Einstein World Models
Pith reviewed 2026-06-26 04:45 UTC · model grok-4.3
The pith
LLMs can call a world-module to insert short visual-temporal rollouts as inspectable hypotheses inside their reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
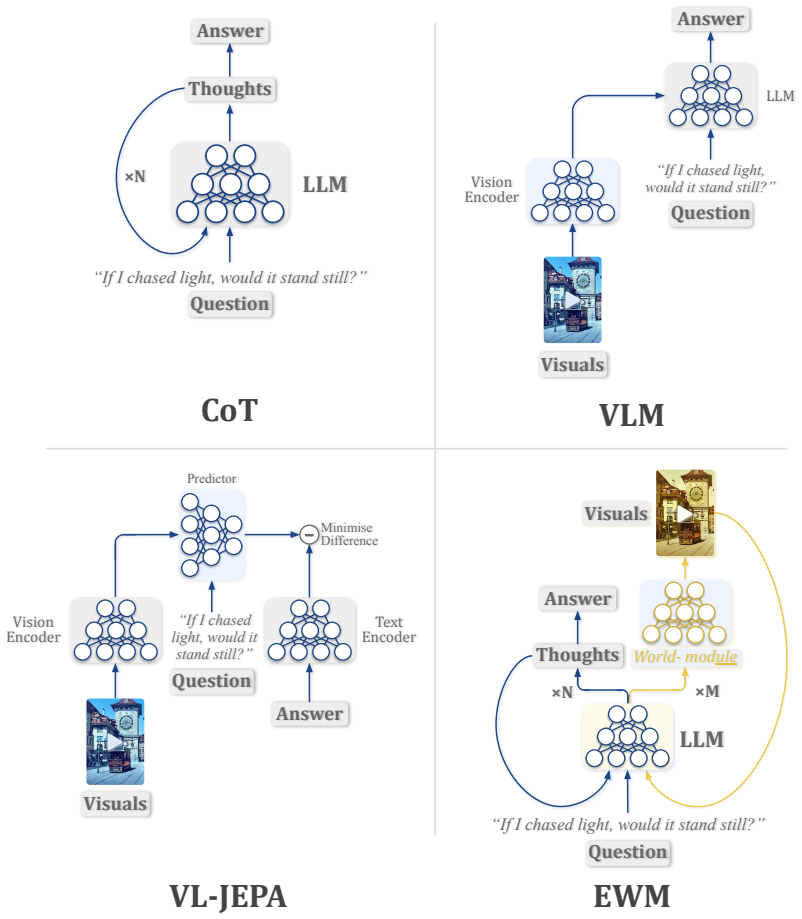
Einstein World Models are a blueprint for LLM-based reasoning systems that place visual-temporal rollouts inside the reasoning trace, allowing them to reason in ways that text alone may not support well. In an EWM, the LLM calls a world-module to produce short rollouts of scenes under consideration. The returned rollout is treated not as the answer, but as an inspectable hypothesis that can support later reasoning. Einstein World Models extend the capability of LLMs for tool calling into the domain of visual thought experiments.
What carries the argument
The world-module that an LLM calls to produce short visual-temporal rollouts of scenes, which are then inserted into the reasoning trace as inspectable hypotheses rather than final outputs.
If this is right
- LLM reasoning traces can incorporate visual simulations of scenes without requiring the rollout to serve as the final answer.
- Tool-calling in LLMs extends from text-based tools to visual thought experiments.
- Reasoning about phenomena beyond direct experience becomes possible through inspectable visual hypotheses.
- Complex thought that resists language-only capture can be supported by short scene rollouts generated on demand.
Where Pith is reading between the lines
- Hybrid LLM-plus-world-module systems could be tested first on spatial or physical counterfactual tasks where text descriptions are known to be ambiguous.
- If the rollouts remain short and inspectable, they might reduce the length of text-based chain-of-thought needed for certain problems.
- The same calling pattern could later be applied to other non-text modalities such as audio or structured data simulations.
