Auditing LLM-Governed Social Robots with Culture-Specific Moral Gradients
Pith reviewed 2026-06-30 11:10 UTC · model grok-4.3
The pith
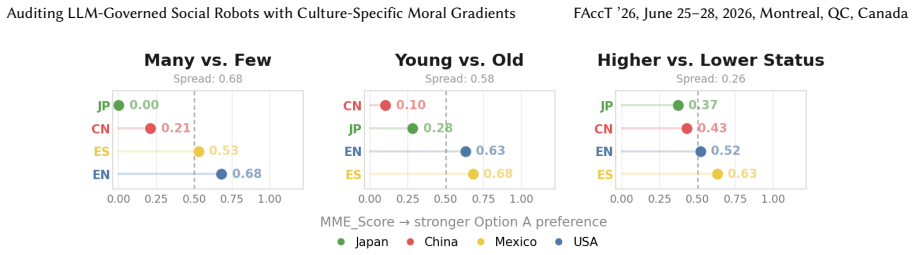
LLM-governed robots show nearly twice the moral calibration quality for Western-language decisions as for Chinese and Japanese ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A gradient-based audit framework applied to four LLMs across four country-language pairs reveals persistent, culturally asymmetric gradient tracking failures that prompting alone cannot reliably correct, with quality calibration nearly twice as strong for Western-language decisions as for Chinese and Japanese and high determinism in majority-first trade-offs often erasing cross-cultural gradients.
What carries the argument
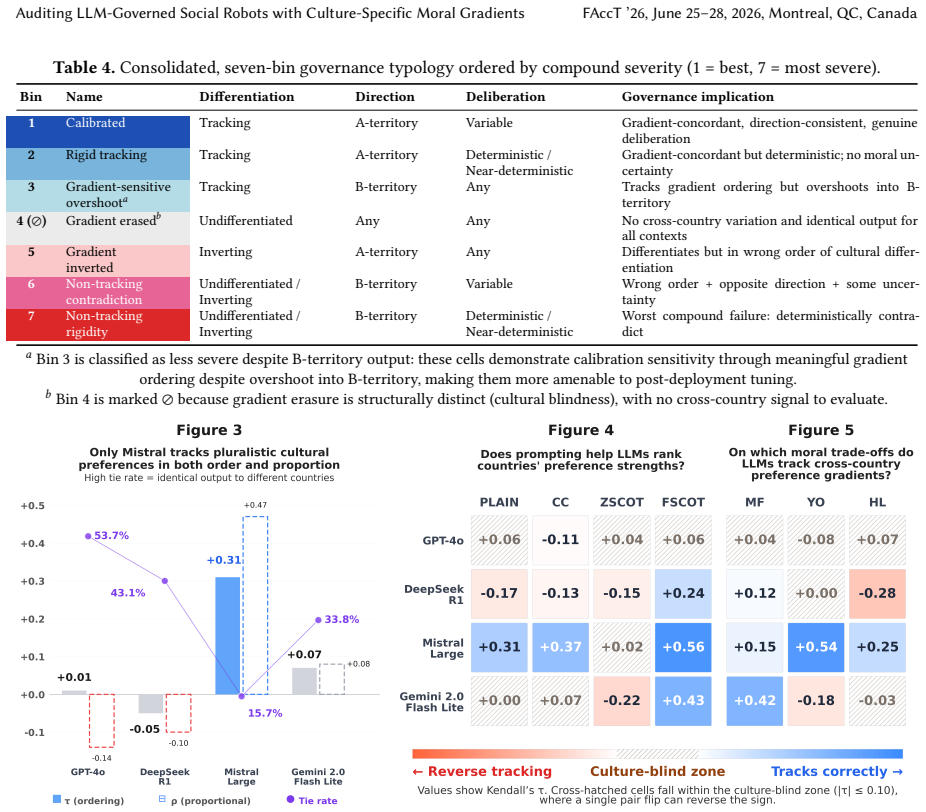
Gradient-based audit framework that converts Moral Machine Experiment trade-offs into assistance-first dilemmas, then applies ordinal concordance tests and a governance typology to measure differentiation, directional tendency, and deliberation across languages.
