Toward Robust In-Context Segmentation via Concept Guidance
Pith reviewed 2026-06-29 04:22 UTC · model grok-4.3
The pith
Extracting semantic concepts from references makes in-context segmentation more robust to varying examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
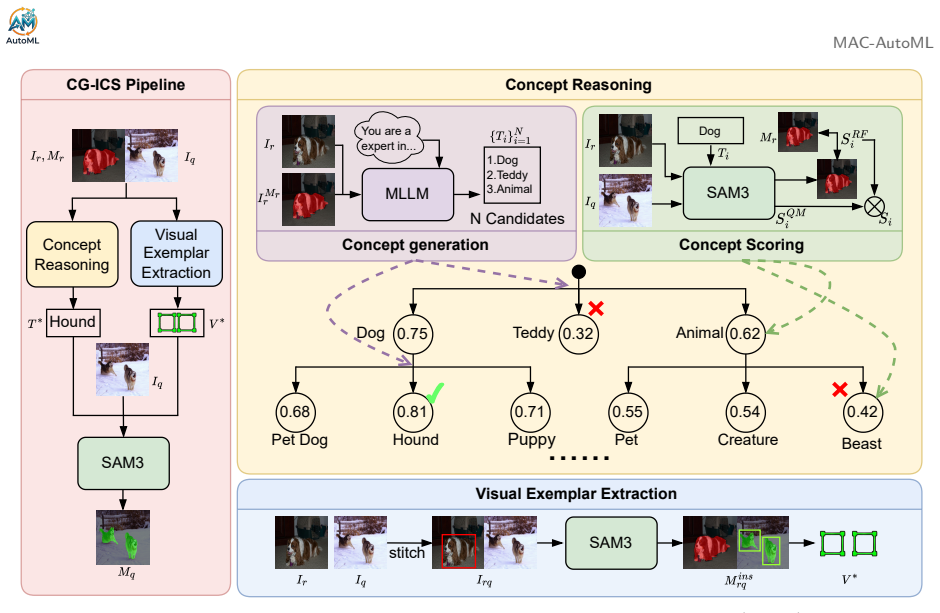
The paper establishes that performing in-context segmentation by extracting high-level semantic concepts from references rather than relying solely on low-level visual matching, via a concept reasoning module that uses an MLLM to propose candidates and a SAM3-driven scoring function with tree-search refinement to select reliable textual concepts, together with a parallel visual exemplar route that provides query-side spatial grounding, activates the segmentation capability of a frozen SAM3 backbone and yields both state-of-the-art accuracy and substantially improved robustness with significantly reduced variance across diverse reference choices.
What carries the argument
The concept reasoning module, which uses an MLLM to propose candidate concepts and a SAM3-driven scoring function with tree-search refinement to select reliable textual concepts, operating in parallel with a visual exemplar route for spatial grounding.
If this is right
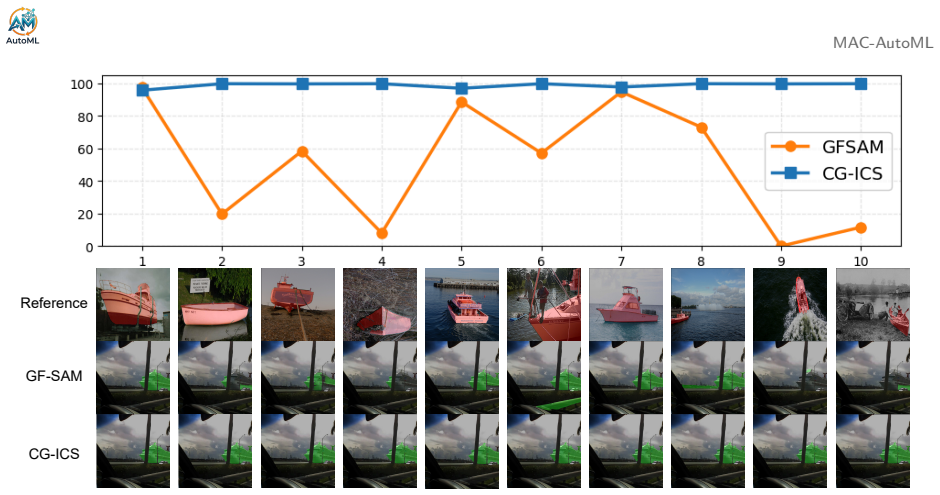
- Segmentation results become markedly more stable when the supplied reference images are swapped.