Load-bearing premise
A world-module exists that can reliably produce short, useful, inspectable visual rollouts that integrate into LLM reasoning without introducing new errors.
What would settle it
An experiment in which LLMs using the proposed visual-rollout mechanism show no accuracy gain over text-only baselines on tasks that require counterfactual visual reasoning.
Figures

read the original abstract
Does intelligence require the ability to reason about phenomena beyond direct experience? It is natural to suspect that some complex thought cannot be captured through language alone. However, of particular concern to this work, is whether visualising counterfactual events can complement language as a mechanism for complex thought. We ask whether LLMs can be trained to utilise such visualisation mechanisms, in a way that benefits their reasoning abilities. Motivated by this question, we propose Einstein World Models. EWMs are a blueprint for LLM-based reasoning systems that place visual-temporal rollouts inside the reasoning trace, allowing them to reason in ways that text alone may not support well. In an EWM, the LLM calls a world-module (not to be confused with a world model), to produce short rollouts of scenes under consideration. The returned rollout is treated not as the answer, but as an inspectable hypothesis that can support later reasoning. Einstein World Models extend the capability of LLMs for tool calling (such as web search or code execution), into the domain of visual thought experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Einstein World Models (EWMs) as a high-level blueprint for LLM-based reasoning systems. In an EWM the LLM invokes an unspecified world-module to generate short visual-temporal rollouts of scenes; these rollouts are treated as inspectable hypotheses inside the reasoning trace rather than as final answers, thereby extending existing tool-calling mechanisms into the domain of visual thought experiments.
Significance. If a reliable world-module existed and could be integrated without introducing new errors, the approach would constitute a concrete architectural extension of tool use to multimodal counterfactual reasoning. The manuscript itself, however, contains no implementation, training objective, interface specification, or empirical result, so the claimed benefit remains entirely speculative.
major comments (2)
- [Abstract] Abstract: the central claim that visual-temporal rollouts enable reasoning 'in ways that text alone may not support well' is asserted without any derivation, illustrative example, error model, or experimental evidence; the claim is therefore unevaluable.
- [Abstract] Abstract and proposal description: the world-module is introduced as a black-box primitive whose existence and reliability are assumed, yet no architecture, training procedure, output format, or failure modes are supplied; this assumption is load-bearing for every subsequent claim about integration and benefit.
Simulated Author's Rebuttal
We thank the referee for their review. The manuscript is a conceptual proposal for an architectural blueprint rather than an empirical study, and we address the two major comments below by clarifying intent and offering targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that visual-temporal rollouts enable reasoning 'in ways that text alone may not support well' is asserted without any derivation, illustrative example, error model, or experimental evidence; the claim is therefore unevaluable.
Authors: We agree the claim is presented without supporting derivation or evidence. The paper is framed as a high-level proposal motivated by the opening question on limitations of language for certain reasoning tasks, drawing an intuitive parallel to human visualization in thought experiments. We will revise the abstract and introduction to explicitly label the benefit as a hypothesis to be tested in future work rather than an asserted capability. revision: partial
-
Referee: [Abstract] Abstract and proposal description: the world-module is introduced as a black-box primitive whose existence and reliability are assumed, yet no architecture, training procedure, output format, or failure modes are supplied; this assumption is load-bearing for every subsequent claim about integration and benefit.
Authors: The world-module is intentionally left as an open modular interface, analogous to how tool-calling papers assume external APIs without specifying their internals. We acknowledge that the lack of even high-level interface assumptions or failure-mode discussion weakens the proposal. We will add a dedicated subsection describing assumed input/output formats, reliability requirements, and example failure modes in the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal without derivations or fits
full rationale
The paper is a conceptual blueprint for LLM reasoning systems that incorporate visual-temporal rollouts via an assumed world-module. No equations, parameter fits, predictions, or derivation chains appear in the provided text. The central claim is an architectural suggestion extending tool-calling, not a reduction of any output to fitted inputs or self-citations. The world-module is treated as a black-box primitive whose reliability is an open assumption, not a self-defined or self-derived quantity. This is a standard non-circular proposal of a system design.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Some complex thought cannot be captured through language alone and benefits from visual counterfactuals.