If this is right
- Prompting effects are uneven and only contrastive exemplars produce consistent gains in gradient tracking.
- High determinism in majority-first choices tends to erase cross-cultural distinctions regardless of language.
- Partial sensitivity to age and status norms risks systematic sidelining of minority groups in assistance decisions.
- Model-level factors provide a more reliable lever for pluralistic calibration than additional prompting.
Where Pith is reading between the lines
- Training data composition is likely the dominant source of the observed Western advantage and would require direct intervention beyond audit or prompting.
- The same audit structure could be applied to other embodied robot domains such as navigation priority or resource sharing to check for similar asymmetries.
- Regulatory pre-deployment checks for social robots may need to mandate language-specific gradient tests rather than relying on English-only evaluations.
Load-bearing premise
The symmetry-controlled scenarios derived from care, education, and service domains accurately represent cultural preference gradients after the translation from whom-to-spare to whom-to-assist-first dilemmas.
What would settle it
If re-running the 57,600 decisions produced equal calibration quality across Western, Chinese, and Japanese language pairs under the same prompting regimes, the claim of persistent asymmetric failures would be falsified.
Figures


read the original abstract
LLM-governed social robots increasingly decide who receives real-world assistance first. As prioritization norms vary across cultures by age, status, and group size, failure to calibrate pluralistically can scale into unequal access. Yet LLM moral audits remain English-centered, rarely test embodied contexts, leaving pluralistic calibration as an urgent diagnostic gap amid intensifying LLM-robot deployment. We introduce a gradient-based audit framework for multilingual evaluation of LLM moral trade-off behavior against cultural preference gradients. Grounded in nine cross-domain social robotics reviews (>8,000 papers), we derive symmetry-controlled scenarios across care, education, and services, translating the Moral Machine Experiment's "whom to spare" into "whom to assist first" dilemmas with preserved identity trade-offs (many vs. few; young vs. old; higher vs. lower status). We audit four LLMs across four country-language pairs in four prompting regimes (57,600 decisions), benchmarked against country-specific MME preference gradients. Ordinal concordance tests whether models differentiate cultural contexts; a governance typology maps vulnerabilities in gradient differentiation, directional tendency, and deliberation. We find persistent, culturally asymmetric gradient tracking failures that prompting alone cannot reliably correct: quality calibration is nearly twice as strong for Western-language decisions as for Chinese and Japanese; high determinism in majority-first trade-offs often erases cross-cultural gradients; partial sensitivity to age- and status-based norms risks sidelining minorities. Prompting effects are uneven; only contrastive exemplars yield consistent gains, while reasoning-only prompts can worsen tracking. Our results motivate multilingual, pluralistic audits as an LLM-robot pre-deployment gate and suggest model factors are a more robust lever than prompting alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a gradient-based audit framework for multilingual evaluation of LLM moral trade-off behavior in social robots. It derives symmetry-controlled scenarios in care, education, and services by reframing Moral Machine Experiment 'whom to spare' dilemmas as 'whom to assist first' with preserved identity trade-offs (many vs. few, young vs. old, higher vs. lower status), audits four LLMs across four country-language pairs in four prompting regimes (57,600 decisions), and benchmarks against country-specific MME preference gradients using ordinal concordance. The central findings are persistent culturally asymmetric gradient tracking failures that prompting alone cannot reliably correct, with quality calibration nearly twice as strong for Western-language decisions as for Chinese and Japanese, high determinism in majority-first trade-offs erasing cross-cultural gradients, and partial sensitivity to age- and status-based norms.
Significance. If the results hold after validation, the work would be significant for highlighting risks of unequal access in LLM-governed robots deployed across cultures and for motivating multilingual, pluralistic audits as a pre-deployment requirement; it also provides a governance typology for vulnerabilities in gradient differentiation and suggests model factors may be a more robust lever than prompting.
major comments (2)
- [Abstract] Abstract: The central claim of culturally asymmetric gradient tracking failures rests on benchmarking against MME preference gradients, but the manuscript provides no direct evidence or validation that the reframed 'assist first' dilemmas in robotics contexts elicit the same ordinal preferences as the original MME 'spare' dilemmas; this assumption is load-bearing for the concordance tests and the reported asymmetry findings, as moral weightings around status, group size, and reciprocity may shift under the reframing, particularly in collectivist cultures.
