Tandem Reinforcement Learning with Verifiable Rewards
Pith reviewed 2026-06-29 03:53 UTC · model grok-4.3
The pith
Tandem reinforcement learning matches standard GRPO on solo math reasoning while producing chains of thought that weaker models can follow more reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
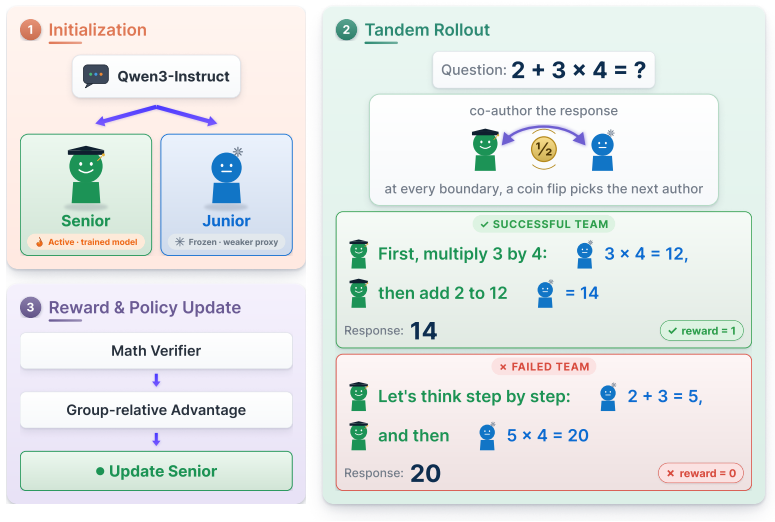
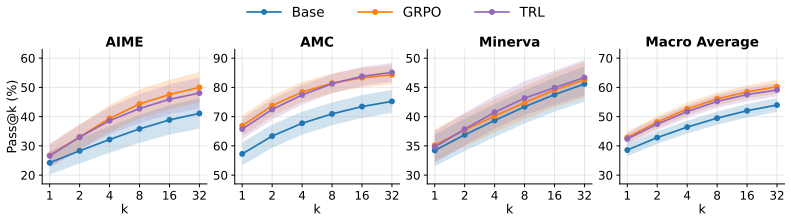
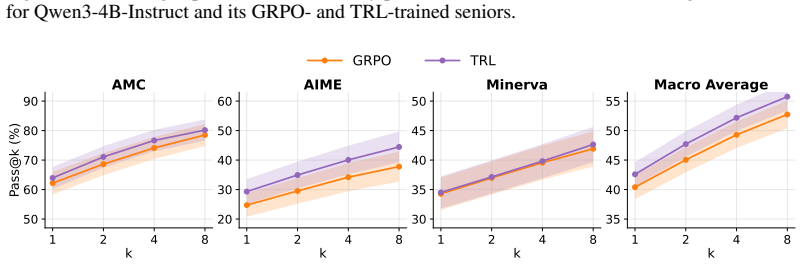
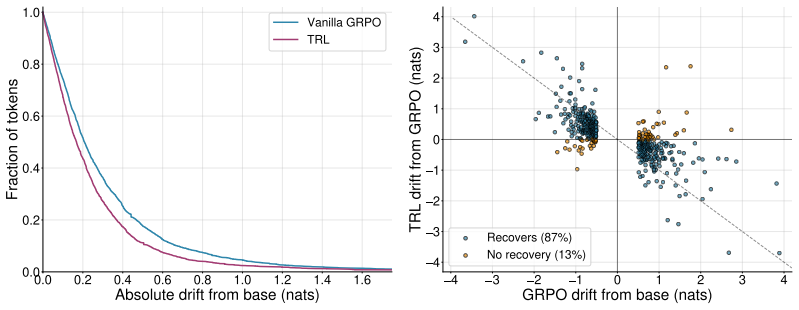
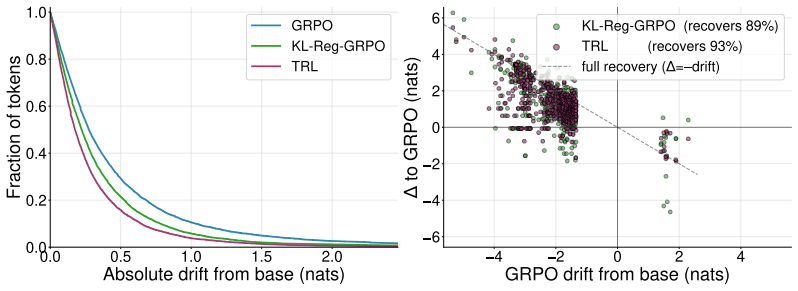
TRL carries the tandem training paradigm into RLVR: the senior and a frozen junior alternate stochastically to co-generate the reasoning trace, the resulting generation receives the verifiable reward, and the standard GRPO loss is applied solely to the senior; when trained on competition math this matches vanilla GRPO on solo reasoning capability while the same structure produces stronger handoff robustness with the junior, reduced distributional drift from the junior, and a chain-of-thought more legible to the junior.
