Heavy-Ball Q-Learning with Residual Weighting Correction
Pith reviewed 2026-06-26 05:15 UTC · model grok-4.3
The pith
A corrected heavy-ball Q-learning method converges and accelerates compared to standard Q-learning under joint spectral radius conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The corrected heavy-ball Q-learning method is theoretically guaranteed to converge and converges faster than standard Q-learning under identified conditions; analogous convergence and acceleration statements hold for the linear function approximation case. The analysis rests on representing the algorithms as switched linear systems and bounding their joint spectral radius.
What carries the argument
Switched linear system representation of the Q-learning updates together with joint spectral radius analysis of the associated switching family.
If this is right
- The corrected method converges to the optimal Q-function whenever the joint spectral radius is less than one.
- Faster convergence than standard Q-learning occurs precisely when the joint spectral radius of the corrected family is smaller than that of the standard family.
- The same convergence and acceleration guarantees apply when linear function approximation is introduced.
- The switched linear system model supplies an alternative analytical route for studying momentum corrections in Q-learning.
Where Pith is reading between the lines
- The switched linear system lens could be used to derive corrections for other momentum variants such as Nesterov acceleration.
- Parameter choices that minimize the joint spectral radius may directly improve practical convergence speed.
- The framework might extend to analyzing momentum in related algorithms such as SARSA or actor-critic methods.
Load-bearing premise
The switched linear system representation accurately captures the dynamics of the heavy-ball Q-learning updates, allowing the joint spectral radius analysis to determine convergence and acceleration.
What would settle it
A concrete computation or simulation in which the joint spectral radius of the corrected method exceeds one yet the iterates still converge, or in which the radius is strictly smaller than that of standard Q-learning yet no speedup occurs.
Figures
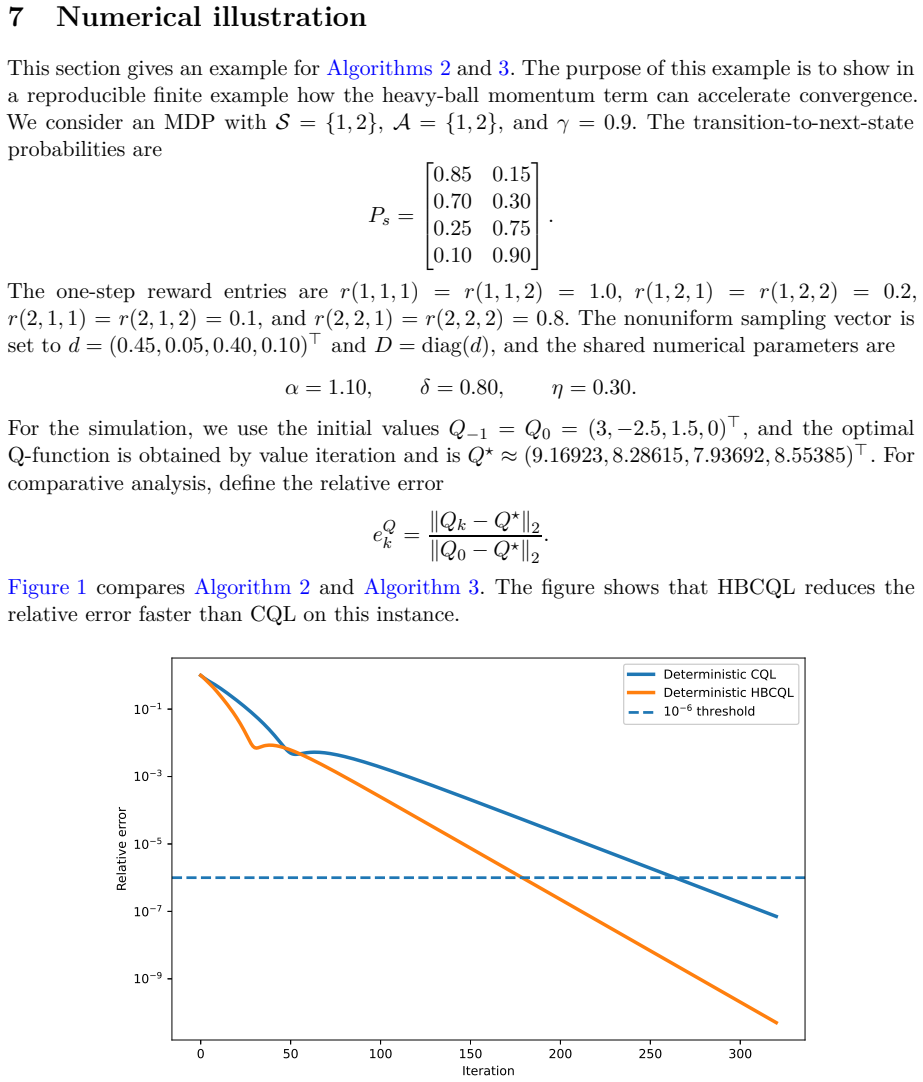
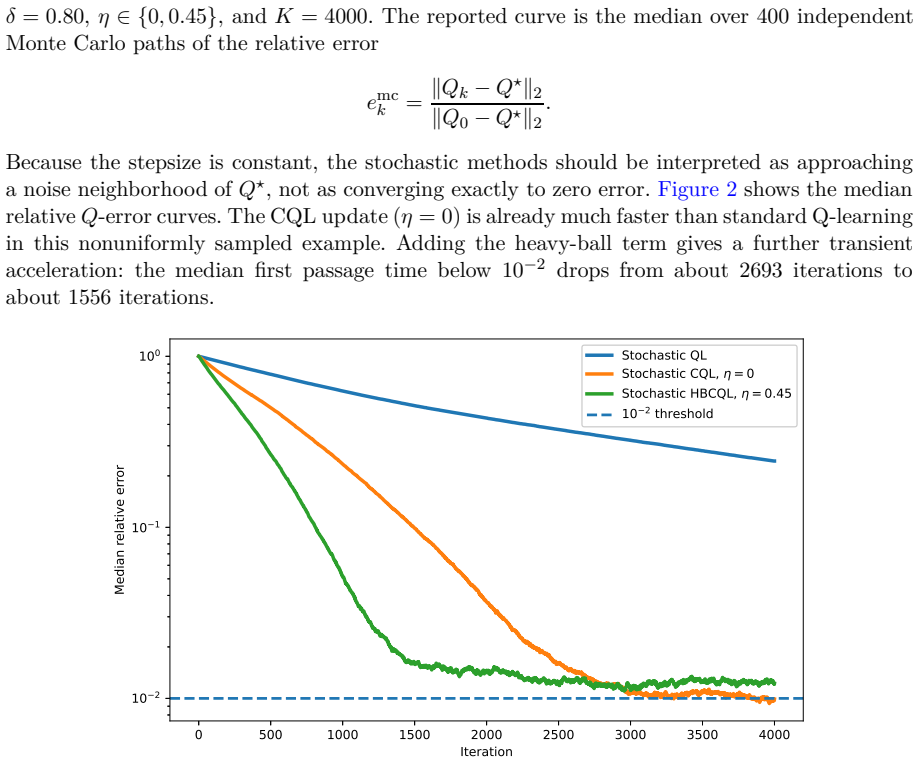
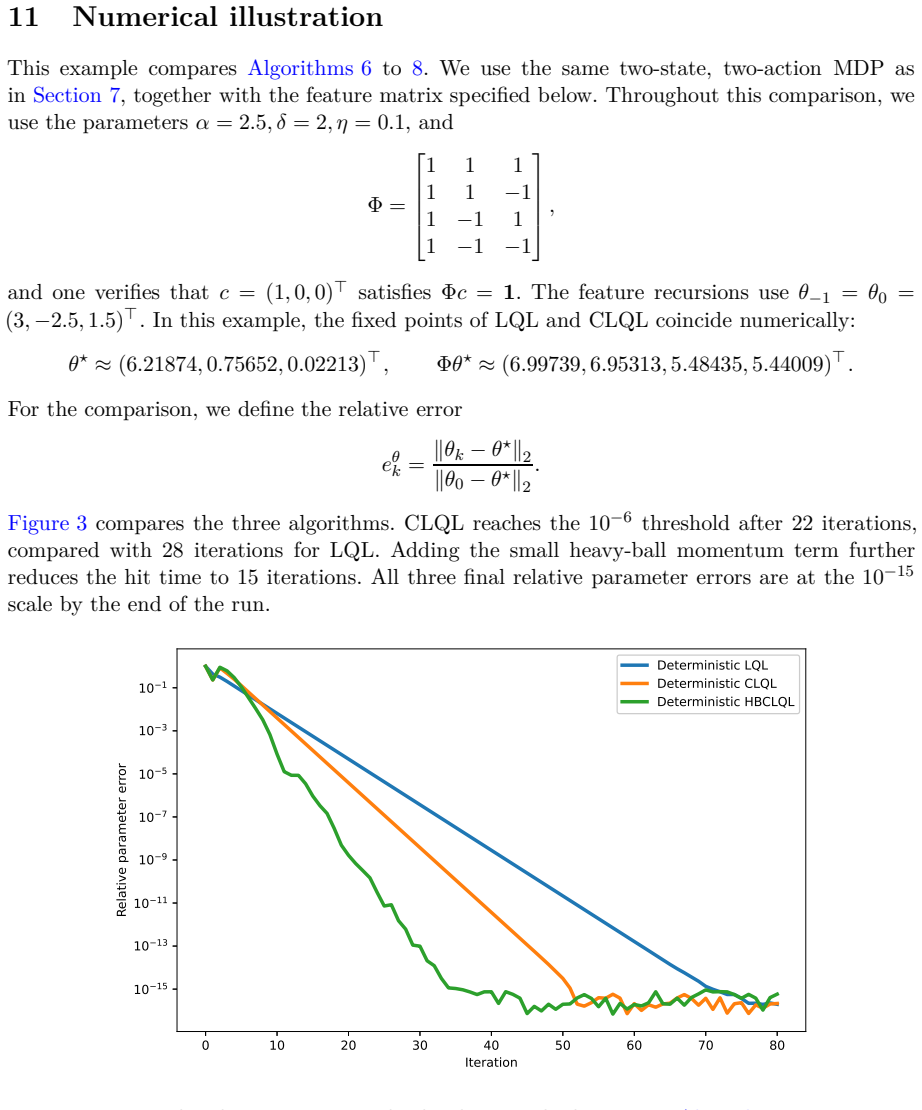
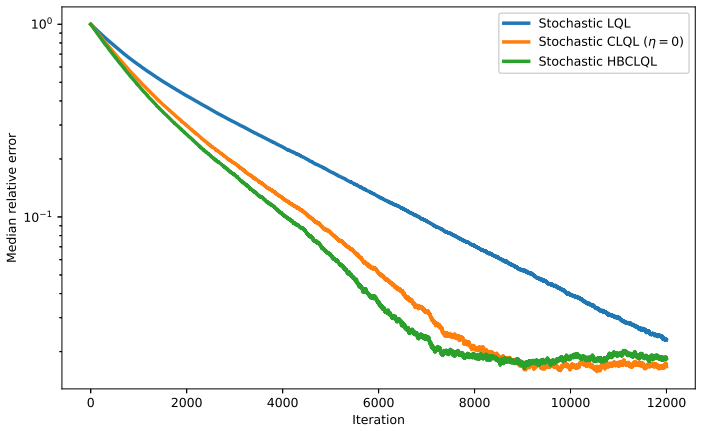
read the original abstract
This paper proposes a corrected heavy-ball Q-learning method for reinforcement learning (RL) and establishes its convergence. It also identifies conditions under which the method is theoretically guaranteed to converge faster than standard Q-learning. The same construction is then extended to Q-learning with linear function approximation, where analogous convergence and acceleration statements are derived. The analysis is based on a switched linear system (SLS) representation of Q-learning algorithms and on the joint spectral radius (JSR) of the associated switching families. This SLS viewpoint is not commonly used in standard analyses of Q-learning, and it provides a complementary framework and new insight into how heavy-ball momentum can accelerate Q-learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a corrected heavy-ball Q-learning method incorporating residual weighting correction. It claims to establish convergence (and identify conditions for faster convergence than standard Q-learning) via a switched linear system (SLS) representation of the updates together with joint spectral radius (JSR) analysis of the associated switching families. The same SLS+JSR construction is extended to Q-learning with linear function approximation, yielding analogous convergence and acceleration statements. The SLS viewpoint is presented as a complementary, non-standard framework for analyzing momentum in Q-learning.
