Direct Action-Head Injection of A Grounded 3D Point Unlocks Spatial and Task Generalization
Pith reviewed 2026-06-29 05:02 UTC · model grok-4.3
The pith
Injecting a grounded 3D point directly into the action head unlocks spatial and task generalization in vision-language-action models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
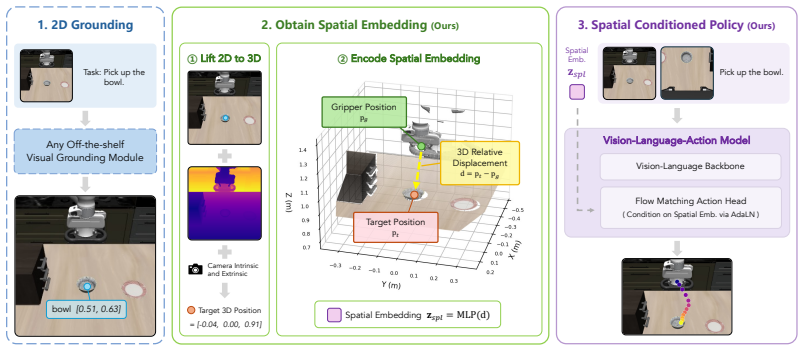
Exploiting a 3D point-based representation and feeding it directly to the action head leads to substantial improvements, revealing that how the grounding signal is represented and injected into the VLA is the true game changer. The lightweight module represents the grounding signal in 3D, computes its relative displacement to the gripper, and injects the resulting spatial embedding directly into the action head through adaptive layer normalization.
What carries the argument
Lightweight two-layer MLP module that lifts grounding to a 3D point, computes its relative displacement to the gripper, and injects the spatial embedding into the action head via adaptive layer normalization
If this is right
- The gains appear for multiple VLA backbones without any change to pretraining or the core model
- Both task instruction changes and object position shifts are addressed by the same injection mechanism
- The module adds negligible parameters yet delivers over 30-point average success improvements
- The result isolates injection method as the decisive factor rather than the amount of grounding data
Where Pith is reading between the lines
- Similar direct geometric injection could be tested in other multimodal policies that currently rely on language prompting for spatial cues
- The finding implies that action heads in existing VLAs may lack built-in mechanisms to extract 3D relations from visual features alone
- Extending the module to multiple 3D points or dynamic gripper-object relations would be a direct next measurement
Load-bearing premise
The method assumes an accurate 3D point for the target object can be obtained and that its relative displacement to the gripper alone supplies sufficient spatial information for the action head to generalize.
What would settle it
Applying the module on LIBERO-PRO under task and position perturbations but replacing the 3D relative-displacement embedding with a 2D coordinate or an inaccurate point and seeing no success-rate gains would falsify the central claim.
Figures



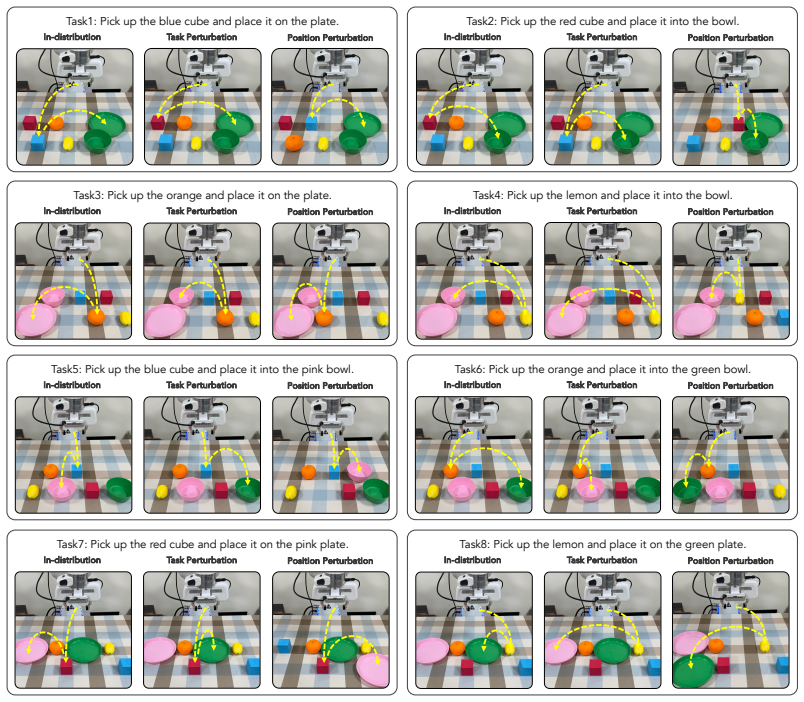


read the original abstract
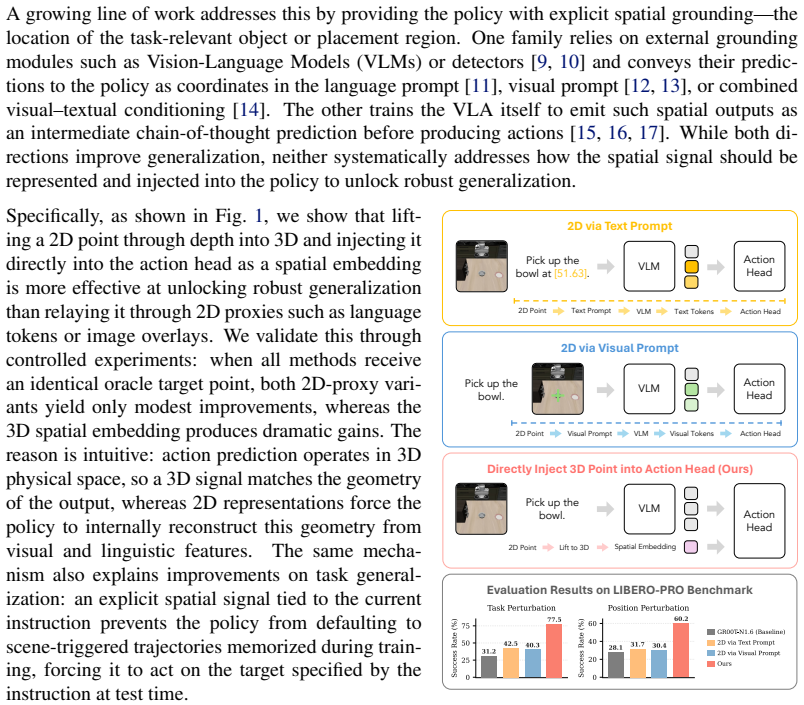
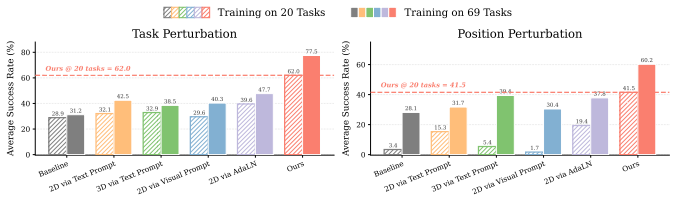
