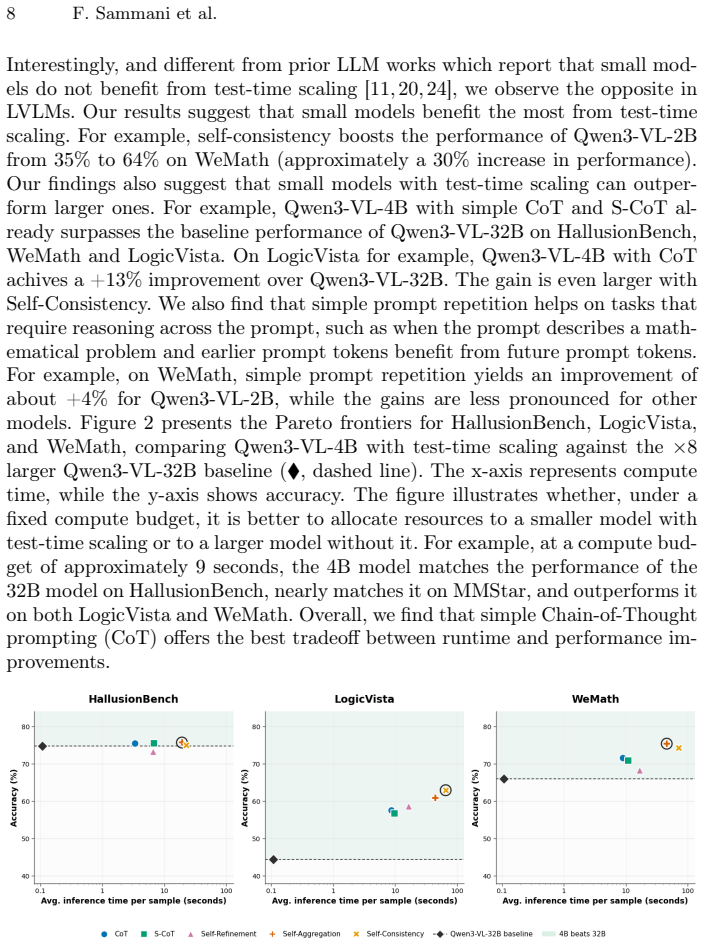
On Test-Time Scaling for Vision-Language Models
Pith reviewed 2026-06-30 09:54 UTC · model grok-4.3
The pith
Small vision-language models gain the largest boosts from test-time scaling, improving up to 30% to reach or beat larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
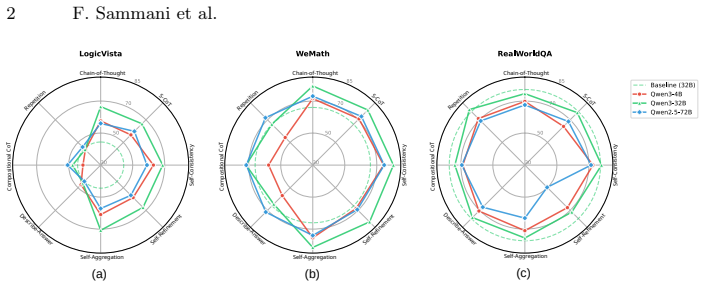
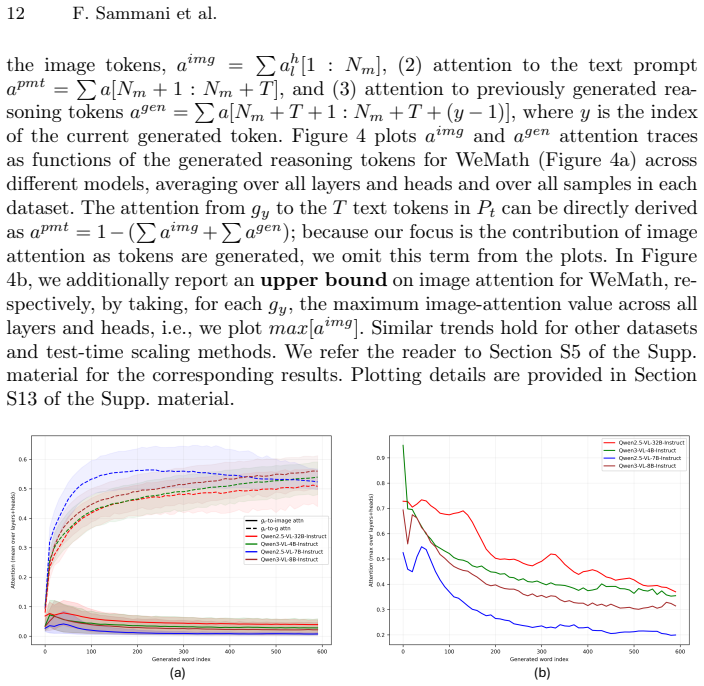
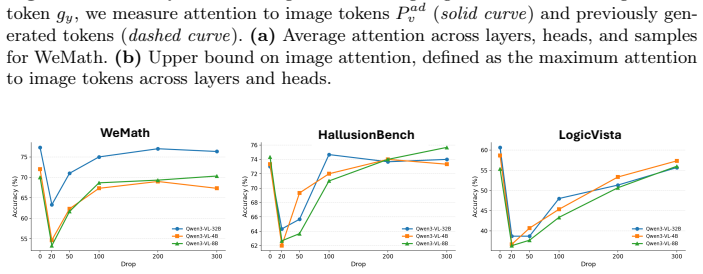
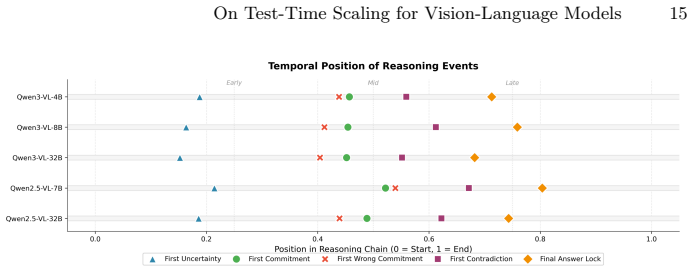
Conventional test-time scaling methods can be applied to LVLMs, but small well-performing models benefit most, with gains reaching around 30% that allow them to match or exceed large-model performance; models lose focus with unnecessary extra compute, and visual information is encoded early in the chain after which text-only reasoning dominates.
What carries the argument
Test-time scaling methods that allocate extra inference compute without changing model weights, applied across LVLMs of varying sizes.
If this is right
- Small models become practical alternatives to large ones when test-time scaling is available.
- Adding more compute beyond a certain point can degrade output quality.
- Reasoning chains shift to text dominance after the initial visual encoding step.
- Performance gains are largest for models that already perform well without scaling.
Where Pith is reading between the lines
- Deployment pipelines could default to smaller base models plus scaling rather than always scaling up model size.
- Architectures might be redesigned to preserve visual token influence deeper into long chains.
- Task-specific early stopping rules for compute could be developed based on when visual contribution drops.
Load-bearing premise
The nine scaling methods and six benchmarks capture the general behavior of test-time scaling for LVLMs and other tasks.
What would settle it
Running the same nine methods on a fresh collection of LVLMs and benchmarks outside the original six and checking whether small models still show the largest relative gains.
