DocArena: Turning Raw Documents into Controllable Training Environments for Document Search Agents
Pith reviewed 2026-06-29 12:47 UTC · model grok-4.3
The pith
Agents trained on DocArena data achieve the best retrieval accuracy and QA quality across multimodal document scenarios and text benchmarks under unified evaluation.
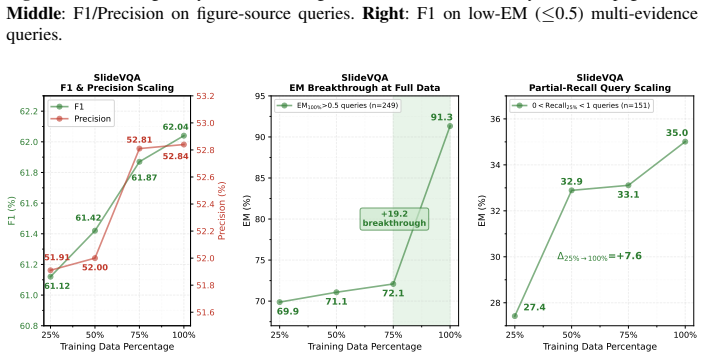
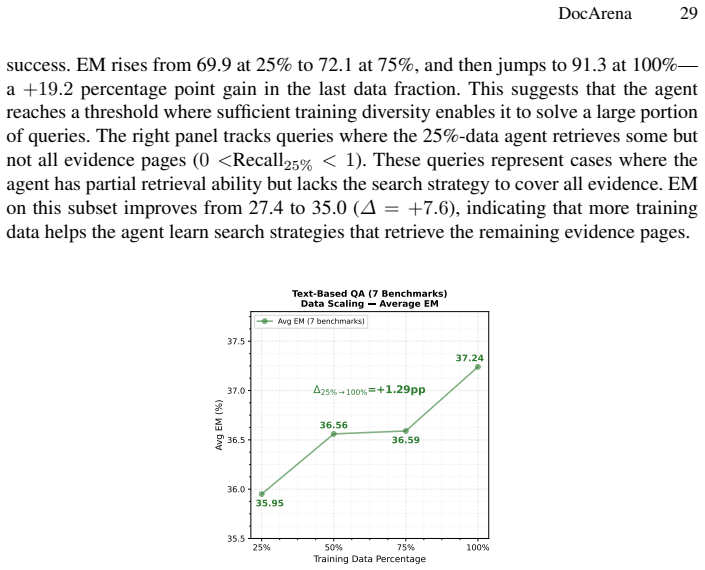
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
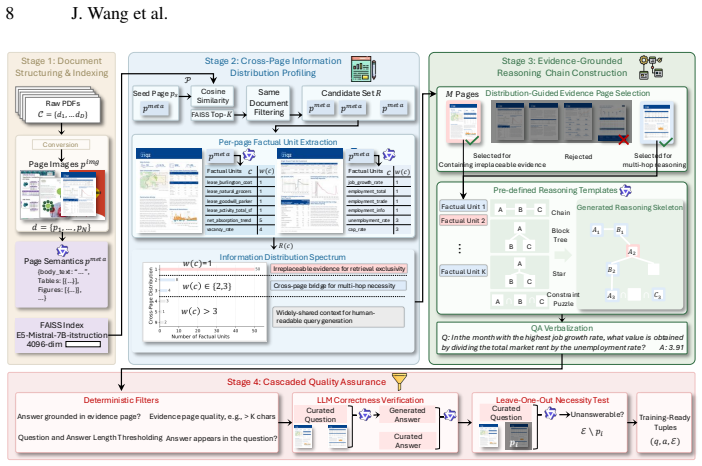
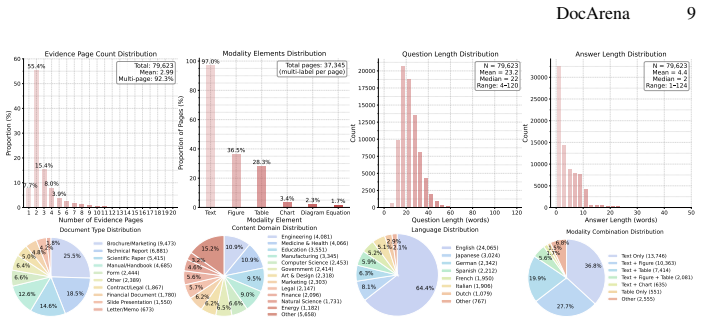
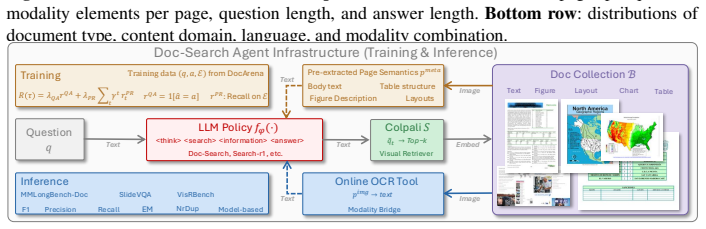
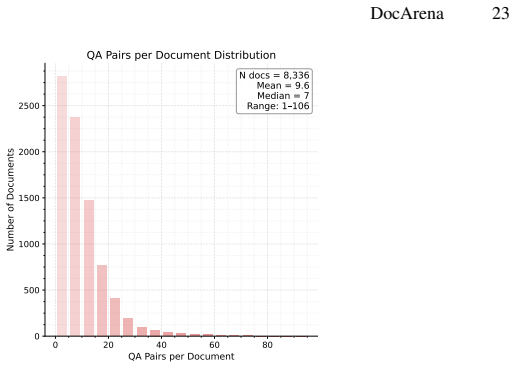
DocArena is a fully automated data curation pipeline that structures and indexes raw documents through MLLM-based visual perception, profiles and leverages cross-page information distribution to construct reasoning-intensive QA pairs, and performs cascaded quality assurance operations via MLLM. It produces DocArena-79K with QA pairs from 8,336 documents spanning 16 domains and 49 languages. The accompanying Doc-Search agent infrastructure decouples visual perception from the policy model so text-based LLMs can act as the reasoning backbone. Under a unified evaluation framework where only the policy model differs, agents trained on DocArena data achieve the best performance on both retrieval
What carries the argument
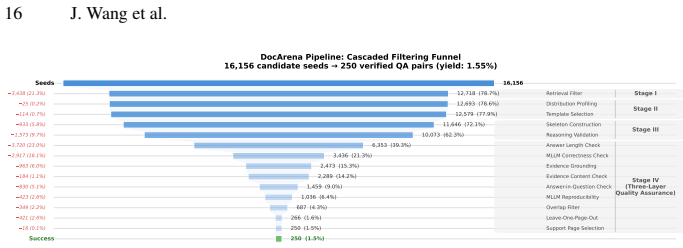
The DocArena pipeline, which automates creation of controllable (question, answer, evidence) training tuples from raw multimodal documents via MLLM perception and cross-page profiling.
If this is right
- Search agents develop more effective strategies and better generalization because the training tuples are reasoning-intensive and multimodal.
- The decoupled infrastructure allows text LLMs to serve as effective reasoning backbones even for visual document tasks.
- Training environments become scalable and controllable without needing expert trajectories or human annotation.
- Performance advantages appear consistently on both retrieval accuracy and downstream QA quality metrics.
Where Pith is reading between the lines
- The same pipeline structure could be adapted to generate training environments for agents that operate on other structured data sources such as scientific papers or legal records.
- The controllability of the generated environments opens the possibility of systematically varying properties like reasoning depth or language distribution to study their effects on agent behavior.
- If the MLLM steps prove robust across new document collections, the approach could reduce dependence on manually curated datasets for training specialized retrieval agents.
Load-bearing premise
MLLM-based visual perception, cross-page profiling, and cascaded quality assurance can reliably generate QA pairs that accurately reflect the real information distribution in raw documents without systematic biases or errors.
What would settle it
A direct replication of the unified evaluation experiments in which agents trained on DocArena data do not rank first on retrieval accuracy and QA quality, or a manual audit that finds frequent mismatches between generated QA pairs and the actual content of the source documents.
