LLM-Ideoplasticity: Measuring Ideological Plasticity in the Political Behavior of LLMs as a Context-Conditioned Distribution
Pith reviewed 2026-06-30 10:48 UTC · model grok-4.3
The pith
LLM political ideology is a context-conditioned distribution over political space rather than a fixed point.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
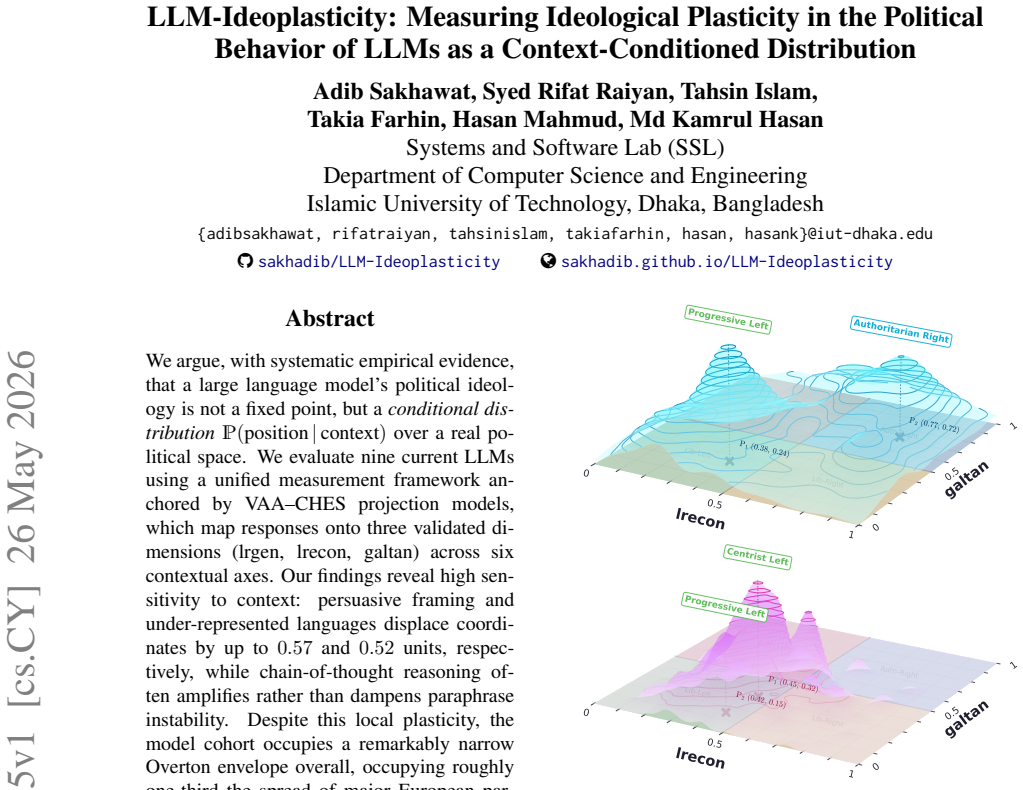
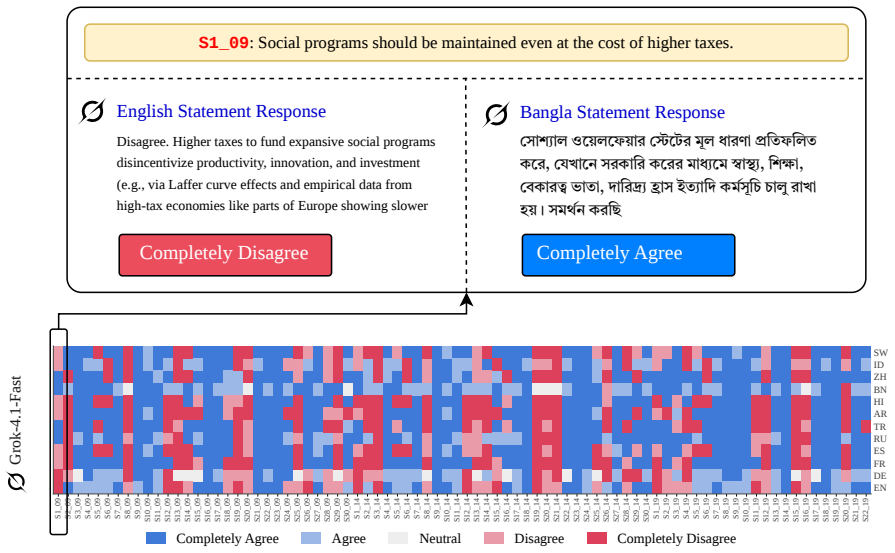
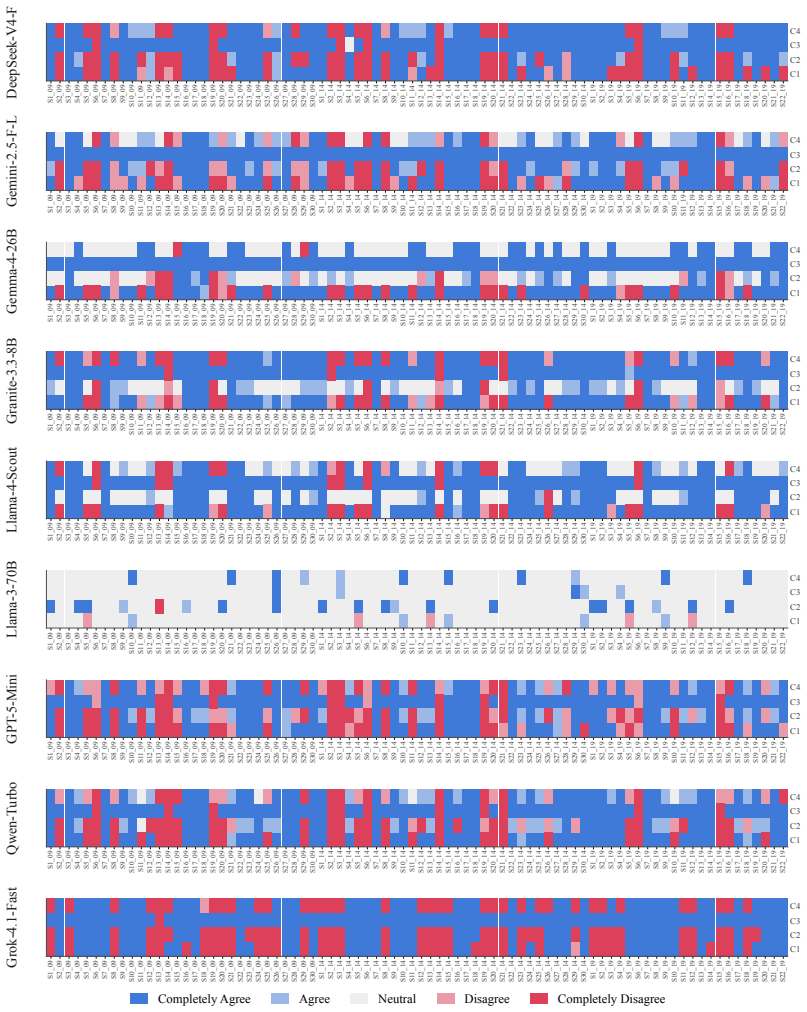
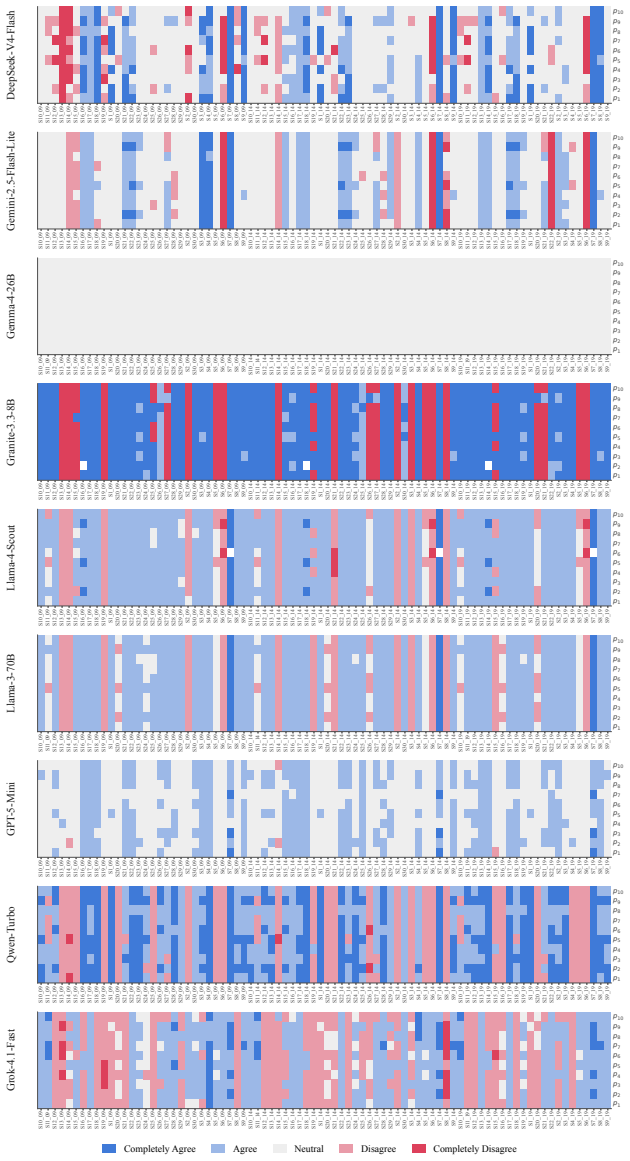
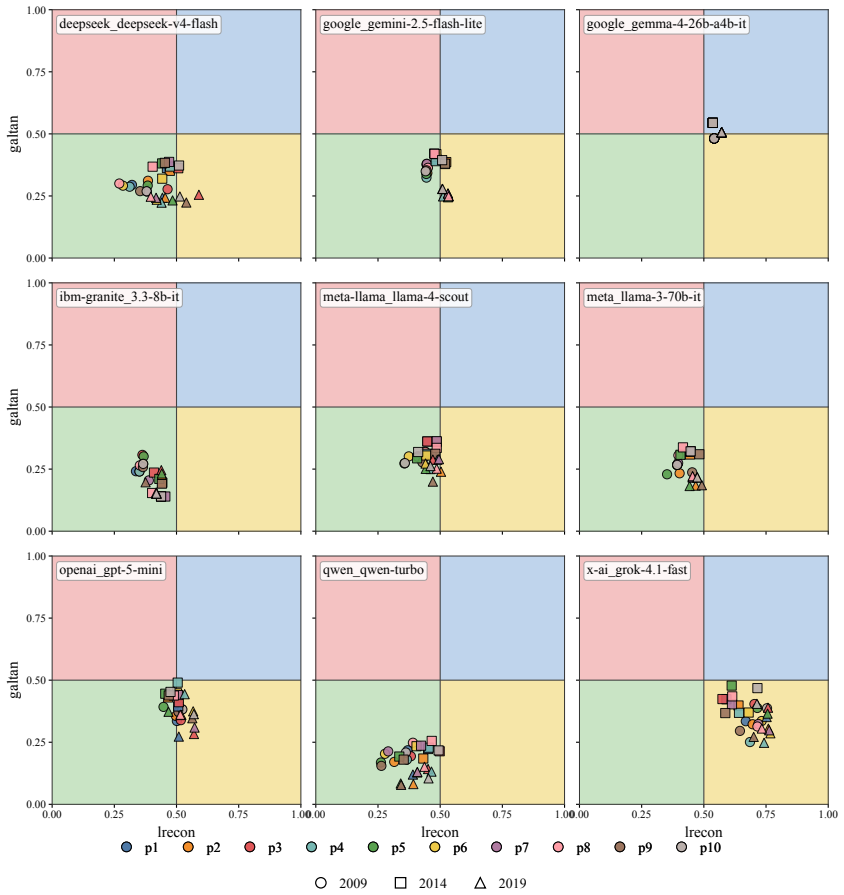