Vision-Language-Action (VLA) models leverage large-scale vision-language pretraining for flexible robot manipulation, yet at test time they remain brittle along two axes: spatial generalization, when object positions differ from those seen during training, and task generalization, when a familiar scene is paired with a different language instruction than the one seen in training. A growing family of methods addresses this brittleness by endowing a policy with the spatial and task-aware information such as 2D pixel-coordinate for object localization and placement. However, we find that existing representation through language prompting or visual prompting does not address the limitations; in contrast, exploiting a 3D point-based representation and feeding it directly to the action head leads to substantial improvements-revealing that how the grounding signal is represented and injected into the VLA is the true game changer. Thus, we propose a lightweight, model-agnostic module that represents the grounding signal in 3D, computes its relative displacement to the gripper, and injects the resulting spatial embedding directly into the action head through adaptive layer normalization. The entire module is a two-layer MLP that requires no changes to the VLA backbone or pretraining pipeline. On LIBERO-PRO, our method improves the average success rate of GR00T-N1.6 from 31.2 to 77.5 points under task perturbation and from 28.1 to 60.2 points under position perturbation (gains of 46.3 and 32.1 points). Comparable gains are achieved for $\pi_{0.5}$ as well, demonstrating that the mechanism is backbone-agnostic. Together, these results support our central finding: given adequate grounding lifted into 3D, injecting it directly into the action head is what unlocks both spatial and task generalization in VLAs-achievable with nothing more than a lightweight module on top of a pretrained backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing 2D prompting methods fail to address spatial and task generalization brittleness in VLAs, but a lightweight module that lifts grounding to a 3D point, computes its relative 3-DOF displacement to the gripper, and injects the embedding directly into the action head via a two-layer MLP and AdaLN yields large gains. On LIBERO-PRO, GR00T-N1.6 improves from 31.2 to 77.5 under task perturbation and 28.1 to 60.2 under position perturbation (gains of 46.3 and 32.1); comparable gains hold for π_{0.5}. The module requires no backbone changes or retraining, supporting the claim that direct action-head injection of adequate 3D grounding is the key mechanism.