- ad hoc to paper A callable world-module can produce short rollouts that function as inspectable hypotheses inside an LLM trace.
invented entities (1)
-
world-module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , month = oct, day =
SimpleBench: The Text Benchmark in which Unspecialized Human Performance Exceeds that of Current Frontier Models , author =. 2024 , month = oct, day =
2024
-
[2]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =
Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding , author =. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =. 2021 , publisher =. doi:10.18653/v1/2021.findings-emnlp.422 , url =
-
[3]
Tracking State Changes in Procedural Text: A Challenge Dataset and Models for Process Paragraph Comprehension , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 , pages =. 2018 , publisher =. doi:10.18653/v1/N18-1144 , url =
-
[4]
Entity Tracking in Language Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Volume 1 , pages =. 2023 , publisher =. doi:10.18653/v1/2023.acl-long.213 , url =
-
[5]
Ghosh, Sayontan and Koupaee, Mahnaz and Chen, Isabella and Ferraro, Francis and Chambers, Nathanael and Balasubramanian, Niranjan , journal =. 2023 , publisher =. doi:10.1162/tacl_a_00600 , url =
-
[6]
2022 , doi =
Shi, Zhengxiang and Zhang, Qiang and Lipani, Aldo , booktitle =. 2022 , doi =
2022
-
[7]
Mirzaee, Roshanak and Rajaby Faghihi, Hossein and Ning, Qiang and Kordjamshidi, Parisa , booktitle =. 2021 , publisher =. doi:10.18653/v1/2021.naacl-main.364 , url =
-
[8]
and van Merrienboer, Bart , journal =
Weston, Jason and Bordes, Antoine and Chopra, Sumit and Mikolov, Tomas and Rush, Alexander M. and van Merrienboer, Bart , journal =. Towards. 2015 , url =
2015
-
[9]
CLUTRR : A Diagnostic Benchmark for Inductive Reasoning from Text
Sinha, Koustuv and Sodhani, Shagun and Dong, Jin and Pineau, Joelle and Hamilton, William L. , booktitle =. 2019 , publisher =. doi:10.18653/v1/D19-1458 , url =
-
[10]
doi:10.18653/v1/2023.findings-acl.824 , url =
Suzgun, Mirac and Scales, Nathan and Scharli, Nathanael and Gehrmann, Sebastian and Tay, Yi and Chung, Hyung Won and Chowdhery, Aakanksha and Le, Quoc and Chi, Ed and Zhou, Denny and Wei, Jason , booktitle =. Challenging. 2023 , publisher =. doi:10.18653/v1/2023.findings-acl.824 , url =
-
[11]
2020 , doi =
Bisk, Yonatan and Zellers, Rowan and Le Bras, Ronan and Gao, Jianfeng and Choi, Yejin , booktitle =. 2020 , doi =
2020
-
[12]
H ella S wag: Can a Machine Really Finish Your Sentence?
