Large Language Model Teaches Visual Students: Cross-Modality Transfer of Fine-Grained Conceptual Knowledge
Pith reviewed 2026-06-29 02:04 UTC · model grok-4.3
The pith
A language-only LLM transfers fine-grained visual distinctions to image models by generating class-specific multiple-choice questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
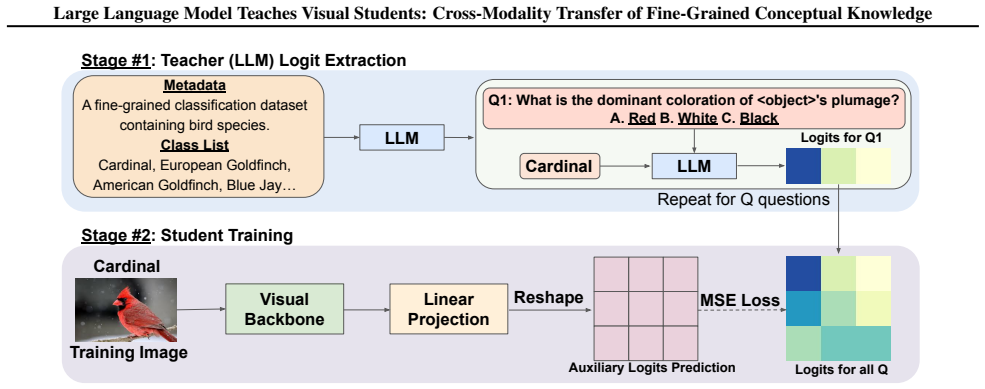
LaViD elicits conceptual signals from a language-only LLM by generating multiple-choice questions that probe semantic distinctions between visual classes. Each class is represented as a soft label distribution over these questions, which then guides the vision student through an auxiliary distillation loss. This yields consistent outperformance over methods such as MaKD that distill from vision-language models, while remaining competitive with pure visual distillation techniques like DKD and MLKD.
What carries the argument
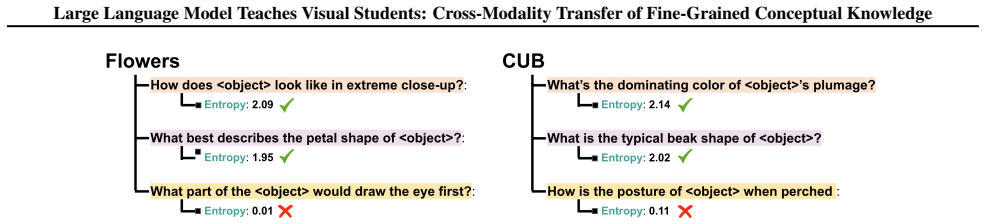
The conceptual signature: a soft distribution over LLM-generated multiple-choice questions for each visual class, used as the target in the auxiliary distillation loss.
If this is right
- LaViD improves worst-group accuracy on Waterbirds by reducing reliance on spurious correlations.
- Combining LaViD with logit standardization produces additional gains over either method alone.
- The framework achieves competitive or better results than DKD and MLKD on fine-grained classification tasks.
- Language-only teachers can replace vision-language models in distillation pipelines without loss of effectiveness.
Where Pith is reading between the lines
- Textual conceptual distinctions may suffice for many visual recognition problems that were assumed to require image-level supervision.
- The same MCQ-elicitation approach could be tested on other student modalities such as audio or video without paired data.
- If the generated questions prove reusable across datasets, the method could lower the cost of creating supervision signals for new visual categories.
Load-bearing premise
The multiple-choice questions generated by the LLM capture semantic distinctions between visual classes that remain useful when transferred to a vision-only student without any visual grounding or paired data.
