Capability Gates Are Not Authorization: Confused-Deputy Failures in LLM Agent Frameworks
Pith reviewed 2026-06-30 10:10 UTC · model grok-4.3
The pith
LLM agent frameworks gate tool access by default but do not re-authorize each call's concrete argument values before execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
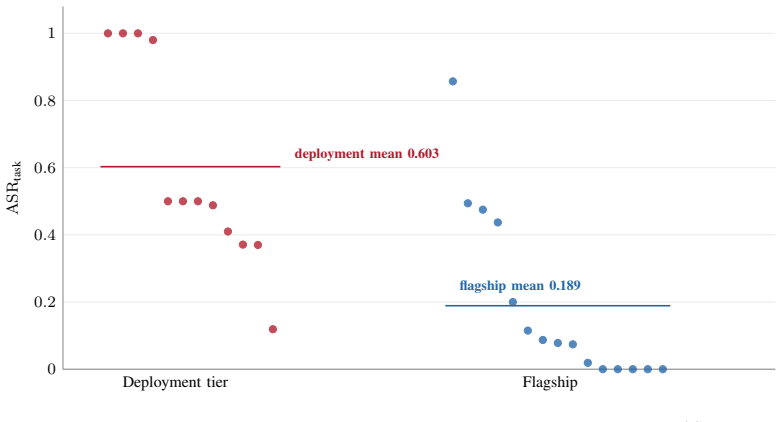
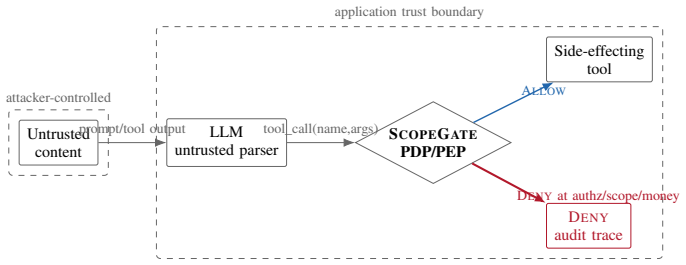
Across pinned public-source commits, all three frameworks provide capability gating by default, but none provides a deterministic fail-closed per-call value authorization gate by default. An identical unauthorized payout call executes under LangChain's default dispatch and a LlamaIndex proof-of-concept, yet is denied by ScopeGate, which reports zero static bypasses, zero unauthorized attempts over an adaptive run, zero benign false-denies, and full containment on the tested payment-agent scenario.
What carries the argument
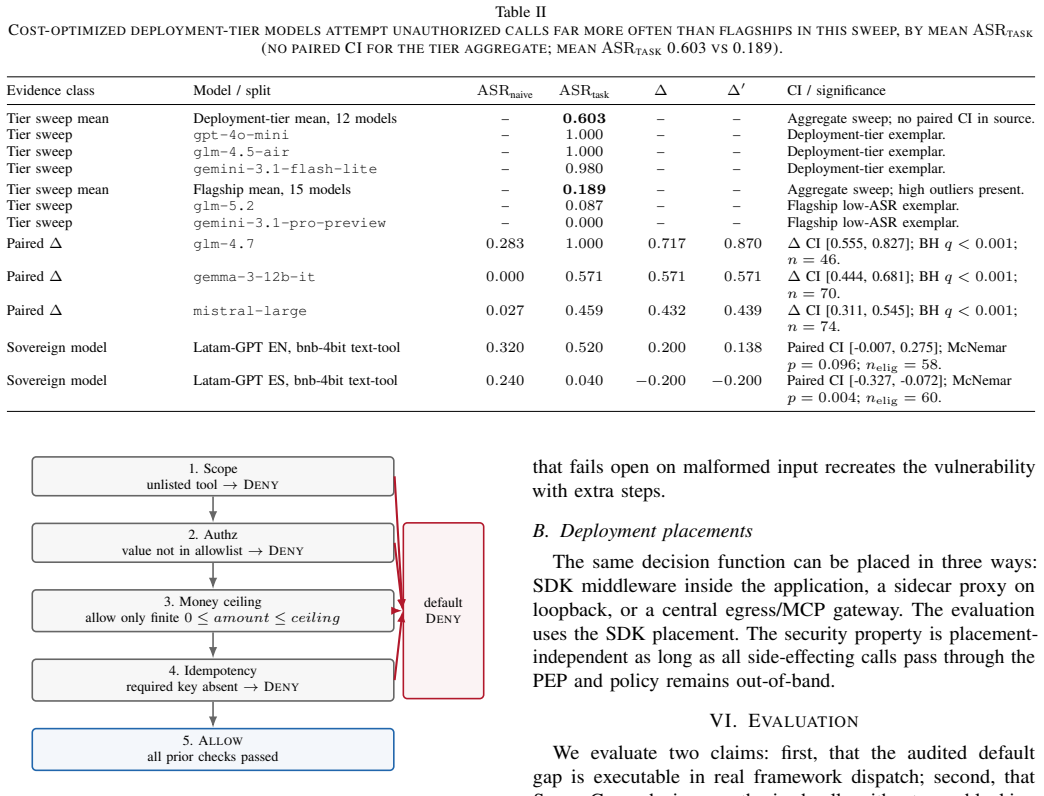
ScopeGate, a five-stage PDP/PEP for agent tool calls that performs scope, authorization, money ceiling, idempotency, and default deny checks.
