Low-cost concept-based localized explanations: How far can we get with training-free approaches?
Pith reviewed 2026-06-30 09:13 UTC · model grok-4.3
The pith
Mid-scale multimodal models can name concepts in localized image regions at 62-88 percent accuracy with zero-shot prompting alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
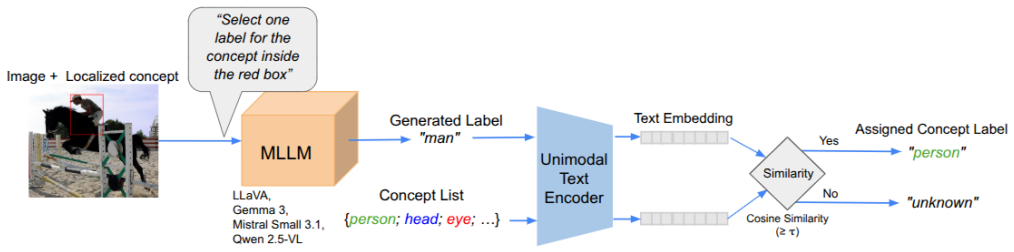
Under strict zero-shot conditions, mid-scale MLLMs can perform localized concept naming by assigning labels to bounding-box regions at object and part levels via closed-set prompting and embedding-similarity matching, with experiments on four models (7B-32B) producing consistent performance trends and object-level exact-match accuracies of 62 percent to 88 percent across datasets.
What carries the argument
The CoNa and Open-CoNa zero-shot evaluation protocols that assign semantic concept labels to localized image regions through closed-set prompting or embedding-similarity matching.
If this is right
- Training-free concept annotation from localized regions becomes a practical option for concept-based explainable AI.
- Mid-scale MLLMs can serve as reproducible annotators for both object-level and part-level concepts.
- The two protocols supply a standardized way to compare zero-shot concept naming performance across models and datasets.
- Documented limitations and failure modes can direct prompt and model selection for future applications.
Where Pith is reading between the lines
- The released framework could be used to test whether ensembling several MLLMs raises accuracy above the single-model range reported.
- The same zero-shot region labeling might transfer to other modalities such as video frames or 3-D point clouds.
- If the accuracy holds on new domains, it would lower the barrier to building concept-based explanation pipelines that avoid large labeled datasets.
Load-bearing premise
The zero-shot prompting and similarity-matching procedure yields labels that correspond to human semantic concepts without systematic distortion from the models' training data or prompt wording.
What would settle it
A human annotation study on the same bounding boxes that finds low inter-rater agreement or systematic mismatches between the labels produced by the zero-shot protocols and the concepts chosen by people.
Figures

read the original abstract
Concept-based Explainable AI (C-XAI) seeks human-understandable explanations grounded in semantic concepts, yet validation is limited by the scarcity of fine-grained concept annotations. We evaluate whether mid-scale Multimodal Large Language Models (MLLMs) can perform localized concept naming under strict zero-shot conditions by assigning labels to bounding-box regions at both object and part levels. We propose a reproducible zero-shot evaluation protocol for Concept Naming (CoNa) with (i) closed-set, category-constrained prompting for moderate vocabularies and (ii) Open-CoNa, an embedding-similarity-based strategy for large label spaces. Experiments with four MLLMs (7B-32B) show consistent performance trends across datasets, reaching 62%-88% object-level exact-match accuracy, highlighting the potential of training-free concept annotation from localized regions. We discuss limitations and failure modes and release a reproducible framework to support future low-cost C-XAI research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether mid-scale MLLMs can perform zero-shot localized concept naming at object and part levels for C-XAI. It introduces reproducible protocols CoNa (closed-set prompting) and Open-CoNa (embedding-similarity matching), reports 62-88% object-level exact-match accuracy across four models (7B-32B) and multiple datasets, discusses failure modes, and releases a framework.
Significance. If the reported accuracies reflect genuine alignment with human semantic concepts, the results would indicate that training-free MLLM prompting can supply low-cost localized concept annotations, mitigating the annotation bottleneck in concept-based explanations.
major comments (2)
- [Evaluation protocols (CoNa and Open-CoNa)] CoNa/Open-CoNa protocols and accuracy calculations: exact-match accuracy is computed against dataset labels via closed-set prompting and embedding similarity, yet the manuscript provides no independent human judgment study to confirm that the assigned concepts match human semantic understanding (as opposed to model pretraining associations or prompt biases). This directly affects the claim that the approach yields 'human-understandable' explanations.