What carries the argument
The tandem rollout structure in which senior and frozen junior alternate stochastically to produce each reasoning step, with the combined generation receiving the verifiable reward and GRPO loss applied only to the senior.
If this is right
- The same training run that preserves solo reasoning also improves the senior's ability to hand off mid-trace to the junior without loss of correctness.
- Distributional drift away from the junior's output distribution is reduced as a direct consequence of the joint reward on the tandem rollout.
- The resulting chain-of-thought becomes more legible to the junior without any separate readability objective being added to the loss.
- The method can be applied to any RLVR domain that already uses GRPO without changing the underlying verifier or reward signal.
Where Pith is reading between the lines
- The approach may allow a single training run to produce models usable both as standalone reasoners and as collaborators with fixed weaker systems.
- If the handoff robustness generalizes, TRL could reduce the need for separate alignment stages aimed at human readability of long traces.
- The stochastic alternation mechanism itself may be the minimal change needed to make RLVR outputs usable in multi-model pipelines.
Load-bearing premise
The tandem training paradigm scales to the long chains of thought of the modern RLVR pipeline without introducing new failure modes in extended reasoning traces.
What would settle it
Training the same senior model on problems whose solutions require reasoning traces substantially longer than those used in the reported experiments and checking whether new inconsistencies or unrecoverable handoff failures appear at a higher rate than in the baseline GRPO runs.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has significantly improved the reasoning capability of large language models, reaching expert or even superhuman performance in domains such as competition math. However, whether weaker agents and humans can actually harness this capability is far less certain, with RLVR documented to drift reasoning toward idiosyncratic patterns such as poor readability and language mixing. Tandem training is a recently introduced paradigm that targets this compatibility problem: a trained, stronger senior co-generates each rollout with a frozen, weaker junior, and the two are rewarded as a team, so the senior is pushed to reason in ways the junior can follow. Yet this paradigm has so far been demonstrated only in proof-of-concept settings, leaving open whether it scales to the long chains of thought of the modern RLVR pipeline. In this work, we propose Tandem Reinforcement Learning (TRL), which carries the tandem training paradigm into RLVR. In TRL, the senior and a frozen junior alternate stochastically to co-generate the reasoning, the resulting generation is rewarded, and the standard GRPO loss is applied to the senior. Training Qwen3-4B-Instruct on competition math, we find that TRL matches vanilla GRPO on solo reasoning capability while three properties emerge together from the same rollout structure: stronger handoff robustness with the junior, reduced distributional drift from the junior, and a chain-of-thought more legible to the junior. Our results demonstrate a promising route for RLVR with practical payoffs in multi-model communication and human compatibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tandem Reinforcement Learning (TRL) to extend the tandem training paradigm to RLVR. A senior model co-generates each rollout with a frozen junior via stochastic alternation; the joint generation receives a verifiable reward and the standard GRPO loss is applied only to the senior. On Qwen3-4B-Instruct trained on competition math, TRL is reported to match vanilla GRPO on solo reasoning accuracy while the same training run yields three compatibility improvements: stronger handoff robustness, reduced distributional drift, and more legible CoT for the junior.
Significance. If the empirical comparisons hold under standard controls, the work is significant for demonstrating that tandem rollouts scale to the long CoT traces of modern RLVR without new failure modes. The fact that the three compatibility properties emerge together from the identical rollout structure, rather than requiring separate objectives, is a clear strength and directly addresses the compatibility problem noted in prior RLVR literature. The use of verifiable rewards on competition math and the direct GRPO baseline further ground the result in a practically relevant setting.
minor comments (2)
- Abstract: the statement that TRL 'matches vanilla GRPO on solo reasoning capability' would be more informative if it referenced the specific accuracy figures, number of runs, and variance reported in the experimental section.
- The definitions and quantitative metrics used to measure 'handoff robustness', 'distributional drift', and 'legibility' should be stated explicitly (e.g., exact prompting protocol for handoff tests, divergence measure, or human/AI readability score) so that the three-property claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation of minor revision. The referee's summary correctly captures the core contribution of extending tandem training to RLVR pipelines via stochastic alternation and the emergence of compatibility properties from the same rollout structure.
Circularity Check
No significant circularity; purely empirical comparison
full rationale
The paper reports experimental results from training Qwen3-4B-Instruct with TRL versus vanilla GRPO on competition math tasks. It measures solo accuracy and three compatibility properties directly from the same rollout runs, with no equations, derivations, fitted parameters renamed as predictions, or self-citation chains. All claims reduce to observable outcomes on external benchmarks rather than internal definitions or self-referential constructions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision.arXiv preprint arXiv:2312.09390,
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. Gpg: A simple and strong reinforcement learning baseline for model reasoning.arXiv preprint arXiv:2504.02546, 2025a. Yuanlin Chu, Bo Wang, Xiang Liu, Hong Chen, Aiwei Liu, and Xuming Hu. Ssr: Speculative parallel scaling reasoning in test-time.arXiv preprint arXiv:2505.15340, 2025b. Tim R ...