Figures

read the original abstract
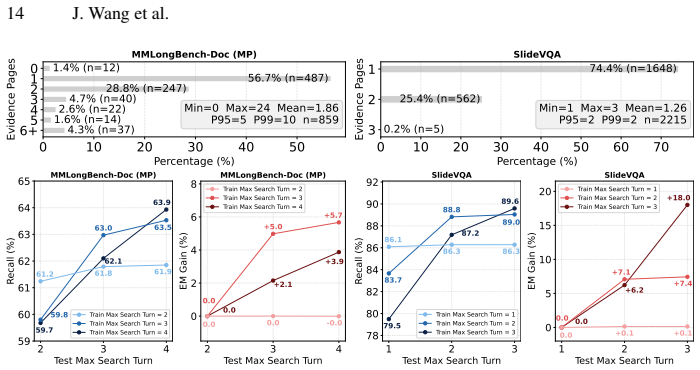
Recent methods train search agents via reinforcement learning from (question, answer, evidence) tuples without requiring expert trajectories. The tuples serve as the training environment, and whose properties directly shape what search strategies and generalization abilities the agent can develop. While prior works have made encouraging progress in improving training data quality, existing environments remain predominantly text-based and existing approaches can struggle to construct training environments that are controllable, scalable, and account for multimodal data. Given this, we propose DocArena, a fully automated data curation pipeline building on the practical need for multimodal document search and question-answering. It transforms raw document collections into training environments for search agents without any human annotation. The pipeline first structures and indexes documents through MLLM-based visual perception, then profiles and leverage the cross-page information distribution to construct reasoning-intensive QA pairs, as well as performs cascaded quality assurance operations via MLLM. We introduce DocArena-79K with QA pairs from 8,336 documents spanning 16 domains and 49 languages. We further design a Doc-Search agent infrastructure that decouples visual perception from the policy model, allowing text-based LLMs to serve as the reasoning backbone for multimodal document retrieval and QA. Under a unified evaluation framework where only the policy model differs, experiments on six multimodal document scenarios and seven text-based QA benchmarks show that agents trained on DocArena data achieve the best performance on both retrieval accuracy and QA quality. Further analysis on agent search behaviors confirms the effectiveness and controllability of the constructed training environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DocArena, a fully automated MLLM-based pipeline that converts raw multimodal document collections into controllable (question, answer, evidence) training environments for RL-trained search agents without human annotation. It structures documents via visual perception, profiles cross-page information to generate reasoning-intensive QA pairs, applies cascaded MLLM quality assurance, and releases DocArena-79K (from 8,336 documents across 16 domains and 49 languages). A Doc-Search agent decouples visual perception from the policy model (allowing text LLMs as backbone). Under a unified framework isolating the policy, agents trained on DocArena data outperform baselines on six multimodal document scenarios and seven text-based QA benchmarks; further analysis examines search behaviors.
Significance. If the generated QA tuples are free of systematic MLLM artifacts, the work provides a scalable, annotation-free route to multimodal document search training data and a clean evaluation protocol that isolates policy effects. The fully automated nature, cross-lingual/domain coverage, and decoupling of perception from reasoning are concrete strengths that could accelerate progress in agent-based document retrieval.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central performance claim—that DocArena-trained agents achieve the best retrieval accuracy and QA quality—rests on the assumption that the MLLM pipeline produces unbiased (Q,A,E) tuples matching real document distributions. No quantitative error rates, human validation percentages, or distributional comparisons (e.g., answer-evidence alignment statistics) are reported, leaving open the possibility that reported gains reflect data artifacts rather than improved search strategies.
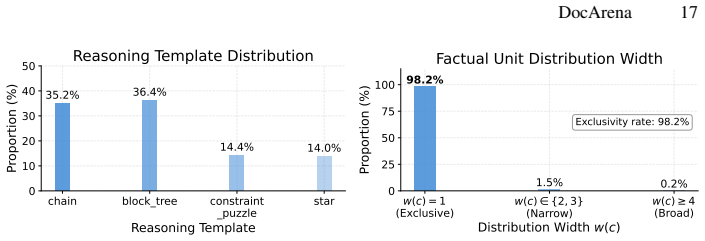
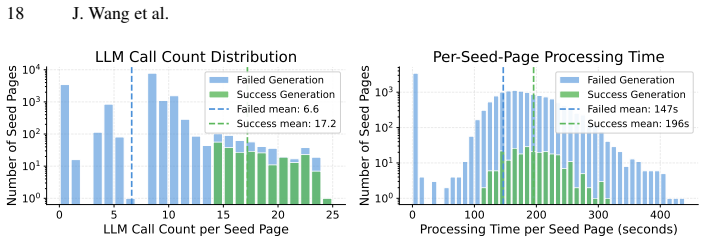
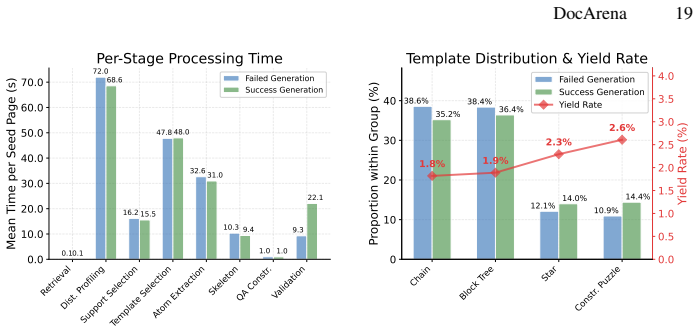
- [§3.2] §3.2 (QA pair construction): the cross-page profiling and cascaded quality assurance steps are described at a high level but lack concrete metrics (e.g., rejection rates per cascade stage, inter-MLLM agreement, or ablation on perception accuracy) that would demonstrate controllability and absence of selection bias across the six multimodal scenarios.
