FeVOS: Foresight Expression Video Object Segmentation
Pith reviewed 2026-06-25 21:11 UTC · model grok-4.3
The pith
Foresight expressions require video object segmentation models to output present-frame masks by reasoning about future events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining foresight expressions that query future events while requiring masks of the relevant objects in the observed frames, and by releasing the FeVOS dataset with explicit chain-of-thought reasoning steps, the work shows that an MLLM trained in two stages can perform the necessary predictive spatio-temporal reasoning and generalize beyond the new benchmark.
What carries the argument
The foresight expression, which describes a future event and requires the model to identify the corresponding object via predictive reasoning and output its mask in the current frames.
If this is right
- FeVOS-R1 reaches state-of-the-art accuracy on the FeVOS benchmark.
- The same model shows strong generalization when tested on existing RVOS benchmarks.
- Chain-of-thought annotations supply explicit, interpretable reasoning steps for the predictive task.
- The approach supports applications that require understanding future actions and decisions from video.
Where Pith is reading between the lines
- Models exposed to foresight training may develop stronger reasoning habits that transfer to standard RVOS even without future-event queries.
- The dataset offers a direct way to measure whether other MLLMs can perform predictive segmentation without task-specific fine-tuning.
- If the task truly isolates future reasoning, performance should degrade sharply when models are denied access to future frames during evaluation.
- The same annotation style could be applied to other video tasks that currently lack explicit predictive components.
Load-bearing premise
The foresight expressions and chain-of-thought annotations genuinely demand prediction of future events instead of being solvable by matching patterns visible in the current frame alone.
What would settle it
A controlled test in which a model trained only on standard current-frame RVOS data is evaluated on the FeVOS test set and achieves accuracy statistically indistinguishable from FeVOS-R1.
Figures

read the original abstract
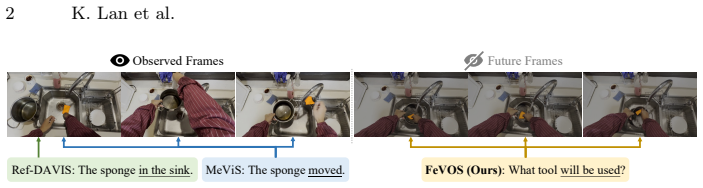
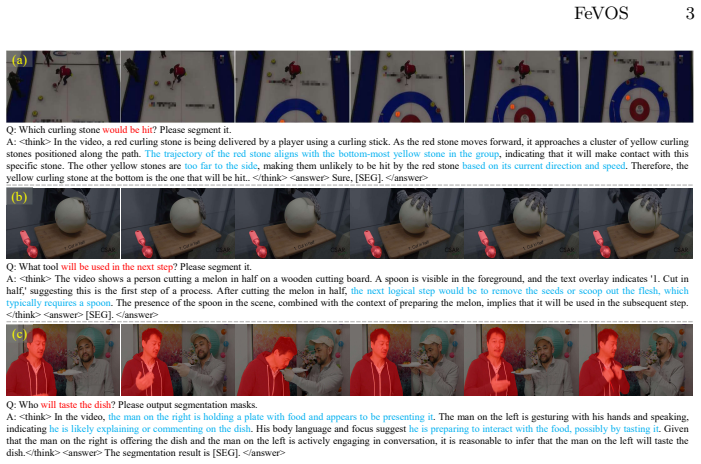
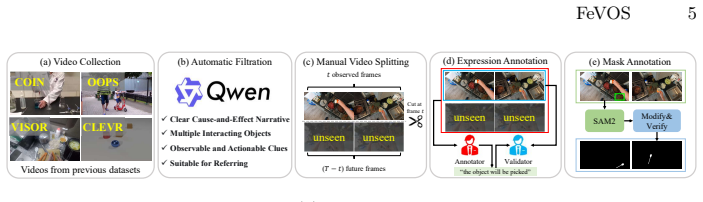
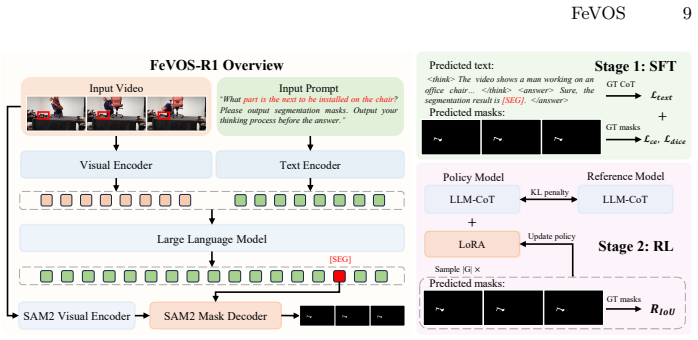
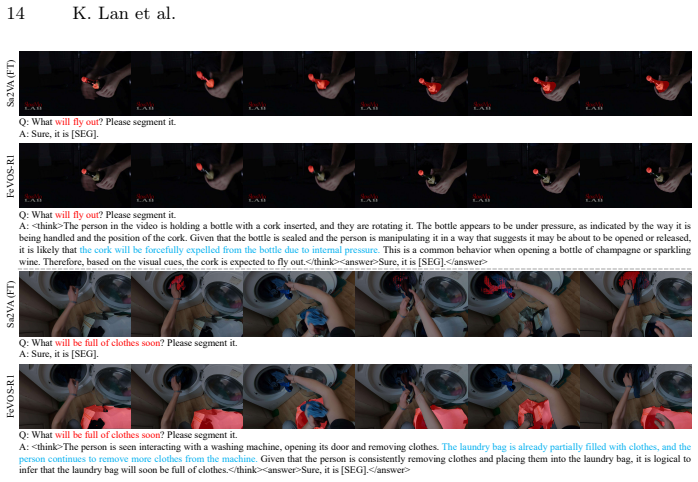
Existing Referring Video Object Segmentation tasks focus on referring expressions describing events, actions or appearances of relevant objects within the observed frames, lacking evaluation in scenarios that require pre-decisive spatio-temporal reasoning, thereby limiting their applicability. To address this, we propose Foresight Expression Video Object Segmentation, a task that queries future events in upcoming video segments and requires masks of the objects in the observed frames as visual answers. For example, in ego-centric scenes, the question "What tool will be used?" demands reasoning over spatio-temporal cues to predict the masks of the next tool to be used, which helps with the understanding of future actions and decisions. To support this task, we introduce FeVOS, a dataset with 968 video clips, 14,525 foresight expressions, and 2,904 chain-of-thought annotations to provide