When More Sampling Hurts: The Modal Ceiling and Correlation Ceiling of Test-Time Scaling
Pith reviewed 2026-06-30 09:41 UTC · model grok-4.3
The pith
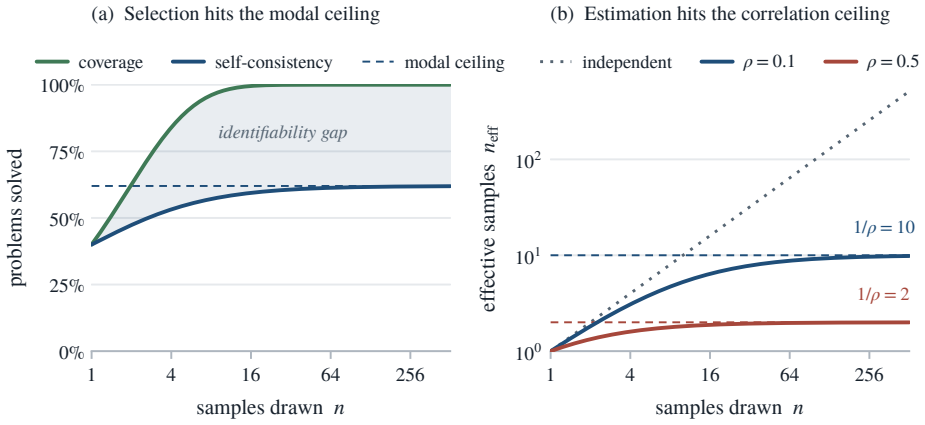
Language models hit a hard limit on selecting the right answer from samples after only a few dozen draws, even as more samples keep generating correct options.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
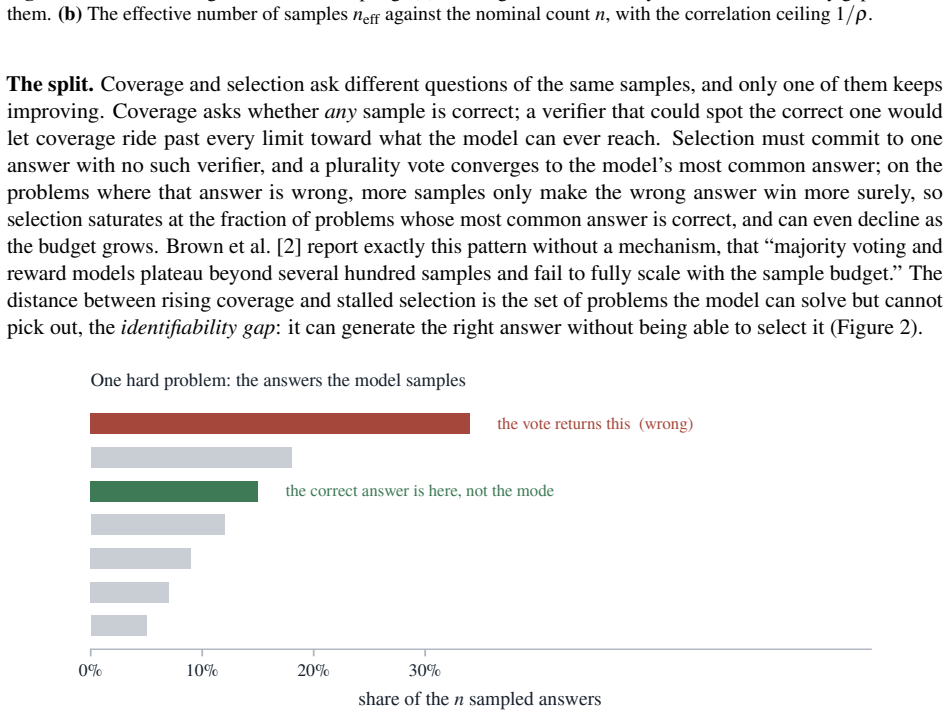
