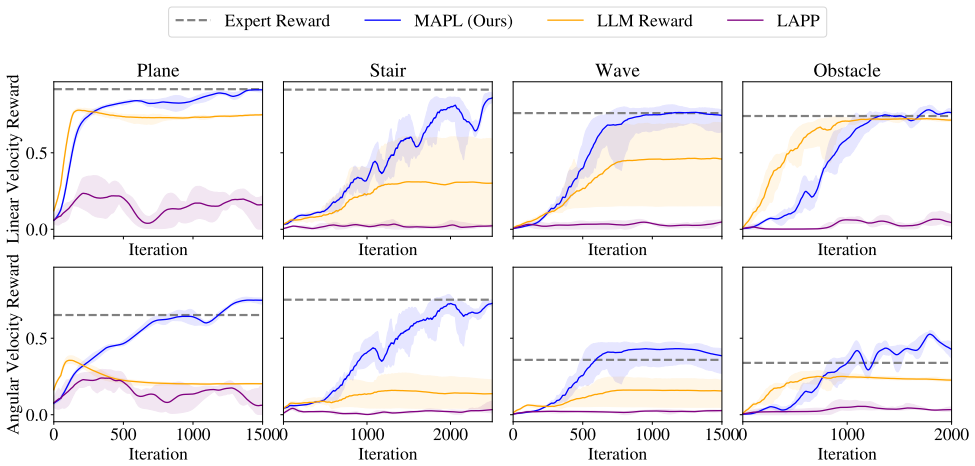
MAPL prompts a large language model to compare trajectories independently along semantically meaningful criteria, using generic language descriptions that are terrain-invariant and require little domain expertise. These objective-wise preferences are used to train a multi-head preference scoring model, whose outputs are aggregated to form a scalar reward for policy optimization. Across four quadruped locomotion environments, MAPL trains policies using only LLM-generated preferences and achieves performance comparable to or better than expert-designed rewards, while eliminating task-specific reward engineering.
What carries the argument
Multi-head preference scoring model trained on objective-wise LLM comparisons that aggregates outputs into a scalar reward signal.
If this is right
- Locomotion policies can be trained without any task-specific reward equations or domain-expert tuning.
- The same set of generic language criteria can be reused across different quadruped environments and terrains.
- Multiple competing objectives in locomotion behavior are captured through separate preference heads rather than a single overall judgment.
- Policy optimization proceeds with a learned reward derived entirely from language-model comparisons instead of hand-crafted terms.
Where Pith is reading between the lines
- The approach could be tested on other robot morphologies or non-locomotion tasks where multiple objectives must be balanced.
- Consistency of the LLM preferences might be checked by repeating comparisons with different models or prompt phrasings.
- The aggregation step from multi-head scores to scalar reward could be varied to measure sensitivity of final policy quality.
Load-bearing premise
Independent LLM comparisons along generic, terrain-invariant criteria produce preference signals whose aggregation yields rewards that produce locomotion policies comparable in quality to those from expert-designed rewards.
What would settle it
Training policies with MAPL rewards and expert rewards on a new quadruped environment or robot morphology and observing that MAPL policies underperform on standard locomotion metrics would falsify the comparability result.