explicit and interpretable reasoning steps. We further develop FeVOS-R1, an MLLM-based model trained on our dataset via a two-stage pipeline of supervised fine-tuning and reinforcement learning. FeVOS-R1 not only achieves state-of-the-art performance on FeVOS, but also demonstrates strong generalization to existing RVOS benchmarks. We hope this work can inspire more research on predictive reasoning in video perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Foresight Expression Video Object Segmentation (FeVOS), a new task requiring masks of objects involved in future events based on foresight expressions about upcoming video segments. It contributes the FeVOS dataset (968 clips, 14,525 expressions, 2,904 CoT annotations) and FeVOS-R1, an MLLM trained via two-stage SFT then RL, claiming SOTA on FeVOS plus strong generalization to prior RVOS benchmarks.
Significance. If the central assumption holds—that the expressions genuinely elicit predictive spatio-temporal reasoning rather than current-frame pattern matching—this could meaningfully extend video object segmentation toward anticipatory perception with applications in robotics and decision support. The CoT annotations are a constructive addition for interpretability. At present the significance is tempered because the manuscript supplies no direct evidence against shortcut solutions.
major comments (3)
- [§3 (Dataset)] Dataset construction (abstract and §3): no control experiments, human studies, or quantitative checks are described to establish that the 14,525 foresight expressions cannot be resolved from visible objects, ego-centric priors, or frame-wise co-occurrence statistics alone. This verification is load-bearing for the claim that the task 'requires pre-decisive spatio-temporal reasoning' and for interpreting both SOTA results and cross-benchmark generalization.
- [§5 (Experiments)] Experiments (§5): the generalization statement to existing RVOS benchmarks is presented without accompanying tables, baseline numbers, or ablation isolating the contribution of foresight training versus standard RVOS supervision; the abstract supplies no metrics, so the strength of the transfer claim cannot be assessed from the text.
- [§4 (Method)] Method (§4): the SFT+RL pipeline is outlined at a high level, yet the manuscript contains no analysis or reward-design discussion showing that the RL stage encourages future-oriented reasoning rather than optimization of current-frame cues that happen to correlate with the foresight labels.
minor comments (1)
- [Abstract] Abstract: the phrase 'strong generalization' is used without any numerical reference to tables or specific metrics; a parenthetical pointer to the relevant results would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the verification of the task, the presentation of results, and the analysis of the training pipeline.
read point-by-point responses
-
Referee: Dataset construction (abstract and §3): no control experiments, human studies, or quantitative checks are described to establish that the 14,525 foresight expressions cannot be resolved from visible objects, ego-centric priors, or frame-wise co-occurrence statistics alone. This verification is load-bearing for the claim that the task 'requires pre-decisive spatio-temporal reasoning' and for interpreting both SOTA results and cross-benchmark generalization.