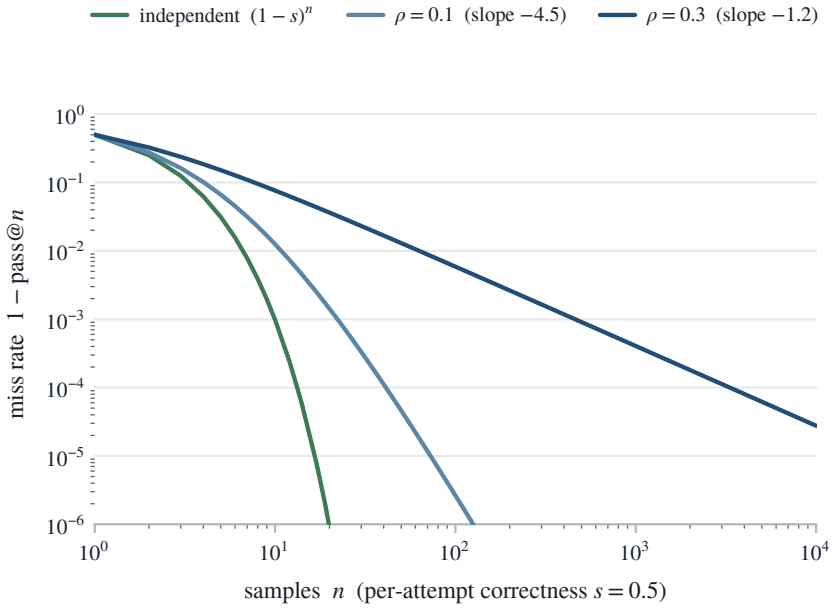
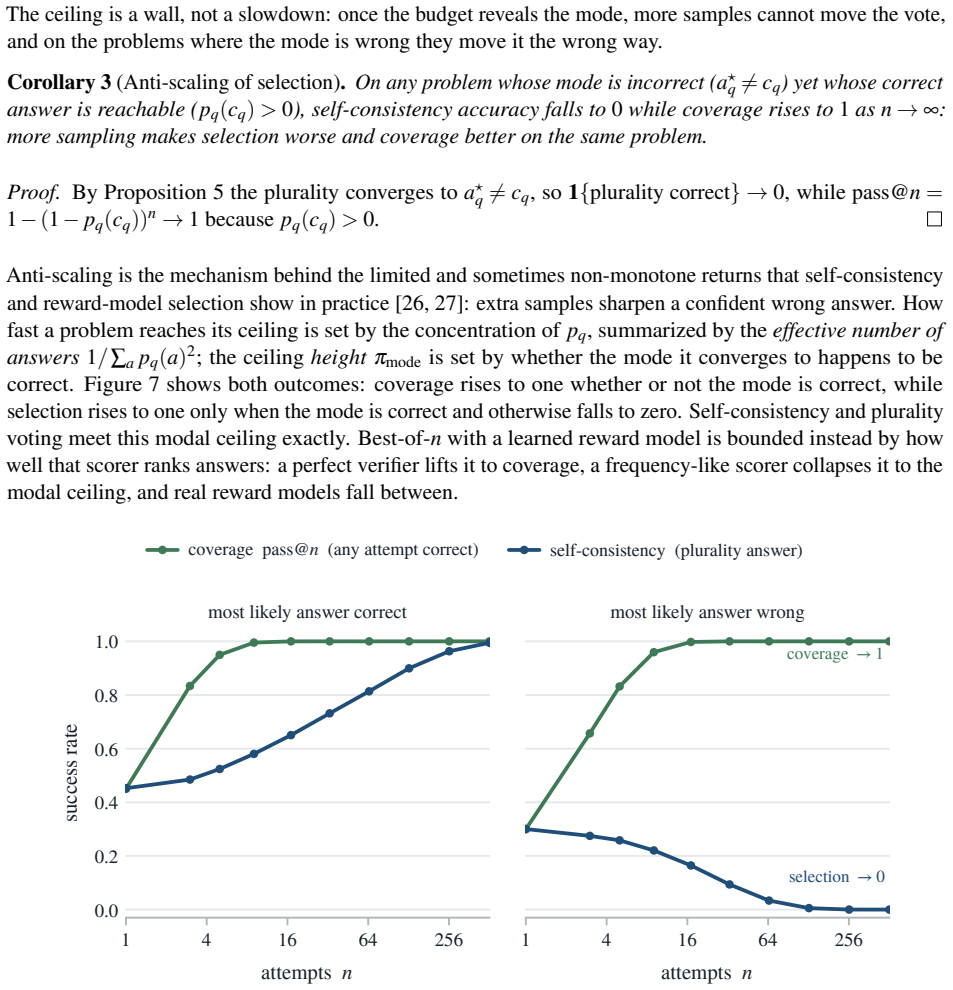
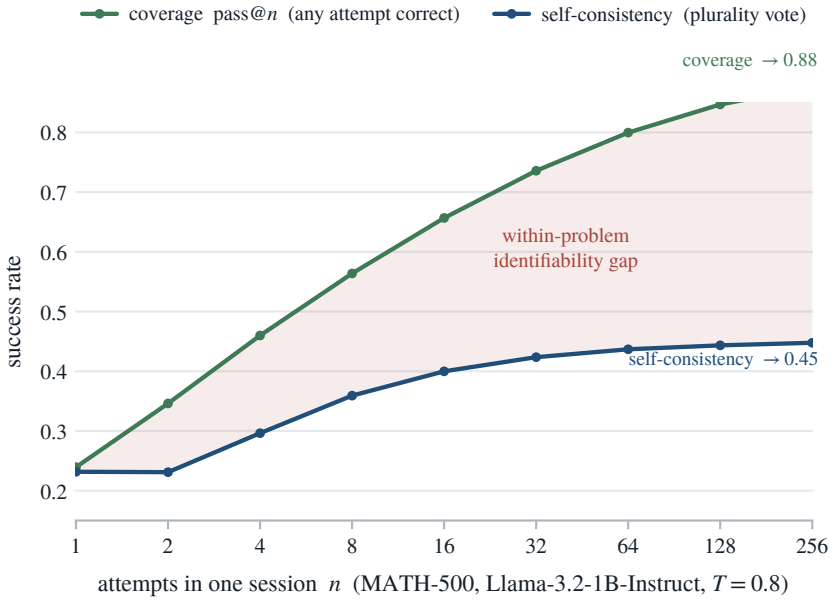
Coverage, the fraction of problems with at least one correct sample, continues to rise with more draws, but selection accuracy plateaus at the modal ceiling after a few dozen samples and benchmark correlation plateaus at the correlation ceiling even sooner; beyond these ceilings extra samples cost compute without improving the chosen answer and can make it worse by increasing certainty in an error.