Figures
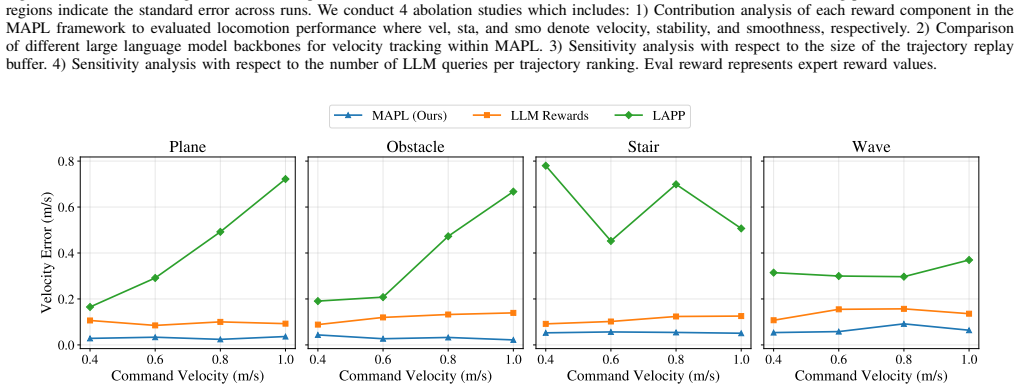
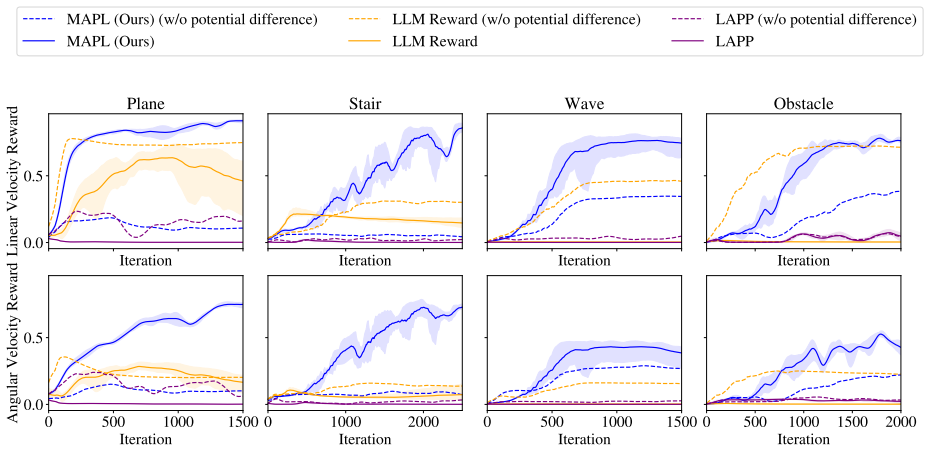
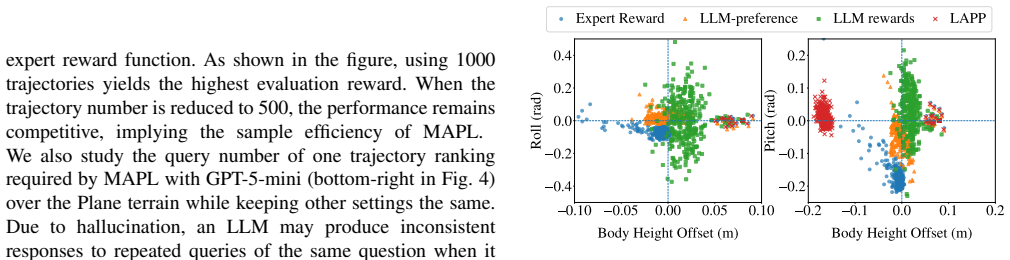
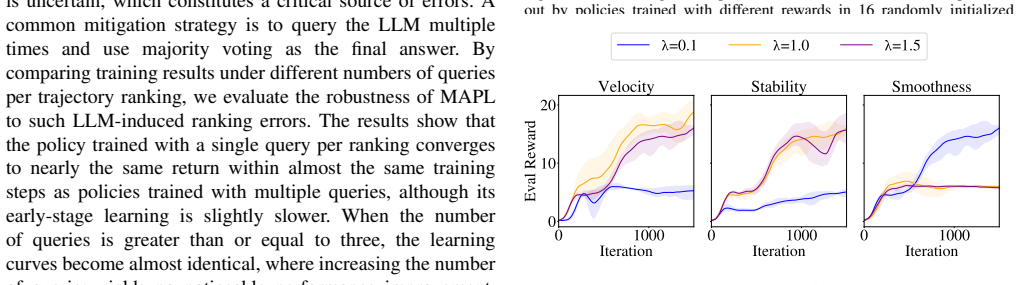
read the original abstract
Reward design remains a major bottleneck in reinforcement learning for robot locomotion, where successful policies often depend on carefully tuned, task-specific reward functions. Preference-based reinforcement learning offers an alternative, but existing LLM-based methods typically ask for a single overall judgment between behaviors, making it difficult to capture the multiple competing objectives that underlie high-quality locomotion. We present Multi-Objective AI-Informed Preference Learning (MAPL), a framework that learns locomotion rewards from high-level natural language objectives rather than manually engineered reward equations. MAPL prompts a large language model to compare trajectories independently along semantically meaningful criteria, using generic language descriptions that are terrain-invariant and require little domain expertise. These objective-wise preferences are used to train a multi-head preference scoring model, whose outputs are aggregated to form a scalar reward for policy optimization. Across four quadruped locomotion environments, MAPL trains policies using only LLM-generated preferences and achieves performance comparable to or better than expert-designed rewards, while eliminating task-specific reward engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAPL, a framework that prompts an LLM to compare locomotion trajectories independently along multiple semantically meaningful, terrain-invariant criteria; these preferences train a multi-head scoring model whose outputs are aggregated into a scalar reward for policy optimization in RL. The central claim is that, across four quadruped environments, policies trained solely from these LLM-generated preferences achieve performance comparable to or better than those obtained from expert-designed rewards, while eliminating task-specific reward engineering.