What would settle it
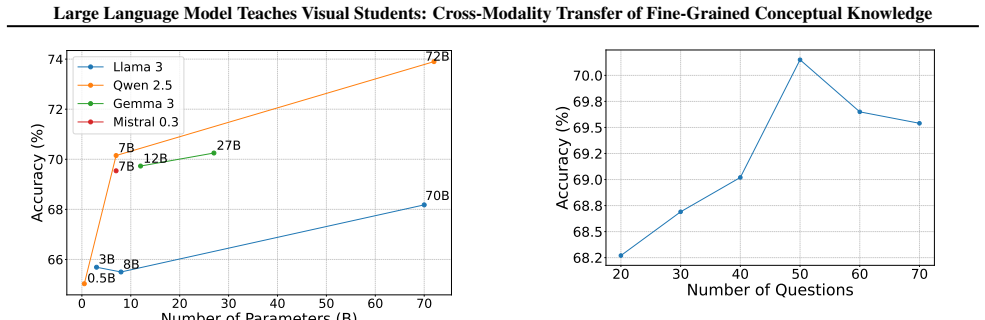
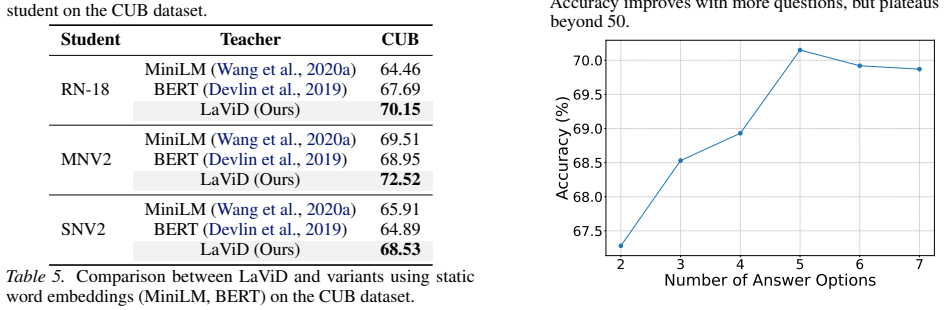
Train the vision student with LaViD on a fine-grained dataset such as CUB-200 and compare top-1 accuracy to a standard supervised baseline; if performance does not exceed the baseline or MaKD, the transfer claim fails.
Figures


read the original abstract
Large Language Models (LLMs) possess broad conceptual knowledge acquired through large-scale text pretraining, yet their potential to supervise models in other modalities remains underexplored. In this work, we propose LaViD--Language-to-Visual Knowledge Distillation--a simple and effective framework for transferring high-level semantic knowledge from a language-only teacher to a vision-only student model. Instead of relying on paired multimodal data, LaViD elicits conceptual signals from an LLM by prompting it to generate multiple-choice questions (MCQs) that probe semantic distinctions between visual classes. Each class is mapped to a soft label distribution over these MCQs, forming a rich conceptual signature that guides the student through an auxiliary distillation loss. Notably, despite using a language-only teacher without access to image data, LaViD consistently outperforms recent methods like MaKD that distill from vision-language models across multiple fine-grained benchmarks. It also achieves competitive or superior performance compared to state-of-the-art visual distillation methods such as DKD and MLKD, with further gains when combined with logit standardization. On the Waterbirds dataset, LaViD substantially improves worst-group accuracy, demonstrating enhanced robustness to spurious correlations with distillation. Code is available at https://github.com/lliangthomas/lavid.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaViD, a framework for cross-modality knowledge distillation in which a language-only LLM is prompted to generate multiple-choice questions that probe semantic distinctions between visual classes. Each class is assigned a soft-label distribution over the generated MCQs, which is then used via an auxiliary distillation loss to supervise a vision-only student model. The central empirical claim is that this approach, despite using no image data or paired multimodal examples, consistently outperforms recent VLM-based distillation methods such as MaKD on fine-grained benchmarks and achieves competitive or better results than visual-only distillation techniques (DKD, MLKD), with additional robustness gains on Waterbirds when combined with logit standardization.
Significance. If the reported gains prove reproducible, the result would be significant: it provides evidence that high-level conceptual knowledge acquired purely from text can be transferred to improve vision models without any visual grounding or paired data. This is a non-obvious finding that could influence the design of distillation pipelines and reduce reliance on multimodal teachers. The public code release at the cited GitHub repository is a clear strength that supports verification.
major comments (2)
- [Experiments] The central claim of outperformance over MaKD rests on the assumption that LLM-generated MCQ distributions capture distinctions that remain useful for a vision student; the manuscript should include an explicit ablation or analysis (e.g., in the experiments section) showing that random or non-semantic MCQ sets yield substantially weaker transfer, to rule out that gains arise from generic regularization rather than conceptual content.
- [Abstract / Experiments] The abstract states that LaViD 'consistently outperforms' MaKD and is 'competitive or superior' to DKD/MLKD, yet no mention is made of the number of random seeds, statistical significance testing, or whether all baselines were reimplemented under identical student architectures and optimization settings; these details are load-bearing for the superiority claim.
minor comments (2)
- [Method] The notation for the soft-label mapping from classes to MCQ distributions should be formalized with an equation in the method section to improve clarity and reproducibility.