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle =. 2019 , publisher =. doi:10.18653/v1/P19-1472 , url =
-
[13]
SWAG: A large- scale adversarial dataset for grounded commonsense inference
Zellers, Rowan and Bisk, Yonatan and Schwartz, Roy and Choi, Yejin , booktitle =. 2018 , publisher =. doi:10.18653/v1/D18-1009 , url =
-
[14]
Huang, Lifu and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , booktitle =. Cosmos. 2019 , publisher =. doi:10.18653/v1/D19-1243 , url =
-
[15]
``Going on a vacation'' takes longer than ``Going for a walk'': A Study of Temporal Commonsense Understanding , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =. 2019 , publisher =. doi:10.18653/v1/D19-1332 , url =
-
[16]
Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin , booktitle =. Social. 2019 , publisher =. doi:10.18653/v1/D19-1454 , url =
-
[17]
International Conference on Learning Representations , year =
Abductive Commonsense Reasoning , author =. International Conference on Learning Representations , year =
-
[18]
AAAI Spring Symposium on Logical Formalizations of Commonsense Reasoning , year =
Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning , author =. AAAI Spring Symposium on Logical Formalizations of Commonsense Reasoning , year =
-
[19]
, booktitle =
Yi, Kexin and Gan, Chuang and Li, Yunzhu and Kohli, Pushmeet and Wu, Jiajun and Torralba, Antonio and Tenenbaum, Joshua B. , booktitle =. 2020 , url =
2020
-
[20]
2019 , url =
Bakhtin, Anton and van der Maaten, Laurens and Johnson, Justin and Gustafson, Laura and Girshick, Ross , booktitle =. 2019 , url =
2019
-
[21]
and Williams, Adina and Rabbat, Michael and Dupoux, Emmanuel , year =
Bordes, Florian and Garrido, Quentin and Kao, Justine T. and Williams, Adina and Rabbat, Michael and Dupoux, Emmanuel , year =. 2506.09849 , archivePrefix =
-
[22]
2021 , volume =
Shu, Tianmin and Bhandwaldar, Abhishek and Gan, Chuang and Smith, Kevin and Liu, Shari and Gutfreund, Dan and Spelke, Elizabeth and Tenenbaum, Joshua and Ullman, Tomer , booktitle =. 2021 , volume =
2021
-
[23]
Zheng, Huaixiu Steven and Mishra, Swaroop and Zhang, Hugh and Chen, Xinyun and Chen, Minmin and Nova, Azade and Hou, Le and Cheng, Heng-Tze and Le, Quoc V. and Chi, Ed H. and Zhou, Denny , year =. 2406.04520 , archivePrefix =
-
[24]
2023 , url =
Valmeekam, Karthik and Marquez, Matthew and Olmo, Alberto and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle =. 2023 , url =
2023
-
[25]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[26]
Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.1117 , url =
-
[27]
Mind's Eye of
Wu, Wenshan and Mao, Shaoguang and Zhang, Yadong and Xia, Yan and Dong, Li and Cui, Lei and Wei, Furu , booktitle =. Mind's Eye of. 2024 , url =
2024
-
[28]
arXiv preprint arXiv:2505.22525 , year=
Thinking with Generated Images , author=. arXiv preprint arXiv:2505.22525 , year=
-
[29]
2025 , eprint =
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm , author =. 2025 , eprint =
2025
-
[30]
Advances in Neural Information Processing Systems , volume=
Seephys: Does seeing help thinking?--benchmarking vision-based physics reasoning , author=. Advances in Neural Information Processing Systems , volume=. 2026 , url =
2026
-
[31]
Greff, Klaus and Belletti, Francois and Beyer, Lucas and Doersch, Carl and Du, Yilun and Duckworth, Daniel and Fleet, David J. and Gnanapragasam, Dan and Golemo, Florian and Herrmann, Charles and Kipf, Thomas and Kundu, Abhijit and Lagun, Dmitry and Laradji, Issam and Liu, Hsueh-Ti and Meyer, Henning and Miao, Yishu and Nowrouzezahrai, Derek and Oztireli,...