What carries the argument
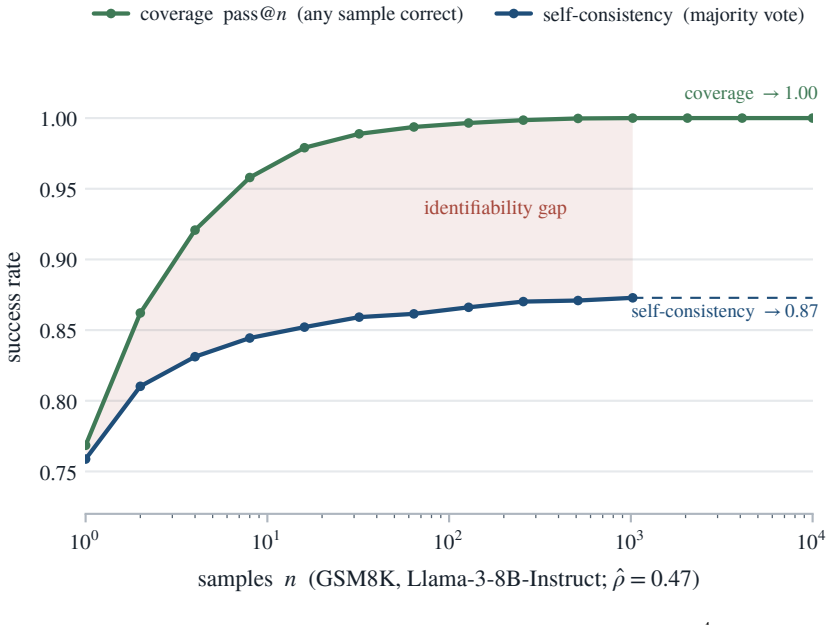
The identifiability gap between coverage and selection, together with the modal ceiling and correlation ceiling that mark where additional samples cease to help answer choice.
If this is right
- Deployed reasoning systems should cap sampling at roughly a few dozen draws to avoid wasted compute and possible accuracy loss.