- [Figures] Figure captions and axis labels in the robustness experiments on Waterbirds should explicitly state the evaluation metric (worst-group accuracy) and the spurious-correlation setup for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the helpful suggestions for strengthening the paper. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] The central claim of outperformance over MaKD rests on the assumption that LLM-generated MCQ distributions capture distinctions that remain useful for a vision student; the manuscript should include an explicit ablation or analysis (e.g., in the experiments section) showing that random or non-semantic MCQ sets yield substantially weaker transfer, to rule out that gains arise from generic regularization rather than conceptual content.
Authors: We agree that an explicit ablation is required to isolate the contribution of semantic content. In the revised manuscript we will add results comparing the full LaViD pipeline against two controls: (i) MCQs generated from random class pairings and (ii) MCQs produced by non-semantic prompts (e.g., generic factual questions unrelated to class distinctions). These controls produce markedly lower transfer performance, confirming that the observed gains are driven by the conceptual distinctions elicited from the LLM rather than generic regularization. revision: yes
-
Referee: [Abstract / Experiments] The abstract states that LaViD 'consistently outperforms' MaKD and is 'competitive or superior' to DKD/MLKD, yet no mention is made of the number of random seeds, statistical significance testing, or whether all baselines were reimplemented under identical student architectures and optimization settings; these details are load-bearing for the superiority claim.
Authors: We acknowledge the omission. All reported results use three independent random seeds with mean and standard deviation; every baseline (including MaKD, DKD, and MLKD) was reimplemented using the identical student backbone, optimizer, and training schedule as LaViD. We will revise the abstract to state these experimental controls explicitly and will add a short paragraph in the experiments section reporting the seed count and confirming identical reimplementation settings. revision: yes
Circularity Check
No significant circularity; empirical method evaluated externally
full rationale
The paper describes an empirical distillation pipeline (LLM-generated MCQs mapped to class soft-label distributions, then used in an auxiliary loss for a vision student). All performance claims are measured against external fine-grained benchmarks and compared to prior methods (MaKD, DKD, MLKD). No equations, fitted parameters, or predictions are defined in terms of the reported gains themselves. No self-citation chains or uniqueness theorems are invoked to force the central result. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs possess broad conceptual knowledge acquired through large-scale text pretraining
- domain assumption Prompting an LLM to generate MCQs that probe semantic distinctions between visual classes produces useful soft labels for a vision student
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Model compression , author=. Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[2]
2025 , eprint=
Saccadic Vision for Fine-Grained Visual Classification , author=. 2025 , eprint=
2025
-
[3]
2019 , eprint=
Learning Deep Bilinear Transformation for Fine-grained Image Representation , author=. 2019 , eprint=
2019
-
[4]
2018 , eprint=
Pairwise Confusion for Fine-Grained Visual Classification , author=. 2018 , eprint=
2018
-
[5]
2024 , eprint=
Data-free Knowledge Distillation for Fine-grained Visual Categorization , author=. 2024 , eprint=
2024
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Graph-Propagation Based Correlation Learning for Weakly Supervised Fine-Grained Image Classification , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2020 , month=. doi:10.1609/aaai.v34i07.6912 , abstractNote=
-
[7]
2019 , eprint=
Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up , author=. 2019 , eprint=
2019
-
[8]
2017 , eprint=
Bilinear CNNs for Fine-grained Visual Recognition , author=. 2017 , eprint=
2017
-
[9]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ICML , year=
The Platonic Representation Hypothesis , author=. ICML , year=
-
[11]
FitNets: Hints for Thin Deep Nets
Fitnets: Hints for thin deep nets , author=. arXiv preprint arXiv:1412.6550 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:1910.10699 (2019)
Contrastive representation distillation , author=. arXiv preprint arXiv:1910.10699 , year=
-
[13]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Decoupled knowledge distillation , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[14]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Knowledge distillation with the reused teacher classifier , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[15]
2021 , organization=
Knowledge distillation via softmax regression representation learning , author=. 2021 , organization=
2021
-
[16]
Advances in Neural Information Processing Systems , volume=
One-for-all: Bridge the gap between heterogeneous architectures in knowledge distillation , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Logit standardization in knowledge distillation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
International conference on learning representations , year=
Improve object detection with feature-based knowledge distillation: Towards accurate and efficient detectors , author=. International conference on learning representations , year=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Relational knowledge distillation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Similarity-preserving knowledge distillation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[21]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[22]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[23]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[24]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Language Models as Knowledge Bases?