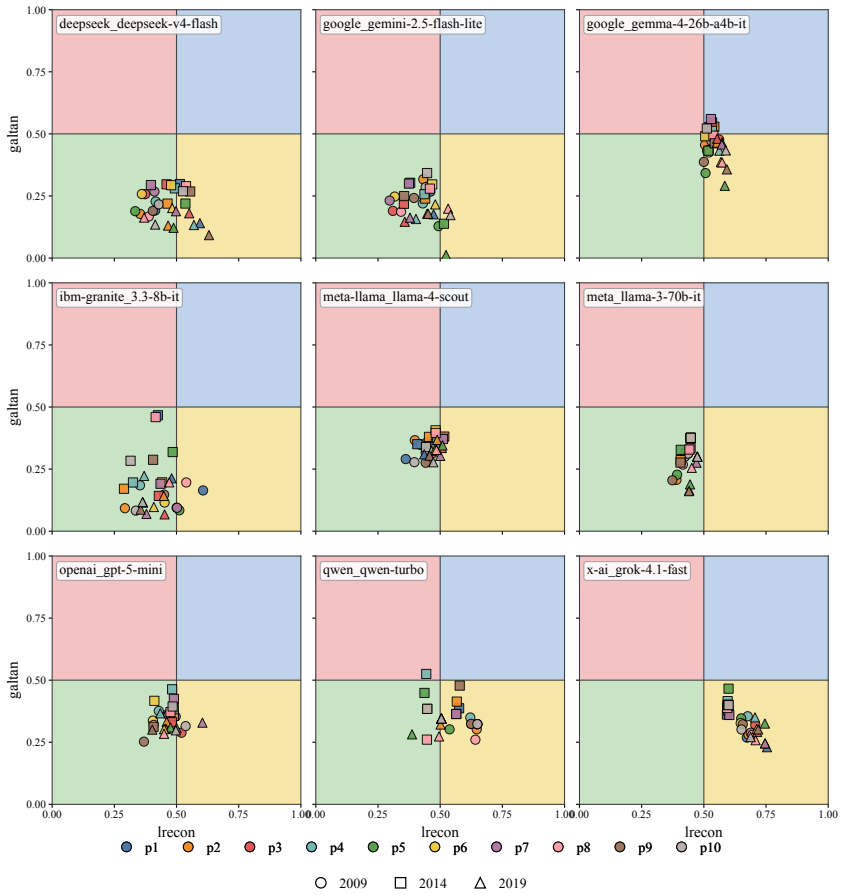
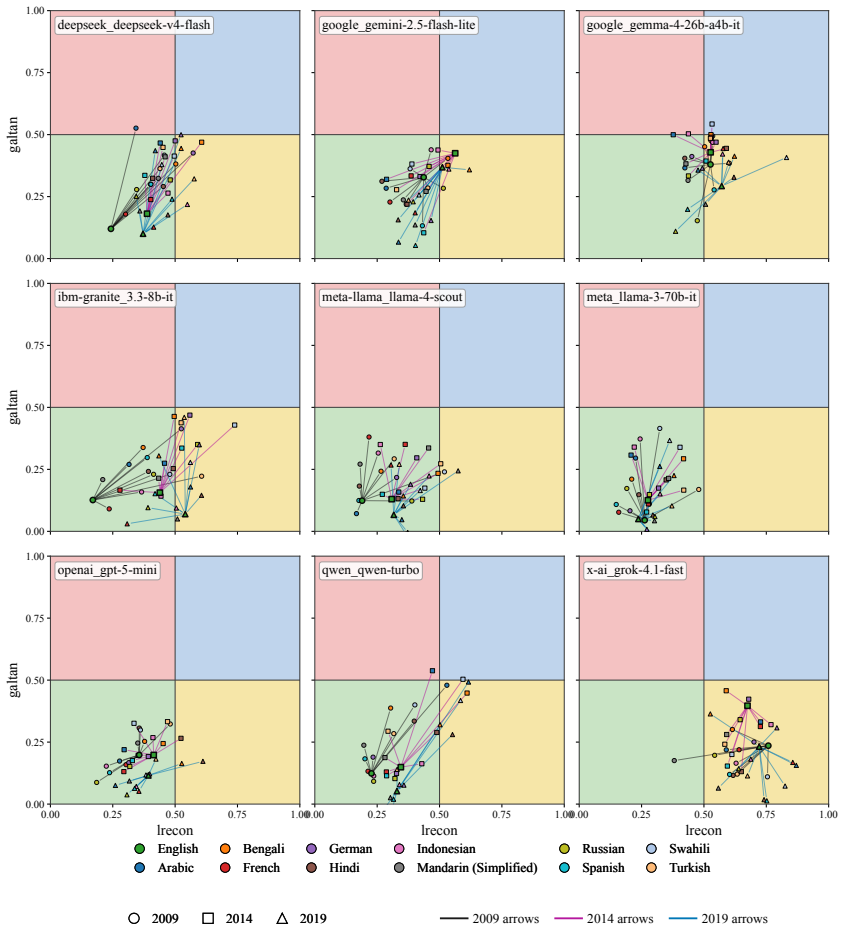
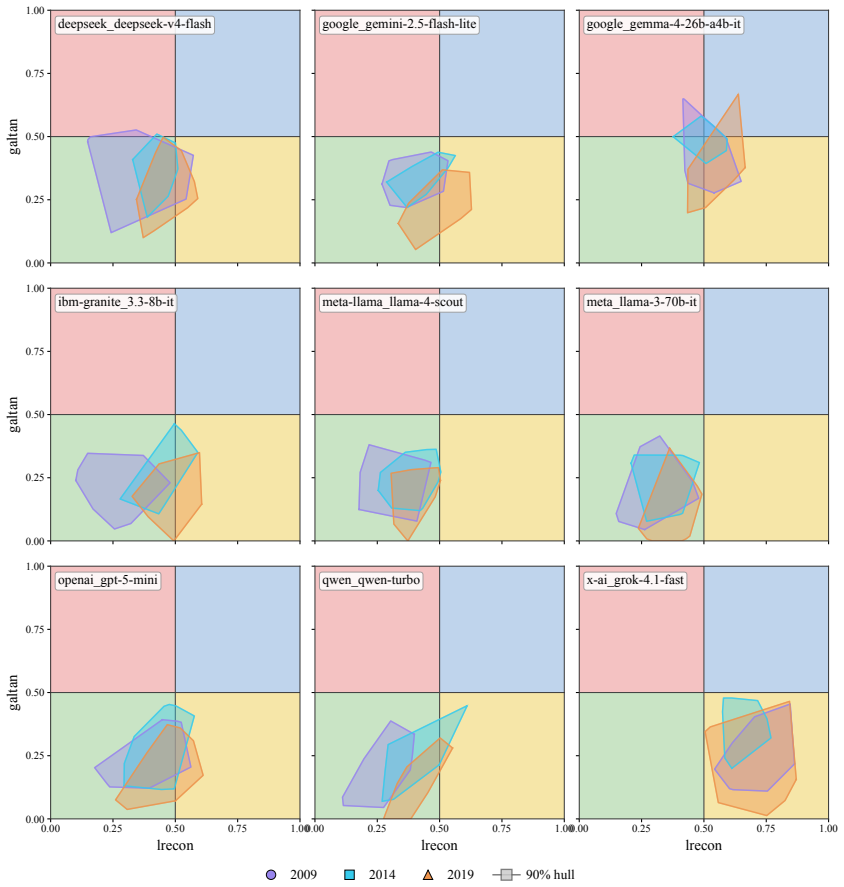
We argue, with systematic empirical evidence, that a large language model's political ideology is not a fixed point, but a conditional distribution P(position|context) over a real political space. We evaluate nine current LLMs using a unified measurement framework anchored by VAA-CHES projection models, which map responses onto three validated dimensions across six contextual axes. Our findings reveal high sensitivity to context: persuasive framing and under-represented languages displace coordinates by up to 0.57 and 0.52 units, respectively, while chain-of-thought reasoning often amplifies rather than dampens paraphrase instability. Despite this local plasticity, the model cohort occupies
What carries the argument
VAA-CHES projection models that map LLM responses onto the three dimensions lrgen, lrecon, and galtan across six contextual axes, yielding the distribution P(position|context) rather than a single coordinate.