- [Abstract and § on experimental results] Abstract and experimental results: the 62%-88% accuracy range is presented as evidence of consistent trends, but without explicit analysis of how label-space size, prompt phrasing, or potential training-data leakage influence the embedding-similarity matching in Open-CoNa, it remains unclear whether the metric isolates genuine localized concept naming.
minor comments (1)
- [Abstract] The abstract would benefit from briefly naming the source datasets and their annotation types to clarify what the exact-match ground truth consists of.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our evaluation protocols and experimental reporting. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Evaluation protocols (CoNa and Open-CoNa)] CoNa/Open-CoNa protocols and accuracy calculations: exact-match accuracy is computed against dataset labels via closed-set prompting and embedding similarity, yet the manuscript provides no independent human judgment study to confirm that the assigned concepts match human semantic understanding (as opposed to model pretraining associations or prompt biases). This directly affects the claim that the approach yields 'human-understandable' explanations.
Authors: We agree that dataset labels serve only as a proxy and do not constitute independent confirmation of alignment with human semantic concepts. Our protocols measure exact-match agreement with existing annotations under zero-shot conditions, which is a standard reproducible baseline but does not rule out pretraining associations or prompt biases. No human judgment study was performed, as the work prioritizes establishing training-free protocols across public datasets. In revision we will expand the limitations discussion to explicitly address this gap and its implications for the human-understandability claim. revision: partial
-
Referee: [Abstract and § on experimental results] Abstract and experimental results: the 62%-88% accuracy range is presented as evidence of consistent trends, but without explicit analysis of how label-space size, prompt phrasing, or potential training-data leakage influence the embedding-similarity matching in Open-CoNa, it remains unclear whether the metric isolates genuine localized concept naming.
Authors: The reported accuracy range aggregates results across datasets that differ in label-space size, yet we did not include dedicated ablations or analysis of label-space size effects, prompt phrasing sensitivity, or training-data leakage risks in the embedding-similarity step of Open-CoNa. We will add a targeted analysis subsection (or appendix) in the revised manuscript to examine these influences and clarify the extent to which the metric captures genuine localized concept naming. revision: yes
Circularity Check
No circularity: purely empirical evaluation of zero-shot protocols
full rationale
The paper reports experimental results from applying four existing MLLMs to localized concept naming on external datasets using the defined CoNa and Open-CoNa zero-shot protocols. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear; accuracies are computed directly against ground-truth labels from the datasets, rendering the work self-contained against external benchmarks with no reduction of claims to internal definitions by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision.” [Online]. Available: http://arxiv.org/abs/2103. 00020 4https://github.com/darianfgUgr/CoNa TABLE IV CONA ANDOPEN-CONA(ADE20K)PERFORMANCE ACROSS ...
-
[2]
Explainable artificial intelligence (XAI): What we know and what is left to attain trustworthy artificial intelligence,
S. Ali, T. Abuhmed, S. El-Sappagh, K. Muhammad, J. M. Alonso-Moral, R. Confalonieri, R. Guidotti, J. Del Ser, N. D ´ıaz- Rodr´ıguez, and F. Herrera, “Explainable artificial intelligence (XAI): What we know and what is left to attain trustworthy artificial intelligence,” vol. 99, p. 101805. [Online]. Available: https: //www.sciencedirect.com/science/articl...