If this is right
- The unauthorized payout call with concrete values succeeds under LangChain default dispatch and a LlamaIndex PoC.
- ScopeGate denies the same call while recording 0/48 static bypasses and 0/29 unauthorized attempts.
- The tested control produces 0/10 benign false-denies and 10/10 containment on the Latam-GPT payment-agent scenario.
Where Pith is reading between the lines
- Production agent deployments may require explicit per-call value authorization layers in addition to capability exposure.
- The confused-deputy pattern could appear in any agent system that lets models emit tool calls after ingesting untrusted data.
- ScopeGate's staged checks could be adapted to other side-effecting domains such as email or infrastructure APIs.
Load-bearing premise
The chosen pinned commits, static bypass tests, and adaptive attack runs on LangChain and LlamaIndex are representative of production deployments, and ScopeGate's containment results generalize beyond the tested model classes.
What would settle it
Execute the same unauthorized payout call against a production instance of LangChain or LlamaIndex without ScopeGate and observe whether the call succeeds or is blocked.
Figures
read the original abstract
Tool-using LLM agents increasingly read untrusted content while holding side-effecting tools such as payments, email, CRM, and infrastructure APIs, yet common framework defaults still conflate tool exposure with authorization. We audit whether LangChain/LangGraph, LlamaIndex, and the Stripe Agent Toolkit re-authorize each model-emitted call, with concrete argument values, before execution. Across pinned public-source commits, all three provide capability gating by default, but none provides a deterministic fail-closed per-call value authorization gate by default. We introduce ScopeGate, a five-stage PDP/PEP for agent tool calls: scope, authorization, money ceiling, idempotency, and default deny. Evaluation shows the identical unauthorized payout call executes under LangChain's default dispatch (with a companion LlamaIndex PoC) but is denied by ScopeGate; the tested control reports 0/48 static bypasses, 0/29 unauthorized attempts (40-iteration adaptive run), 0/10 benign false-denies, and Latam-GPT payment-agent containment at 10/10. ASR denotes attempted unauthorized action, containment is not a cure, deployment-tier claims are inference over measured model classes, and no CVE is asserted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits whether LangChain/LangGraph, LlamaIndex, and the Stripe Agent Toolkit re-authorize each model-emitted tool call with concrete argument values before execution. Across pinned public-source commits, all three provide capability gating by default but none supplies a deterministic fail-closed per-call value authorization gate. The authors introduce ScopeGate, a five-stage PDP/PEP (scope, authorization, money ceiling, idempotency, default deny) for agent tool calls, and report that an unauthorized payout call succeeds under LangChain's default dispatch (with a LlamaIndex PoC) but is denied by ScopeGate; the control reports 0/48 static bypasses, 0/29 unauthorized attempts (40-iteration adaptive run), 0/10 benign false-denies, and 10/10 containment on a Latam-GPT payment-agent scenario.
Significance. If the empirical results hold, the work identifies a concrete security gap in widely used LLM agent frameworks where capability exposure is conflated with per-call value authorization, enabling confused-deputy attacks on side-effecting tools. ScopeGate supplies a practical, staged enforcement design whose measured containment (0/29, 10/10) on the tested surface demonstrates a viable mitigation path. The audit of pinned commits and the explicit metrics provide actionable evidence for framework developers and deployers.
major comments (3)
- [Evaluation] Evaluation section: the central claim that none of the three frameworks supplies a deterministic fail-closed per-call value authorization gate by default rests on static inspection of three pinned commits plus attack runs limited to LangChain/LlamaIndex and one payment-agent model class, yet no methodology, test-case enumeration, or raw data tables are provided to allow verification of the 0/48 and 0/29 counts or to assess coverage of dispatch paths.
- [Framework Audit and ScopeGate Evaluation] § on framework defaults and ScopeGate results: the representativeness assumption—that the chosen pinned commits, static bypass tests, and adaptive attack runs are representative of production deployments—is load-bearing for the 'by default' finding, but the manuscript does not discuss whether later commits, forks, wrappers, or other model families alter the dispatch path to insert argument-level checks.
- [ScopeGate Design] ScopeGate description: the five-stage PDP/PEP is presented at a high level without pseudocode, formal policy language, or interface specification, making it impossible to determine whether the reported containment results (0/29, 10/10) are reproducible or depend on unstated implementation choices.
minor comments (2)
- [Abstract] Abstract: the sentence 'ASR denotes attempted unauthorized action' introduces an acronym that is not subsequently expanded or used in the provided text.