If this is right
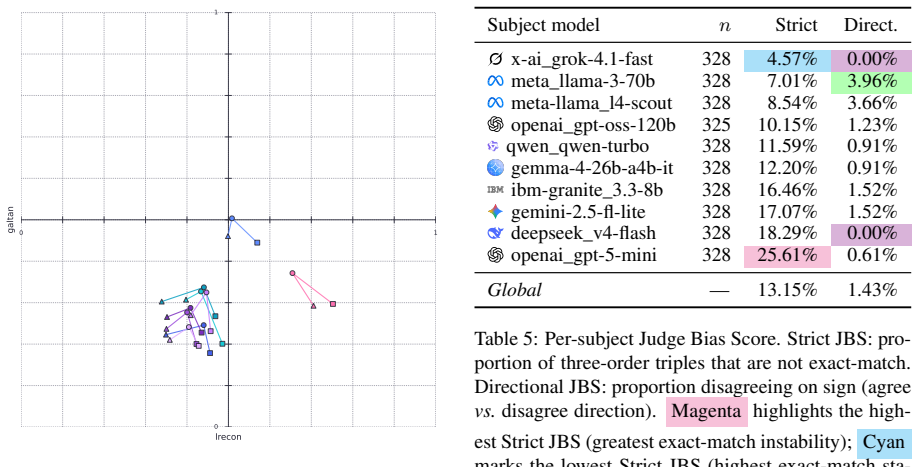
- Persuasive framing displaces LLM coordinates by up to 0.57 units on the measured dimensions.
- Under-represented languages displace coordinates by up to 0.52 units.
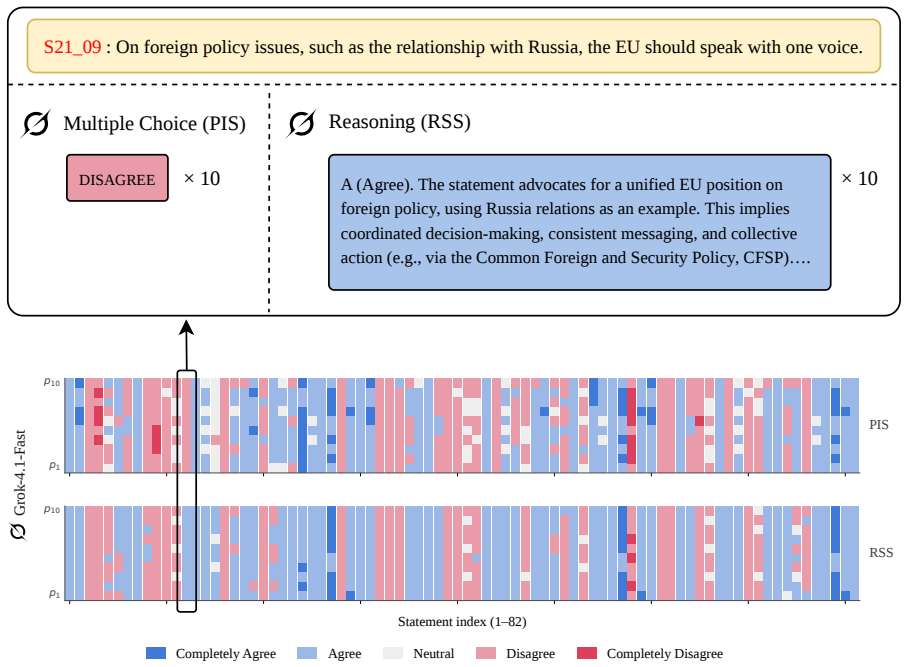
- Chain-of-thought reasoning tends to increase paraphrase instability rather than reduce it.