Significance. If the central claims hold, the work supplies a novel analytical tool (SLS representation + JSR) for studying acceleration in tabular and linear-approximation Q-learning; this is a genuine departure from the usual contraction-mapping or supermartingale arguments and could yield new insight into momentum effects. The explicit identification of acceleration conditions and the extension to function approximation are also positive features.
major comments (2)
- [Abstract / SLS representation] Abstract and the SLS-representation section: the convergence claim rests on rewriting the corrected heavy-ball update as an SLS whose stability is settled by JSR < 1. This modeling step implicitly treats the sequence of visited state-action pairs as an arbitrary switching signal. In the actual algorithm the switching is generated by the Markov chain induced by the behavior policy and the current Q-estimate; the resulting JSR therefore only upper-bounds the worst-case deterministic trajectory. No explicit contraction mapping, supermartingale, or mean-square analysis is supplied to close the gap between the deterministic SLS and the stochastic recursion, which is load-bearing for the central convergence guarantee.
- [Linear function approximation section] The same modeling gap appears in the linear function approximation extension: the switched-linear-system representation must still be shown to imply almost-sure or mean-square convergence under the stochastic sampling induced by the behavior policy, rather than only deterministic worst-case stability.
minor comments (1)
- Notation for the residual weighting correction term and the precise definition of the switching family should be introduced earlier and used consistently throughout the proofs.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / SLS representation] Abstract and the SLS-representation section: the convergence claim rests on rewriting the corrected heavy-ball update as an SLS whose stability is settled by JSR < 1. This modeling step implicitly treats the sequence of visited state-action pairs as an arbitrary switching signal. In the actual algorithm the switching is generated by the Markov chain induced by the behavior policy and the current Q-estimate; the resulting JSR therefore only upper-bounds the worst-case deterministic trajectory. No explicit contraction mapping, supermartingale, or mean-square analysis is supplied to close the gap between the deterministic SLS and the stochastic recursion, which is load-bearing for the central convergence guarantee.
Authors: The joint spectral radius condition JSR < 1 establishes uniform asymptotic stability of the switched linear system for every possible switching sequence. The sequence of state-action pairs generated by any behavior policy (Markovian or otherwise) is simply one particular switching sequence; therefore the stability result applies directly to the realized trajectories of the algorithm. The residual weighting correction is constructed precisely so that the update recursion takes the exact SLS form. We will add a short clarifying paragraph in the SLS-representation section that explicitly connects the arbitrary-switching stability guarantee to the Markovian case and notes the implications for the underlying stochastic process. revision: yes
-
Referee: [Linear function approximation section] The same modeling gap appears in the linear function approximation extension: the switched-linear-system representation must still be shown to imply almost-sure or mean-square convergence under the stochastic sampling induced by the behavior policy, rather than only deterministic worst-case stability.
