Recognition: 2 theorem links
· Lean TheoremVP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models
Pith reviewed 2026-05-15 00:51 UTC · model grok-4.3
The pith
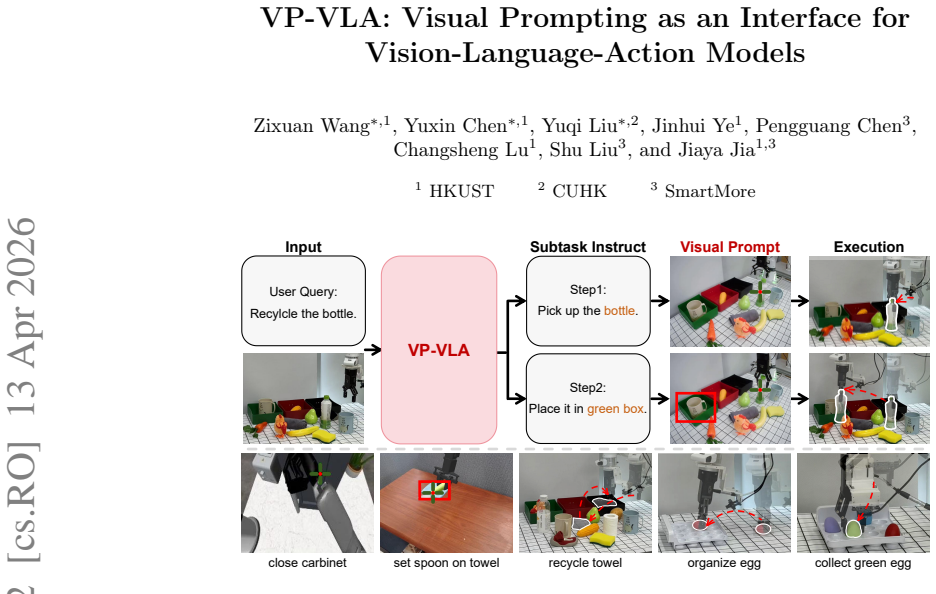
VP-VLA decouples high-level planning from low-level control in vision-language-action models by rendering spatial anchors as visual prompts directly in RGB camera images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing instructions in a planner and then overlaying the resulting spatial anchors as modality-consistent visual prompts such as crosshairs and bounding boxes inside the native RGB observation, the System 1 Controller can produce more precise low-level actions than single-forward-pass models, as confirmed by superior results against QwenOFT and GR00T-N1.6 in simulation and real-world tests.
What carries the argument
The visual prompting interface that converts planner outputs into crosshairs and bounding boxes rendered directly on the input RGB image for the controller to follow.
If this is right
- The controller generates lower-level motions with higher spatial accuracy because it receives explicit location cues in the same image modality.
- An auxiliary visual grounding objective during training strengthens the controller's ability to interpret and act on the rendered prompts.
- The separation allows the planner to handle complex or out-of-distribution instructions while the controller focuses on execution.
- Overall performance exceeds current end-to-end vision-language-action baselines in both simulated environments and physical robot deployments.
Where Pith is reading between the lines
- The same prompt-rendering step could be tested as a lightweight way to add spatial guidance to other multimodal control architectures.
- Different visual prompt styles, such as arrows or heatmaps, might be compared to measure which shapes transfer best to the controller.
- The planner could be swapped for stronger language models without retraining the entire controller stack.
Load-bearing premise
That simple visual marks placed on the original camera image will give the controller reliable spatial information without creating new confusion or errors in motion generation.
What would settle it
A controlled test in which the controller receives the same inputs and training but with the visual prompts removed or replaced by random marks, then measures whether task success rate and spatial accuracy drop, stay the same, or improve.