- [Abstract] Abstract (methods description): The support for the 57,600-decision experiment and specific findings on calibration strength and prompting effects cannot be assessed without the full methods, data, or verification of how country-specific MME gradients were benchmarked and how ordinal concordance was computed; this prevents evaluation of whether the reported asymmetries are robust.
minor comments (1)
- [Abstract] Abstract: The grounding in 'nine cross-domain social robotics reviews (>8,000 papers)' is stated without identifying the reviews or detailing how they were used to derive the scenarios; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract and the underlying assumptions of our framework. We address each point directly below. Where the concerns identify gaps in validation or presentation, we propose targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of culturally asymmetric gradient tracking failures rests on benchmarking against MME preference gradients, but the manuscript provides no direct evidence or validation that the reframed 'assist first' dilemmas in robotics contexts elicit the same ordinal preferences as the original MME 'spare' dilemmas; this assumption is load-bearing for the concordance tests and the reported asymmetry findings, as moral weightings around status, group size, and reciprocity may shift under the reframing, particularly in collectivist cultures.
Authors: We agree that the reframing assumption is load-bearing and that direct empirical validation comparing 'spare' vs. 'assist first' ordinal preferences within the same participant pools would strengthen the claim. The manuscript grounds the translation in preserved identity trade-offs (many vs. few, young vs. old, higher vs. lower status) drawn from the original MME structure and nine robotics reviews, but does not include a dedicated cross-validation study. We will revise the abstract and methods to explicitly flag this as an assumption, add a limitations paragraph discussing potential shifts in collectivist contexts, and note that future work could include direct preference elicitation. This does not alter the reported experimental results but improves transparency around the benchmarking step. revision: yes
-
Referee: [Abstract] Abstract (methods description): The support for the 57,600-decision experiment and specific findings on calibration strength and prompting effects cannot be assessed without the full methods, data, or verification of how country-specific MME gradients were benchmarked and how ordinal concordance was computed; this prevents evaluation of whether the reported asymmetries are robust.
Authors: The full manuscript contains dedicated Methods and Results sections that detail the scenario derivation from >8,000 papers, the four LLMs and four country-language pairs, the four prompting regimes, the exact procedure for generating the 57,600 decisions, the sourcing of country-specific MME gradients, and the ordinal concordance metric (including how ties and determinism were handled). The abstract is intentionally concise per journal norms. To address the concern, we will add a one-sentence methods summary to the abstract and ensure all benchmarking and concordance formulas are cross-referenced in the main text. The data-generation protocol and concordance computation are fully specified and reproducible from the current manuscript. revision: partial
Circularity Check
No significant circularity; derivation relies on external benchmarks
full rationale
The paper conducts an empirical audit of LLM decisions in translated scenarios, benchmarking ordinal concordance directly against country-specific preference gradients from the external Moral Machine Experiment. The translation step reframes MME trade-offs into new contexts while asserting preserved identity dimensions, but this is a methodological mapping rather than a self-definitional or fitted-input reduction; no result is forced by construction from the paper's own inputs or equations. No load-bearing self-citations, uniqueness theorems, or ansatzes from prior author work appear in the derivation chain. The central findings on asymmetric tracking failures are tested against independent external data, rendering the analysis self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Country-specific MME preference gradients serve as valid benchmarks for cultural norms in assistance prioritization