- Accuracy reaches state-of-the-art levels on standard ICS benchmarks.
- The backbone remains frozen, so no parameter updates are required.
- Textual concepts and visual exemplars are used together to activate the segmentation model.
Where Pith is reading between the lines
- Semantic concept guidance may reduce sensitivity to low-level variations in other few-shot vision settings where example consistency matters.
- The same proposer-plus-scorer pattern could be tested for stabilizing outputs in few-shot detection or classification under changing references.
- If tree-search refinement proves essential, simpler selection heuristics might be compared to isolate which component drives the variance reduction.
Load-bearing premise
An MLLM can reliably propose candidate concepts and the SAM3-driven scoring function with tree-search refinement will consistently select concepts that improve segmentation stability when references vary.
What would settle it
Measure segmentation metric variance on standard benchmark queries across multiple distinct reference sets; if the variance remains as high as in visual-matching baselines after applying the concept module, the robustness claim does not hold.
Figures

read the original abstract
In-context segmentation (ICS) requires a model to segment target regions in a query image using only a few reference images and their corresponding masks, without updating any parameters. Despite recent progress, prior ICS studies have largely overlooked a critical aspect: system robustness, ie, whether the model can produce stable segmentation results for the same query under different references. In this work, we revisit ICS from the robustness perspective and introduce a novel paradigm, Concept-Guided In-Context Segmentation (CG-ICS), which performs segmentation by extracting high-level semantic concepts from references rather than relying solely on low-level visual matching. Specifically, CG-ICS introduces a concept reasoning module that uses an MLLM to propose candidates and a SAM3-driven scoring function with tree-search refinement to select reliable textual concepts, together with a parallel visual exemplar route that provides query-side spatial grounding via a simple context construction. Both the textual concept and the visual exemplar are then used to activate the segmentation capability of a frozen SAM3 backbone. Extensive experiments on standard ICS benchmarks demonstrate that CG-ICS not only achieves state-of-the-art accuracy but also substantially improves robustness, yielding a more reliable ICS system with significantly reduced variance across diverse reference choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Concept-Guided In-Context Segmentation (CG-ICS), a paradigm for in-context segmentation that extracts high-level semantic concepts from reference images via an MLLM candidate proposal step, followed by a SAM3-driven scoring function with tree-search refinement to select reliable textual concepts. These are combined with a parallel visual exemplar route for spatial grounding and used to activate a frozen SAM3 backbone. The central claim is that this yields state-of-the-art accuracy on standard ICS benchmarks while substantially improving robustness through significantly reduced variance across diverse reference choices.
Significance. If the robustness results hold under rigorous validation, the work would be significant for shifting ICS research toward reliability rather than accuracy alone. The explicit focus on variance across references addresses a previously overlooked practical failure mode, and the design choice of keeping SAM3 frozen while routing through high-level concepts offers a practical path to more stable systems without parameter updates.