minor comments (2)
- [Abstract] Abstract, sentence 2: the phrasing “The tuples serve as the training environment, and whose properties” is grammatically awkward and should be revised for clarity.
- [§4] The manuscript would benefit from an explicit table listing the exact baselines, metrics (e.g., retrieval@K, QA F1), and statistical significance tests used in the unified evaluation framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of our MLLM-generated training data and the need for additional concrete metrics. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central performance claim—that DocArena-trained agents achieve the best retrieval accuracy and QA quality—rests on the assumption that the MLLM pipeline produces unbiased (Q,A,E) tuples matching real document distributions. No quantitative error rates, human validation percentages, or distributional comparisons (e.g., answer-evidence alignment statistics) are reported, leaving open the possibility that reported gains reflect data artifacts rather than improved search strategies.
Authors: We agree that direct quantitative validation of the generated tuples would strengthen the central claim. The unified evaluation framework (isolating the policy model across both multimodal document scenarios and text-based QA benchmarks) provides supporting evidence that gains arise from improved search strategies rather than artifacts alone, since text-only benchmarks are unlikely to be influenced by multimodal-specific MLLM biases. We will revise §4 to incorporate available pipeline metrics such as rejection rates from cascaded quality assurance and inter-MLLM consistency statistics. However, human validation percentages were not collected to preserve the fully automated design; we will add an explicit discussion of this limitation and its implications for interpreting the results. revision: partial
-
Referee: [§3.2] §3.2 (QA pair construction): the cross-page profiling and cascaded quality assurance steps are described at a high level but lack concrete metrics (e.g., rejection rates per cascade stage, inter-MLLM agreement, or ablation on perception accuracy) that would demonstrate controllability and absence of selection bias across the six multimodal scenarios.
Authors: We will expand §3.2 with the requested metrics, including rejection rates per cascade stage, inter-MLLM agreement rates, and an ablation on perception accuracy components, using data from our pipeline execution logs. These additions will more clearly demonstrate controllability and help address concerns about selection bias. revision: yes
- Human validation percentages for the (Q,A,E) tuples, as obtaining them would require manual annotation contrary to the fully automated pipeline design.
Circularity Check
No circularity: empirical pipeline and benchmark comparisons
full rationale
The paper describes an automated MLLM-based pipeline to generate QA pairs from raw documents and reports empirical results showing superior agent performance under a unified evaluation where only the policy model varies. No equations, derivations, fitted parameters presented as predictions, or self-citations appear in the provided text. The central claims rest on external benchmark comparisons rather than reducing to self-definitional inputs or load-bearing self-references. The derivation chain is self-contained as a standard data-generation-plus-evaluation workflow.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. In: arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: CVPR (2025)
Caffagni, D., Sarto, S., Cornia, M., Baraldi, L., Cucchiara, R.: Recurrence-enhanced vision- and-language transformers for robust multimodal document retrieval. In: CVPR (2025)
2025
-
[3]
arXiv preprint arXiv:2505.19683 (2025)