- Benchmark scores obtained with hundreds of samples may overstate real selection performance because they sit past the correlation ceiling.
- The effective number of samples computed from any run already reveals when the ceilings have been reached.
- The bottleneck for test-time scaling is recognizing a right answer rather than generating one.
Where Pith is reading between the lines
- Systems that add verifiers or other signals could push the ceilings higher by closing the identifiability gap.
- The same sampling budget might be better spent on diverse prompts or model variants instead of repeated draws from one distribution.
- Benchmark protocols that report performance only at very high sample counts may need revision to reflect realistic selection limits.
Load-bearing premise
Answer selection is performed solely from the distribution of sampled outputs without external verifiers, additional context, or model-internal signals that could distinguish correct from incorrect candidates.
What would settle it
A controlled experiment showing that majority-vote or similar selection accuracy continues to rise meaningfully after several dozen samples on a fixed set of problems when no other signals are added.
Figures

read the original abstract
People overthink; language models over-sample, and the extra effort can talk both into a worse answer. Reasoning systems answer a hard question by sampling it many times (test-time scaling), and the more they draw, the more often a correct answer turns up somewhere, so coverage, the fraction of problems with at least one correct try, climbs and appears to be progress. But a deployed system must return one answer, and choosing it, not knowing which try is right, is selection; selection is capped, and past a point extra samples only make the model surer of a confident mistake, even as every draw adds cost. The gap between climbing coverage and stalled selection, the identifiability gap, is the answer a model can produce but not pick. So the real question is not whether to sample but how far, and the answer is: not far. For picking an answer, the vote has already settled within a few dozen draws, the modal ceiling; for scoring a benchmark, sooner still, the correlation ceiling. Beyond that, extra draws cost compute and add nothing, and can even make the answer worse. This paper turns the cutoff into a single number, the effective number of samples, that any sampling run already reveals. The bottleneck is recognizing a right answer, not generating one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that test-time scaling in language models increases coverage (fraction of problems with at least one correct sample) but selection of a single answer is limited by a modal ceiling reached within a few dozen draws and a correlation ceiling reached even sooner; beyond these points extra samples add cost without benefit and can degrade the selected answer due to the identifiability gap. It introduces a single scalar, the effective number of samples, that is revealed by any sampling run and determines the practical cutoff for both answer picking and benchmark scoring.
Significance. If the empirical ceilings and the effective-number construction hold under the stated selection regime, the result would directly affect compute allocation in deployed reasoning systems by showing that over-sampling is often counterproductive. The work supplies a falsifiable, run-time measurable quantity rather than an abstract scaling law, which strengthens its practical value if the supporting experiments are reproducible.
major comments (2)
- [Abstract] Abstract (paragraph on selection vs. coverage): the central claim that selection is capped by the modal ceiling and that extra samples can make the model surer of a confident mistake rests on the assumption that answer selection uses only the empirical frequency distribution of samples, with no access to external verifiers, consistency checks, or model-internal signals. This assumption is load-bearing for the identifiability gap; if any ranking or verification signal is available, the effective ceiling shifts and the effective-number-of-samples derivation must be re-worked to account for the enlarged candidate pool.
- [Abstract] The manuscript states that the effective number of samples is a single number revealed by any sampling run, yet the abstract provides no equation or algorithmic definition. If this quantity is computed from the observed mode or vote distribution, the paper must show (in the methods or appendix) that it is independent of additional fitted parameters; otherwise the claim that it is directly observable is weakened.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the models, benchmarks, and exact sample counts used to locate the modal and correlation ceilings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We respond to each point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on selection vs. coverage): the central claim that selection is capped by the modal ceiling and that extra samples can make the model surer of a confident mistake rests on the assumption that answer selection uses only the empirical frequency distribution of samples, with no access to external verifiers, consistency checks, or model-internal signals. This assumption is load-bearing for the identifiability gap; if any ranking or verification signal is available, the effective ceiling shifts and the effective-number-of-samples derivation must be re-worked to account for the enlarged candidate pool.