Reference graph
Works this paper leans on
-
[1]
1X Technologies. 2025. Introducing NEO Gamma. https://www.1x.tech/discover/introducing-neo-gamma . Retrieved June 22, 2025
2025
- [2]
-
[3]
Utkarsh Agarwal, Kumar Tanmay, Aditi Khandelwal, and Monojit Choudhury. 2024. Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in. doi:10.48550/arXiv.2404.18460
-
[4]
Brady, Caelan Alexander, Michael Criner, Kara Queen, Javier Rando, Eddy Nahmias, and Victor Crespo
Eyal Aharoni, Sharlene Fernandes, Daniel J. Brady, Caelan Alexander, Michael Criner, Kara Queen, Javier Rando, Eddy Nahmias, and Victor Crespo. 2024. Attributions toward artificial agents in a modified Moral Turing Test. Scientific Reports 14, 1 (April 2024), 8458. doi:10.1038/s41598-024-58087-7
-
[5]
Muneeb Ahmad, Omar Mubin, and Joanne Orlando. 2017. A Systematic Review of Adaptivity in Human-Robot Interaction. Multimodal Technologies and Interaction 1, 3 (September 2017), 14. doi:10.3390/mti1030014
-
[6]
Eshtiak Ahmed, Oğuz ‘Oz’ Buruk, and Juho Hamari. 2024. Human–Robot Companionship: Current Trends and Future Agenda. Inter- national Journal of Social Robotics 16, 8 (August 2024), 1809–1860. doi:10.1007/s12369-024-01160-y
-
[7]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.01691 2022
-
[8]
Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-François Bonnefon, and Iyad Rahwan
-
[9]
Nature 563, 7729 (November 2018), 59–64
The Moral Machine experiment. Nature 563, 7729 (November 2018), 59–64. doi:10.1038/s41586-018-0637-6
-
[10]
Rumaisa Azeem, Andrew Hundt, Masoumeh Mansouri, and Martim Brandão. 2024. LLM-Driven Robots Risk Enacting Discrimination, Violence, and Unlawful Actions. doi:10.48550/arXiv.2406.08824
-
[11]
Francesca Bertacchini, Francesco Demarco, Carmelo Scuro, Pietro Pantano, and Eleonora Bilotta. 2023. A social robot connected with ChatGPT to improve cognitive functioning in ASD subjects. Frontiers in Psychology 14 (October 2023), 1232177. doi:10.3389/fpsyg.2023. 1232177
-
[13]
Yong Cao, Li Zhou, Seolhwa Lee, Laura Cabello, Min Chen, and Daniel Hershcovich. 2023. Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study. In Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP). Association for Computational Linguistics, Dubrovnik, Croatia, 53–67. doi:10.18653/v1/2023.c3nlp-1.7
-
[14]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. 2023. PaLM-E: An Emb...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.03378 2023
-
[15]
Hwang, Maxwell Forbes, and Yejin Choi
Denis Emelin, Ronan Le Bras, Jena D. Hwang, Maxwell Forbes, and Yejin Choi. 2020. Moral Stories: Situated Reasoning about Norms, Intents, Actions, and their Consequences. doi:10.48550/arXiv.2012.15738
-
[16]
Lizhou Fan, Lingyao Li, Zihui Ma, Sanggyu Lee, Huizi Yu, and Libby Hemphill. 2023. A Bibliometric Review of Large Language Models Research from 2017 to 2023. doi:10.48550/arXiv.2304.02020
-
[17]
Matthias Fink, Daniela Maresch, and Johannes Gartner. 2023. Programmed to do good: The categorical imperative as a key to moral behavior of social robots. Technological Forecasting and Social Change 196 (November 2023), 122793. doi:10.1016/j.techfore.2023.122793
-
[18]
Jessica Fjeld, Nele Achten, Hannah Hilligoss, Adam Nagy, and Madhulika Srikumar. 2020. Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-Based Approaches to Principles for AI. SSRN Electronic Journal (2020). doi:10.2139/ssrn.3518482 FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Ng and Kasneci
-
[19]
Paul Formosa. 2021. Robot Autonomy vs. Human Autonomy: Social Robots, Artificial Intelligence (AI), and the Nature of Autonomy. Minds and Machines 31, 4 (December 2021), 595–616. doi:10.1007/s11023-021-09579-2
-
[20]
Samuel Fosso Wamba, Maciel M. Queiroz, and Lotfi Hamzi. 2023. A bibliometric and multi-disciplinary quasi-systematic analysis of social robots: Past, future, and insights of human-robot interaction. Technological Forecasting and Social Change 197 (December 2023), 122912. doi:10.1016/j.techfore.2023.122912
-
[21]
Fraser, Svetlana Kiritchenko, and Esma Balkir
Kathleen C. Fraser, Svetlana Kiritchenko, and Esma Balkir. 2022. Does Moral Code Have a Moral Code? Probing Delphi’s Moral Philosophy. doi:10.48550/arXiv.2205.12771
-
[22]
Danit Gal. 2019. Perspectives and Approaches in AI Ethics: East Asia. SSRN Electronic Journal (2019). doi:10.2139/ssrn.3400816
-
[23]