Significance. If reproducible, the result would indicate that the representation and injection point of spatial grounding matter more than the grounding source itself, offering a simple, backbone-agnostic path to better generalization in VLAs. The explicit conditioning on 'adequate grounding' and the model-agnostic design are clear strengths that could be adopted quickly. However, the significance is limited by the absence of robustness tests against the oracle-accurate 3D point assumption.
major comments (2)
- [Abstract] Abstract: the headline gains (46.3 and 32.1 points) are reported without error bars, standard deviations, number of seeds, or full hyperparameter details, which is load-bearing for the empirical generalization claim.
- [Abstract] Abstract and method description: the central claim that relative 3-DOF displacement alone suffices for both spatial and task generalization is conditioned on 'adequate grounding' but no experiments or analysis address degradation under realistic 3D sensor noise, partial occlusion, or grounding error, leaving the weakest assumption untested.
minor comments (1)
- [Abstract] Abstract: the sentence 'endowing a policy with the spatial and task-aware information such as 2D pixel-coordinate' is grammatically incomplete and should be clarified when contrasting with the proposed 3D method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical reporting and the scope of our claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline gains (46.3 and 32.1 points) are reported without error bars, standard deviations, number of seeds, or full hyperparameter details, which is load-bearing for the empirical generalization claim.
Authors: We agree that statistical details are essential for supporting the generalization claims. The reported numbers are averages across evaluation episodes, but error bars, standard deviations, seed counts, and expanded hyperparameter information were omitted from the abstract in the initial submission. In the revised manuscript we will include these details (e.g., results over 3 seeds with standard deviations) either in the abstract or a new supplementary table referenced from the abstract. revision: yes
-
Referee: [Abstract] Abstract and method description: the central claim that relative 3-DOF displacement alone suffices for both spatial and task generalization is conditioned on 'adequate grounding' but no experiments or analysis address degradation under realistic 3D sensor noise, partial occlusion, or grounding error, leaving the weakest assumption untested.
Authors: The manuscript explicitly qualifies the claim with the phrase 'given adequate grounding' in both the abstract and conclusion, and the experiments deliberately use oracle 3D points to isolate the contribution of the injection mechanism itself. We acknowledge that robustness under realistic perception noise is an important untested dimension. Because new experiments with simulated sensor noise or occlusion would require additional data collection and are outside the current scope, we will add an explicit limitations paragraph discussing this assumption and listing it as future work. revision: partial
Circularity Check
No circularity; purely empirical method with no derivations or self-referential reductions
full rationale
The paper describes a lightweight module for 3D point injection into VLA action heads and reports empirical success-rate gains on LIBERO-PRO benchmarks. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the abstract or described content. The central claim rests on experimental outcomes under the stated assumption of adequate 3D grounding rather than any reduction to fitted inputs or self-definitional constructs. This is the most common honest finding for empirical robotics papers without mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An accurate 3D point representing the target object is available at test time
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=ZMnD6QZAE6
2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[6]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
2025
-
[7]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization.[arXiv preprint arXiv:2510.03827], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id= GVX6jpZOhU
2024
-
[10]
Huang, X
H. Huang, X. Chen, Y . Chen, H. Li, X. Han, Z. Wang, T. Wang, J. Pang, and Z. Zhao. Roboground: Robotic manipulation with grounded vision-language priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22540–22550, June 2025
2025
-
[11]
Deshpande, M
A. Deshpande, M. Guru, R. Hendrix, S. Jauhri, A. Eftekhar, R. Tripathi, M. Argus, J. Salvador, H. Fang, M. Wallingford, W. Pumacay, Y . Kim, Q. Pfeifer, Y .-C. Lee, P. Wolters, O. Rayyan, M. Zhang, J. Duan, K. Farley, W. Han, E. Vanderbilt, D. Fox, A. Farhadi, G. Chalvatzaki, D. Shah, and R. Krishna. Molmob0t: Large-scale simulation enables zero-shot mani...