Cao, P., Men, T., Liu, W., Zhang, J., Li, X., Lin, X., Sui, D., Cao, Y ., Liu, K., Zhao, J.: Large language models for planning: A comprehensive and systematic survey. arXiv preprint arXiv:2505.19683 (2025)
-
[4]
In: arXiv preprint arXiv:2508.07493 (2025)
Chen, J., Li, M., Kil, J., Wang, C., Yu, T., Rossi, R., Zhou, T., Chen, C., Zhang, R.: Visr- bench: An empirical study on visual retrieval-augmented generation for multilingual long document understanding. In: arXiv preprint arXiv:2508.07493 (2025)
-
[5]
In: CoRR (2024)
Chen, J., Zhang, R., Zhou, Y ., Rossi, R., Gu, J., Chen, C.: Mmr: Evaluating reading ability of large multimodal models. In: CoRR (2024)
2024
-
[6]
In: ICLR (2025)
Chen, J., Zhang, R., Zhou, Y ., Yu, T., Dernoncourt, F., Gu, J., Rossi, R.A., Chen, C., Sun, T.: Sv-rag: Lora-contextualizing adaptation of mllms for long document understanding. In: ICLR (2025)
2025
-
[7]
In: CVPR (2025)
Chen, J., Xu, D., Fei, J., Feng, C.M., Elhoseiny, M.: Document haystacks: Vision-language reasoning over piles of 1000+ documents. In: CVPR (2025)
2025
-
[8]
NeurIPS (2025)
Chen, M., Sun, L., Li, T., Sun, H., Zhou, Y ., Zhu, C., Wang, H., Pan, J.Z., Zhang, W., Chen, H., et al.: Learning to reason with search for llms via reinforcement learning. NeurIPS (2025)
2025
-
[9]
arXiv preprint arXiv:2411.04952 (2024)
Cho, J., Mahata, D., Irsoy, O., He, Y ., Bansal, M.: M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding. arXiv preprint arXiv:2411.04952 (2024)
-
[10]
arXiv preprint arXiv:2602.14234 (2026) 32 J
Chu, Z., Wang, X., Hong, J., Fan, H., Huang, Y ., Yang, Y ., Xu, G., Zhao, C., Xiang, C., Hu, S., et al.: Redsearcher: A scalable and cost-efficient framework for long-horizon search agents. arXiv preprint arXiv:2602.14234 (2026) 32 J. Wang et al
-
[11]
arXiv preprint arXiv:2510.12979 (2025)
Fan, W., Yao, W., Li, Z., Yao, F., Liu, X., Qiu, L., Yin, Q., Song, Y ., Yin, B.: Deepplanner: Scaling planning capability for deep research agents via advantage shaping. arXiv preprint arXiv:2510.12979 (2025)
-
[12]
In: ICLR (2025)
Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., Colombo, P.: Colpali: Efficient document retrieval with vision language models. In: ICLR (2025)
2025
-
[13]
In: arXiv preprint arXiv:2508.07976 (2025)
Gao, J., Fu, W., Xie, M., Xu, S., He, C., Mei, Z., Zhu, B., Wu, Y .: Beyond ten turns: Un- locking long-horizon agentic search with large-scale asynchronous rl. In: arXiv preprint arXiv:2508.07976 (2025)
-
[14]
arXiv preprint arXiv:2504.04736 (2025)
Goldie, A., Mirhoseini, A., Zhou, H., Cai, I., Manning, C.D.: Synthetic data generation & multi-step rl for reasoning & tool use. arXiv preprint arXiv:2504.04736 (2025)
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. In: arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: EMNLP (2024)
Han, R., Zhang, Y ., Qi, P., Xu, Y ., Wang, J., Liu, L., Wang, W.Y ., Min, B., Castelli, V .: Rag-qa arena: Evaluating domain robustness for long-form retrieval augmented question answering. In: EMNLP (2024)
2024
-
[17]
CoRR (2025)
Han, S., Xia, P., Zhang, R., Sun, T., Li, Y ., Zhu, H., Yao, H.: Mdocagent: A multi-modal multi-agent framework for document understanding. CoRR (2025)
2025
-
[18]
In: COLING (2020)
Ho, X., Nguyen, A.K.D., Sugawara, S., Aizawa, A.: Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. In: COLING (2020)
2020
-
[19]
Hu, T., Zhao, Y ., Zhang, C., Cohan, A., Zhao, C.: Sage: Benchmarking and improving re- trieval for deep research agents (2026)
2026
-
[20]
In: arXiv preprint arXiv:2505.07596 (2025)
Huang, Z., Yuan, X., Ju, Y ., Zhao, J., Liu, K.: Reinforced internal-external knowledge syn- ergistic reasoning for efficient adaptive search agent. In: arXiv preprint arXiv:2505.07596 (2025)
-
[21]
In: arXiv preprint arXiv:2505.15117 (2025)