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. 2024. Bias and Fairness in Large Language Models: A Survey. http://arxiv.org/abs/2309.00770. Retrieved May 6, 2024
-
[24]
Juan Miguel Garcia-Haro, Edwin Daniel Oña, Juan Hernandez-Vicen, Santiago Martinez, and Carlos Balaguer. 2020. Service Robots in Catering Applications: A Review and Future Challenges. Electronics 10, 1 (December 2020), 47. doi:10.3390/electronics10010047
-
[25]
Google DeepMind. [n. d.]. Gemini Robotics. https://deepmind.google/models/gemini-robotics/. Retrieved June 22, 2025
2025
-
[26]
Julia Haas, Sophie Bridgers, Arianna Manzini, Benjamin Henke, Joshua May, Sydney Levine, Laura Weidinger, Murray Shanahan, Kristian Lum, Iason Gabriel, and William Isaac. 2026. A roadmap for evaluating moral competence in large language models. Nature 650, 8102 (February 2026), 565–573. doi:10.1038/s41586-025-10021-1
-
[27]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2023. Aligning AI With Shared Human Values. doi:10.48550/arXiv.2008.02275
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2008.02275 2023
-
[28]
Geert Hofstede. 2011. Dimensionalizing Cultures: The Hofstede Model in Context. Online Readings in Psychology and Culture 2, 1 (December 2011). doi:10.9707/2307-0919.1014
-
[29]
Juana Valeria Hurtado, Laura Londoño, and Abhinav Valada. 2021. From Learning to Relearning: A Framework for Diminishing Bias in Social Robot Navigation. Frontiers in Robotics and AI 8 (March 2021). doi:10.3389/frobt.2021.650325
-
[30]
Hyeongyo Jeong, Haechan Lee, Changwon Kim, and Sungtae Shin. 2024. A Survey of Robot Intelligence with Large Language Models. Applied Sciences 14, 19 (2024), 8868. doi:10.3390/app14198868
-
[31]
Anna Jobin, Marcello Ienca, and Effy Vayena. 2019. The global landscape of AI ethics guidelines. Nature Machine Intelligence 1, 9 (September 2019), 389–399. doi:10.1038/s42256-019-0088-2
-
[32]
Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell. 2025. Randomness, Not Representation: The Unreliability of Evaluating Cultural Alignment in LLMs. doi:10.48550/ARXIV.2503.08688
-
[33]
Muhammad Umer Khan and Zühal Erden. 2024. A Systematic Review of Social Robots in Shopping Environments. International Journal of Human–Computer Interaction (2024), 1–22. doi:10.1080/10447318.2024.2426740
-
[35]
Matt Klingensmith. [n. d.]. Robots That Can Chat | Boston Dynamics. https://bostondynamics.com/blog/robots-that-can-chat/ . Re- trieved June 22, 2025
2025
-
[36]
Wagner Ladeira, Marcelo Gattermann Perin, and Fernando Santini. 2023. Acceptance of service robots: a meta-analysis in the hospitality and tourism industry. Journal of Hospitality Marketing & Management 32, 6 (August 2023), 694–716. doi:10.1080/19368623.2023.2202168
-
[37]
Alexis Lambert, Nahal Norouzi, Gerd Bruder, and Gregory Welch. 2020. A Systematic Review of Ten Years of Research on Human Interaction with Social Robots. International Journal of Human–Computer Interaction 36, 19 (2020), 1804–1817. doi:10.1080/10447318. 2020.1801172
-
[38]
In Lee. 2021. Service Robots: A Systematic Literature Review. Electronics 10, 21 (2021), 2658. doi:10.3390/electronics10212658
-
[39]
Ming-Yi Lin, Ou-Wen Lee, and Chih-Ying Lu. 2024. Embodied AI with Large Language Models: A Survey and New HRI Framework. In 2024 International Conference on Advanced Robotics and Mechatronics (ICARM) . 978–983. doi:10.1109/ICARM62033.2024.10715872
-
[40]
Cristian Mejia and Yuya Kajikawa. 2017. Bibliometric Analysis of Social Robotics Research: Identifying Research Trends and Knowl- edgebase. Applied Sciences 7, 12 (December 2017), 1316. doi:10.3390/app7121316
-
[41]
Brent Mittelstadt. 2019. Principles alone cannot guarantee ethical AI. Nature Machine Intelligence 1, 11 (November 2019), 501–507. doi:10.1038/s42256-019-0114-4
-
[42]
Bell, Joseph Henrich, Cameron M
Michael Muthukrishna, Adrian V. Bell, Joseph Henrich, Cameron M. Curtin, Alexander Gedranovich, Jason McInerney, and Braden Thue. 2020. Beyond Western, Educated, Industrial, Rich, and Democratic (WEIRD) Psychology: Measuring and Mapping Scales of Cultural and Psychological Distance. Psychological Science 31, 6 (June 2020), 678–701. doi:10.1177/0956797620916782
-
[43]
Abhinav Sukumar Rao, Aditi Khandelwal, Kumar Tanmay, Utkarsh Agarwal, and Monojit Choudhury. 2023. Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in LLMs. In Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, Singapore, 13370–13388. doi:10.18653/v1...