Authors: The manuscript's claims on the modal and correlation ceilings, as well as the identifiability gap, are derived under the explicit regime of frequency-based selection (majority vote or mode selection) with no external verifiers or additional signals. This is the standard test-time scaling setting analyzed in the introduction and methods. We agree that the presence of verifiers would alter the ceilings and require a different derivation; our work does not claim to cover that case. We will revise the abstract to state the selection regime more explicitly. revision: yes
-
Referee: [Abstract] The manuscript states that the effective number of samples is a single number revealed by any sampling run, yet the abstract provides no equation or algorithmic definition. If this quantity is computed from the observed mode or vote distribution, the paper must show (in the methods or appendix) that it is independent of additional fitted parameters; otherwise the claim that it is directly observable is weakened.
Authors: Section 3 defines the effective number of samples directly from the empirical vote distribution (as a function of the observed mode frequency and sample counts) with no fitted parameters or external model. This makes it observable from any sampling run alone. The methods already establish this independence; we will add an explicit sentence in the methods confirming the absence of fitted parameters and will consider a brief clarifying phrase in the abstract. revision: partial
Circularity Check
No circularity; derivation self-contained
full rationale
The abstract and provided context introduce the modal ceiling, correlation ceiling, and effective number of samples as conceptual constructs based on sampling behavior and selection limits, without any equations, fitted parameters, or self-citations that reduce the central claims to their own inputs by construction. No load-bearing steps match the enumerated patterns of self-definition, fitted-input prediction, or ansatz smuggling. The paper's claims rest on the stated assumption about selection from sample distribution alone, which is an external modeling choice rather than a circular reduction. This is the normal case of a self-contained empirical argument against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