Authors: The identical JSR argument applies verbatim to the linear-function-approximation setting, because the switched-linear representation and the associated switching family are constructed analogously. We will insert a parallel clarifying sentence in that section. revision: yes
Circularity Check
No circularity; external SLS/JSR framework used
full rationale
The paper's convergence claims rest on rewriting the heavy-ball update as a switched linear system whose stability is analyzed via joint spectral radius. This modeling step and the JSR tool are presented as an external complementary framework drawn from control theory, not derived from or equivalent to the paper's own fitted parameters, self-citations, or target results by construction. No self-definitional loops, renamed empirical patterns, or load-bearing self-citation chains appear in the provided derivation outline. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning . Machine Learning, 8(3–4):279– 292, 1992. doi:10.1007/BF00992698
-
[2]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement learning: an introduction. Second edition, MIT Press, Cambridge, MA, 2018
2018
-
[3]
Kappen, Mohammad G
Mohammad Ghavamzadeh, Hilbert J. Kappen, Mohammad G. Az ar, and Rémi Munos. Speedy q-learning. In Advances in Neural Information Processing Systems 24 , pages 2411– 2419, 2011
2011
-
[4]
Pid a ccelerated value itera- tion algorithm
Amir-Massoud Farahmand and Mohammad Ghavamzadeh. Pid a ccelerated value itera- tion algorithm. In Proceedings of the 38th International Conference on Machin e Learning, Proceedings of Machine Learning Research, Vol. 139, pages 3 143–3153, PMLR, 2021
2021
-
[5]
A first-order app roach to accelerated value it- eration
Vineet Goyal and Julien Grand-Clément. A first-order app roach to accelerated value it- eration. Operations Research, 71(2):517–535, 2023. Published online March 24, 2022; doi:10.1287/opre.2022.2269
-
[6]
Meir Herzberg and Uri Yechiali. Accelerating procedure s of the value iteration algorithm for discounted markov decision processes, based on a one-step l ookahead analysis. Operations Research, 42(5):940–946, 1994. doi:10.1287/opre.42.5.940
-
[7]
Acceleration op- erators in the value iteration algorithms for markov decisi on processes
Oleksandr Shlakhter, Chi-Guhn Lee, Dmitry Khmelev, and Nasser Jaber. Acceleration op- erators in the value iteration algorithms for markov decisi on processes. Operations Research, 58(1):193–202, 2010. doi:10.1287/opre.1090.0705
-
[8]
Dimitri P. Bertsekas. Generic rank-one corrections for the value iteration in markovian decision problems. Operations Research Letters , 17(3):111–119, 1995. doi:10.1016/0167- 6377(95)00007-7
-
[9]
Rank-one modified value iteration
Arman Sharifi Kolarijani, Tolga Ok, Peyman Mohajerin Esf ahani, and Mohamad Amin Sharifi Kolarijani. Rank-one modified value iteration. In Proceedings of the 42nd Interna- tional Conference on Machine Learning , Proceedings of Machine Learning Research, Vol. 267, pages 31182–31201, PMLR, 2025
2025
-
[10]
Ryu, and Amir-Mass oud Farahmand
Jongmin Lee, Amin Rakhsha, Ernest K. Ryu, and Amir-Mass oud Farahmand. Deflated dynamics value iteration. Transactions on Machine Learning Research , 2025
2025
-
[11]
Switching-Geometry Analysis of Deflated Q-Value Iteration
Donghwan Lee. Switching-geometry analysis of deflated q-value iteration . arXiv:2605.10811v2, 2026. doi:10.48550/arXiv.2605.108 11
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.108 2026
-
[12]
Spectral analysis of heavy-ball q-value iteration
Donghwan Lee. Spectral analysis of heavy-ball q-value iteration . Manuscript, 2026
2026
-
[13]
Analysis of q-learning with adaptation and momentum restart for gradient descent
Bowen Weng, Huaqing Xiong, Yingbin Liang, and Wei Zhang . Analysis of q-learning with adaptation and momentum restart for gradient descent. In Proceedings of the Twenty- Ninth International Joint Conference on Artificial Intelli gence, pages 3051–3057, 2020. doi:10.24963/ijcai.2020/422
-
[14]
Finite-time theory for momentum q-learning
Bowen Weng, Huaqing Xiong, Lin Zhao, Yingbin Liang, and Wei Zhang. Finite-time theory for momentum q-learning. In Proceedings of the Thirty-Seventh Conference on Uncertain ty in Artificial Intelligence , Proceedings of Machine Learning Research, Vol. 161, pages 665– 674, PMLR, 2021
2021
-
[15]
Anderson accelerat ion for reinforcement learning
Matthieu Geist and Bruno Scherrer. Anderson accelerat ion for reinforcement learning. In Proceedings of the 14th European Workshop on Reinforcement Learning (EWRL 2018), Lille, France, 2018. 34
2018
-
[16]
Momentum in re- inforcement learning
Nino Vieillard, Bruno Scherrer, Olivier Pietquin, and Matthieu Geist. Momentum in re- inforcement learning. In Proceedings of the Twenty Third International Conference o n Artificial Intelligence and Statistics , Proceedings of Machine Learning Research, Vol. 108, pages 2529–2538, PMLR, 2020
2020
-
[17]
Jongmin Lee and Ernest K. Ryu. Accelerating value itera tion with anchoring. In Advances in Neural Information Processing Systems 36 , pages 53924–53963, 2023. doi:10.52202/075280- 2346
-
[18]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andr ei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fi djeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antono glou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Hum an-level control through deep reinforceme...