Significance. If the empirical results and the aggregation step are validated, the work would offer a concrete route to replacing manual multi-objective reward engineering with high-level language specifications in robot locomotion, a persistent bottleneck in RL for legged systems. The multi-criterion preference elicitation is a clear technical contribution over single-judgment LLM preference methods.
major comments (3)
- [Abstract] Abstract (final sentence): the performance claim that MAPL policies are 'comparable to or better than expert-designed rewards' is stated without any quantitative results, baselines, statistical details, or experimental protocol, so it is impossible to verify whether the data support the claim as written.
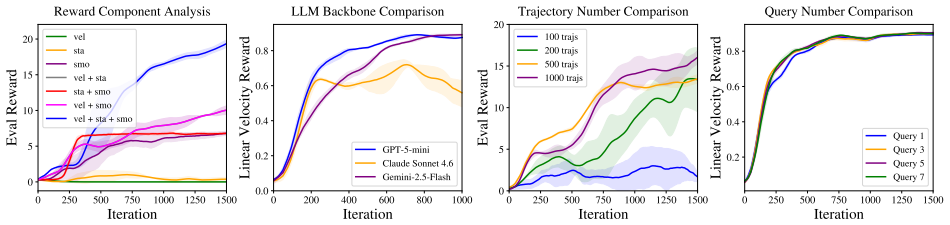
- [Method] Method section (aggregation of multi-head scores): no derivation, sensitivity analysis, or ablation is supplied showing that independent LLM judgments on generic criteria, once aggregated, recover the precise trade-offs among competing objectives (e.g., velocity vs. energy vs. stability) that expert rewards encode; this step is load-bearing for the claim that LLM-based rewards match expert performance.
- [Experiments] Experiments section: the abstract asserts results 'across four quadruped locomotion environments' yet supplies no table or figure reporting the actual metrics, variance, or statistical tests that would allow assessment of whether the LLM-derived rewards truly match or exceed the expert baselines.
minor comments (2)
- [Method] The description of the multi-head model architecture and the exact aggregation function (linear, learned, etc.) should be stated with equations for reproducibility.
- [Method] Clarify whether the LLM criteria are fixed across all terrains or adapted; the claim of 'terrain-invariant' descriptions needs an explicit list or example in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract, method, and experiments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence): the performance claim that MAPL policies are 'comparable to or better than expert-designed rewards' is stated without any quantitative results, baselines, statistical details, or experimental protocol, so it is impossible to verify whether the data support the claim as written.
Authors: We agree the abstract claim would be more verifiable with quantitative support. In revision we will update the final sentence to reference key metrics (e.g., normalized returns and success rates) and the evaluation protocol across environments and random seeds. revision: yes
-
Referee: [Method] Method section (aggregation of multi-head scores): no derivation, sensitivity analysis, or ablation is supplied showing that independent LLM judgments on generic criteria, once aggregated, recover the precise trade-offs among competing objectives (e.g., velocity vs. energy vs. stability) that expert rewards encode; this step is load-bearing for the claim that LLM-based rewards match expert performance.
Authors: The current manuscript describes the multi-head model and a simple weighted aggregation but lacks the requested analysis. We will add a derivation of the aggregation, a sensitivity study on weights, and an ablation comparing aggregated LLM scores against expert reward trade-offs. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts results 'across four quadruped locomotion environments' yet supplies no table or figure reporting the actual metrics, variance, or statistical tests that would allow assessment of whether the LLM-derived rewards truly match or exceed the expert baselines.
