GPTNT: Benchmarking Real-Time Collaboration Between Multimodal Agents on Keep Talking And Nobody Explodes
Pith reviewed 2026-06-30 01:11 UTC · model grok-4.3
The pith
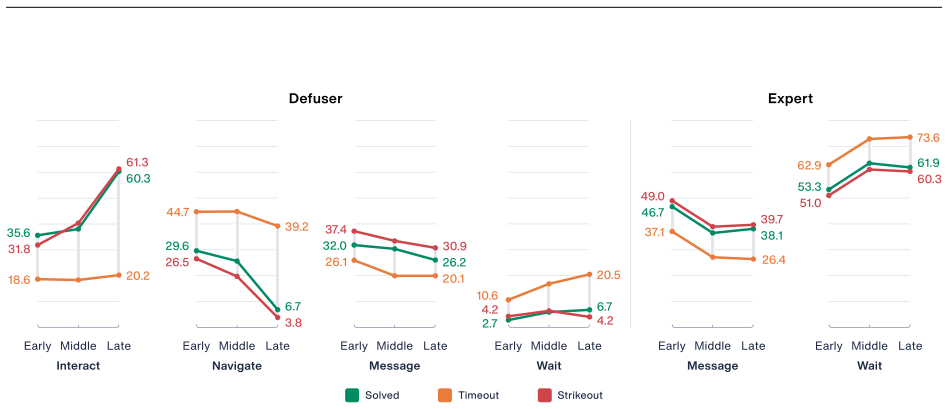
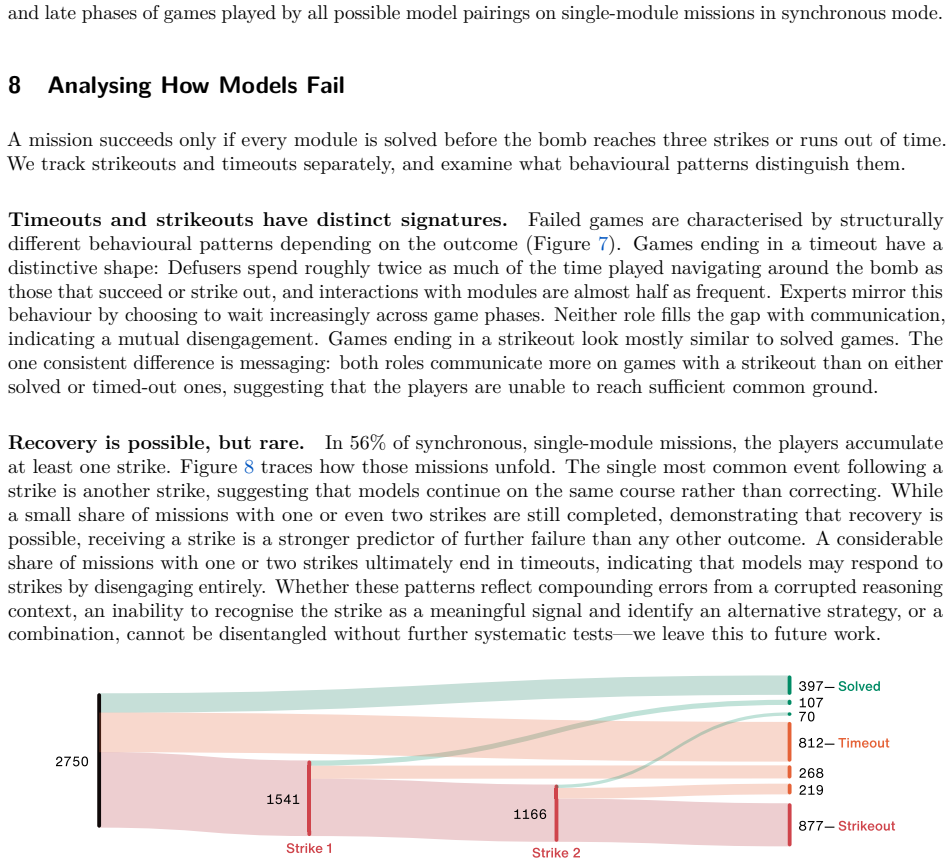
No tested multimodal models defuse even one bomb in real time under the benchmark conditions, while human players succeed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GPTNT requires two agents to coordinate asynchronously in real time to defuse procedurally generated bomb modules, with success depending on effective communication across information asymmetry. None of the tested models completes even a single defusal, a threshold human players meet, and controlled experiments trace the failures to specific weaknesses in maintaining shared state, acting efficiently under countdown pressure, resolving ambiguous messages, and recovering from mistakes.