Jin, B., Yoon, J., Kargupta, P., Arik, S.O., Han, J.: An empirical study on reinforcement learning for reasoning-search interleaved llm agents. In: arXiv preprint arXiv:2505.15117 (2025)
-
[22]
In: COLM (2025)
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., Han, J.: Search-r1: Training llms to reason and leverage search engines with reinforcement learning. In: COLM (2025)
2025
-
[23]
In: ACL (2017)
Joshi, M., Choi, E., Weld, D.S., Zettlemoyer, L.: Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In: ACL (2017)
2017
-
[24]
In: TACL
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. In: TACL. pp. 453–466 (2019)
2019
-
[25]
In: EMNLP (2025)
Lee, J., Kwon, D., Jin, K.: Grade: Generating multi-hop qa and fine-grained difficulty matrix for rag evaluation. In: EMNLP (2025)
2025
-
[26]
arXiv preprint arXiv:2506.01710 (2025)
Lei, F., Meng, J., Huang, Y ., Chen, T., Zhang, Y ., He, S., Zhao, J., Liu, K.: Reasoning- table: Exploring reinforcement learning for table reasoning. arXiv preprint arXiv:2506.01710 (2025)
-
[27]
In: COLING (2020)
Li, M., Xu, Y ., Cui, L., Huang, S., Wei, F., Li, Z., Zhou, M.: Docbank: A benchmark dataset for document layout analysis. In: COLING (2020)
2020
-
[28]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Li, X., Jin, J., Dong, G., Qian, H., Zhu, Y ., Wu, Y ., Wen, J.R., Dou, Z.: Webthinker: Empowering large reasoning models with deep research capability. In: arXiv preprint arXiv:2504.21776 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: CVPR (2025)
Liao, W., Wang, J., Li, H., Wang, C., Huang, J., Jin, L.: Doclayllm: An efficient multi-modal extension of large language models for text-rich document understanding. In: CVPR (2025)
2025
-
[30]
In: CoRR (2024) DocArena 33
Liu, Y ., Yang, B., Liu, Q., Li, Z., Ma, Z., Zhang, S., Bai, X.: Textmonkey: An ocr-free large multimodal model for understanding document. In: CoRR (2024) DocArena 33
2024
-
[31]
In: AAAI (2025)
Livathinos, N., Auer, C., Lysak, M., Nassar, A., Dolfi, M., Vagenas, P., Ramis, C.B., Omenetti, M., Dinkla, K., Kim, Y ., et al.: Docling: An efficient open-source toolkit for ai- driven document conversion. In: AAAI (2025)
2025
-
[32]
In: arXiv preprint arXiv:2505.16282 (2025)
Lu, F., Zhong, Z., Liu, S., Fu, C.W., Jia, J.: Arpo: End-to-end policy optimization for gui agents with experience replay. In: arXiv preprint arXiv:2505.16282 (2025)
-
[33]
In: NeurIPS (2024)
Ma, Y ., Zang, Y ., Chen, L., Chen, M., Jiao, Y ., Li, X., Lu, X., Liu, Z., Ma, Y ., Dong, X., et al.: Mmlongbench-doc: Benchmarking long-context document understanding with visual- izations. In: NeurIPS (2024)
2024
-
[34]
In: ACL (2023)
Mallen, A., Asai, A., Zhong, V ., Das, R., Khashabi, D., Hajishirzi, H.: When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In: ACL (2023)
2023
-
[35]
In: arXiv preprint arXiv:2505.16582 (2025)
Mei, J., Hu, T., Fu, D., Wen, L., Yang, X., Wu, R., Cai, P., Cai, X., Gao, X., Yang, Y ., et al.: O2-searcher: A searching-based agent model for open-domain open-ended question answering. In: arXiv preprint arXiv:2505.16582 (2025)
-
[36]
In: ICLR (2026)
Miroyan, M., Wu, T.H., King, L., Li, T., Pan, J., Hu, X., Chiang, W.L., Angelopoulos, A.N., Darrell, T., Norouzi, N., Gonzalez, J.E.: Search arena: Analyzing search-augmented llms. In: ICLR (2026)
2026
-
[37]
In: CVPR (2025)
Ouyang, L., Qu, Y ., Zhou, H., Zhu, J., Zhang, R., Lin, Q., Wang, B., Zhao, Z., Jiang, M., Zhao, X., et al.: Omnidocbench: Benchmarking diverse pdf document parsing with compre- hensive annotations. In: CVPR (2025)
2025
-
[38]
In: EMNLP
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N.A., Lewis, M.: Measuring and narrow- ing the compositionality gap in language models. In: EMNLP. pp. 5687–5711 (2023)
2023
-
[39]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. In: arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., Wu, C.: Hy- bridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