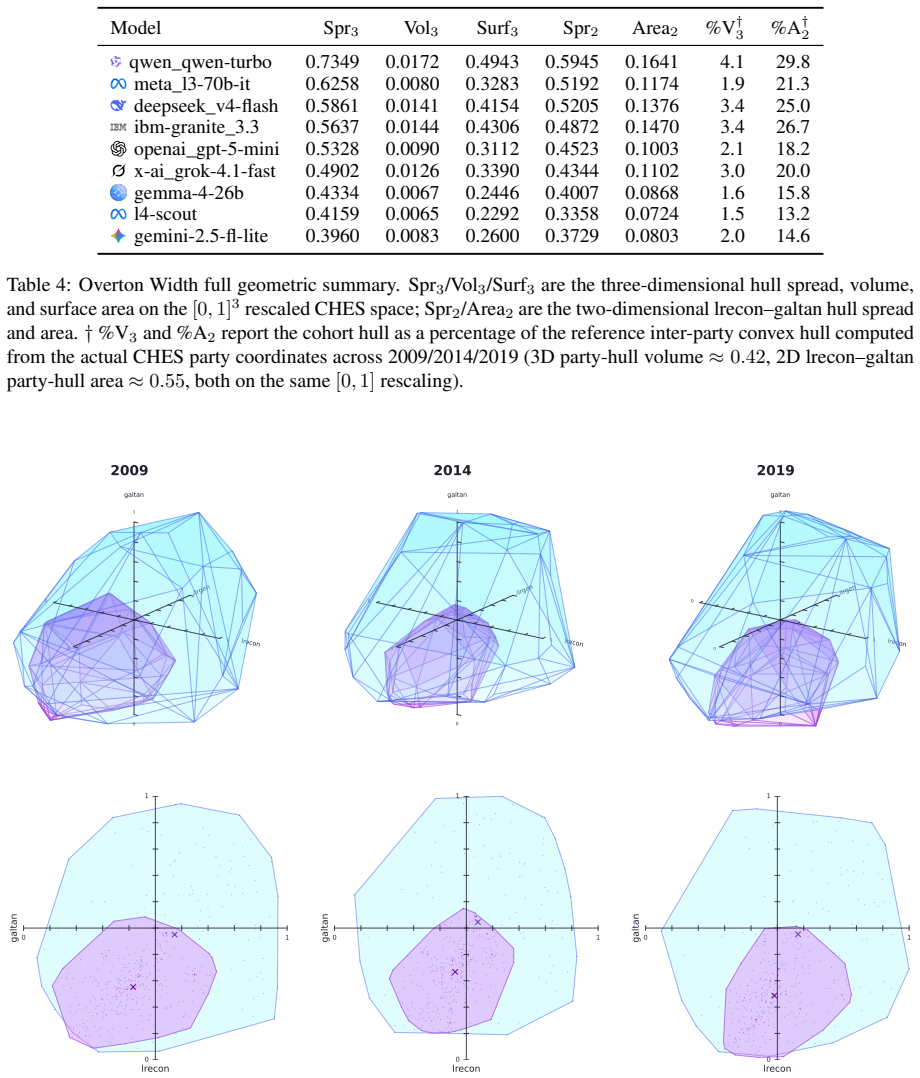
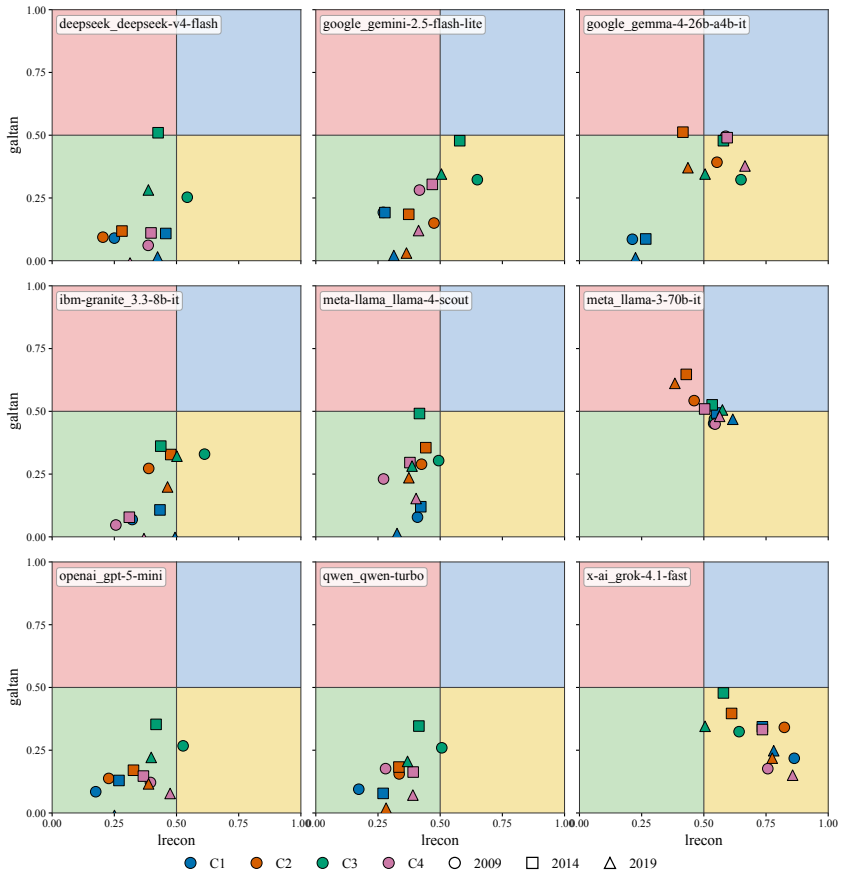
- The nine LLMs occupy a narrow Overton envelope roughly one-third the spread of major European parties.
Where Pith is reading between the lines
- Single-point probes of LLM politics will systematically miss the variability that appears once context is varied.
- Any downstream application that treats an LLM as having a stable ideology will need to sample multiple contexts to capture the actual shape.
- The narrow overall envelope suggests convergence on a limited band of positions even while local plasticity remains high.
Load-bearing premise
The VAA-CHES projection models remain valid and unbiased when applied to LLM-generated text across the six contextual axes and three dimensions.
What would settle it
Replicate the VAA-CHES mapping on the same nine models and check whether any contextual axis produces coordinate shifts at or above the reported 0.57 and 0.52 units.
Figures


read the original abstract
We argue, with systematic empirical evidence, that a large language model's political ideology is not a fixed point, but a conditional distribution $\mathbb{P}($position$\mid$context$)$ over a real political space. We evaluate nine current LLMs using a unified measurement framework anchored by VAA-CHES projection models, which map responses onto three validated dimensions (lrgen, lrecon, galtan) across six contextual axes. Our findings reveal high sensitivity to context: persuasive framing and under-represented languages displace coordinates by up to 0.57 and 0.52 units, respectively, while chain-of-thought reasoning often amplifies rather than dampens paraphrase instability. Despite this local plasticity, the model cohort occupies a remarkably narrow Overton envelope overall, occupying roughly one-third the spread of major European parties. Supported by a multi-trait multi-method (MTMM) analysis, we conclude that a single point cannot summarize LLM political behavior; it must be characterized as a shape. Our code and data are publicly available at https://github.com/sakhadib/LLM-Ideoplasticity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM political ideology is not a fixed point but a conditional distribution P(position|context) over a real political space. Using a unified framework anchored in VAA-CHES projection models, it evaluates nine LLMs across six contextual axes and three dimensions (lrgen, lrecon, galtan), reporting context-induced displacements of up to 0.57 and 0.52 units, amplified paraphrase instability under chain-of-thought, and a narrow Overton envelope occupying roughly one-third the spread of major European parties. An MTMM analysis is presented to support measurement reliability, leading to the conclusion that LLM political behavior must be characterized as a shape rather than a single point. Code and data are made publicly available.