What carries the argument
The GPTNT benchmark, which places agents in asymmetric roles within a live countdown game and withholds the manual or partner to isolate real-time collaboration from memorized knowledge.
If this is right
- Models exhibit specific shortfalls in state tracking and handling time pressure that prevent collaborative success.
- Error recovery and ambiguity resolution remain insufficient for tasks requiring ongoing coordination.
- The benchmark can continue to evolve through the game's procedural generation and modding community instead of becoming fixed and retired.
- Withholding conditions allow direct measurement of derivation versus recall in collaborative settings.
Where Pith is reading between the lines
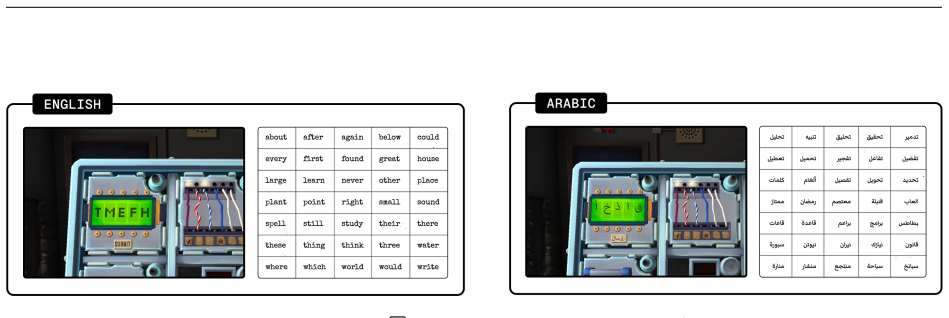
- Similar real-time asymmetry tests could be applied to other domains where agents must act without full shared information.
- Models that improve on GPTNT might transfer better to dynamic human-AI teaming scenarios than those tuned only on static benchmarks.
- The zero-success result suggests current training may under-emphasize efficient communication under strict time limits.
Load-bearing premise
The game setup with procedural generation and withholding conditions accurately isolates in-the-moment derivation and collaboration skills from memorized knowledge or other confounds.
What would settle it
A model that completes at least one procedurally generated bomb defusal in real time when either the instruction manual or the partner is withheld.
Figures









read the original abstract
Multimodal models are increasingly deployed to solve tasks collaboratively with humans or other artificial agents. Existing benchmarks show that these models possess many of the required component capabilities, but the conditions that coincide in collaboration, including time pressure, information asymmetry, and imperfect communication, are usually studied in isolation. We introduce GPTNT, a benchmark built on the cooperative video game Keep Talking and Nobody Explodes, in which two agents must coordinate to defuse procedurally generated bomb puzzles against a live countdown. One agent can see and manipulate the bomb but does not have the defusal instructions; the other has the instructions but cannot see or manipulate the bomb. Neither agent can succeed alone: success requires effective and efficient communication. Unlike turn-based proxies, GPTNT requires agents to act asynchronously and communicate in real time. GPTNT is designed to separate collaboration from reliance on memorized solutions: the instruction manual, the partner, or both can be withheld to isolate what a model derives in the moment from what it already knows. We show that GPTNT poses a substantial challenge for state-of-the-art systems: none of the closed- or open-source models we test defuses a single bomb in real time, a bar that human players clear. Through controlled experiments, we identify critical weaknesses in state tracking, efficient action under time pressure, ambiguity handling, and error recovery. We release GPTNT as a benchmark for collaborative performance that current evaluations leave unmeasured. Because it runs on the real game, GPTNT benefits from procedural generation and inherits a living modding community, allowing the benchmark to evolve as models improve rather than being solved once and retired.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GPTNT benchmark, built on the cooperative game Keep Talking and Nobody Explodes, to evaluate real-time multimodal agent collaboration under time pressure, information asymmetry, and imperfect communication. Two agents must coordinate asynchronously: one manipulates the bomb without instructions, the other holds the manual without visual access. The design includes withholding conditions (manual, partner, or both) plus procedural generation to isolate in-the-moment derivation and collaboration skills from memorized knowledge. The central empirical claim is that none of the tested closed- or open-source models defuse any bomb in real time (a bar humans clear), with controlled experiments identifying weaknesses in state tracking, efficient action under time pressure, ambiguity handling, and error recovery. The benchmark is released to evolve with the modding community.