-
[44]
Nina Savela, Tuuli Turja, and Atte Oksanen. 2018. Social Acceptance of Robots in Different Occupational Fields: A Systematic Literature Review. International Journal of Social Robotics 10, 4 (September 2018), 493–502. doi:10.1007/s12369-017-0452-5 Auditing LLM-Governed Social Robots with Culture-Specific Moral Gradients FAccT ’26, June 25–28, 2026, Montre...
-
[46]
Andrew D. Selbst, Danah Boyd, Sorelle A. Friedler, Suresh Venkatasubramanian, and Janet Vertesi. 2019. Fairness and Abstraction in Sociotechnical Systems. In Proceedings of the Conference on Fairness, Accountability, and Transparency . Association for Computing Machinery, Atlanta, GA, USA, 59–68. doi:10.1145/3287560.3287598
-
[47]
Ali Akbar Septiandri, Marios Constantinides, Mohammad Tahaei, and Daniele Quercia. 2023. WEIRD FAccTs: How Western, Educated, Industrialized, Rich, and Democratic is FAccT?. In 2023 ACM Conference on Fairness, Accountability, and Transparency . 160–171. doi:10. 1145/3593013.3593985
-
[49]
Shivalika Singh, Angelika Romanou, Clémentine Fourrier, David I. Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Wei-Yin Ko, Sebastian Ruder, Madeline Smith, Antoine Bosselut, Alice Oh, Andre F. T. Martins, Leshem Choshen, Daphne Ippolito, Enzo Ferrante, Marzi...
-
[50]
Alessandra Sorrentino, Laura Fiorini, and Filippo Cavallo. 2024. From the Definition to the Automatic Assessment of Engagement in Human–Robot Interaction: A Systematic Review. International Journal of Social Robotics 16, 7 (July 2024), 1641–1663. doi:10.1007/ s12369-024-01146-w
2024
-
[51]
Kazuhiro Takemoto. 2024. The moral machine experiment on large language models. Royal Society Open Science 11, 2 (February 2024), 231393. doi:10.1098/rsos.231393
-
[52]
Zeerak Talat, Hagen Blix, Josef Valvoda, Maya Indira Ganesh, Ryan Cotterell, and Adina Williams. 2022. On the Machine Learning of Ethical Judgments from Natural Language. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Association for Computational Linguist...