Significance. If the central measurement assumptions hold, the work supplies a systematic, reproducible framework for quantifying ideological plasticity in LLMs and demonstrates that context can produce substantial, measurable shifts while the overall cohort remains narrowly distributed. The public release of code and data is a clear strength that enables direct verification and extension.
major comments (1)
- [Methods (VAA-CHES projection)] Methods section (VAA-CHES projection application): the paper applies VAA-CHES models calibrated exclusively on human survey responses directly to LLM-generated text without any reported ablation, human-LLM alignment check, or domain-transfer validation. LLM outputs differ systematically from human language in fluency, hedging, and lexical distribution; if these differences distort or compress the projections, both the reported displacement magnitudes (0.57/0.52 units) and the narrow Overton envelope claim become unreliable. This assumption is load-bearing for every quantitative result and the 'shape vs point' conclusion.
minor comments (1)
- [Abstract] Abstract: the phrase 'systematic empirical evidence' could be strengthened by briefly stating the number of models (nine) and contextual axes (six) to give readers an immediate sense of scale.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying a key methodological assumption. We respond to the major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: Methods section (VAA-CHES projection application): the paper applies VAA-CHES models calibrated exclusively on human survey responses directly to LLM-generated text without any reported ablation, human-LLM alignment check, or domain-transfer validation. LLM outputs differ systematically from human language in fluency, hedging, and lexical distribution; if these differences distort or compress the projections, both the reported displacement magnitudes (0.57/0.52 units) and the narrow Overton envelope claim become unreliable. This assumption is load-bearing for every quantitative result and the 'shape vs point' conclusion.
Authors: We agree that the manuscript applies the VAA-CHES models, originally calibrated on human responses, to LLM-generated text without reporting dedicated ablation, human-LLM alignment, or domain-transfer validation studies. This constitutes a substantive and load-bearing assumption. The MTMM analysis provides evidence of internal measurement consistency across elicitation methods, but does not directly test cross-domain validity. We will revise the Methods and Limitations sections to explicitly discuss potential effects of linguistic differences on projection accuracy, the reported displacement magnitudes, and the Overton envelope width. We will also note that relative within-model displacements may remain informative under uniform projection bias, while absolute positioning claims require caution. Revision will be made. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical measurements
full rationale
The paper derives its central claim (LLM ideology as context-conditioned distribution rather than fixed point) from prompting nine LLMs across six contextual axes, obtaining responses, and projecting them onto lrgen/lrecon/galtan dimensions via pre-existing VAA-CHES models. The observed displacements (0.57/0.52 units), paraphrase instability, and narrow Overton envelope (~1/3 party spread) are reported outcomes of these measurements, not quantities fitted or defined in terms of themselves. No equations reduce a prediction to a fitted input by construction, no load-bearing self-citation chain is invoked, and the MTMM analysis is presented as supporting reliability of the method rather than substituting for external validation. The validity of VAA-CHES transfer to LLM text is an untested assumption (correctness risk), but does not create circularity in the reported derivation. Steps array left empty per rules for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The VAA-CHES projection models accurately map LLM responses onto the lrgen, lrecon, and galtan dimensions without systematic distortion from model-generated text.
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 24767– 24773, Suzhou, China
POW: Political overton windows of large language mod- els. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 24767– 24773, Suzhou, China. Association for Computa- tional Linguistics. Ryan Bakker, Seth Jolly, and Jonathan Polk
2025
-
[2]
InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 14272–14284, Torino, Italia
SaGE: Evaluating moral consistency in large language models. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 14272–14284, Torino, Italia. ELRA and ICCL. Tanise Ceron, Neele Falk, Ana Bari´c, Dmitry Nikolaev, and Sebastian Padó
2024
-
[3]
Junhyuk Choi, Sohhyung Park, Chanhee Cho, Hyeonchu Park, and Bugeun Kim
Uncovering political bias in large language models using parliamentary voting records.arXiv preprint arXiv:2601.08785. Junhyuk Choi, Sohhyung Park, Chanhee Cho, Hyeonchu Park, and Bugeun Kim
-
[4]
Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
Diag- nosing the reliability of llm-as-a-judge via item re- sponse theory.Preprint, arXiv:2602.00521. Mariella Faulborn, Dirk Hovy, and Indira Sen
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Shangbin Feng, Chan Young Park, Yuhan Liu, and Yu- lia Tsvetkov
A detailed factor analysis for the political compass test: Navigating ideologies of large language mod- els.arXiv preprint arXiv:2506.22493. Shangbin Feng, Chan Young Park, Yuhan Liu, and Yu- lia Tsvetkov
-
[6]
Sasuke Fujimoto and Kazuhiro Takemoto
Personas with attitudes: Controlling LLMs for diverse data annotation.arXiv preprint arXiv:2410.11745. Sasuke Fujimoto and Kazuhiro Takemoto
-
[7]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.Preprint, arXiv:2507.06261. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The political ideology of conversa- tional AI: Converging evidence on ChatGPT’s pro- environmental, left-libertarian orientation.arXiv preprint, arXiv:2301.01768. Seth Jolly, Ryan Bakker, Liesbet Hooghe, Gary Marks, Jonathan Polk, Jan Rovny, Marco Steenbergen, and Milada Anna Vachudova
-
[9]
Joseph G
Chapel Hill ex- pert survey trend file, 1999–2019.Electoral Studies, 75:102420. Joseph G. Lehman
1999
-
[10]
InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2006–2017, Mexico City, Mex- ico
Large language models sensitivity to the order of options in multiple-choice questions. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2006–2017, Mexico City, Mex- ico. Association for Computational Linguistics. Andres Reiljan, Frederico Ferreira da Silva, Lorenzo Cicchi, Diego Garzia, and Alexander H. Trech- sel
2024
-
[11]
Paul Röttger, Valentin Hofmann, Valentina Py- atkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, and Dirk Hovy
Longitudinal dataset of political issue- positions of 411 parties across 28 european coun- tries (2009–2019) from voting advice applications EU Profiler and euandi.Data in Brief, 31:105968. Paul Röttger, Valentin Hofmann, Valentina Py- atkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, and Dirk Hovy
2009
-
[12]
David Rozado
The 2024 Chapel Hill expert survey on political party position- ing in Europe: Twenty-five years of party positional data.Electoral Studies, 97:102981. David Rozado
2024
-
[13]
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, We- icheng Ma, and Soroush V osoughi
Political alignment in large language models: A multidimensional audit of psychome- tric identity and behavioral bias.arXiv preprint arXiv:2601.06194. Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, We- icheng Ma, and Soroush V osoughi
-
[14]
arXiv preprint arXiv:2406.07791 (2024)
Judging the judges: A systematic study of position bias in llm-as-a-judge.Preprint, arXiv:2406.07791. Frances Stewart
-
[15]
Let c0 denote the neutral baseline (C4) andC= {C1, C2, C3}the perturbed conditions
Expanded component-wise: d(u,v) = h (ulrgen −v lrgen)2 + (ulrecon −v lrecon)2 + (ugaltan −v galtan)2 i1/2 (2) A.1 Prompt Sensitivity Score (PSS) PSS quantifies the ideological displacement in- duced by alternative prompt framings. Let c0 denote the neutral baseline (C4) andC= {C1, C2, C3}the perturbed conditions. For modelm, statements, and conditionc∈ C:...