Figures


read the original abstract
Test-time scaling is a paradigm where large models use additional compute at inference to achieve better performance, without changing model weights. While it has been widely studied for Large Language Models (LLMs), its applicability to Large Vision-Language Models (LVLMs) remains less explored and analyzed, with limited analysis of whether, when, and to what extent these approaches transfer to LVLMs. In this work, we ask a simple but fundamental question: can conventional test-time scaling methods developed for LLMs be directly applied to LVLMs? We present the first comprehensive study of test-time scaling for LVLMs, spanning multiple models and model sizes, nine test-time scaling methods, and six diverse benchmarks. Our main findings is that 1) different from previous findings, small, well-performing models benefit the most from test-time scaling, enabling performance improvements of up to around 30\%, reaching large models performance, and often outperforming them, 2) LVLMs lose focus when given more compute than necessary, and 3) Visual information is encoded early in the reasoning chain, after which the chain is dominated by text-only reasoning and the contribution of image tokens drops significantly. Finally, we also provide a global and fine-grained analysis on the quality and information sufficiency of the reasoning chains produced. Overall, our findings and analysis provide practical guidance and insights into LVLMs and their deployment in research and industry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first comprehensive empirical study of test-time scaling for Large Vision-Language Models (LVLMs). It evaluates nine test-time scaling methods (adapted from LLMs) across six diverse benchmarks and multiple model sizes, claiming that (1) small, well-performing LVLMs benefit most, with gains up to ~30% that allow them to match or exceed larger models, (2) excess compute causes LVLMs to lose focus, and (3) visual information is encoded early in the reasoning chain, after which text-only reasoning dominates. The work also includes global and fine-grained analysis of reasoning chain quality and information sufficiency.
Significance. If the empirical patterns hold, the results provide actionable guidance for efficient LVLM deployment, showing that test-time scaling can make smaller models competitive with larger ones without retraining. The breadth of the study (nine methods, six benchmarks, multi-size models) and the analysis of reasoning chains (early visual encoding, focus loss) are strengths that go beyond raw performance numbers and offer insights into LVLM behavior under varying inference compute.
major comments (2)
- [§4 (Experimental Setup)] §4 (Experimental Setup): The headline claim that small well-performing models benefit most (up to ~30% gains, often outperforming larger models) is observed only on the nine chosen LLM-derived scaling methods and six benchmarks. The manuscript does not provide an explicit justification or sensitivity analysis for why these nine methods and six benchmarks are representative of the broader space of inference-time compute strategies and visual reasoning tasks; without this, the differential benefit for smaller models risks being an artifact of the selected subset rather than a general property.
- [§5 (Results)] §5 (Results): Performance improvements are reported without error bars, statistical significance tests, details on data splits, or controls for confounding factors (e.g., prompt sensitivity or benchmark-specific biases). This makes it difficult to assess the robustness of the ~30% gain claim and the cross-model comparisons that underpin the central finding.
minor comments (2)
- [Abstract] Abstract: 'our main findings is' should be corrected to 'our main findings are'.
- [§5] Figures in §5: Ensure all plots include legends that explicitly name the nine scaling methods and six benchmarks for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experimental choices and result reporting. We address each major comment below, providing justifications where possible and committing to revisions to improve clarity and robustness.
read point-by-point responses
-
Referee: [§4 (Experimental Setup)] §4 (Experimental Setup): The headline claim that small well-performing models benefit most (up to ~30% gains, often outperforming larger models) is observed only on the nine chosen LLM-derived scaling methods and six benchmarks. The manuscript does not provide an explicit justification or sensitivity analysis for why these nine methods and six benchmarks are representative of the broader space of inference-time compute strategies and visual reasoning tasks; without this, the differential benefit for smaller models risks being an artifact of the selected subset rather than a general property.
Authors: The nine methods were chosen to systematically cover the primary categories of test-time scaling techniques from the LLM literature (sampling-based, search-based, and verification-based), directly adapted to LVLMs as stated in the paper. The six benchmarks were selected for their established use in LVLM evaluation and diversity across visual question answering, reasoning, and multimodal tasks. We will add an explicit justification paragraph in §4, referencing the source LLM papers and prior LVLM benchmark surveys. To further address concerns about generality, we will include a sensitivity analysis on a representative subset of methods and benchmarks in the revision. revision: partial
-
Referee: [§5 (Results)] §5 (Results): Performance improvements are reported without error bars, statistical significance tests, details on data splits, or controls for confounding factors (e.g., prompt sensitivity or benchmark-specific biases). This makes it difficult to assess the robustness of the ~30% gain claim and the cross-model comparisons that underpin the central finding.