2022
-
[32]
and Wang, Elias and Mrowca, Damian and Binder, Felix J
Bear, Daniel M. and Wang, Elias and Mrowca, Damian and Binder, Felix J. and Tung, Hsiao-Yu Fish and Pramod, R. T. and Holdaway, Cameron and Tao, Sirui and Smith, Kevin A. and Sun, Fan-Yun and Fei-Fei, Li and Kanwisher, Nancy and Tenenbaum, Joshua B. and Yamins, Daniel L. K. and Fan, Judith E. , booktitle =. 2021 , url =
2021
-
[33]
Riochet, Ronan and Castro, Mario Ynocente and Bernard, Mathieu and Lerer, Adam and Fergus, Rob and Izard, V. 2018 , eprint =. doi:10.48550/arXiv.1803.07616 , url =
-
[34]
Upadhyay, Rishi and Zhang, Howard and Solomon, Jim and Agrawal, Ayush and Boreddy, Pranay and Satya Narayana, Shruti and Ba, Yunhao and Wong, Alex and de Melo, Celso M. and Kadambi, Achuta , year =. doi:10.48550/arXiv.2601.21282 , url =. 2601.21282 , archivePrefix =
-
[35]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=. 2022 , url =
2022
-
[36]
arXiv preprint arXiv:2603.19312 , year=
Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels , author=. arXiv preprint arXiv:2603.19312 , year=
-
[37]
arXiv preprint arXiv:2510.11512 , year=
Likephys: Evaluating intuitive physics understanding in video diffusion models via likelihood preference , author=. arXiv preprint arXiv:2510.11512 , year=
-
[38]
2026 , eprint =
Discovering High Level Patterns from Simulation Traces , author =. 2026 , eprint =
2026
-
[39]
Chia, Yew Ken and Toh, Vernon and Ghosal, Deepanway and Bing, Lidong and Poria, Soujanya , booktitle =. 2024 , address =. doi:10.18653/v1/2024.findings-acl.962 , url =
-
[40]
2025 , eprint =
Chollet, Fran. 2025 , eprint =
2025
-
[41]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[42]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the. 2021 , url =
2021
-
[43]
International Conference on Learning Representations , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations , year =
-
[44]
2024 , url =
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , booktitle =. 2024 , url =
2024
-
[45]
2024 , url =
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , booktit...
2024
-
[46]
2021 , url =
Nakano, Reiichiro and Hilton, Jacob and Balaji, Suchir and Wu, Jeff and Ouyang, Long and Kim, Christina and Hesse, Christopher and Jain, Shantanu and Kosaraju, Vineet and Saunders, William and Jiang, Xu and Cobbe, Karl and Eloundou, Tyna and Krueger, Gretchen and Button, Kevin and Knight, Matthew and Chess, Benjamin and Schulman, John , journal =. 2021 , url =
2021
-
[47]
2023 , editor =
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , booktitle =. 2023 , editor =
2023
-
[48]
Transactions on Machine Learning Research , year =
Augmented Language Models: A Survey , author =. Transactions on Machine Learning Research , year =
-
[49]
Advances in Neural Information Processing Systems , volume =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[50]
and Cao, Yuan , booktitle =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik R. and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[51]
Advances in Neural Information Processing Systems , volume =
Gorilla: Large Language Model Connected with Massive APIs , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[52]
1945 , url =
An Essay on the Psychology of Invention in the Mathematical Field , author =. 1945 , url =
1945
-
[53]
Albert Einstein: Philosopher-Scientist , editor =
Autobiographical Notes , author =. Albert Einstein: Philosopher-Scientist , editor =. 1949 , pages =
1949
-
[54]
Historical Studies in the Physical and Biological Sciences , volume =
Einstein's Kyoto Address: ``How I Created the Theory of Relativity'' , author =. Historical Studies in the Physical and Biological Sciences , volume =. 2000 , url =
2000
-
[55]
Einstein's Clocks, Poincar
Galison, Peter , publisher =. Einstein's Clocks, Poincar. 2003 , isbn =
2003
-
[56]
Neuron , volume =
Mnemonic Training Reshapes Brain Networks to Support Superior Memory , author =. Neuron , volume =. 2017 , doi =
2017
-
[57]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Bizarre Imagery as an Effective Memory Aid: The Importance of Distinctiveness , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 1986 , doi =