Authors: The experiments section contains tables and figures with per-environment metrics; however, to improve clarity we will insert a consolidated main-body table reporting means, standard deviations over multiple seeds, and direct statistical comparisons to the expert-designed reward baselines. revision: yes
Circularity Check
No significant circularity; derivation relies on external LLM judgments
full rationale
The paper describes training a multi-head scoring model from LLM-generated per-criterion preferences on generic language criteria, then aggregating outputs into a scalar reward for RL policy optimization. This chain depends on external LLM comparisons rather than any fitted parameter of the target performance claim or self-citation that reduces the result to its inputs by construction. No equations, uniqueness theorems, or ansatzes are shown to be smuggled or self-defined. The reported performance comparability is presented as an empirical outcome across environments, not a definitional equivalence. This is the normal case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RMA: Rapid Motor Adaptation for Legged Robots
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science robotics, vol. 5, no. 47, p. eabc5986, 2020
2020
-
[3]
Walk these ways: Tuning robot control for generalization with multiplicity of behavior,
G. B. Margolis and P. Agrawal, “Walk these ways: Tuning robot control for generalization with multiplicity of behavior,” inConference on Robot Learning. PMLR, 2023, pp. 22–31
2023
-
[4]
Rapid locomotion via reinforcement learning,
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal, “Rapid locomotion via reinforcement learning,”The International Journal of Robotics Research, vol. 43, no. 4, pp. 572–587, 2024
2024
-
[5]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,”Advances in Neural Information Processing Systems, vol. 35, pp. 9460–9471, 2022
2022
-
[6]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[7]
J. Park, Y . Seo, J. Shin, H. Lee, P. Abbeel, and K. Lee, “Surf: Semi-supervised reward learning with data augmentation for feedback- efficient preference-based reinforcement learning,”arXiv preprint arXiv:2203.10050, 2022
-
[8]
K. Lee, L. Smith, and P. Abbeel, “Pebble: Feedback-efficient interac- tive reinforcement learning via relabeling experience and unsupervised pre-training,”arXiv preprint arXiv:2106.05091, 2021
-
[9]
Eureka: Human-Level Reward Design via Coding Large Language Models
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Ja- yaraman, Y . Zhu, L. Fan, and A. Anandkumar, “Eureka: Human- level reward design via coding large language models,”arXiv preprint arXiv:2310.12931, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Boosting universal llm reward design through heuristic reward observation space evolution,
Z. K. Heng, Z. Zhao, T. Wu, Y . Wang, M. Wu, Y . Wang, and H. Dong, “Boosting universal llm reward design through heuristic reward observation space evolution,”arXiv preprint arXiv:2504.07596, 2025
-
[11]
Learning reward for robot skills using large language models via self-alignment,
Y . Zeng, Y . Mu, and L. Shao, “Learning reward for robot skills using large language models via self-alignment,”arXiv preprint arXiv:2405.07162, 2024
-
[12]
Skill preferences: Learning to extract and execute robotic skills from human feedback,
X. Wang, K. Lee, K. Hakhamaneshi, P. Abbeel, and M. Laskin, “Skill preferences: Learning to extract and execute robotic skills from human feedback,” inConference on robot learning. PMLR, 2022, pp. 1259– 1268
2022
-
[13]
R. Wang, D. Zhao, Z. Yuan, T. Shao, G. Chen, D. Kao, S. Hong, and B.-C. Min, “Primt: Preference-based reinforcement learning with multimodal feedback and trajectory synthesis from foundation mod- els,”arXiv preprint arXiv:2509.15607, 2025
-
[14]
Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,
Y . Wang, Z. Sun, J. Zhang, Z. Xian, E. Biyik, D. Held, and Z. Erickson, “Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,”arXiv preprint arXiv:2402.03681, 2024
-
[15]
Learning Tactile-Aware Quadrupedal Loco-Manipulation Policies
P. Zhou, Y . Zhou, Q. K. Luu, S. Han, H. Zhang, B. Huang, Y . Li, A. Ajoudani, Z. Xu, and Y . She, “Learning tactile-aware quadrupedal loco-manipulation policies,”arXiv preprint arXiv:2604.27224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
A bayesian approach for policy learning from trajectory preference queries,
A. Wilson, A. Fern, and P. Tadepalli, “A bayesian approach for policy learning from trajectory preference queries,”Advances in neural information processing systems, vol. 25, 2012
2012
-
[17]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
H. Lee, S. Phatale, H. Mansoor, T. Mesnard, J. Ferret, K. Lu, C. Bishop, E. Hall, V . Carbune, A. Rastogiet al., “Rlaif vs. rlhf: Scal- ing reinforcement learning from human feedback with ai feedback,” arXiv preprint arXiv:2309.00267, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Con- stitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Rlaif-v: Open-source ai feedback leads to super gpt-4v trustworthiness,
T. Yu, H. Zhang, Q. Li, Q. Xu, Y . Yao, D. Chen, X. Lu, G. Cui, Y . Dang, T. Heet al., “Rlaif-v: Open-source ai feedback leads to super gpt-4v trustworthiness,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19 985–19 995
2025
-
[20]
Silkie: Preference distillation for large visual language models,