Authors: We agree that explicit verification against potential shortcuts is essential to substantiate the task's focus on predictive reasoning. In the revised manuscript we will add a dedicated subsection in §3 with control experiments (current-frame-only baselines and co-occurrence statistics comparisons), quantitative checks, and a small-scale human study in which annotators attempt to answer expressions without access to future video segments. These additions will directly support the claim that the expressions require foresight. revision: yes
-
Referee: Experiments (§5): the generalization statement to existing RVOS benchmarks is presented without accompanying tables, baseline numbers, or ablation isolating the contribution of foresight training versus standard RVOS supervision; the abstract supplies no metrics, so the strength of the transfer claim cannot be assessed from the text.
Authors: We will revise the abstract to report the key quantitative metrics on prior RVOS benchmarks. In §5 we will insert the missing tables with baseline comparisons and add an ablation that isolates the contribution of the foresight-specific training data versus standard RVOS supervision. These changes will make the generalization claims fully verifiable from the text. revision: yes
-
Referee: Method (§4): the SFT+RL pipeline is outlined at a high level, yet the manuscript contains no analysis or reward-design discussion showing that the RL stage encourages future-oriented reasoning rather than optimization of current-frame cues that happen to correlate with the foresight labels.
Authors: We will expand §4 with a detailed discussion of the reward formulation used in the RL stage and how it is designed to reward correct future-event predictions. We will also add analysis (frame-ablation studies and attention visualizations) demonstrating that the learned policy relies on foresight rather than current-frame correlations alone. These elements will be included in the revision. revision: yes
Circularity Check
No circularity; claims rest on newly collected dataset and empirical evaluation
full rationale
The paper defines a new task (FeVOS) and introduces a new dataset (968 clips, 14,525 expressions, 2,904 CoT annotations) collected to support it. No equations, parameters, or derivations are present that could reduce to self-definition or fitted inputs. The two-stage training pipeline (SFT+RL) on FeVOS-R1 is standard supervised training on external data; performance claims are empirical and falsifiable against the held-out test set and external RVOS benchmarks. No self-citation load-bearing steps or uniqueness theorems are invoked. This is the common case of a dataset-driven contribution with no internal circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities. arXiv preprint arXiv:2308.12966 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 4, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Advances in Neural Information Processing Systems37, 6833–6859 (2024) 1, 3, 4, 11, 12
Bai, Z., He, T., Mei, H., Wang, P., Gao, Z., Chen, J., Zhang, Z., Shou, M.Z.: One token to seg them all: Language instructed reasoning segmentation in videos. Advances in Neural Information Processing Systems37, 6833–6859 (2024) 1, 3, 4, 11, 12
2024
-
[4]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024) 4, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24185–24198 (2024) 4
2024
-
[6]
Advances in Neural Information Processing Systems35, 13745–13758 (2022) 5
Darkhalil, A., Shan, D., Zhu, B., Ma, J., Kar, A., Higgins, R., Fidler, S., Fouhey, D., Damen, D.: Epic-kitchens visor benchmark: Video segmentations and object relations. Advances in Neural Information Processing Systems35, 13745–13758 (2022) 5
2022
-
[7]
In: ICCV (2023) 1, 2, 3, 4, 7, 8, 11, 12
Ding, H., Liu, C., He, S., Jiang, X., Loy, C.C.: MeViS: A large-scale benchmark for video segmentation with motion expressions. In: ICCV (2023) 1, 2, 3, 4, 7, 8, 11, 12
2023
-
[8]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 1, 2
Ding, H., Liu, C., He, S., Ying, K., Jiang, X., Loy, C.C., Jiang, Y.G.: Mevis: A multi-modal dataset for referring motion expression video segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 1, 2
2025
-
[9]
arXiv preprint arXiv:2508.05630 (2025) 8