Authors: We agree that the lack of error bars and statistical tests weakens the ability to evaluate robustness. In the revised manuscript, we will add error bars from multiple runs with different random seeds for the main results and include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the reported gains across models. Data splits use the official test sets from each benchmark's original release. Prompts follow standardized templates from prior LVLM studies; we will add a note on this and a brief discussion of potential prompt sensitivity. Benchmark biases are addressed through the use of six diverse tasks, which we will emphasize more clearly. revision: yes
Circularity Check
No circularity: purely empirical benchmark study
full rationale
The paper reports measured performance of nine test-time scaling methods across six benchmarks on multiple LVLMs. All findings (e.g., small models gaining up to ~30%, visual information encoded early) are direct empirical observations against external benchmarks. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided text or abstract. The study is self-contained against its chosen benchmarks with no derivation chain that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmarks used are valid proxies for real-world LVLM performance
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Transactions on Machine Learning Research (2025)
Chen, H., Tu, H., Wang, F., Liu, H., Tang, X., Du, X., Zhou, Y., Xie, C.: SFT or RL? an early investigation into training r1-like reasoning large vision-language models. Transactions on Machine Learning Research (2025)
2025
-
[4]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., Zhao, F.: Are we on the right way for evaluating large vision- language models? In: Advances in Neural Information Processing Systems (2024), https://openreview.net/forum?id=evP9mxNNxJ
2024
-
[5]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim, C.D., Yang, Y., Shao, V., Yang, Y., Huang, W., Gao, Z., Anderson, T., Zhang, J., Jain, J., Stoica, G., Han, W., Farhadi, A., Krishna, R.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. ArXivabs/2601.10611(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14375–14385 (2024)
2024
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp
Guo, J., Li, J., Li, D., Tiong, A.M.H., Li, B.A., Tao, D., Hoi, S.C.H.: From im- ages to textual prompts: Zero-shot visual question answering with frozen large language models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp. 10867–10877 (2022)
2022
-
[8]
In: The 16th Asian Conference on Machine Learning (Conference Track) (2024)
Jia, Z., Liu, J., Li, H., Liu, Q., Gao, H.: DCot: Dual chain-of-thought prompting for large multimodal models. In: The 16th Asian Conference on Machine Learning (Conference Track) (2024)
2024
-
[9]
In: International Conference on Learning Representations (2026)
Kaya, M.O., Elliott, D., Papadopoulos, D.: Efficient test-time scaling for small vision-language models. In: International Conference on Learning Representations (2026)
2026
-
[10]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A di- agram is worth a dozen images. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) European Conference on Computer Vision. pp. 235–251. Springer Interna- tional Publishing, Cham (2016)
2016
-
[11]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Denison, C.E., Hernan- dez, D., Li, D., Durmus, E., Hubinger, E., Kernion, J., Lukovsiut.e, K., Nguyen, K., Cheng, N., Joseph, N., Schiefer, N., Rausch, O., Larson, R., McCandlish, S., Kundu, S., Kadavath, S., Yang, S., Henighan, T., Maxwell, T.D., Telleen-Lawton, T., Hume, T., Hatfield-Dodds, Z., Kapl...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Leviathan, Y., Kalman, M., Matias, Y.: Prompt repetition improves non-reasoning llms. ArXivabs/2512.14982(2025)
-
[13]
Transactions on Machine Learning Research (2025)
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., Li, C.: LLaVA-onevision: Easy visual task transfer. Transactions on Machine Learning Research (2025)
2025
-
[14]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Li, B., Wang, R., Wang, G., Ge, Y., Ge, Y., Shan, Y.: Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Li, Z., Feng, X., Cai, Y., Zhang, Z., Liu, T., Liang, C., Chen, W., Wang, H., Zhao, T.: Llms can generate a better answer by aggregating their own responses. ArXiv abs/2503.04104(2025)
-
[16]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European Conference on Computer Vision. pp. 216–233. Springer (2024)
2024
-
[17]
In: International Conference on Learning Representa- tions (2024)
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In: International Conference on Learning Representa- tions (2024)
2024
-
[18]
In: Advances in Neural Information Processing Systems (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: Advances in Neural Information Processing Systems (2022)
2022
-
[19]
In: Advances in Neural Information Processing Systems (2023)
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B.P., Hermann, K., Welleck, S., Yazdanbakhsh, A., Clark, P.: Self-refine: Iterative refinement with self-feedback. In: Advances in Neural Information Processing Systems (2023)
2023
-
[20]
doi:10.18653/v1/2023.acl- long.346
Magister, L.C., Mallinson, J., Adamek, J., Malmi, E., Severyn, A.: Teaching small language models to reason. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Pro- ceedings of the 61st Annual Meeting of the Association for Computational Linguis- tics (Volume 2: Short Papers). pp. 1773–1781. Association for Computational Lin- guistics, Toronto, Canada (J...