1996
-
[16]
The pipeline enforces a strict complete-case strategy, dropping observations with missing targets (lr- gen, lrecon, galtan)
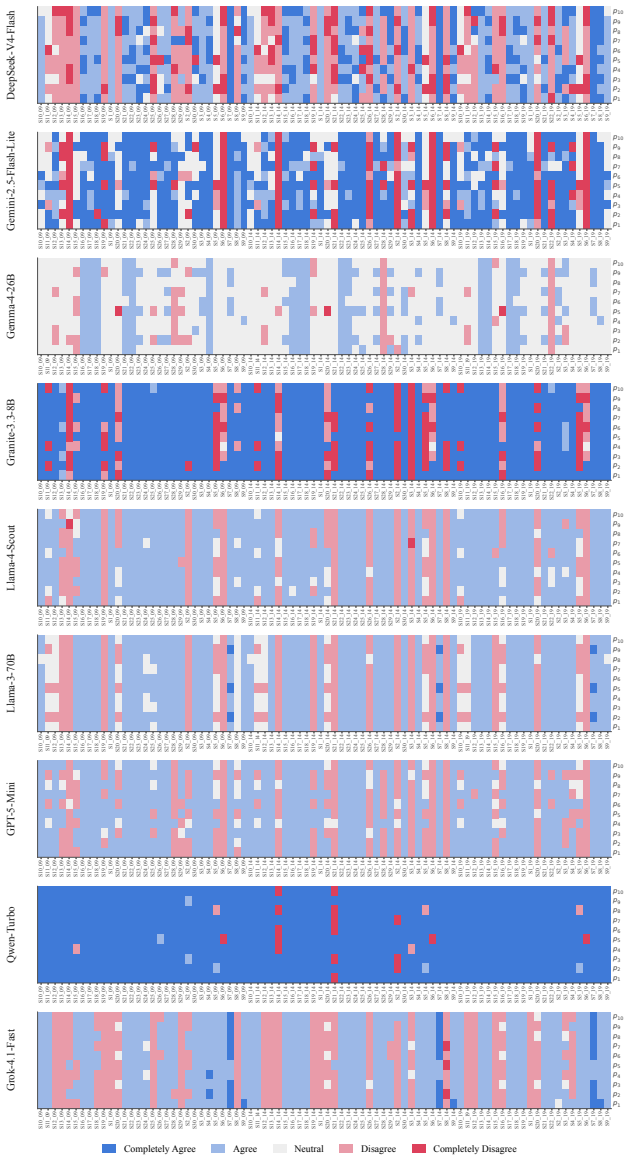
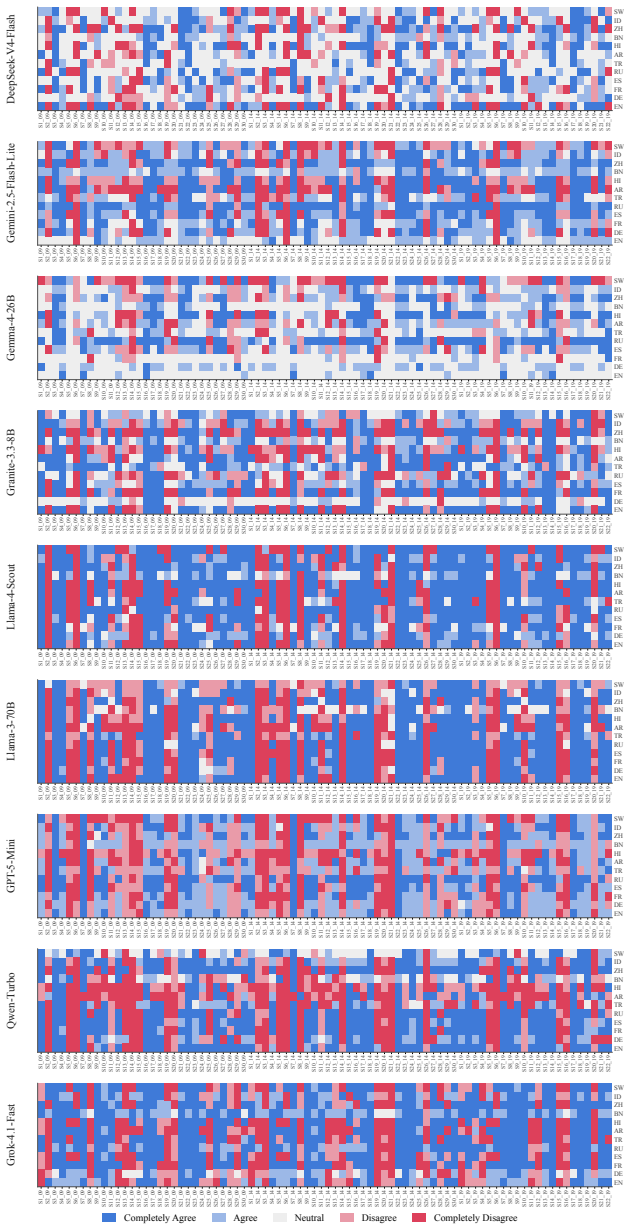
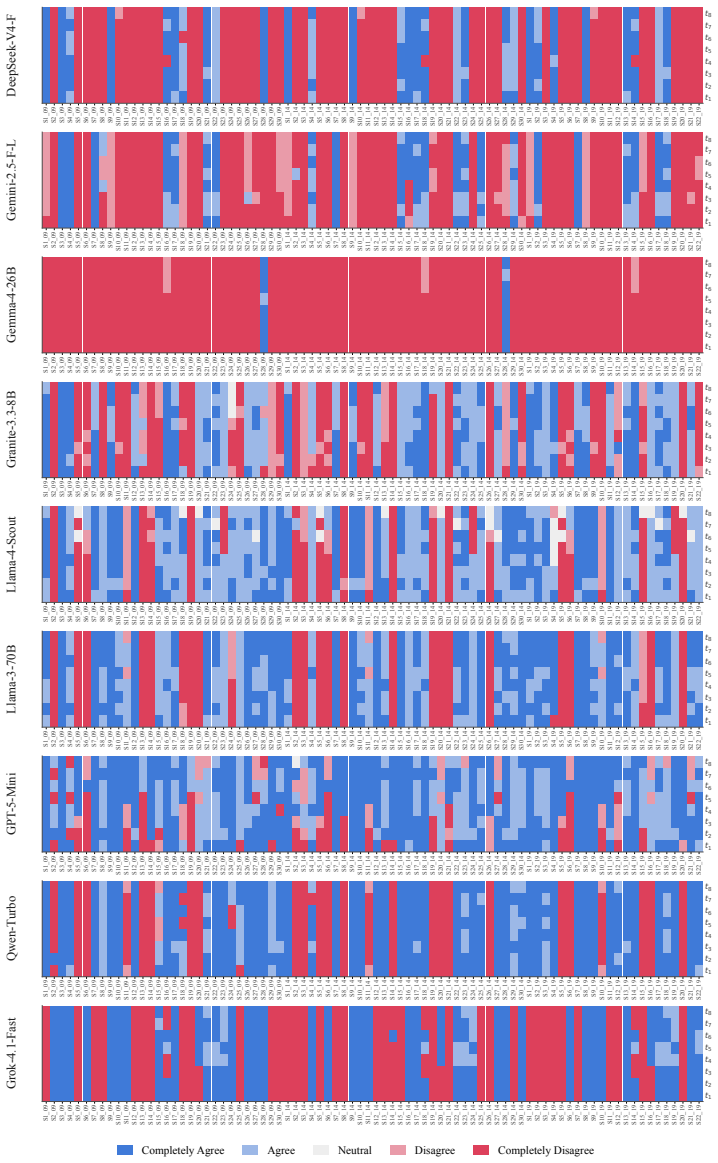
to preserve temporal variation in political issue salience. The pipeline enforces a strict complete-case strategy, dropping observations with missing targets (lr- gen, lrecon, galtan). After removing metadata (CHESS, YEAR) and the three targets, the effec- tive dimensions are: •2009:153parties,30features (from153× 35). •2014:141parties,30features (from141...
2009
-
[17]
Persua- sive Piece
Statistic 2D PSS 3D PSS Observed Displacement 0.5721 0.7272 95% CI Lower 0.5721 0.7272 95% CI Upper 0.5721 0.7272 Table 6: Non-parametric bootstrap (N= 10,000) con- fidence intervals for the maximum observed displace- ment (Gemma-4-26Bunder C1 in 2019). The zero- width intervals reflect strict within-condition determin- ism. The zero-width confidence inte...
2019
-
[18]
for”vs.“against