GRPO, Dr. GRPO, and DAPO Are Three Operations on One Number: The Group-Standard-Deviation Identity
GRPO, Dr. GRPO, and DAPO are three settings of one dial on the group standard deviation of binary rewards, unified by the group-standard-deviation identity where disagreement equals update magnitude.
Reference graph
Works this paper leans on
-
[1]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR), 2023. arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. arXiv:2407.21787
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters, 2024. arXiv:2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models, 2024. arXiv:2408.00724
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
OpenAI. Openai o1 system card, 2024. arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning,
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning,
-
[7]
s1: Simple test-time scaling,
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling,
-
[8]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muennighoff, Irwin King, Xue Liu, and Chen Ma. A survey on test-time scaling in large language models: What, how, where, and how well?, 2025. arXiv:2503.24235
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021. arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
John Wiley & Sons, New York, 1965
Leslie Kish.Survey Sampling. John Wiley & Sons, New York, 1965
1965
-
[11]
Cochran.Sampling Techniques
William G. Cochran.Sampling Techniques. John Wiley & Sons, New York, 3rd edition, 1977. 20
1977
-
[12]
Krishna K. Ladha. The Condorcet jury theorem, free speech, and correlated votes.American Journal of Political Science, 36(3):617–634, 1992
1992
-
[13]
Philip J. Boland. Majority systems and the Condorcet jury theorem.Journal of the Royal Statistical Society: Series D (The Statistician), 38(3):181–189, 1989
1989
-
[14]
Nine judges, two effective votes: Correlated errors undermine LLM evaluation panels,
Guneet Kohli. Nine judges, two effective votes: Correlated errors undermine LLM evaluation panels,
-
[15]
Chandra, Ponnurangam Kumaraguru, Douwe Kiela, Ameya Prabhu, Matthias Bethge, and Jonas Geiping