-
[21]
In: Second Conference on Language Modeling (2025),https://openreview.net/forum?id=qMUbhGUFUb
Marafioti, A., Zohar, O., Farré, M., noyan, M., Bakouch, E., Jiménez, P.M.C., Zakka, C., allal, L.B., Lozhkov, A., Tazi, N., Srivastav, V., Lochner, J., Larcher, H., Morlon, M., Tunstall, L., Werra, L.V., Wolf, T.: SmolVLM: Redefining small and efficient multimodal models. In: Second Conference on Language Modeling (2025),https://openreview.net/forum?id=q...
2025
-
[22]
Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition pp
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models. Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition pp. 14420–14431 (2023)
2023
-
[23]
In: Conference on Empirical Methods in Natural Language Processing (2025), https://api.semanticscholar.org/CorpusID:276079693
Muennighoff, N., Yang, Z., Shi, W., Li, X.L., Li, F.F., Hajishirzi, H., Zettle- moyer, L.S., Liang, P., Candès, E.J., Hashimoto, T.: s1: Simple test-time scal- ing. In: Conference on Empirical Methods in Natural Language Processing (2025), https://api.semanticscholar.org/CorpusID:276079693
2025
-
[24]
ArXivabs/2509.03321(2025),https://api.semanticscholar.org/CorpusID: 281092552
Ou, L.: Empowering lightweight mllms with reasoning via long cot sft. ArXivabs/2509.03321(2025),https://api.semanticscholar.org/CorpusID: 281092552
-
[25]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Qiao, R., Tan, Q., Dong, G., Wu, M., Sun, C., Song, X., GongQue, Z., Lei, S., Wei, Z., Zhang, M., et al.: We-math: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284 (2024) 18 F. Sammani et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) pp
Sammani, F., Deligiannis, N.: Uni-nlx: Unifying textual explanations for vision and vision-language tasks. 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) pp. 4636–4641 (2023)
2023
-
[27]
In: The Thirteenth International Conference on Learning Representations (2025)
Sammani, F., Deligiannis, N.: Zero-shot natural language explanations. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[28]
2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) pp
Sammani, F., Mukherjee, T., Deligiannis, N.: Nlx-gpt: A model for natural lan- guage explanations in vision and vision-language tasks. 2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) pp. 8312–8322 (2022)
2022
-
[29]
In: European Conference on Computer Vision (2022),https://api.semanticscholar.org/ CorpusID:249375629
Schwenk, D., Khandelwal, A., Clark, C., Marino, K., Mottaghi, R.: A-okvqa: A benchmark for visual question answering using world knowledge. In: European Conference on Computer Vision (2022),https://api.semanticscholar.org/ CorpusID:249375629
2022
-
[30]
In: International Con- ference on Learning Representations (2025)
Snell, C.V., Lee, J., Xu, K., Kumar, A.: Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In: International Con- ference on Learning Representations (2025)
2025
-
[31]
In: International Conference on Learning Representations (2025)
Springer, J.M., Kotha, S., Fried, D., Neubig, G., Raghunathan, A.: Repetition improves language model embeddings. In: International Conference on Learning Representations (2025)
2025
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Suma, A., Dauncey, S.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. ArXivabs/2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Venkatraman, S., Jain, V., Mittal, S., Shah, V., Obando-Ceron, J., Bengio, Y., Bartoldson, B.R., Kailkhura, B., Lajoie, G., Berseth, G., Malkin, N., Jain, M.: Recursive self-aggregation unlocks deep thinking in large language models. ArXiv abs/2509.26626(2025)
-
[34]
In: Annual Meeting of the Association for Computational Linguistics (2023)
Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R.K.W., Lim, E.P.: Plan-and-solve prompting:Improvingzero-shotchain-of-thoughtreasoningbylargelanguagemod- els. In: Annual Meeting of the Association for Computational Linguistics (2023)
2023
-
[35]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hao, H., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He, C., Shi, B., He, J....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: International Conference on Learning Representations (2023)