-
[19]
Carl D. Meyer. Matrix analysis and applied linear algebra . Society for Industrial and Applied Mathematics, Philadelphia, 2000. ISBN 978-0-89871-454-8 ; doi:10.1137/1.9780898719512
-
[20]
Raphaël M. Jungers. The joint spectral radius: theory and applications . Lecture Notes in Control and Information Sciences, Vol. 385, Spring er, Berlin, Heidelberg, 2009. doi:10.1007/978-3-540-95980-9
-
[21]
Eliahu I. Jury. Theory and application of the z-transform method . John Wiley & Sons, New York, 1964
1964
-
[22]
Lyapunov-Certified Direct Switching Theory for Q-Learning
Donghwan Lee. Lyapunov-certified direct switching theory for q-learning . arXiv:2604.19569v3, 2026. doi:10.48550/arXiv.2604.195 69
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.195 2026
-
[23]
Beyond the Bellman Fixed Point: Geometry and Fast Policy Identification in Value Iteration
Donghwan Lee. Beyond the bellman fixed point: geometry and fast policy iden tification in value iteration. arXiv:2604.17457v4, 2026. doi:10.48550/arXiv.2604.17 457
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.17 2026
-
[24]
Maguluri, Sanjay Shakkottai, and K arthikeyan Shanmugam
Zaiwei Chen, Siva T. Maguluri, Sanjay Shakkottai, and K arthikeyan Shanmugam. A lyapunov theory for finite-sample guarantees of markovian stochastic approxima- tion. Operations Research, 72(4):1352–1367, 2024. Published online October 6, 2023; doi:10.1287/opre.2022.0249
-
[25]
Daniel Liberzon. Switching in systems and control . Systems & Control: Foundations & Applications, Birkhäuser Boston, 2003. doi:10.1007/978- 1-4612-0017-8
-
[26]
Hai Lin and Panos J. Antsaklis. Stability and stabiliza bility of switched linear systems: a survey of recent results. IEEE Transactions on Automatic Control , 54(2):308–322, 2009. doi:10.1109/TAC.2008.2012009
-
[27]
Sta- bility criteria for switched and hybrid systems
Robert Shorten, Fabian Wirth, Oliver Mason, Kai Wulff, a nd Christopher King. Sta- bility criteria for switched and hybrid systems. SIAM Review , 49(4):545–592, 2007. doi:10.1137/05063516X
-
[28]
A note on the joint s pectral radius
Gian-Carlo Rota and Gilbert Strang. A note on the joint s pectral radius. Indagationes Mathematicae, 22:379–381, 1960. doi:10.1016/S1385-7258(60)50046-1
-
[29]
Generating fu nctions of switched linear systems: analysis, computation, and stability applications
Jianghai Hu, Jinglai Shen, and Wei Zhang. Generating fu nctions of switched linear systems: analysis, computation, and stability applications. IEEE Transactions on Automatic Control, 56(5):1059–1074, 2011. doi:10.1109/TAC.2010.2067590
-
[30]
Martin L. Puterman. Markov decision processes: discrete stochastic dynamic pr ogram- ming. Wiley Series in Probability and Statistics, John Wiley & So ns, New York, 1994. doi:10.1002/9780470316887. 35
-
[31]
Bertsekas and John N
Dimitri P. Bertsekas and John N. Tsitsiklis. Neuro-dynamic programming. Athena Scientific, Belmont, MA, 1996
1996
-
[32]
Residual algorithms: reinforcement lea rning with function approximation
Leemon Baird. Residual algorithms: reinforcement lea rning with function approximation. In Proceedings of the Twelfth International Conference on Mac hine Learning, pages 30–37. Morgan Kaufmann, 1995. 36 A Auxiliary results A.1 Nonnegative matrix row-sum bounds The following standard row-sum bound is the form of the Colla tz–Wielandt inequality used below...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.