Figures






read the original abstract
Vision-Language-Action (VLA) models typically map visual observations and linguistic instructions directly to control signals. This "black-box" mapping forces a single forward pass to simultaneously handle instruction interpretation, spatial grounding, and low-level control, often leading to poor spatial precision and limited robustness in out-of-distribution scenarios. To address these limitations, we propose VP-VLA, a dual-system framework that decouples high-level reasoning and low-level execution via a structured visual prompting interface. Specifically, a "System 2 Planner" decomposes complex instructions into sub-tasks and identifies relevant target objects and goal locations. These spatial anchors are rendered directly within the native RGB observation space as modality-consistent visual prompts, such as crosshairs and bounding boxes. This avoids the modality mismatch introduced by dense masks, affordance maps, or additional control-specific representations. Guided by these prompts and enhanced by a novel auxiliary visual grounding objective during training, a "System 1 Controller" reliably generates precise low-level execution motions. Extensive experiments in simulation and real world demonstrate that VP-VLA surpasses state-of-the-art end-to-end baselines including QwenOFT and GR00T-N1.6. Project page: https://visualprompt-vla.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VP-VLA, a dual-system Vision-Language-Action framework that decouples high-level reasoning from low-level control. A System 2 Planner decomposes instructions into sub-tasks and identifies spatial anchors, which are rendered as visual prompts (crosshairs, bounding boxes) directly in the native RGB observation space. These prompts, together with a novel auxiliary visual grounding objective, guide a System 1 Controller to produce precise low-level actions. The central claim is that this visual-prompt interface avoids modality mismatch and yields superior performance over end-to-end baselines such as QwenOFT and GR00T-N1.6 in both simulation and real-world robot experiments.
Significance. If the empirical results hold, the work offers a practical, modality-consistent interface for improving spatial precision and out-of-distribution robustness in VLAs without requiring dense masks or separate control representations. The modular System-2/System-1 split with rendered visual anchors is a clean architectural idea that could be adopted more broadly in robotics and embodied AI.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the claim that VP-VLA 'surpasses state-of-the-art end-to-end baselines' is presented without any quantitative metrics, success rates, error bars, or statistical comparisons. This absence makes it impossible to assess the magnitude or reliability of the reported gains and is load-bearing for the central empirical claim.
- [Method] Method section (auxiliary objective): the novel auxiliary visual grounding objective is mentioned but never formulated (no loss equation, weighting schedule, or training details). Without this, it is unclear how the objective contributes to the System 1 Controller's claimed precision and whether the reported improvements depend on it.
- [Experiments] Experiments / Ablations: no ablation isolating the effect of rendering spatial anchors as visual prompts versus alternative interfaces (dense masks, affordance maps, or text-only conditioning) is described. This directly tests the weakest assumption that the RGB-native prompt format avoids modality mismatch and enables reliable low-level control.
minor comments (2)
- [Figures] Figure captions for the visual-prompt examples should explicitly label the prompt types (crosshair vs. bounding box) and indicate whether they are generated by the planner or ground-truth.
- [Appendix / Experiments] The paper should include a short reproducibility statement (model sizes, training compute, exact simulation environments, and real-robot hardware) to support the simulation-to-real claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results, clarify the auxiliary objective, and add targeted ablations.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim that VP-VLA 'surpasses state-of-the-art end-to-end baselines' is presented without any quantitative metrics, success rates, error bars, or statistical comparisons. This absence makes it impossible to assess the magnitude or reliability of the reported gains and is load-bearing for the central empirical claim.
Authors: We agree that explicit quantitative support is required. In the revised version we will expand both the abstract and Experiments section to report success rates (with standard deviations over multiple seeds), error bars, and statistical comparisons (e.g., paired t-tests) against QwenOFT and GR00T-N1.6 on all simulation and real-world tasks. These numbers are already computed and will be moved from the supplementary material into the main text. revision: yes
-
Referee: [Method] Method section (auxiliary objective): the novel auxiliary visual grounding objective is mentioned but never formulated (no loss equation, weighting schedule, or training details). Without this, it is unclear how the objective contributes to the System 1 Controller's claimed precision and whether the reported improvements depend on it.
Authors: We accept this criticism. The revised Method section will contain the full loss formulation L_aux = λ · CE(ŷ_prompt, y_prompt) with λ = 0.5, the precise weighting schedule across training epochs, and all optimizer and data-augmentation details used for the auxiliary head. This addition will make explicit how the objective improves spatial grounding inside the System 1 Controller. revision: yes
-
Referee: [Experiments] Experiments / Ablations: no ablation isolating the effect of rendering spatial anchors as visual prompts versus alternative interfaces (dense masks, affordance maps, or text-only conditioning) is described. This directly tests the weakest assumption that the RGB-native prompt format avoids modality mismatch and enables reliable low-level control.