1986
-
[58]
Imagery and Verbal Processes , author =
-
[59]
The Twelfth International Conference on Learning Representations , year =
Learning Interactive Real-World Simulators , author =. The Twelfth International Conference on Learning Representations , year =
-
[60]
2024 , howpublished =
Video Generation Models as World Simulators , author =. 2024 , howpublished =
2024
-
[61]
International Conference on Machine Learning , year =
How Far Is Video Generation from World Model: A Physical Law Perspective , author =. International Conference on Machine Learning , year =
-
[62]
2025 , url =
Bansal, Hritik and Lin, Zongyu and Xie, Tianyi and Zong, Zeshun and Yarom, Michal and Bitton, Yonatan and Jiang, Chenfanfu and Sun, Yizhou and Chang, Kai-Wei and Grover, Aditya , booktitle =. 2025 , url =
2025
-
[63]
2026 , url =
Bansal, Hritik and Peng, Clark and Bitton, Yonatan and Goldenberg, Roman and Grover, Aditya and Chang, Kai-Wei , booktitle =. 2026 , url =
2026
-
[64]
Guo, Xuyang and Huo, Jiayan and Shi, Zhenmei and Song, Zhao and Zhang, Jiahao and Zhao, Jiale , year =. 2505.00337 , archivePrefix =
-
[65]
Zhang, Chenyu and Cherniavskii, Daniil and Zadaianchuk, Andrii and Tragoudaras, Antonios and Vozikis, Antonios and Nijdam, Thijmen and Prinzhorn, Derck W. E. and Bodracska, Mark and Sebe, Nicu and Gavves, Efstratios , year =. 2504.02918 , archivePrefix =
-
[66]
2025 , eprint =
Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos , author =. 2025 , eprint =
2025
-
[67]
and Stoica, Ion and Han, Song and Lu, Yao , booktitle =
Li, Dacheng and Fang, Yunhao and Chen, Yukang and Yang, Shuo and Cao, Shiyi and Wong, Justin and Luo, Michael and Wang, Xiaolong and Yin, Hongxu and Gonzalez, Joseph E. and Stoica, Ion and Han, Song and Lu, Yao , booktitle =. 2025 , url =
2025
-
[68]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , year =
Do Generative Video Models Understand Physical Principles? , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , year =
-
[69]
International Conference on Learning Representations , year =
NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics , author =. International Conference on Learning Representations , year =
-
[70]
Transactions on Machine Learning Research , issn =
Revisiting Feature Prediction for Learning Visual Representations from Video , author =. Transactions on Machine Learning Research , issn =. 2024 , url =
2024
-
[71]
2022 , eprint =
Joint Embedding Predictive Architectures Focus on Slow Features , author =. 2022 , eprint =
2022
-
[72]
Live: Learning video llm with stream- ing speech transcription at scale
Goswami, Raktim Gautam and Krishnamurthy, Prashanth and LeCun, Yann and Khorrami, Farshad , booktitle =. 2025 , pages =. doi:10.1109/CVPR52734.2025.00650 , url =
-
[73]
2025 , pages =
Zhou, Gaoyue and Pan, Hengkai and LeCun, Yann and Pinto, Lerrel , booktitle =. 2025 , pages =
2025
-
[74]
Sobal, Vlad and Zhang, Wancong and Cho, Kyunghyun and Balestriero, Randall and Rudner, Tim G. J. and LeCun, Yann , booktitle =. 2025 , url =
2025
-
[75]
Assran, Mido and Bardes, Adrien and Fan, David and Garrido, Quentin and Howes, Russell and Komeili, Mojtaba and Muckley, Matthew and Rizvi, Ammar and Roberts, Claire and Sinha, Koustuv and Zholus, Artem and Arnaud, Sergio and Gejji, Abha and Martin, Ada and Hogan, Francois Robert and Dugas, Daniel and Bojanowski, Piotr and Khalidov, Vasil and Labatut, Pat...
-
[76]
2025 , url =
Goswami, Raktim Gautam and Krishnamurthy, Prashanth and LeCun, Yann and Khorrami, Farshad , booktitle =. 2025 , url =
2025
-
[77]
Value-Guided Action Planning with
Destrade, Matthieu and Bounou, Oumayma and Le Lidec, Quentin and Ponce, Jean and LeCun, Yann , year =. Value-Guided Action Planning with. 2601.00844 , archivePrefix =
-
[78]
2025 , eprint =
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models? , author =. 2025 , eprint =
2025
-
[79]
Nam, Heejeong and Le Lidec, Quentin and Maes, Lucas and LeCun, Yann and Balestriero, Randall , year =. 2602.11389 , archivePrefix =
-
[80]
2026 , eprint =
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.