Ding, H., Ying, K., Liu, C., He, S., Jiang, X., Jiang, Y.G., Torr, P.H., Bai, S.: Mosev2: A more challenging dataset for video object segmentation in complex scenes. arXiv preprint arXiv:2508.05630 (2025) 8
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Epstein, D., Chen, B., Vondrick, C.: Oops! predicting unintentional action in video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 919–929 (2020) 5
2020
-
[11]
In: CVPR (2018) 4
Gavrilyuk, K., Ghodrati, A., Li, Z., Snoek, C.G.: Actor and Action Video Segmen- tation from a Sentence. In: CVPR (2018) 4
2018
-
[12]
arXiv preprint arXiv:2508.11538 (2025) 5, 10, 13
Gong, S., Zhang, L., Zhuge, Y., Jia, X., Zhang, P., Lu, H.: Reinforcing video rea- soning segmentation to think before it segments. arXiv preprint arXiv:2508.11538 (2025) 5, 10, 13
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Gong,S.,Zhuge,Y.,Zhang,L.,Yang,Z.,Zhang,P.,Lu,H.:Thedevilisintemporal token: High quality video reasoning segmentation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29183–29192 (2025) 3, 4, 11, 12 16 K. Lan et al
2025
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 3, 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: ICLR (2022) 10
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-Rank Adaptation of Large Language Models. In: ICLR (2022) 10
2022
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Hu, H., Ying, K., Ding, H.: Segment anything across shots: a method and bench- mark. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 4825– 4833 (2026) 8
2026
-
[17]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, H., Chen, X., Chen, Y., Li, H., Han, X., Wang, Z., Wang, T., Pang, J., Zhao, Z.: Roboground: Robotic manipulation with grounded vision-language pri- ors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22540–22550 (2025) 1
2025
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visual rep- resentation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024) 4
2024
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2901–2910 (2017) 5
2017
-
[20]
In: ACCV (2019) 1, 2, 4, 7
Khoreva, A., Rohrbach, A., Schiele, B.: Video Object Segmentation with Language Referring Expressions. In: ACCV (2019) 1, 2, 4, 7
2019
-
[21]
In: CVPR (2024) 4, 12
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: LISA: Reasoning Segmentation via Large Language Model. In: CVPR (2024) 4, 12
2024
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22195–22206 (2024) 2
2024
-
[23]
IEEE Transac- tions on Intelligent Transportation Systems (2024) 1
Lin, J., Chen, J., Peng, K., He, X., Li, Z., Stiefelhagen, R., Yang, K.: Echotrack: Auditory referring multi-object tracking for autonomous driving. IEEE Transac- tions on Intelligent Transportation Systems (2024) 1
2024
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) 3, 4, 11, 12
Lin, L., Yu, X., Pang, Z., Wang, Y.X.: Glus: Global-local reasoning unified into a single large language model for video segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) 3, 4, 11, 12
2025
-
[25]
In: NeurIPS (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual Instruction Tuning. In: NeurIPS (2023) 4
2023
-
[26]
Liu, S., Ying, K., Zhang, H., Yang, Y., Lin, Y., Zhang, T., Li, C., Qiao, Y., Luo, P., Shao, W., et al.: ConvBench: A Multi-Turn Conversation Evaluation Benchmark with Hierarchical Ablation Capability for Large Vision-Language Models. In: Adv. Neural Inform. Process. Syst. Datasets Benchmarks Track (2024) 4
2024
-
[27]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024) 2
2024
-
[28]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520 (2025) 5, 10, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: CVPR (2025) 11, 12 FeVOS 17
Munasinghe, S., Gani, H., Zhu, W., Cao, J., Xing, E., Khan, F.S., Khan, S.: Videoglamm: A large multimodal model for pixel-level visual grounding in videos. In: CVPR (2025) 11, 12 FeVOS 17
2025
-
[30]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: SAM 2: Segment Anything in Images and Videos. arXiv preprint arXiv:2408.00714 (2024) 4, 6, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
In: ECCV (2020) 1, 2, 4, 7
Seo, S., Lee, J.Y., Han, B.: URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark. In: ECCV (2020) 1, 2, 4, 7
2020