major comments (2)
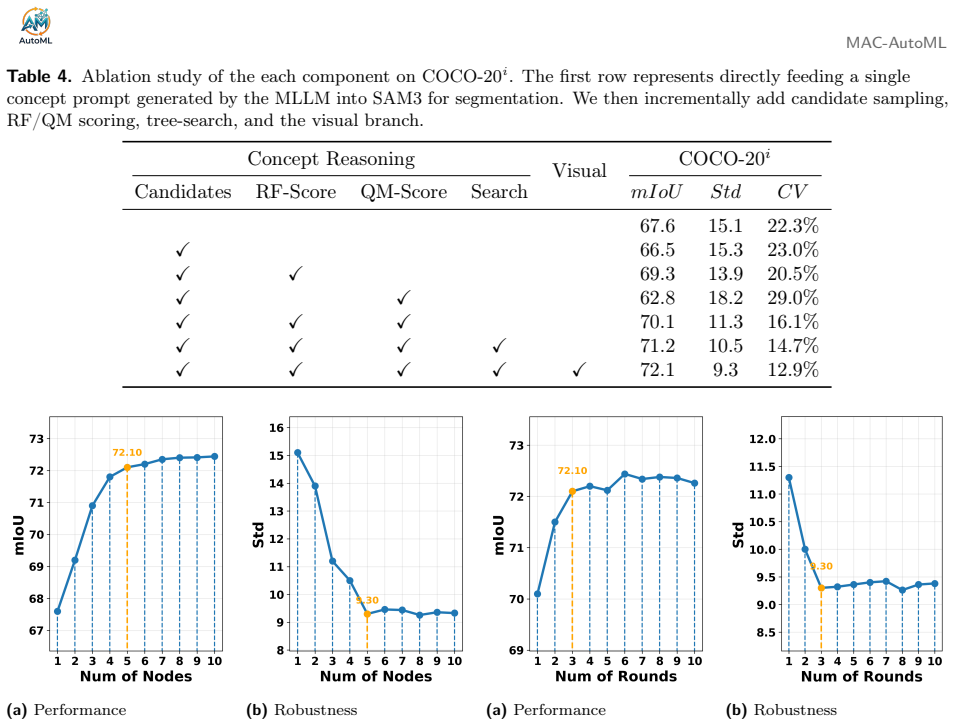
- [Abstract and §4 (Experiments)] The central robustness claim (reduced variance across references) rests on the unverified assumption that the concept reasoning module (MLLM proposal + SAM3 scoring + tree-search) consistently selects concepts that causally improve mask stability. No ablation is described that isolates this module's contribution to variance reduction versus the visual exemplar route alone, nor is the scoring function shown to be calibrated against measured mask variance.
- [Abstract] The abstract asserts SOTA accuracy and substantially reduced variance but supplies no quantitative numbers, error bars, dataset names, or baseline comparisons. Without these in the provided text, the load-bearing empirical claim cannot be assessed for effect size or statistical significance.
minor comments (2)
- [Method] Clarify the exact form of the SAM3-driven scoring function and how tree-search is implemented (depth, branching factor, termination criteria).
- [Experiments] Add a table or figure showing per-reference variance metrics (e.g., standard deviation of IoU or mask overlap) for CG-ICS versus prior ICS methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of our robustness claims. We address each major comment below and commit to revisions that directly strengthen the empirical support without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The central robustness claim (reduced variance across references) rests on the unverified assumption that the concept reasoning module (MLLM proposal + SAM3 scoring + tree-search) consistently selects concepts that causally improve mask stability. No ablation is described that isolates this module's contribution to variance reduction versus the visual exemplar route alone, nor is the scoring function shown to be calibrated against measured mask variance.
Authors: We agree that isolating the concept reasoning module's causal contribution to variance reduction is necessary to substantiate the robustness claim. In the revised manuscript we will add a dedicated ablation in §4 comparing full CG-ICS against the visual-exemplar-only variant, reporting per-reference variance on the same benchmarks. We will also add a calibration analysis plotting SAM3 concept scores against observed mask variance across reference choices to demonstrate that higher-scoring concepts correlate with lower variance. revision: yes
-
Referee: [Abstract] The abstract asserts SOTA accuracy and substantially reduced variance but supplies no quantitative numbers, error bars, dataset names, or baseline comparisons. Without these in the provided text, the load-bearing empirical claim cannot be assessed for effect size or statistical significance.
Authors: While the abstract is intentionally concise, we acknowledge that including key quantitative indicators would improve verifiability. We will revise the abstract to report concrete accuracy gains, variance reductions (with error bars), the primary datasets used, and direct baseline comparisons drawn from the experimental results in §4. revision: yes
Circularity Check
No circularity: methodological description with no derivations or equations
full rationale
The paper introduces CG-ICS as an empirical method using MLLM concept proposal, SAM3 scoring, and tree-search, evaluated on benchmarks for accuracy and robustness. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. The approach is described as a new paradigm relying on external components (MLLM, SAM3) rather than re-expressing prior quantities by construction. This is the common case of a self-contained engineering paper whose central claims rest on experimental outcomes, not internal reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An MLLM can propose candidate textual concepts that, when scored by SAM3, yield reliable guidance for segmentation.