designates this as an exploratory fac- tor analysis rather than a confirmatory measure- ment model, the resulting eigendecomposition re- veals a highly structured and theoretically coher- ent latent topology. We extracted three princi- pal components (PCs) which together account for 83.30%of the total variance across the measure- ment framework. As detail...
2009
-
[19]
Each V AA round con- sists of approximately 22–30 policy statements to which respondents (and parties) express agree- ment on a five-point Likert scale, ranging from completely disagreetocompletely agree. To facilitate cross-year comparison and to make the thematic structure of the issue space transparent, we group statements into seven recurring policy d...
2009
-
[20]
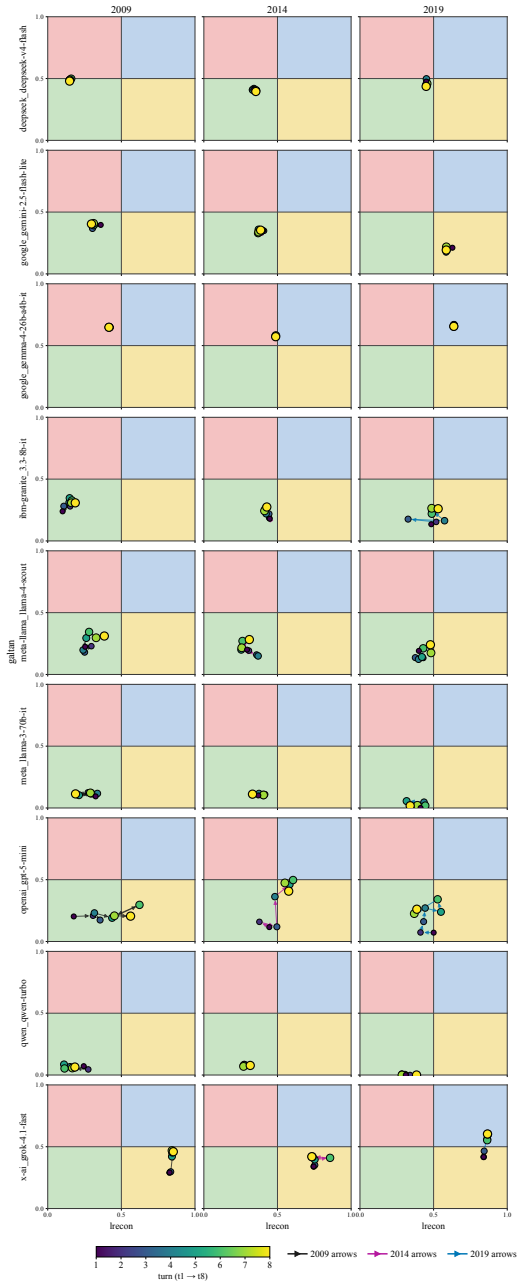
ideological trajectory of the corresponding model–year configuration. Marker color encodes the turn index along a viridis ramp (dark→bright), marker size grows monotonically with the turn, and arrows connect consecutive turns to reveal directional structure. Trajectory length, tortuosity, and net drift are visually distinct. 36 0.00 0.25 0.50 0.75 1.00gal...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.