Shashwat Goel, Joschka Strüber, Ilze Amanda Auzina, Karuna K. Chandra, Ponnurangam Kumaraguru, Douwe Kiela, Ameya Prabhu, Matthias Bethge, and Jonas Geiping. Great models think alike and this undermines AI oversight, 2025. arXiv:2502.04313
-
[16]
Model capability dominates: Inference-time optimization lessons from AIMO 3,
Natapong Nitarach. Model capability dominates: Inference-time optimization lessons from AIMO 3,
-
[17]
arXiv preprint arXiv:2502.17578 , year=
Rylan Schaeffer, Joshua Kazdan, John Hughes, Jordan Juravsky, Sara Price, Aengus Lynch, Erik Jones, Robert Kirk, Azalia Mirhoseini, and Sanmi Koyejo. How do large language monkeys get their power (laws)?, 2025. arXiv:2502.17578
-
[18]
Efficient prediction of pass@k scaling in large language models, 2025
Joshua Kazdan, Rylan Schaeffer, Youssef Allouah, Colin Sullivan, Kyssen Yu, Noam Levi, and Sanmi Koyejo. Efficient prediction of pass@k scaling in large language models, 2025. arXiv:2510.05197
-
[19]
A simple model of inference scaling laws, 2024
Noam Levi. A simple model of inference scaling laws, 2024. arXiv:2410.16377
-
[20]
Scaling test-time compute with open mod- els
Edward Beeching, Lewis Tunstall, and Sasha Rush. Scaling test-time compute with open mod- els. Hugging Face blog, 2024. https://huggingface.co/spaces/HuggingFaceH4/ blogpost-scaling-test-time-compute
2024
-
[21]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
La prévision: ses lois logiques, ses sources subjectives.Annales de l’Institut Henri Poincaré, 7(1):1–68, 1937
Bruno de Finetti. La prévision: ses lois logiques, ses sources subjectives.Annales de l’Institut Henri Poincaré, 7(1):1–68, 1937
1937
-
[23]
Yong Yi Bay and Kathleen A. Yearick. No 3D matrices: A unified tensor-product view of matrix-free Cartesian PDE solvers, 2026. arXiv:2606.25148
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
J. G. Skellam. A probability distribution derived from the binomial distribution by regarding the probability of success as variable between the sets of trials.Journal of the Royal Statistical Society: Series B, 10(2):257–261, 1948
1948
- [25]
-
[26]
Are more LLM calls all you need? towards scaling laws of compound inference systems, 2024
Lingjiao Chen, Jared Quincy Davis, Boris Hanin, Peter Bailis, Ion Stoica, Matei Zaharia, and James Zou. Are more LLM calls all you need? towards scaling laws of compound inference systems, 2024. arXiv:2403.02419