L. Li, Z. Xie, M. Li, S. Chen, P. Wang, L. Chen, Y . Yang, B. Wang, and L. Kong, “Silkie: Preference distillation for large visual language models,”arXiv preprint arXiv:2312.10665, 2023
-
[21]
S. Tu, J. Sun, Q. Zhang, X. Lan, and D. Zhao, “Online preference- based reinforcement learning with self-augmented feedback from large language model,”arXiv preprint arXiv:2412.16878, 2024
-
[22]
Prefclm: Enhanc- ing preference-based reinforcement learning with crowdsourced large language models,
R. Wang, D. Zhao, Z. Yuan, I. Obi, and B.-C. Min, “Prefclm: Enhanc- ing preference-based reinforcement learning with crowdsourced large language models,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2486–2493, 2025
2025
-
[23]
Real-world offline reinforcement learning from vision lan- guage model feedback,
S. Venkataraman, Y . Wang, Z. Wang, N. S. Ravie, Z. Erickson, and D. Held, “Real-world offline reinforcement learning from vision lan- guage model feedback,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 13 452– 13 459
2025
-
[24]
Lapp: Large language model feedback for preference-driven rein- forcement learning,
P. Jian, X. Wei, Y . Liu, S. A. Moore, M. M. Zavlanos, and B. Chen, “Lapp: Large language model feedback for preference-driven rein- forcement learning,”arXiv preprint arXiv:2504.15472, 2025
-
[25]
Dap- per: Discriminability-aware policy-to-policy preference-based rein- forcement learning for query-efficient robot skill acquisition,
Y . Kadokawa, J. Frey, T. Miki, T. Matsubara, and M. Hutter, “Dap- per: Discriminability-aware policy-to-policy preference-based rein- forcement learning for query-efficient robot skill acquisition,”IEEE Robotics & Automation Magazine, 2026
2026
-
[26]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduc- tion. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[27]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
R. A. Bradley and M. E. Terry, “Rank analysis of incomplete block designs: I. the method of paired comparisons,”Biometrika, vol. 39, no. 3/4, pp. 324–345, 1952
1952
-
[28]
Preference transformer: Modeling human preferences using transformers for rl,
C. Kim, J. Park, J. Shin, H. Lee, P. Abbeel, and K. Lee, “Preference transformer: Modeling human preferences using transformers for rl,” arXiv preprint arXiv:2303.00957, 2023
-
[29]
Navigating noisy feedback: Enhancing reinforcement learning with error-prone language models,
M. Lin, S. Shi, Y . Guo, B. Chalaki, V . Tadiparthi, E. M. Pari, S. Stepputtis, J. Campbell, and K. Sycara, “Navigating noisy feedback: Enhancing reinforcement learning with error-prone language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024
2024
-
[30]
A minimaximalist approach to reinforcement learning from human feedback,
G. Swamy, C. Dann, R. Kidambi, Z. S. Wu, and A. Agarwal, “A minimaximalist approach to reinforcement learning from human feedback,”arXiv preprint arXiv:2401.04056, 2024
-
[31]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[32]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Rsl-rl: A learning library for robotics research,
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter, “Rsl-rl: A learning library for robotics research,”arXiv preprint arXiv:2509.10771, 2025. APPENDIX A. Reward Model Hyperparameter The hyparameter of Transformer-based reward model are tuned manually. The details are listed below. Hyperparameter Transformer Reward Model Embedding Dimension 256 Nu...
-
[34]
You will be given two trajectories of the Unitree Go2 Robot Dog, and you need to decide which trajectory is better
V elocity Preference Prompt: You are a robotics engineer specializing in analyzing and comparing the trajectories of a Unitree Go2 Robot Dog. You will be given two trajectories of the Unitree Go2 Robot Dog, and you need to decide which trajectory is better. A trajectory will include the following information:
-
[35]
”The base linear velocity” (m/s): Current Unitree Go2 robot dog x and y velocity, you will need that information to decide if the robot dog is moving forward, the shape of this term is (6, 2), where 6 is the time length, and 2 is x and y linear velocity respectively
-
[36]
”The base angular velocity” (rad/s): Current Unitree Go2 robot dog yaw velocity, you will need that information to decide if the robot dog is turning, the shape of this term is (6, 1)
-
[37]
”The commands”(m/s, m/s, rad/s): The desired x, y, yaw velocity of Unitree Go2 robot dog, you will need that information to decide if the robot dog is following the commands, the shape of this term is (6, 3)
-
[38]
1 means touching the ground while 0 means in the air
”The feet contacts”[front left, front right, rear left, rear right]: The contact boolean values of the four feet on the ground. 1 means touching the ground while 0 means in the air. You only need that information for considering Gait pattern consistency. The shape of this term is (6, 4)
-
[39]
Smaller deviations correspond to better tracking, and preference should decrease smoothly as deviations increase
The negative sign only represents direction of velocity Decision Rules 1)Linear velocity tracking (primary criterion) At each timestep, compare the robot’s actual x–y linear velocity to the commanded x–y velocity. Smaller deviations correspond to better tracking, and preference should decrease smoothly as deviations increase. Very small errors should stil...