- domain assumption A frozen SAM3 backbone can be activated by both textual concepts and visual exemplars to produce stable masks.
Reference graph
Works this paper leans on
-
[1]
Aakanksha and A. N. Rajagopalan. Improving robustness of semantic segmentation to motion-blur using class- centric augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10470–10479, June 2023
2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Visual prompting via image inpainting.Advances in Neural Information Processing Systems, 35:25005–25017, 2022
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei Efros. Visual prompting via image inpainting.Advances in Neural Information Processing Systems, 35:25005–25017, 2022
2022
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[7]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
2025
-
[8]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, October 2021
2021
-
[9]
Robustsam: Segment anything robustly on degraded images
Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhou Ma, and Jian Wang. Robustsam: Segment anything robustly on degraded images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4081–4091, June 2024
2024
-
[10]
Sansa: Unleashing the hidden semantics in sam2 for few-shot segmentation, 2025
Claudia Cuttano, Gabriele Trivigno, Giuseppe Averta, and Carlo Masone. Sansa: Unleashing the hidden semantics in sam2 for few-shot segmentation, 2025
2025
-
[11]
Semantic segmentation of degraded images using layer-wise feature adjustor
Kazuki Endo, Masayuki Tanaka, and Masatoshi Okutomi. Semantic segmentation of degraded images using layer-wise feature adjustor. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3205–3213, January 2023
2023
-
[12]
The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010
2010
-
[13]
Yunhe Gao, Di Liu, Zhuowei Li, Yunsheng Li, Dongdong Chen, Mu Zhou, and Dimitris N. Metaxas. Show and segment: Universal medical image segmentation via in-context learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20830–20840, June 2025
2025
-
[14]
Degraded image semantic segmentation with dense-gram networks.IEEE Transactions on Image Processing, 29:782–795, 2020
Dazhou Guo, Yanting Pei, Kang Zheng, Hongkai Yu, Yuhang Lu, and Song Wang. Degraded image semantic segmentation with dense-gram networks.IEEE Transactions on Image Processing, 29:782–795, 2020. 12 MAC-AutoML
2020
-
[15]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5356–5364, June 2019
2019
-
[16]
Semantic contours from inverse detectors
Bharath Hariharan, Pablo Arbeláez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 991–998, 2011
2011
-
[17]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, June 2022
2022
-
[18]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[19]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023
2023
-
[20]
Fss-1000: A 1000-class dataset for few-shot segmentation
Xiang Li, Tianhan Wei, Yau Pun Chen, Yu-Wing Tai, and Chi-Keung Tang. Fss-1000: A 1000-class dataset for few-shot segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2869–2878, June 2020
2020
-
[21]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[22]
A simple image segmentation framework via in-context examples.Advances in Neural Information Processing Systems, 37: 25095–25119, 2024
Yang Liu, Chenchen Jing, Hengtao Li, Muzhi Zhu, Hao Chen, Xinlong Wang, and Chunhua Shen. A simple image segmentation framework via in-context examples.Advances in Neural Information Processing Systems, 37: 25095–25119, 2024
2024
-
[23]
Matcher: Segment anything with one shot using all-purpose feature matching
Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen. Matcher: Segment anything with one shot using all-purpose feature matching. InInternational Conference on Learning Representations, volume 2024, pages 17904–17925, 2024
2024
-
[24]
Segic: Unleashing the emergent correspondence for in-context segmentation
Lingchen Meng, Shiyi Lan, Hengduo Li, Jose M Alvarez, Zuxuan Wu, and Yu-Gang Jiang. Segic: Unleashing the emergent correspondence for in-context segmentation. InEuropean Conference on Computer Vision, pages 203–220. Springer, 2024
2024
-
[25]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatu...
2023
-
[26]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos. InInternational Conference o...