Significance. If the isolation claim holds and the zero-success result is robust, GPTNT would provide a valuable, hard-to-game benchmark for collaborative capabilities that existing evaluations do not measure. Strengths include the use of a real game with procedural generation (preventing static solution memorization) and the potential for the benchmark to scale rather than be retired. The identification of concrete failure modes offers actionable directions, though the significance is tempered by the need to confirm that observed failures stem from the targeted skills rather than confounds.
major comments (2)
- [Abstract / Benchmark Design] Abstract and benchmark design: the claim that withholding the manual (or partner) isolates 'what a model derives in the moment from what it already knows' is load-bearing for attributing the zero-success result to deficits in state tracking, real-time action, and collaboration. Because the KTANE manual is a fixed public document, models whose pretraining includes wikis, rule PDFs, or transcripts could still apply correct procedures even when the text is withheld at runtime. Procedural generation randomizes module layouts and configurations but leaves rule semantics unchanged, so it does not block this pathway. Without additional controls (e.g., explicit tests of rule recall when the manual is absent), the headline result cannot be cleanly attributed to the intended skills.
- [Experimental Results] Experimental results section: the abstract reports that 'none of the closed- or open-source models we test defuses a single bomb in real time' yet supplies no information on the number of trials per condition, specific models and versions tested, success criteria, error bars, or statistical tests. This absence prevents verification that the zero-success rate is reliable rather than an artifact of small sample size or particular prompting setups.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline revisions to improve clarity and robustness of the claims.
read point-by-point responses
-
Referee: [Abstract / Benchmark Design] The claim that withholding the manual (or partner) isolates 'what a model derives in the moment from what it already knows' is load-bearing... Without additional controls (e.g., explicit tests of rule recall when the manual is absent), the headline result cannot be cleanly attributed to the intended skills.
Authors: We agree this is a valid concern: because the KTANE manual is a fixed public document, pretraining exposure could allow rule recall even under withholding. Procedural generation varies module instances but not core semantics. To strengthen the isolation claim, we will add a dedicated control experiment measuring rule recall accuracy when the manual is withheld at runtime (comparing against conditions where it is provided). This will be reported in a new subsection of the benchmark design and results, allowing clearer attribution of failures to state tracking and collaboration rather than memorized knowledge. revision: yes
-
Referee: [Experimental Results] the abstract reports that 'none of the closed- or open-source models we test defuses a single bomb in real time' yet supplies no information on the number of trials per condition, specific models and versions tested, success criteria, error bars, or statistical tests.
Authors: The full manuscript provides these details in the Experimental Results section (including trial counts, model versions, exact success criteria based on bomb defusal within the timer, and any applicable statistics). However, we acknowledge the abstract is too terse for standalone verification. We will revise the abstract to include a concise statement on the number of trials, models evaluated, and success definition. revision: yes
Circularity Check
No circularity; new benchmark evaluated empirically against external models
full rationale
The paper introduces GPTNT, a new benchmark built on an existing game, and reports an empirical observation that none of the tested closed- or open-source models succeed while humans do. No equations, parameter fits, self-definitional derivations, or load-bearing self-citations appear in the provided text. The withholding conditions and procedural generation are presented as design choices to isolate skills, but the result (model failure rates) does not reduce to those choices by construction or via any cited prior work by the authors. The evaluation relies on external models and is falsifiable outside the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Procedural generation of bomb puzzles combined with withholding conditions isolates what a model derives in the moment from memorized solutions.
Reference graph
Works this paper leans on
-
[1]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
doi:10.1145/3474666. Tamay Besiroglu, Sage Andrus Bergerson, Amelia Michael, Lennart Heim, Xueyun Luo, and Neil Thompson. The Compute Divide in Machine Learning: A Threat to Academic Contribution and Scrutiny?, January 2024. Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanc...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3474666 2024
-
[2]
Curran Associates Inc. Xiaofeng Gao, Qiaozi Gao, Ran Gong, Kaixiang Lin, Govind Thattai, and Gaurav S. Sukhatme. DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following.IEEE Robotics and Automation Letters, 7 (4):10049–10056, October 2022. ISSN 2377-3766. doi:10.1109/LRA.2022.3193254. Darren Gergle, Robert E. Kraut, and Susan R. Fussell. Lang...
-
[3]
doi:10.18653/v1/2022.acl-short.18
Association for Computational Linguistics. doi:10.18653/v1/2022.acl-short.18. Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Sh...