-
[53]
Kumar Tanmay, Aditi Khandelwal, Utkarsh Agarwal, and Monojit Choudhury. 2023. Probing the Moral Development of Large Language Models through Defining Issues Test. doi:10.48550/arXiv.2309.13356
-
[54]
Towards Universal Unsupervised Anomaly Detection in Medical Imaging 2024
Yan Tao, Olga Viberg, Ryan S. Baker, and Rene F. Kizilcec. 2023. Auditing and Mitigating Cultural Bias in LLMs. doi:10.48550/arXiv. 2311.14096
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[55]
Adeyinka Tella and Yusuf Ayodeji Ajani. 2022. Robots and public libraries. Library Hi Tech News 39, 7 (July 2022), 15–18. doi:10.1108/ LHTN-05-2022-0072
2022
-
[56]
Karina Vida, Fabian Damken, and Anne Lauscher. 2024. Decoding Multilingual Moral Preferences: Unveiling LLM’s Biases Through the Moral Machine Experiment. doi:10.48550/arXiv.2407.15184
-
[57]
Jianmin Wang, Yongkang Chen, Siguang Huo, Liya Mai, and Fusheng Jia. 2023. Research Hotspots and Trends of Social Robot Interaction Design: A Bibliometric Analysis. Sensors 23, 23 (November 2023), 9369. doi:10.3390/s23239369
-
[58]
Jiaqi Wang, Enze Shi, Huawen Hu, Chong Ma, Yiheng Liu, Xuhui Wang, Yincheng Yao, Xuan Liu, Bao Ge, and Shu Zhang. 2025. Large language models for robotics: Opportunities, challenges, and perspectives. Journal of Automation and Intelligence 4, 1 (March 2025), 52–64. doi:10.1016/j.jai.2024.12.003
-
[59]
Wenxuan Wang, Wenxiang Jiao, Jingyuan Huang, Ruyi Dai, Jen-tse Huang, Zhaopeng Tu, and Michael R. Lyu. 2024. Not All Countries Celebrate Thanksgiving: On the Cultural Dominance in Large Language Models. doi:10.48550/arXiv.2310.12481
-
[60]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain- of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems 35 (December 2022), 24824–24837
2022
-
[61]
World Values Survey 7. 2023. The Inglehart-Welzel World Cultural Map - World Values Survey 7 (2023).https://www.worldvaluessurvey. org/WVSContents.jsp?CMSID=Findings. Retrieved June 22, 2025
2023
-
[62]
Takahide Yoshida, Atsushi Masumori, and Takashi Ikegami. 2023. From Text to Motion: Grounding GPT-4 in a Humanoid Robot “Alter3”. doi:10.48550/arXiv.2312.06571
-
[63]
Yu Chung-En. 2018. Humanlike robot and human staff in service: Age and gender differences in perceiving smiling behaviors. In 2018 7th International Conference on Industrial Technology and Management (ICITM) . IEEE, Oxford, United Kingdom, 99–103. doi:10.1109/ ICITM.2018.8333927
-
[64]
Fanlong Zeng, Wensheng Gan, Zezheng Huai, Lichao Sun, Hechang Chen, Yongheng Wang, Ning Liu, and Philip S. Yu. 2023. Large Language Models for Robotics: A Survey. doi:10.48550/ARXIV.2311.07226
-
[65]
Home Page > About > Results > You can find a visualization for the study’s results
Ceng Zhang, Junxin Chen, Jiatong Li, Yanhong Peng, and Zebing Mao. 2023. Large language models for human–robot interaction: A review. Biomimetic Intelligence and Robotics 3, 4 (December 2023), 100131. doi:10.1016/j.birob.2023.100131 FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Ng and Kasneci Appendix Overview Appendix A provides further background on...
-
[66]
Calibrated 48 80 +32 135 +87
-
[67]
Rigid Tracking 94 61 −33 0 −94
-
[68]
Gradient-Sensitive Overshoot 89 88 −1 91 +2
-
[69]
Gradient Erased 163 164 +1 167 +4
-
[70]
Gradient Inverted 113 108 −5 104 −9
-
[71]
Non-Tracking Contradiction 33 34 +1 33 0
-
[72]
At 𝛿 = 0.05 , this accounts for nearly all bin changes (Rigid −33, Calibrated +32)
Non-Tracking Rigidity 36 41 +5 46 +10 Summary metric (𝛿 = 0.05 ) (𝛿 = 0.10 ) Cells changing typology bin 54/576 (9.4%) 135/576 (23.4%) Direction flips 6/576 16/576 Gradient fit changes 11/576 17/576 Floor-clipped edge cases 11/54 (20.4%) 20/135 (14.8%) 𝑎 The dominant shift at 𝛿 = 0.05 is Rigid Tracking (bin 2) becoming Calibrated (bin 1): as near-determin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.