-
[27]
On the effect of sampling diversity in scaling LLM inference, 2025
Tianchun Wang, Zichuan Liu, Yuanzhou Chen, Jonathan Light, Weiyang Liu, Haifeng Chen, Xi- ang Zhang, and Wei Cheng. On the effect of sampling diversity in scaling LLM inference, 2025. arXiv:2502.11027. 21
-
[28]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAd- vances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021. arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Understanding the Effects of RLHF on LLM Generalisation and Diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefen- stette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2310.06452
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text de- generation. InInternational Conference on Learning Representations (ICLR), 2020. arXiv:1904.09751
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[31]
arXiv preprint arXiv:2502.06703 , year =
Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, and Bowen Zhou. Can 1B LLM surpass 405B LLM? rethinking compute-optimal test-time scaling, 2025. arXiv:2502.06703
-
[32]
Yong Yi Bay and Kathleen A. Yearick. Solve for the hyperparameter, skip the search: Kolmogorov- optimal scaling laws for spline regression.arXiv preprint arXiv:2606.23575, 2026. 22 Appendix A: Elementary derivations The body states the propositions and leans on these short calculations without pausing for them; each one underwrites a result above. Beta-bi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Because θ> 1 2 pushes every rival answer under 1 2, hence under the correct one, this majority bound never exceedsπ mode
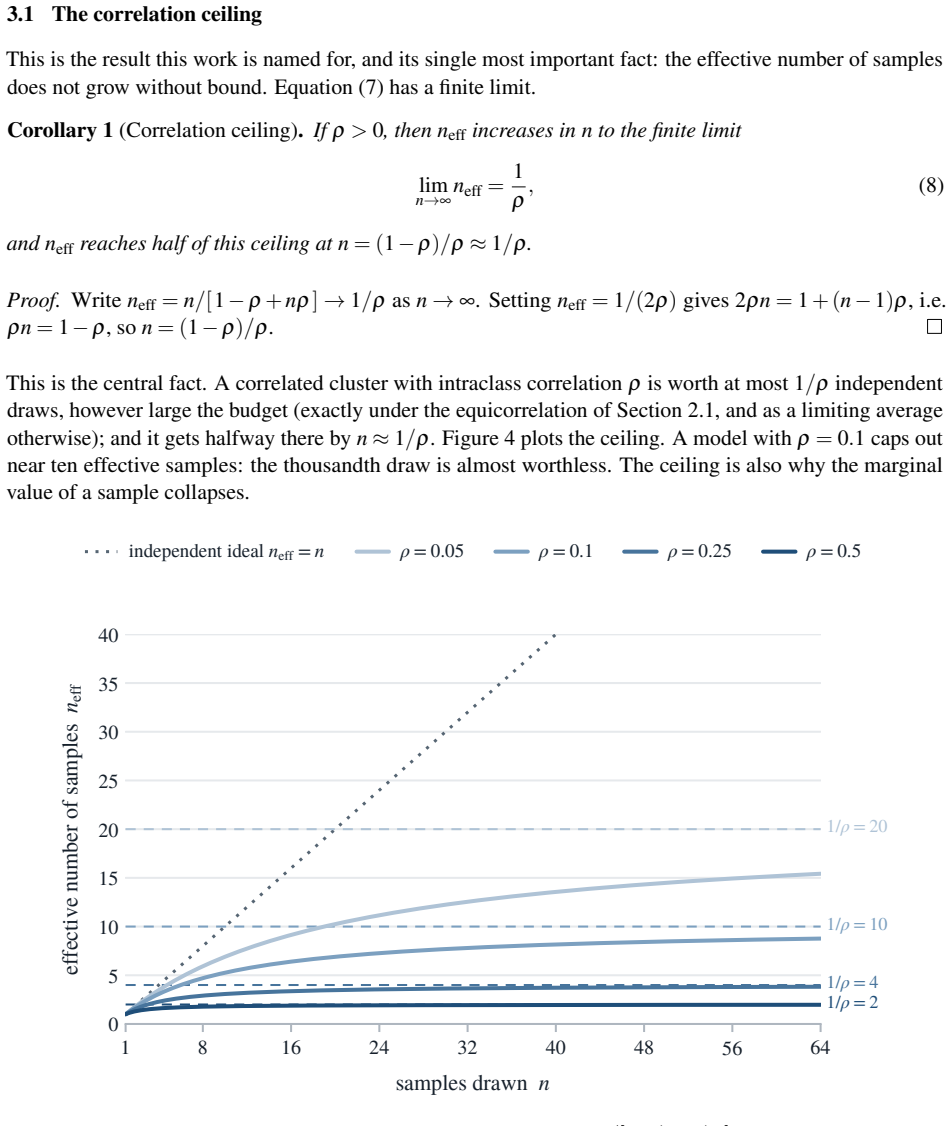
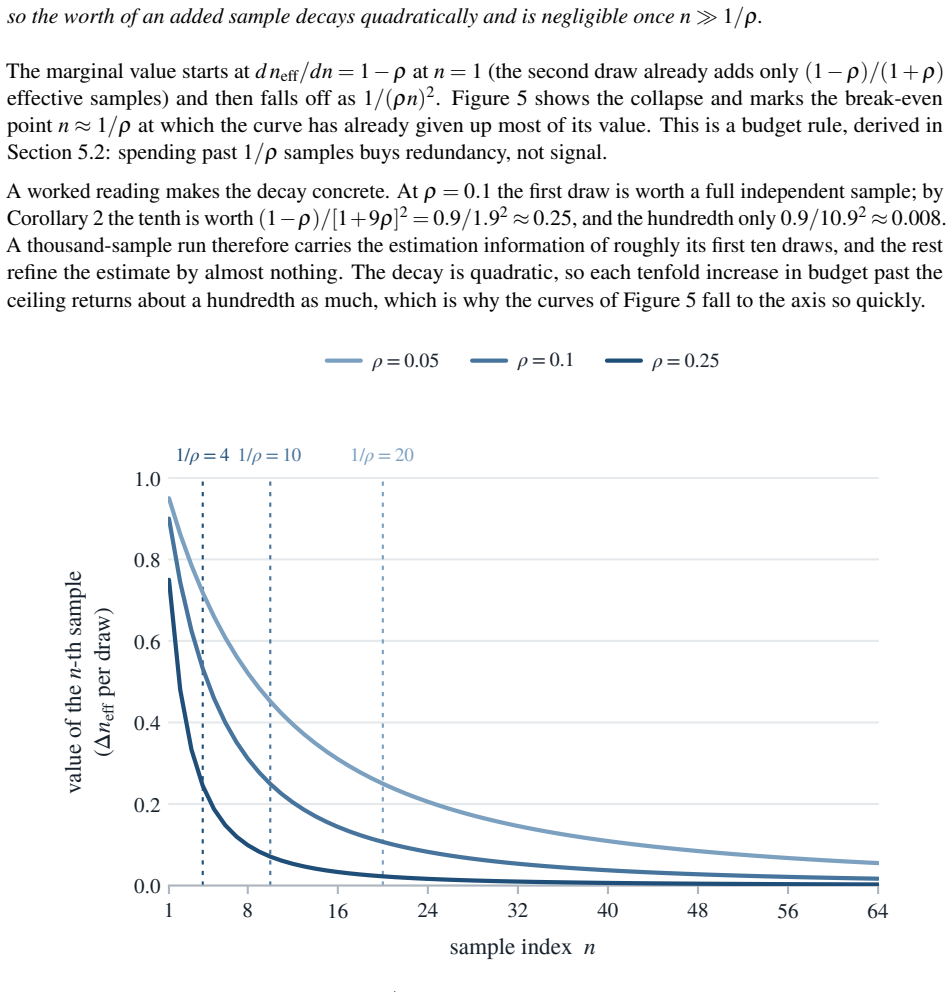
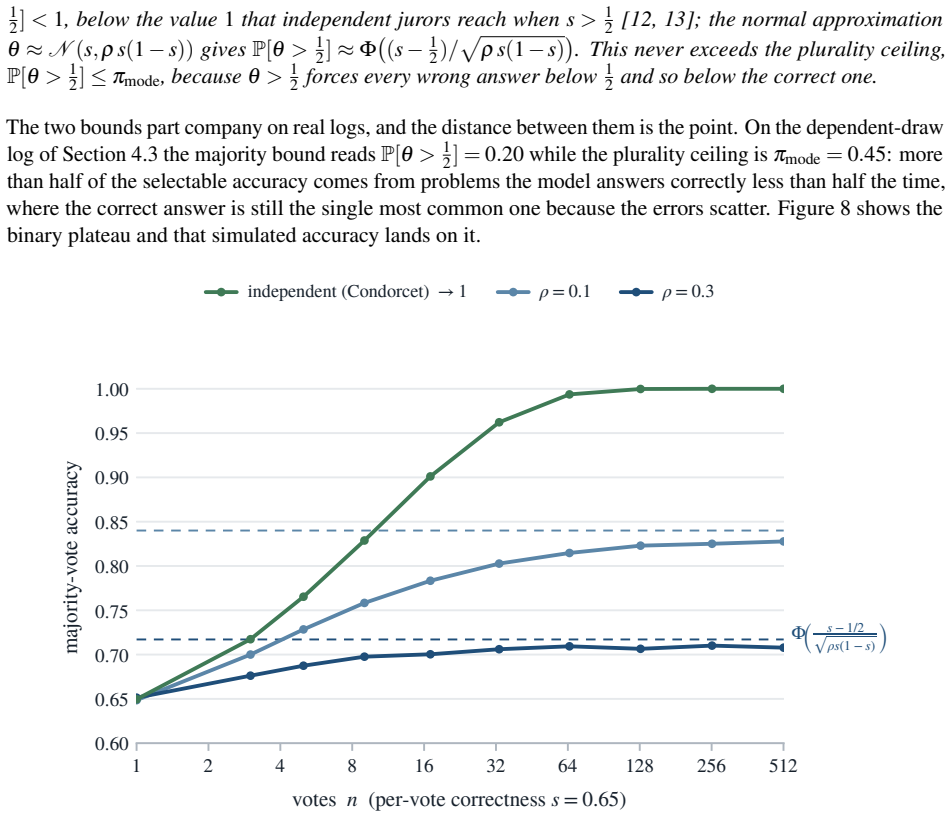
Its variance tends to Var(ˆp)→ρs(1−s) , and approximating θ as N s,ρs(1−s) gives the closed form P[θ> 1 2 ]≈Φ s− 1 2p ρs(1−s) ! of Corollary 4. Because θ> 1 2 pushes every rival answer under 1 2, hence under the correct one, this majority bound never exceedsπ mode. 23 Two-stage design effect.Pool attempts over problems, and let µi be the success rate of p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.