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 3, 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Shen, H., Liu, P., Li, J., Fang, C., Ma, Y., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., et al.: Vlm-r1: A stable and generalizable r1-style large vision-language model. arXiv preprint arXiv:2504.07615 (2025) 4, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
arXiv preprint arXiv:2303.00905 (2023) 1
Stone, A., Xiao, T., Lu, Y., Gopalakrishnan, K., Lee, K.H., Vuong, Q., Wohlhart, P., Kirmani, S., Zitkovich, B., Xia, F., et al.: Open-world object manipulation using pre-trained vision-language models. arXiv preprint arXiv:2303.00905 (2023) 1
-
[35]
MIT press Cambridge (1998) 4
Sutton, R.S., Barto, A.G., et al.: Reinforcement learning: An introduction. MIT press Cambridge (1998) 4
1998
-
[36]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tang, Y., Ding, D., Rao, Y., Zheng, Y., Zhang, D., Zhao, L., Lu, J., Zhou, J.: Coin: A large-scale dataset for comprehensive instructional video analysis. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1207–1216 (2019) 5
2019
-
[37]
In: Proceedings of the 29th International Conference on Intelligent User Interfaces
Tilekbay, B., Yang, S., Lewkowicz, M.A., Suryapranata, A., Kim, J.: Expressedit: Video editing with natural language and sketching. In: Proceedings of the 29th International Conference on Intelligent User Interfaces. pp. 515–536 (2024) 1
2024
-
[38]
arXiv preprint arXiv:2505.22457 (2025) 2
Wang, H., Liu, H., Liu, X., Du, C., Kawaguchi, K., Wang, Y., Pang, T.: Fostering video reasoning via next-event prediction. arXiv preprint arXiv:2505.22457 (2025) 2
-
[39]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv preprint arXiv:2409.12191 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
arXiv preprint arXiv:2405.09711 (2024) 5
Wu,B.,Yu,S.,Chen,Z.,Tenenbaum,J.B.,Gan,C.:Star:Abenchmarkforsituated reasoning in real-world videos. arXiv preprint arXiv:2405.09711 (2024) 5
-
[41]
In: CVPR (2022) 11, 12
Wu, J., Jiang, Y., Sun, P., Yuan, Z., Luo, P.: Language as Queries for Referring Video Object Segmentation. In: CVPR (2022) 11, 12
2022
-
[42]
In: ECCV (2024) 1, 3, 4, 8, 11, 12
Yan, C.,Wang,H., Yan,S., Jiang, X., Hu,Y., Kang, G., Xie,W., Gavves, E.:VISA: Reasoning Video Object Segmentation via Large Language Models. In: ECCV (2024) 1, 3, 4, 8, 11, 12
2024
-
[43]
Ying, K., Ding, H., Jie, G., Jiang, Y.G.: Towards omnimodal expressions and reasoningin referringaudio-visual segmentation.In: Proceedings of theIEEE/CVF International Conference on Computer Vision. pp. 22575–22585 (2025) 1
2025
-
[44]
In: ICCV (2025) 8
Ying, K., Hu, H., Ding, H.: MOVE: Motion-guided few-shot video object segmen- tation. In: ICCV (2025) 8
2025
-
[45]
Ying, K., Meng, F., Wang, J., Li, Z., Lin, H., Yang, Y., Zhang, H., Zhang, W., Lin, Y., Liu, S., Lei, J., Lu, Q., Chen, R., Xu, P., Zhang, R., Zhang, H., Gao, P., Wang, Y., Qiao, Y., Luo, P., Zhang, K., Shao, W.: MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI. In: Int. Conf. Mach. Learn. (2024) 4
2024
-
[46]
In: European Conference on Computer Vision
Yu, E., Zhao, L., Wei, Y., Yang, J., Wu, D., Kong, L., Wei, H., Wang, T., Ge, Z., Zhang, X., et al.: Merlin: Empowering multimodal llms with foresight minds. In: European Conference on Computer Vision. pp. 425–443. Springer (2024) 2 18 K. Lan et al
2024
-
[47]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Yuan, H., Li, X., Zhang, T., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., Yang, M.H.: Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv preprint arXiv:2501.04001 (2025) 3, 4, 8, 10, 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2506.04308 (2025) 1
Zhou, E., An, J., Chi, C., Han, Y., Rong, S., Zhang, C., Wang, P., Wang, Z., Huang, T., Sheng, L., et al.: Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. arXiv preprint arXiv:2506.04308 (2025) 1
-
[49]
arXiv preprint arXiv:2312.17448 (2023) 4, 12
Zhu, J., Cheng, Z.Q., He, J.Y., Li, C., Luo, B., Lu, H., Geng, Y., Xie, X.: Tracking with human-intent reasoning. arXiv preprint arXiv:2312.17448 (2023) 4, 12
-
[50]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhu, M., Tian, Y., Chen, H., Zhou, C., Guo, Q., Liu, Y., Yang, M., Shen, C.: Segagent: Exploring pixel understanding capabilities in mllms by imitating hu- man annotator trajectories. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3686–3696 (2025) 5
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.