-
[3]
M. Bello, R. Bello, M.-M. Garc ´ıa, A. Now´e, I. Sevillano-Garc ´ıa, and F. Herrera, “A three-level framework for LLM-enhanced explainable AI: From technical explanations to natural language.” [Online]. Available: https://doi.org/10.1007/s10796-025-10668-1
-
[4]
A. B. Arrieta, N. D ´ıaz-Rodr´ıguez, J. D. Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garc ´ıa, S. Gil-L ´opez, D. Molina, R. Benjamins, R. Chatila, and F. Herrera, “Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI.” [Online]. Available: http://arxiv.org/abs/1910.10045
-
[5]
Concept-based explainable artificial intelligence: A survey
E. Poeta, G. Ciravegna, E. Pastor, T. Cerquitelli, and E. Baralis, “Concept-based explainable artificial intelligence: A survey.” [Online]. Available: http://arxiv.org/abs/2312.12936
-
[6]
Connecting the dots in trustworthy artificial intelligence: From AI principles, ethics, and key requirements to responsible AI systems and regulation,
N. D ´ıaz-Rodr´ıguez, J. Del Ser, M. Coeckelbergh, M. L ´opez de Prado, E. Herrera-Viedma, and F. Herrera, “Connecting the dots in trustworthy artificial intelligence: From AI principles, ethics, and key requirements to responsible AI systems and regulation,” vol. 99, p. 101896. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S1566...
-
[7]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V),
B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viegas, and R. Sayres, “Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V),” inProceedings of the 35th International Conference on Machine Learning. PMLR, pp. 2668–2677. [Online]. Available: https://proceedings.mlr.press/v80/ kim18d.html
-
[8]
CUBIC: Concept embeddings for unsupervised bias identification using VLMs,
D. M ´endez, G. Bontempo, E. Ficarra, R. Confalonieri, and N. D ´ıaz- Rodr´ıguez, “CUBIC: Concept embeddings for unsupervised bias identification using VLMs,” in2025 International Joint Conference on Neural Networks (IJCNN), pp. 1–8, ISSN: 2161-4407. [Online]. Available: https://ieeexplore.ieee.org/document/11228477
-
[9]
Towards automatic concept-based explanations,
A. Ghorbani, J. Wexler, J. Y . Zou, and B. Kim, “Towards automatic concept-based explanations,” inAdvances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc. [Online]. Available: https://proceedings.neurips.cc/paper/2019/hash/ 77d2afcb31f6493e350fca61764efb9a-Abstract.html
2019
-
[10]
Evaluating object hallucination in large vision-language models,
Y . Li, Y . Du, K. Zhou, J. Wang, X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, pp. 292–305. [Online]. Available: https://aclanthology.org/2...
2023
-
[11]
Concept bottleneck models,
P. W. Koh, T. Nguyen, Y . S. Tang, S. Mussmann, E. Pierson, B. Kim, and P. Liang, “Concept bottleneck models,” inProceedings of the 37th International Conference on Machine Learning. PMLR, pp. 5338–5348. [Online]. Available: https://proceedings.mlr.press/v119/ koh20a.html
-
[12]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,” in Computer Vision – ECCV 2024, A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, Eds. Springer Nature Switzerland, pp. 38–55
2024
-
[13]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R ¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Nomic Embed: Training a Reproducible Long Context Text Embedder
Z. Nussbaum, J. X. Morris, B. Duderstadt, and A. Mulyar, “Nomic embed: Training a reproducible long context text embedder.” [Online]. Available: http://arxiv.org/abs/2402.01613
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Vi- sual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Vi- sual instruction tuning,” inNeurIPS, 2023. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/file/ 6dcf277ea32ce3288914faf369fe6de0-Paper-Conference.pdf
2023
-
[16]
G. Teamet al., “Gemma 3 technical report.” [Online]. Available: http://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
[Online]
Mistral small 3.1|mistral AI. [Online]. Available: https://mistral.ai/ news/mistral-small-3-1
-
[18]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-VL technical report.” [Online]. Available: http://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Scene parsing through ADE20k dataset,
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ADE20k dataset,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 5122–5130. [Online]. Available: http://ieeexplore.ieee.org/document/ 8100027/
-
[20]
Detect what you can: Detecting and representing objects using holistic models and body parts,
X. Chen, R. Mottaghi, X. Liu, S. Fidler, R. Urtasun, and A. Yuille, “Detect what you can: Detecting and representing objects using holistic models and body parts,” in2014 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, pp. 1979–1986. [Online]. Available: https://ieeexplore.ieee.org/document/6909651
-
[21]
K. Gong, X. Liang, D. Zhang, X. Shen, and L. Lin, “Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 6757–6765. [Online]. Available: http://ieeexplore.ieee.org/document/8100198/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.