-
[40]
Yaw (angular) velocity tracking (secondary criterion) Evaluate how closely the robot’s yaw rate follows the commanded yaw rate across timesteps in the same smooth and continuous manner
-
[41]
Front-right and rear-left feet tend to be in the same contact state at the same time
Gait pattern consistency (conditional criterion) The robot is encouraged to use a diagonal gait (trot): Front-left and rear-right feet tend to be in the same contact state at the same time. Front-right and rear-left feet tend to be in the same contact state at the same time. Overall preference rule The final decision must consider both linear and angular ...
-
[42]
If the first trajectory is better than the second trajectory, the preference value for this pair of trajectory is 0
-
[43]
If the second trajectory is better than the first trajectory, the preference value for this pair of trajectory is 1
-
[45]
Please return a Python list of preference values
You should analyze each pair of trajectory independently, do not refer to previous results. Please return a Python list of preference values. You must output ONLY a JSON array, do not output anything else, do not hallucinate or make up data, strictly follow the decision rules
-
[46]
Stability Preference Prompt: You are a robotics engineer specializing in analyzing and comparing the trajectories of a Unitree Go2 Robot. You will be given two trajectories of the Unitree Go2 Robot, each trajectory consisting of continuous 6 states, and you need to decide which trajectory is better given 6 states in the trajectory. A trajectory will inclu...
-
[47]
Shape (6,1), one value per step
”The base height” (m): The z position (height) of the robot base torso. Shape (6,1), one value per step. Height should stay close to 0.34 m with minimal fluctuation
-
[48]
Shape (6, 1)
”The vertical linear velocity” (m/s): The z-axis component of the base linear velocity. Shape (6, 1). Values should be near 0 to avoid bouncing
-
[49]
Shape (6, 2)
”The roll/pitch angular velocity” (rad/s): The base angular rates around x (roll) and y (pitch). Shape (6, 2). Magnitudes should be close to 0 to avoid rocking. Decision Rules 1)Base height consistency The base height should stay very close to 0.34 m throughout the trajectory. Even small deviations should noticeably reduce preference, and larger deviation...
-
[54]
Smoothness Preference Prompt: You are a robotics engineer specializing in analyzing and comparing the trajectories of a Unitree Go2 Robot. You will be given two trajectories of the Unitree Go2 Robot, each trajectory consisting of continuous 6 states, and you need to decide which trajectory is better given these states in the trajectory. A trajectory will ...
-
[55]
This value is already computed as the sum of per-step, per-joint action differences between consecutive action commands
”sum of joint action change∆u” (unitless): The total accumulated change in joint action commands across the entire trajectory. This value is already computed as the sum of per-step, per-joint action differences between consecutive action commands. The shape for this term is (6, 1)
-
[56]
The shape for this term is (6, 1) Decision Rules 1)Action Smoothness: We prefer the trajectory with smaller overall joint action change
”stumble”: The number of foot slipping, scraping, or skidding, where the foot is not properly supporting the robot’s weight but is experiencing strong lateral forces. The shape for this term is (6, 1) Decision Rules 1)Action Smoothness: We prefer the trajectory with smaller overall joint action change. 2)Stumble avoidance: Trajectories with fewer or weake...
-
[57]
If the trajectory 0 is better, the preference value should be 0
-
[58]
If the trajectory 1 is better, the preference value should be 1
-
[59]
If the two trajectories are equally preferable, the preference value for this pair of trajectory is 2
-
[60]
You must output ONLY a JSON array, do not output anything else, do not hallucinate or make up data, strictly follow the decision rules
You should analyze each pair of trajectory independently, do not refer to previous results Please return a Python list of preference values. You must output ONLY a JSON array, do not output anything else, do not hallucinate or make up data, strictly follow the decision rules
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.