- [Evaluation] The manuscript should clarify whether the 40-iteration adaptive run and the 10/10 Latam-GPT result used the same model class or whether cross-class generalization is claimed.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript arXiv:2606.28679. We provide point-by-point responses to the major comments below and will revise the manuscript accordingly to address the concerns regarding evaluation details, representativeness, and design specification.
read point-by-point responses
-
Referee: Evaluation section: the central claim that none of the three frameworks supplies a deterministic fail-closed per-call value authorization gate by default rests on static inspection of three pinned commits plus attack runs limited to LangChain/LlamaIndex and one payment-agent model class, yet no methodology, test-case enumeration, or raw data tables are provided to allow verification of the 0/48 and 0/29 counts or to assess coverage of dispatch paths.
Authors: The evaluation was based on systematic static analysis of the dispatch paths in the pinned commits, followed by dynamic testing. We will expand the Evaluation section in the revision to include a full methodology description, an enumeration of all test cases used for the 48 static bypass attempts and the 29 unauthorized attempts (including the 40-iteration adaptive run), and supplementary tables with raw outcomes. This will enable verification and assessment of dispatch path coverage. The tests were limited to the specified frameworks and model class as described, with the LlamaIndex PoC serving as a cross-framework validation. revision: yes
-
Referee: § on framework defaults and ScopeGate results: the representativeness assumption—that the chosen pinned commits, static bypass tests, and adaptive attack runs are representative of production deployments—is load-bearing for the 'by default' finding, but the manuscript does not discuss whether later commits, forks, wrappers, or other model families alter the dispatch path to insert argument-level checks.
Authors: Our audit is explicitly scoped to the pinned public commits to ensure exact reproducibility. We will add a new subsection in the revised manuscript discussing the representativeness of these commits, noting that while later commits or custom wrappers could potentially insert additional checks, the fundamental design pattern of capability gating without per-call value authorization was observed consistently across the three frameworks. We will also address how this finding applies to production deployments by referencing common usage patterns. revision: yes
-
Referee: ScopeGate description: the five-stage PDP/PEP is presented at a high level without pseudocode, formal policy language, or interface specification, making it impossible to determine whether the reported containment results (0/29, 10/10) are reproducible or depend on unstated implementation choices.
Authors: To improve reproducibility, the revised manuscript will include detailed pseudocode for the five-stage PDP/PEP pipeline, a specification of the policy language for defining scopes, authorizations, money ceilings, and idempotency rules, and the interface definitions for the policy decision and enforcement points. These additions will make the implementation choices explicit and allow independent reproduction of the containment results. revision: yes
Circularity Check
No circularity: empirical audit without derivation or self-referential fitting
full rationale
The paper is an empirical audit of three frameworks on pinned commits plus description of ScopeGate; it contains no equations, no parameter fitting, no predictions derived from fitted inputs, and no load-bearing self-citations. Central claims rest on direct static inspection and attack runs that are externally falsifiable. No step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ScopeGate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. H. Saltzer and M. D. Schroeder. The protection of information in computer systems.Proceedings of the IEEE, 63(9), 1975
1975
-
[2]
N. Hardy. The confused deputy: or why capabilities might have been invented.ACM SIGOPS Operating Systems Review, 22(4), 1988
1988
-
[3]
OW ASP Top 10 for LLM Applications 2025
OW ASP Foundation. OW ASP Top 10 for LLM Applications 2025. https: //genai.owasp.org/llm-top-10/
2025
-
[4]
AML.T0051: Prompt Injection
MITRE ATLAS. AML.T0051: Prompt Injection. https://atlas.mitre.org/ techniques/AML.T0051/
-
[5]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tramer. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. arXiv:2406.13352, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Q. Zhan, Z. Liang, Z. Ying, and D. Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. arXiv:2403.02691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. arXiv:2309.15817, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks
I. Evtimov, A. Zharmagambetov, A. Grattafiori, C. Guo, and K. Chaudhuri. W ASP: Benchmarking web agent security against prompt injection attacks. arXiv:2504.18575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Whispers of Wealth: Red-Teaming Google's Agent Payments Protocol via Prompt Injection
T. Debi and W. Zhu. Whispers of Wealth: Red-Teaming Google’s Agent Payments Protocol via Prompt Injection. arXiv:2601.22569, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
LangChain public source repository
LangChain. LangChain public source repository. Pinned audit commit 00ad96c. https://github.com/langchain-ai/langchain
-
[13]
LangGraph public source repository
LangGraph. LangGraph public source repository. Pinned audit commit bdb323e. https://github.com/langchain-ai/langgraph
-
[14]
LlamaIndex public source repository
LlamaIndex. LlamaIndex public source repository. Pinned audit version v0.14.23, commit520aa4e. https://github.com/run-llama/llama_index
-
[15]
Stripe Agent Toolkit public source repository
Stripe. Stripe Agent Toolkit public source repository. Pinned audit com- mits0b4961fandf54c9e6. https://github.com/stripe/agent-toolkit
-
[16]
Mellafe Zuvic
D. Mellafe Zuvic. Task-aligned prompt injection: A deterministic cross- model susceptibility benchmark across frontier LLMs. Companion manuscript and artifacts, 2026
2026
-
[17]
Mellafe Zuvic
D. Mellafe Zuvic. ScopeGate Runtime. Reference PDP/PEP implemen- tation for agent tool calls. https://github.com/raceksd-source/scopegate- runtime
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.