In: NeurIPS (2025)
Shi, Y ., Li, S., Wu, C., Liu, Z., Fang, J., Cai, H., Zhang, A., Wang, X.: Search and refine during think: Autonomous retrieval-augmented reasoning of llms. In: NeurIPS (2025)
2025
-
[42]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Song, H., Jiang, J., Min, Y ., Chen, J., Chen, Z., Zhao, W.X., Fang, L., Wen, J.R.: R1-searcher: Incentivizing the search capability in llms via reinforcement learning. In: arXiv preprint arXiv:2503.05592 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
NeurIPS (2025)
Stojanovski, Z., Stanley, O., Sharratt, J., Jones, R., Adefioye, A., Kaddour, J., Köpf, A.: Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards. NeurIPS (2025)
2025
-
[44]
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
Sun, H., Qiao, Z., Guo, J., Fan, X., Hou, Y ., Jiang, Y ., Xie, P., Zhang, Y ., Huang, F., Zhou, J.: Zerosearch: Incentivize the search capability of llms without searching. In: arXiv preprint arXiv:2505.04588 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
In: CVPR (2025)
Tanaka, R., Iki, T., Hasegawa, T., Nishida, K., Saito, K., Suzuki, J.: Vdocrag: Retrieval- augmented generation over visually-rich documents. In: CVPR (2025)
2025
-
[46]
In: AAAI (2023)
Tanaka, R., Nishida, K., Nishida, K., Hasegawa, T., Saito, I., Saito, K.: Slidevqa: A dataset for document visual question answering on multiple images. In: AAAI (2023)
2023
-
[47]
In: COLM (2024)
Tang, Y ., Yang, Y .: Multihop-rag: Benchmarking retrieval-augmented generation for multi- hop queries. In: COLM (2024)
2024
-
[48]
Team, Q., et al.: Qwen2 technical report. arXiv preprint arXiv:2407.106712(3) (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
In: ICCV (2025)
Tian, Y ., Lu, Z., Gao, M., Liu, Z., Zhao, B.: Mmcr: Benchmarking cross-source reasoning in scientific papers. In: ICCV (2025)
2025
-
[50]
In: TACL
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Musique: Multihop questions via single-hop question composition. In: TACL. vol. 10, pp. 539–554 (2022)
2022
-
[51]
In: ICDAR (2023) 34 J
Turski, M., Stanisławek, T., Kaczmarek, K., Dyda, P., Grali ´nski, F.: Ccpdf: Building a high quality corpus for visually rich documents from web crawl data. In: ICDAR (2023) 34 J. Wang et al
2023
-
[52]
In: ACL (2024)
Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y ., Nourbakhsh, A., Liu, X.: DocLLM: A layout-aware generative language model for multimodal document understanding. In: ACL (2024)
2024
-
[53]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., Wei, F.: Text em- beddings by weakly-supervised contrastive pre-training. In: arXiv preprint arXiv:2212.03533 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
In: NeurIPS (2025)
Wang, Q., Ding, R., Zeng, Y ., Chen, Z., Chen, L., Wang, S., Xie, P., Huang, F., Zhao, F.: Vrag-rl: Empower vision-perception-based rag for visually rich information understanding via iterative reasoning with reinforcement learning. In: NeurIPS (2025)
2025
-
[55]
In: EMNLP (2025)
Wang, Z., Zheng, X., An, K., Ouyang, C., Cai, J., Wang, Y ., Wu, Y .: Stepsearch: Igniting llms search ability via step-wise proximal policy optimization. In: EMNLP (2025)
2025
-
[56]
In: CVPR (2025)
Wang, Z., Guan, T., Fu, P., Duan, C., Jiang, Q., Guo, Z., Guo, S., Luo, J., Shen, W., Yang, X.: Marten: Visual question answering with mask generation for multi-modal document un- derstanding. In: CVPR (2025)
2025
-
[57]
In: arXiv preprint arXiv:2505.16421 (2025)
Wei, Z., Yao, W., Liu, Y ., Zhang, W., Lu, Q., Qiu, L., Yu, C., Xu, P., Zhang, C., Yin, B., et al.: Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning. In: arXiv preprint arXiv:2505.16421 (2025)
-
[58]
MMSearch-R1: Incentivizing LMMs to Search