- [12]
-
[13]
K. Fang, F. Liu, P. Abbeel, and S. Levine. Moka: Open-world robotic manipulation through mark-based visual prompting. InRobotics: Science and Systems, 2024. URLhttp://dblp. uni-trier.de/db/conf/rss/rss2024.html#FangLAL24
2024
-
[14]
Z. Wang, Y . Chen, Y . Liu, J. Ye, P. Chen, C. Lu, S. Liu, and J. Jia. Vp-vla: Visual prompting as an interface for vision-language-action models.arXiv preprint arXiv:2603.22003, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
J. Li, Y . Zhu, Z. Tang, J. Wen, M. Zhu, X. Liu, C. Li, R. Cheng, Y . Peng, Y . Peng, and F. Feng. Coa-vla: Improving vision-language-action models via visual-text chain-of-affordance. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9759–9769, October 2025
2025
-
[16]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space, 2025. URLhttps: //arxiv.org/abs/2508.07917
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Zawalski, W
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=S70MgnIA0v
2024
-
[18]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control, 2026. URLhttps://arxiv.org/abs/2602.13193
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, October 2023
2023
-
[21]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018
2018
-
[22]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Bench- marking knowledge transfer for lifelong robot learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural In- formation Processing Systems, volume 36, pages 44776–44791. Curran Associates, Inc.,
-
[23]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ 8c3c666820ea055a77726d66fc7d447f-Paper-Datasets_and_Benchmarks.pdf. 10
2023
-
[24]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[26]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, C. R. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, and A. Goyal. HAMSTER: Hierarchical action models for open-world robot manipulation. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps: //openreview.net/forum?id=h7aQxzKbq6. 11
2025
-
[27]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-VLA: A 3d vision- language-action generative world model. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=EZcFK8HupF
2024
-
[28]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, J. Gu, Z. Wang, Y . Ding, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.011
-
[29]
C. Li, J. Wen, Y . Peng, Y . Peng, and Y . Zhu. Pointvla: Injecting the 3d world into vision- language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026. doi: 10.1109/LRA.2026.3653303
-
[30]
Zhang, H
Z. Zhang, H. Li, Y . Dai, Z. Zhu, L. Zhou, C. Liu, D. Wang, F. E. H. Tay, S. Chen, Z. Liu, Y . Liu, X. Li, and P. Zhou. From spatial to actions: Grounding vision-language-action model in spatial foundation priors. InThe Fourteenth International Conference on Learning Representations,
-
[31]
URLhttps://openreview.net/forum?id=fzmittHfq3
-
[32]
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, H. Cui, Z. Zhang, and H. Wang. GraspVLA: a grasping foundation model pre-trained on billion-scale synthetic action data. In9th Annual Conference on Robot Learning, 2025. URLhttps: //openreview.net/forum?id=zEC8TOXDkH
2025
-
[33]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Borgefors
G. Borgefors. Distance transformations in digital images.Computer Vision, Graphics, and Image Processing, 34(3):344–371, 1986. ISSN 0734-189X. doi:https://doi.org/10.1016/ S0734-189X(86)80047-0. URLhttps://www.sciencedirect.com/science/article/ pii/S0734189X86800470
1986
-
[35]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024. 12 Appendix A Table of Contents
2024
-
[36]
B providesImplementation Detailsfor lifting a 2D point into 3D and encoding the spatial embedding, injecting it into the VLA, and each variant evaluated in Sec
Sec. B providesImplementation Detailsfor lifting a 2D point into 3D and encoding the spatial embedding, injecting it into the VLA, and each variant evaluated in Sec. 4.3 of the main paper
-
[37]
Sec. C providesSimulation Experimental Details, including the training tasks, how we obtain 2D grounding in simulation, the model training configurations, and the full experi- mental results
-
[38]
Sec. D providesReal-World Experimental Details, including the task and evaluation setup, how we obtain 2D grounding in real world, the model training configurations, and the full experimental results
-
[39]
u v 1 # =
Sec. E providesQualitative Resultsin both simulation and real-world settings. B Implementation Details In this section, we provide implementation details for: (1) lifting a 2D point into 3D and encoding the spatial embedding (Sec. B.1); (2) injecting the spatial embedding into the VLA (Sec. B.2); and (3) each variant evaluated in Sec. 4.3 of the main pape...
-
[40]
The object that needs to be picked up (role: "target")
-
[41]
placement
The location or object where it should be placed (role: "placement") Output ONLY a JSON array with exactly two entries, no extra text: [ {{"point 2d": [x, y], "label": "<object name>", "role": "target"}}, {{"point 2d": [x, y], "label": "<object name>", "role": "placement"}} ] We parse the returned JSON and rescale the normalized coordinates (in[0,1000]) t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.