Authors: We will add the requested ablation study to the revised Experiments section. It will compare the native RGB visual-prompt interface against (i) text-only conditioning, (ii) dense mask overlays, and (iii) affordance-map conditioning, reporting success rates and failure modes on the same task suite. This will quantify the benefit of staying within the native RGB modality. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces VP-VLA as a modular dual-system architecture (System 2 Planner producing spatial anchors rendered as visual prompts, System 1 Controller generating motions) with an auxiliary training objective. All central claims rest on empirical comparisons against external baselines (QwenOFT, GR00T-N1.6) in simulation and real-world settings rather than any derivation, equation, or self-citation chain. No step reduces a prediction to a fitted input by construction, renames a known result, or imports uniqueness from prior author work; the design choices are presented as engineering decisions validated by experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual prompts rendered in native RGB space can be reliably interpreted by the controller to produce precise actions without introducing new errors
invented entities (2)
-
System 2 Planner
no independent evidence
-
System 1 Controller
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VP-VLA leverages a dual-system architecture... System 2 Planner... visual prompts... auxiliary visual grounding objective... Ltotal = L_action(θ) + λ1 event L_grounding(ω)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no mention of recognition cost, golden ratio, or periodic tick structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Ho, D., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jang, E., Ruano, R.J., Jeffrey, K., Jesmonth, S., Joshi, N.J., Julian, R., Kalashnikov, D., Kuang, Y., Lee, K.H., Levine, S., Lu, Y., Luu, L., Parada, C., Pastor, P., Quiamba...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P., Fu, C., Arenas, M.G., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.W.E., Levine, S., Lu, Y., Michalewski...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Training strategies for efficient embodied reasoning.arXiv preprint arXiv:2505.08243, 2025b
Chen, W., Belkhale, S., Mirchandani, S., Mees, O., Driess, D., Pertsch, K., Levine, S.: Training strategies for efficient embodied reasoning (2025),https://arxiv. org/abs/2505.08243
-
[9]
GitHub repository (1 2025).https: //doi
starVLA Contributors: Starvla: A lego-like codebase for vision-language-action model developing. GitHub repository (1 2025).https: //doi. org/10 .5281/ zenodo.18264214,https://github.com/starVLA/starVLA
work page 2025
-
[10]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Fei, S., Wang, S., Shi, J., Dai, Z., Cai, J., Qian, P., Ji, L., He, X., Zhang, S., Fei, Z., et al.: Libero-plus: In-depth robustness analysis of vision-language-action models. arXiv preprint arXiv:2510.13626 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
- [14]
-
[15]
In: Forty-first International Conference on Machine Learning (2024)
Karamcheti, S., Nair, S., Balakrishna, A., Liang, P., Kollar, T., Sadigh, D.: Pris- matic vlms: Investigating the design space of visually-conditioned language models. In: Forty-first International Conference on Machine Learning (2024)
work page 2024
-
[16]
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., Fagan, P.D., Hejna, J., Itkina, M., Lepert, M., Ma, Y.J., Miller, P.T., Wu, J., Belkhale, S., Dass, S., Ha, H., Jain, A., Lee, A., Lee, Y., Memmel, M., Park, S., Radosavovic, I., Wang, K., Zhan, A., Black, K., Chi, C., Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025) VP-VLA 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: Openvla: An open- source vision-language-action model (2024),https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2512.20014 (2025)
Lee, S., Mo, S., Han, W.S.: Bring my cup! personalizing vision-language-action models with visual attentive prompting. arXiv preprint arXiv:2512.20014 (2025)
-
[20]
arXiv preprint arXiv:2412.20451 (2024)
Li, J., Zhu, Y., Tang, Z., Wen, J., Zhu, M., Liu, X., Li, C., Cheng, R., Peng, Y., Peng, Y., et al.: Coa-vla: Improving vision-language-action models via visual- textual chain-of-affordance. arXiv preprint arXiv:2412.20451 (2024)
-
[21]
Li, Q., Liang, Y., Wang, Z., Luo, L., Chen, X., Liao, M., Wei, F., Deng, Y., Xu, S., Zhang,Y.,etal.:Cogact:Afoundationalvision-language-actionmodelforsynergiz- ing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li, X., Hsu, K., Gu, J., Pertsch, K., Mees, O., Walke, H.R., Fu, C., Lunawat, I., Sieh, I., Kirmani, S., et al.: Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2502.05485 (2025)