Wu, J., Deng, Z., Li, W., Liu, Y ., You, B., Li, B., Ma, Z., Liu, Z.: Mmsearch-r1: Incentivizing lmms to search. In: arXiv preprint arXiv:2506.20670 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
In: ACL (2025)
Wu, J., Xia, Y ., Yu, T., Chen, X., Harsha, S.S., Maharaj, A.V ., Zhang, R., Bursztyn, V ., Kim, S., Rossi, R.A., McAuley, J., Li, Y ., Sinha, R.: Doc-react: Multi-page heterogeneous document question-answering. In: ACL (2025)
2025
-
[60]
In: arXiv preprint arXiv:2505.20285 (2025)
Wu, W., Guan, X., Huang, S., Jiang, Y ., Xie, P., Huang, F., Cao, J., Zhao, H., Zhou, J.: Masksearch: A universal pre-training framework to enhance agentic search capability. In: arXiv preprint arXiv:2505.20285 (2025)
-
[61]
In: EMNLP (2025)
Wu, X., Tan, Y ., Hou, N., Zhang, R., Cheng, H.: Molorag: Bootstrapping document under- standing via multi-modal logic-aware retrieval. In: EMNLP (2025)
2025
-
[62]
In: CVPR (2025)
Xiao, H., Xie, Y ., Tan, G., Chen, Y ., Hu, R., Wang, K., Zhou, A., Li, H., Shao, H., Lu, X., et al.: Adaptive markup language generation for contextually-grounded visual document understanding. In: CVPR (2025)
2025
-
[63]
In: ICCV (2025)
Yang, Z., Tang, J., Li, Z., Wang, P., Wan, J., Zhong, H., Liu, X., Yang, M., Wang, P., Bai, S., et al.: Cc-ocr: A comprehensive and challenging ocr benchmark for evaluating large multi- modal models in literacy. In: ICCV (2025)
2025
-
[64]
In: EMNLP (2018)
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W.W., Salakhutdinov, R., Manning, C.D.: Hot- potqa: A dataset for diverse, explainable multi-hop question answering. In: EMNLP (2018)
2018
-
[65]
Structured In-context Environment Scaling for Large Language Model Reasoning
Yu, P., Zhao, Z., Zhang, S., Fu, L., Wang, X., Wen, Y .: Learning to reason in structured in- context environments with reinforcement learning. arXiv preprint arXiv:2509.23330 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al.: Dapo: An open-source llm reinforcement learning system at scale. In: arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
In: NeurIPS (2024)
Yu, Y ., Ping, W., Liu, Z., Wang, B., You, J., Zhang, C., Shoeybi, M., Catanzaro, B.: Rankrag: Unifying context ranking with retrieval-augmented generation in llms. In: NeurIPS (2024)
2024
-
[68]
arXiv preprint arXiv:2506.00789 (2025)
Zeng, Y ., Cao, T., Wang, D., Zhao, X., Qiu, Z., Ziyadi, M., Wu, T., Li, L.: Rare: Retrieval- aware robustness evaluation for retrieval-augmented generation systems. arXiv preprint arXiv:2506.00789 (2025)
-
[69]
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Zeng, Z., Ivison, H., Wang, Y ., Yuan, L., Li, S.S., Ye, Z., Li, S., He, J., Zhou, R., Chen, T., et al.: Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments. arXiv preprint arXiv:2511.07317 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
In: NeurIPS (2025) DocArena 35
Zhang, H., Feng, T., You, J.: Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. In: NeurIPS (2025) DocArena 35
2025
-
[71]
arXiv preprint arXiv:2601.05163 (2026)
Zhang, Q., Lv, X., Wu, J., Li, B., Tao, Z., Yan, G., Zhang, H., Wang, B., Xu, J., Mi, H., et al.: Docdancer: Towards agentic document-grounded information seeking. arXiv preprint arXiv:2601.05163 (2026)
-
[72]
Zhao, Q., Wang, R., Xu, D., Zha, D., Liu, L.: R-search: Empowering llm reasoning with search via multi-reward reinforcement learning. In: arXiv preprint arXiv:2506.04185 (2025)
-
[73]
In: EMNLP (2025)
Zheng, Y ., Fu, D., Hu, X., Cai, X., Ye, L., Lu, P., Liu, P.: Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. In: EMNLP (2025)
2025
-
[74]
In: CVPR (2025)
Zhu, Z., Luo, C., Shao, Z., Gao, F., Xing, H., Zheng, Q., Zhang, J.: A simple yet effective layout token in large language models for document understanding. In: CVPR (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.