2025
-
[27]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022
2022
-
[28]
Unicl-sam: Uncertainty-driven in-context segmentation with part prototype discovery
Dianmo Sheng, Dongdong Chen, Zhentao Tan, Qiankun Liu, Qi Chu, Tao Gong, Bin Liu, Jing Han, Wenbin Tu, Shengwei Xu, and Nenghai Yu. Unicl-sam: Uncertainty-driven in-context segmentation with part prototype discovery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20201–20211, June 2025
2025
-
[29]
Vrp-sam: Sam with visual reference prompt
Yanpeng Sun, Jiahui Chen, Shan Zhang, Xinyu Zhang, Qiang Chen, Gang Zhang, Errui Ding, Jingdong Wang, and Zechao Li. Vrp-sam: Sam with visual reference prompt. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23565–23574, June 2024. 13 MAC-AutoML
2024
-
[30]
Rethinking and improving visual prompt selection for in-context learning segmentation
Wei Suo, Lanqing Lai, Mengyang Sun, Hanwang Zhang, Peng Wang, and Yanning Zhang. Rethinking and improving visual prompt selection for in-context learning segmentation. InEuropean Conference on Computer Vision, pages 18–35. Springer, 2024
2024
-
[31]
Wailing Tang, Biqi Yang, Pheng-Ann Heng, Yun-Hui Liu, and Chi-Wing Fu. Overcoming support dilution for robust few-shot semantic segmentation.arXiv preprint arXiv:2501.13529, 2025
-
[32]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Explore in-context segmentation via latent diffusion models
Chaoyang Wang, Xiangtai Li, Henghui Ding, Lu Qi, Jiangning Zhang, Yunhai Tong, Chen Change Loy, and Shuicheng Yan. Explore in-context segmentation via latent diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7545–7553, 2025
2025
-
[34]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Images speak in images: A generalist painter for in-context visual learning
Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6830–6839, June 2023
2023
-
[36]
Seggpt: Towards segmenting everything in context
Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, and Tiejun Huang. Seggpt: Towards segmenting everything in context. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1130–1140, October 2023
2023
-
[37]
Weihao Xia, Zhanglin Cheng, Yujiu Yang, and Jing-Hao Xue. Cooperative semantic segmentation and image restoration in adverse environmental conditions.arXiv preprint arXiv:1911.00679, 2019
-
[38]
Towards global optimal visual in-context learning prompt selection.Advances in Neural Information Processing Systems, 37:74945–74965, 2024
Chengming Xu, Chen Liu, Yikai Wang, Yuan Yao, and Yanwei Fu. Towards global optimal visual in-context learning prompt selection.Advances in Neural Information Processing Systems, 37:74945–74965, 2024
2024
-
[39]
Self-feature distillation with uncertainty modeling for degraded image recognition
Zhou Yang, Weisheng Dong, Xin Li, Jinjian Wu, Leida Li, and Guangming Shi. Self-feature distillation with uncertainty modeling for degraded image recognition. InEuropean Conference on Computer Vision, pages 552–569. Springer, 2022
2022
-
[40]
Bridge the points: Graph-based few-shot segment anything semantically.Advances in Neural Information Processing Systems, 37:33232–33261, 2024
Anqi Zhang, Guangyu Gao, Jianbo Jiao, Chi Liu, and Yunchao Wei. Bridge the points: Graph-based few-shot segment anything semantically.Advances in Neural Information Processing Systems, 37:33232–33261, 2024
2024
-
[41]
Personalize segment anything model with one shot
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Yu Qiao, Gao Peng, and Hongsheng Li. Personalize segment anything model with one shot. InInternational Conference on Learning Representations, volume 2024, pages 18250–18279, 2024
2024
-
[42]
What makes good examples for visual in-context learning? Advances in Neural Information Processing Systems, 36:17773–17794, 2023
Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. What makes good examples for visual in-context learning? Advances in Neural Information Processing Systems, 36:17773–17794, 2023
2023
-
[43]
Unleashing the potential of the diffusion model in few-shot semantic segmentation.Advances in Neural Information Processing Systems, 37:42672–42695, 2024
Muzhi Zhu, Yang Liu, Zekai Luo, Chenchen Jing, Hao Chen, Guangkai Xu, Xinlong Wang, and Chunhua Shen. Unleashing the potential of the diffusion model in few-shot semantic segmentation.Advances in Neural Information Processing Systems, 37:42672–42695, 2024. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.