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Karim Hamade, Reid McIlroy-Young, Siddhartha Sen, Jon Kleinberg, and Ashton Anderson. Design- ing skill-compatible ai: Methodologies and frameworks in chess.arXiv preprint arXiv:2405.05066,
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
URLhttps://arxiv.org/abs/2103.03874. NeurIPS 2021 Datasets and Benchmarks Track. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
The steganographic potentials of language models.arXiv preprint arXiv:2505.03439,
Artem Karpov, Tinuade Adeleke, Seong Hah Cho, and Natalia Perez-Campanero. The steganographic potentials of language models.arXiv preprint arXiv:2505.03439,
-
[9]
Prover-verifier games improve legibility of llm outputs.arXiv preprint arXiv:2407.13692,
Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, and Yuri Burda. Prover-verifier games improve legibility of llm outputs.arXiv preprint arXiv:2407.13692,
-
[10]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan- ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
The impact of language mixing on bilingual llm reasoning
Yihao Li, Jiayi Xin, Miranda Muqing Miao, Qi Long, and Lyle Ungar. The impact of language mixing on bilingual llm reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 32519–32536,
2025
-
[12]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.arXiv preprint arXiv:2603.22446,
-
[14]
URL https://arxiv.org/abs/2203.02155. NeurIPS
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Joey Skaf, Luis Ibanez-Lissen, Robert McCarthy, Connor Watts, Vasil Georgiv, Hannes Whittingham, Lorena Gonzalez-Manzano, David Lindner, Cameron Tice, Edward James Young, et al. Large lan- guage models can learn and generalize steganographic chain-of-thought under process supervision. arXiv preprint arXiv:2506.01926,
-
[17]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Xiao Wang, Jia Wang, Yijie Wang, Pengtao Dang, Sha Cao, and Chi Zhang. Mars: toward more efficient multi-agent collaboration for llm reasoning.arXiv preprint arXiv:2509.20502,
-
[19]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URLhttps://arxiv.org/abs/2503.14476. 13 Guanning Zeng, Zhaoyi Zhou, Daman Arora, and Andrea Zanette. Shrinking the variance: Shrinkage baselines for reinforcement learning with verifiable rewards.arXiv preprint arXiv:2511.03710,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245,
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F Wong, and Yu Cheng. Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245,
-
[22]
Improving sampling efficiency in rlvr through adaptive rollout and response reuse
Yuheng Zhang, Wenlin Yao, Changlong Yu, Yao Liu, Qingyu Yin, Bing Yin, Hyokun Yun, and Lihong Li. Improving sampling efficiency in rlvr through adaptive rollout and response reuse. arXiv preprint arXiv:2509.25808,
-
[23]
Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673,
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shao- han Huang, Lei Cui, Qixiang Ye, et al. Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673,
-
[24]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025a. Haizhong Zheng, Yang Zhou, Brian R Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning ...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
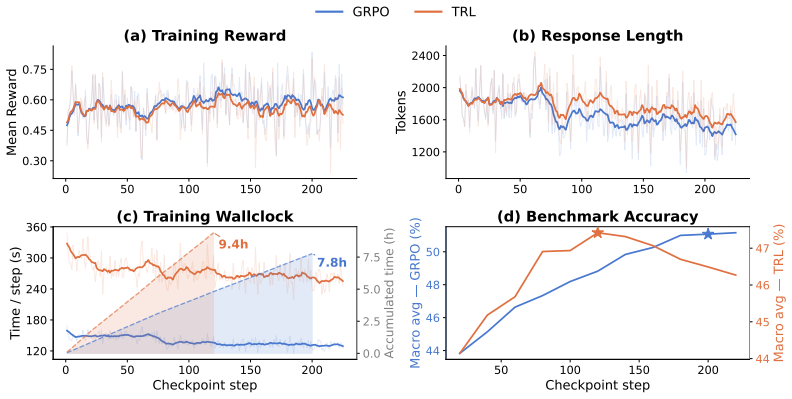
14 A Reproducibility A.1 Tandem rollout implementation A naive realization of tandem rollout couples two HuggingFace models in an outer Python loop with manual KV-cache management. We built such a prototype and found it impractical for RL training: at 512 generated tokens it exhausts the memory of a single 80 GB GPU, making RLVR under long chain-of-though...
2025
-
[26]
6Compiled from AIME (American Invitational Mathematics Examination) of 2024, 2025, and
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.