Li, Y., Deng, Y., Zhang, J., Jang, J., Memmel, M., Yu, R., Garrett, C.R., Ramos, F., Fox, D., Li, A., et al.: Hamster: Hierarchical action models for open-world robot manipulation. arXiv preprint arXiv:2502.05485 (2025)
-
[24]
LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Lian, S., Yu, B., Lin, X., Yang, L.T., Shen, Z., Wu, C., Miao, Y., Huang, C., Chen, K.: Bayesianvla: Bayesian decomposition of vision language action models via latent action queries. arXiv preprint arXiv:2601.15197 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Bench- marking knowledge transfer for lifelong robot learning (2023),https://arxiv. org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Liu, H., Li, X., Li, P., Liu, M., Wang, D., Liu, J., Kang, B., Ma, X., Kong, T., Zhang, H.: Towards generalist robot policies: What matters in building vision- language-action models (2025)
work page 2025
-
[27]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.L., Brockman, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 6892–6903. IEEE (2024)
work page 2024
-
[31]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: Spatialvla: Exploring spatial representations for visual-language- action model. arXiv preprint arXiv:2501.15830 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
- [33]
- [34]
-
[35]
Team, G.R., Abeyruwan, S., Ainslie, J., Alayrac, J.B., Arenas, M.G., Armstrong, T., Balakrishna, A., Baruch, R., Bauza, M., Blokzijl, M., Bohez, S., Bousmalis, K., Brohan, A., Buschmann, T., Byravan, A., Cabi, S., Caluwaerts, K., Casarini, F., Chang, O., Chen, J.E., Chen, X., Chiang, H.T.L., Choromanski, K., D’Ambrosio, D., Dasari, S., Davchev, T., Devin,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Team, Q.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C.C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabs...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
In: Conference on Robot Learning
Walke, H.R., Black, K., Zhao, T.Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A.W., Myers, V., Kim, M.J., Du, M., et al.: Bridgedata v2: A dataset for robot learning at scale. In: Conference on Robot Learning. pp. 1723–1736. PMLR (2023)
work page 2023
- [40]
-
[41]
In: Proceedings of the computer vision and pattern recognition conference
Yang, J., Tan, R., Wu, Q., Zheng, R., Peng, B., Liang, Y., Gu, Y., Cai, M., Ye, S., Jang, J., et al.: Magma: A foundation model for multimodal ai agents. In: Proceedings of the computer vision and pattern recognition conference. pp. 14203– 14214 (2025)
work page 2025
-
[42]
Zawalski,M.,Chen,W.,Pertsch,K.,Mees,O.,Finn,C.,Levine,S.:Roboticcontrol via embodied chain-of-thought reasoning (2025),https://arxiv.org/abs/2407. 08693
work page 2025
-
[43]
arXiv preprint arXiv:2507.04447 (2025) 3, 7, 14
Zhang, W., Liu, H., Qi, Z., Wang, Y., Yu, X., Zhang, J., Dong, R., He, J., Lu, F., Wang, H., et al.: Dreamvla: a vision-language-action model dreamed with compre- hensive world knowledge. arXiv preprint arXiv:2507.04447 (2025)
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, Q., Lu, Y., Kim, M.J., Fu, Z., Zhang, Z., Wu, Y., Li, Z., Ma, Q., Han, S., Finn, C., et al.: Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1702–1713 (2025) 20 Z. Wang et al
work page 2025
-
[45]
arXiv preprint arXiv:2412.10345 (2024) 13
Zheng, R., Liang, Y., Huang, S., Gao, J., Daumé III, H., Kolobov, A., Huang, F., Yang, J.: Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345 (2024)
-
[46]
Dexgraspvla: A vision-language- action framework towards general dexterous grasping,
Zhong, Y., Huang, X., Li, R., Zhang, C., Chen, Z., Guan, T., Zeng, F., Lui, K.N., Ye, Y., Liang, Y., et al.: Dexgraspvla: A vision-language-action framework towards general dexterous grasping. arXiv preprint arXiv:2502.20900 (2025)
-
[47]
Zhong, Z., Yan, H., Li, J., Liu, X., Gong, X., Zhang, T., Song, W., Chen, J., Zheng, X., Wang, H., et al.: Flowvla: Visual chain of thought-based motion reasoning for vision-language-action models. arXiv preprint arXiv:2508.18269 (2025)
-
[48]
Zhou, X., Xu, Y., Tie, G., Chen, Y., Zhang, G., Chu, D., Zhou, P., Sun, L.: Libero- pro: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827 (2025) VP-VLA 21 Supplementary Material for “VP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models” A Extended Ablation Result...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.