Language models as knowledge bases? , author=. arXiv preprint arXiv:1909.01066 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[29]
Advances in neural information processing systems , volume=
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers , author=. Advances in neural information processing systems , volume=
-
[30]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[31]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[32]
arXiv preprint arXiv:2309.04344 , year=
Zero-shot robustification of zero-shot models , author=. arXiv preprint arXiv:2309.04344 , year=
-
[33]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[34]
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer , author=. arXiv preprint arXiv:1612.03928 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in Neural Information Processing Systems , volume=
What knowledge gets distilled in knowledge distillation? , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Knowledge distillation from a stronger teacher , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2411.06786 , year=
ScaleKD: Strong Vision Transformers Could Be Excellent Teachers , author=. arXiv preprint arXiv:2411.06786 , year=
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
A good student is cooperative and reliable: Cnn-transformer collaborative learning for semantic segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[39]
Proceedings of the Asian conference on computer vision , pages=
Cross-architecture knowledge distillation , author=. Proceedings of the Asian conference on computer vision , pages=
-
[40]
arXiv preprint arXiv:2206.06487 , year=
The modality focusing hypothesis: Towards understanding crossmodal knowledge distillation , author=. arXiv preprint arXiv:2206.06487 , year=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
C2kd: Bridging the modality gap for cross-modal knowledge distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Decomposed cross-modal distillation for rgb-based temporal action detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Open-vocabulary object detection via vision and language knowledge distillation , author=. arXiv preprint arXiv:2104.13921 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Aligning bag of regions for open-vocabulary object detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Masqclip for open-vocabulary universal image segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Multimodal knowledge expansion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[47]
Advances in neural information processing systems , volume=
Soundnet: Learning sound representations from unlabeled video , author=. Advances in neural information processing systems , volume=
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cross modal distillation for supervision transfer , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Modality distillation with multiple stream networks for action recognition , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[50]
The Caltech-UCSD Birds-200-2011 Dataset , abstractNote=
Wah, Catherine and Branson, Steve and Welinder, Peter and Perona, Pietro and Belongie, Serge , year=. The Caltech-UCSD Birds-200-2011 Dataset , abstractNote=
2011
-
[51]
Caltech 101 , DOI=
Li, Fei-Fei and Andreeto, Marco and Ranzato, Marc'Aurelio and Perona, Pietro , year=. Caltech 101 , DOI=
-
[52]
Automated Flower Classification over a Large Number of Classes
Maria-Elena Nilsback and Andrew Zisserman. Automated Flower Classification over a Large Number of Classes. Indian Conference on Computer Vision, Graphics and Image Processing. 2008
2008
-
[53]
Fine-Grained Visual Classification of Aircraft
Fine-grained visual classification of aircraft , author=. arXiv preprint arXiv:1306.5151 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
2012 IEEE conference on computer vision and pattern recognition , pages=
Cats and dogs , author=. 2012 IEEE conference on computer vision and pattern recognition , pages=. 2012 , organization=
2012
-
[55]
Proceedings of the IEEE international conference on computer vision workshops , pages=
3d object representations for fine-grained categorization , author=. Proceedings of the IEEE international conference on computer vision workshops , pages=
-
[56]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[57]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. arXiv preprint arXiv:1911.08731 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[58]
arXiv preprint arXiv:2501.13341 , year=
Multi-aspect Knowledge Distillation with Large Language Model , author=. arXiv preprint arXiv:2501.13341 , year=
-
[59]
Proceedings of the European conference on computer vision (ECCV) , pages=
Shufflenet v2: Practical guidelines for efficient cnn architecture design , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Mobilenetv2: Inverted residuals and linear bottlenecks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[61]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-level logit distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
arXiv preprint arXiv:2106.10270 , year=
How to train your vit? data, augmentation, and regularization in vision transformers , author=. arXiv preprint arXiv:2106.10270 , year=
-
[64]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[66]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[67]
2024 , howpublished =
GPT-4o System Card , author =. 2024 , howpublished =
2024
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Robust fine-tuning of zero-shot models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[70]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.