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. In: International Conference on Learning Representations (2023)
2023
-
[37]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Wei, J., Wang, X., Schuurmans, D., Bosma, M., brian ichter, Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain of thought prompting elicits reasoning in large language models. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022)
2022
-
[38]
co / datasets / xai - org / RealworldQA
xai: Realworldqa (2024),https : / / huggingface . co / datasets / xai - org / RealworldQA
2024
-
[39]
Xiao, Y., Sun, E., Liu, T., Wang, W.: Logicvista: Multimodal llm logical reasoning benchmark in visual contexts (2024)
2024
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xu, G., Jin, P., Wu, Z., Li, H., Song, Y., Sun, L., Yuan, L.: Llava-cot: Let vision lan- guage models reason step-by-step. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2087–2098 (2025) On Test-Time Scaling for Vision-Language Models 19
2087
-
[41]
In: Advances in Neural Information Processing Systems (2025)
Yao, H., Yin, Q., Zhang, J., Yang, M., Wang, Y., Wu, W., Su, F., Shen, L., Qiu, M., Tao, D., Huang, J.: R1-shareVL: Incentivizing reasoning capabilities of multi- modal large language models via share-GRPO. In: Advances in Neural Information Processing Systems (2025)
2025
-
[42]
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., Wei, C., Yu, B., Yuan, R., Sun, R., Yin, M., Zheng, B., Yang, Z., Liu, Y., Huang, W., Sun, H., Su, Y., Chen, W.: Mmmu: A massive multi-discipline multimodalunderstandingandreasoningbenchmarkforexpertagi.In:Proceedings of the IEEE/CVF Conference on Computer...
2024
-
[43]
Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y., Song, S., Huang, G.: Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In: Advances in Neural Information Processing Systems (2025)
2025
-
[44]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Zhang, R., Zhang, B., Li, Y., Zhang, H., Sun, Z., Gan, Z., Yang, Y., Pang, R., Yang, Y.: Improve vision language model chain-of-thought reasoning. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers). pp.1631–1662(2025).https://doi.org/10.18653/v1...
-
[45]
Transactions on Machine Learning Research (2023)
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.J.: Multimodal chain-of-thought reasoning in language models. Transactions on Machine Learning Research (2023)
2023
-
[46]
Zheng, G., Yang, B., Tang, J., Zhou, H.Y., Yang, S.: DDCot: Duty-distinct chain- of-thought prompting for multimodal reasoning in language models. In: Advances in Neural Information Processing Systems (2023),https://openreview.net/ forum?id=ktYjrgOENR On Test-Time Scaling for Vision-Language Models (Supplementary Material) S1 InternVL-3.5 Results Tabular ...
2023
-
[47]
Understand the question and break it down into independent concepts and components
-
[48]
Then outline relevant information for each
-
[49]
Apply logical reasoning to derive conclusions from the information and provide a step-by-step articulation of your reasoning process
-
[50]
PaS: First understand the question and devise a plan to solve the question
Summarize the main points that are relevant to answering the question. PaS: First understand the question and devise a plan to solve the question. Then, carry out the plan and solve the question step by step. Self-Aggregation: Question: {question} You will read multiple solutions (may be redundant or wrong): {candidates} Using the image, review the soluti...
-
[51]
Objects that are relevant to answering the question
-
[52]
Object attributes that are relevant to answering the question
-
[53]
predicted_answer_from_rationale
Object relationships that are relevant to answering the question Scene Graph: Note that for prompt repetition, thethink-promptis just thequestion. More- over, Self-Consistency does not have a specificthink-promptas it is just in- volves sampling multiple responses for the CoT method, which means it uses thethink-promptof the CoT method for each sample. S9...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.