-
[4]
Dota 2 with Large Scale Deep Reinforcement Learning
ISSN 0028-0836, 1476-4687. doi:10.1038/nature14236. OpenAI. Computer-Using Agent, January 2025a. URLhttps://openai.com/index/computer-using-age nt/. OpenAI. Introducing GPT-5.2, December 2025b. URLhttps://openai.com/index/introducing-gpt-5 -2/. OpenAI. Function calling, April 2026. URLhttps://developers.openai.com/api/docs/guides/functi on-calling. OpenAI...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/nature14236 2026
-
[5]
ISSN 1469-8986. doi:10.1111/psyp.12171. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna M. Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards Understanding Sycophancy in...
-
[6]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
URLhttps://openreview.net/forum?id=dfeFy1PSSw. Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Parameters for Reasoning. InThe Thirteenth International Conference on Learning Representations, October 2024. URLhttps://openreview.net/forum?id=4FWAwZtd2n. Leonidas Spil...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1037/xlm0000535 2024
-
[7]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao
URL https://openaccess.thecvf.com/content/CVPR2026/html/Xu_VS-Bench_Evaluating_VL Ms_for_Strategic_Abilities_in_Multi-Agent_Environments_CVPR_2026_paper.html. Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, November 2023. 33 Shunyu Yao, Jeffrey Zhao, Dia...
-
[8]
Li et al
moves in a complementary direction by introducing natural environment dynamics—where the world evolves independently of what agents do—but does so in a single-agent setting, forfeiting the cooperative structure entirely. Li et al. (2024c) takes yet another path, trading visual grounding for richer interaction modelling and operating on text-based state re...
2024
-
[9]
automatically solved
and Werewolf (Wu et al., 2024) operationalise this best, with hidden roles creating a communicative pressure under which agents must reason strategically over what others know and believe. WhodunitBench (Xie et al., 2024a) extends this with visual grounding over evidential images, adding an absent multimodal layer to purely text-based deduction. But all t...
2024
-
[10]
Because the game is paused, observations are captured from a frozen, fully resolved game state
Observe.The Defuser pulls its observations and drains its message queue. Because the game is paused, observations are captured from a frozen, fully resolved game state
-
[11]
Unity’s internal time scale is set to zero during generation, so the model may take unbounded wall-clock time at no cost in game time
Generate.The Defuser produces a forward pass. Unity’s internal time scale is set to zero during generation, so the model may take unbounded wall-clock time at no cost in game time
-
[12]
The action executes and all resulting animations and state transitions resolve before the game is paused again
Act.The action is dispatched to the game, which is resumed for a window of at least3s of game time; in practice the realised window is3s to 3.5s (Appendix B.4.1). The action executes and all resulting animations and state transitions resolve before the game is paused again. The bomb clock therefore advances for each Defuser turn, regardless of the type of...
-
[13]
result": {
Expert turn.While the game is paused, the Expert pulls its message queue, produces a forward pass, and dispatches its action. Expert turns consume no game time. The cycle repeats until the game ends. Because each Defuser turn consumes3s, a mission’s time limit translates into a maximum number of Defuser turns—the time limit divided by three (Appendix B.4)...
2024
-
[14]
Therefore, the base conversational ability must not have been degraded by task-specific post-training
Conversational capability.Models must sustain coherent multi-turn dialogue across a full game, which can span dozens of turns per player. Therefore, the base conversational ability must not have been degraded by task-specific post-training
-
[15]
Interleaved multi-image multi-turn support.Models must handle sequences of images interleaved with text within a single conversation. The Defuser receives new visual observations on every turn, and the Expert receives the manual as a sequence of page images interleaved with extracted text across the first user turn. Architectures that support only single-...
-
[16]
This places a practical lower bound on usable context length, with InternVL representing the most constrained case at 40,060 tokens (Table E.1)
Context length.Models must be capable of holding the Expert’s manual and a sufficient dialogue history simultaneously within their context window. This places a practical lower bound on usable context length, with InternVL representing the most constrained case at 40,060 tokens (Table E.1)
-
[17]
Keep Talking and Nobody Explodes
No task-specific training.Models may not be fine-tuned on ktane, the game manual, or any task-derived data prior to their evaluation. Fine-tuning on the manual would trivialise the benchmark: a model capable of reciting module solutions from parametric memory is not performing the collaborative grounded reasoning the benchmark is designed to measure. Gene...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.