Evidence-Informed LLM Beliefs for Continual Scientific Discovery
Pith reviewed 2026-06-30 07:55 UTC · model grok-4.3
The pith
LLMs compute better discovery rewards when priors update with evidence from past hypotheses instead of treating surprise as fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
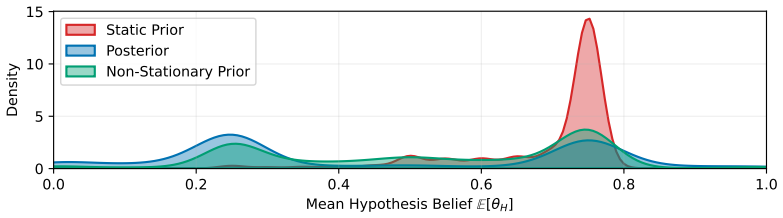
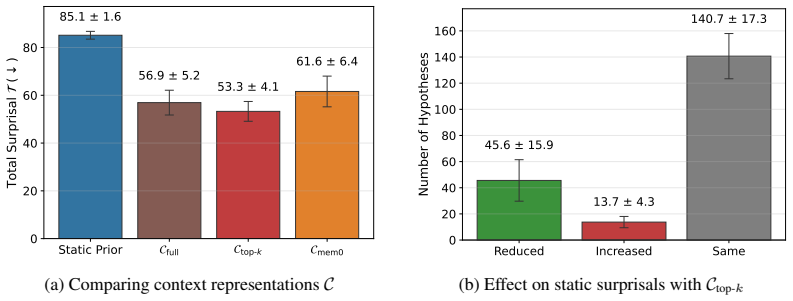
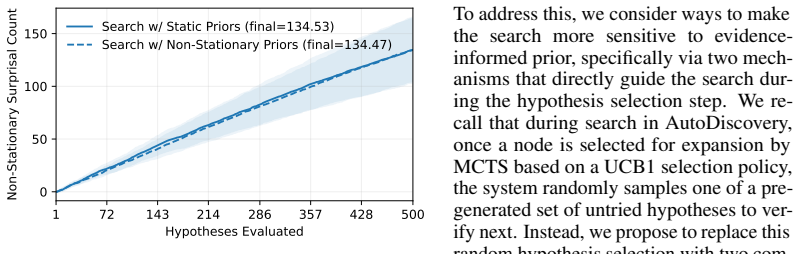
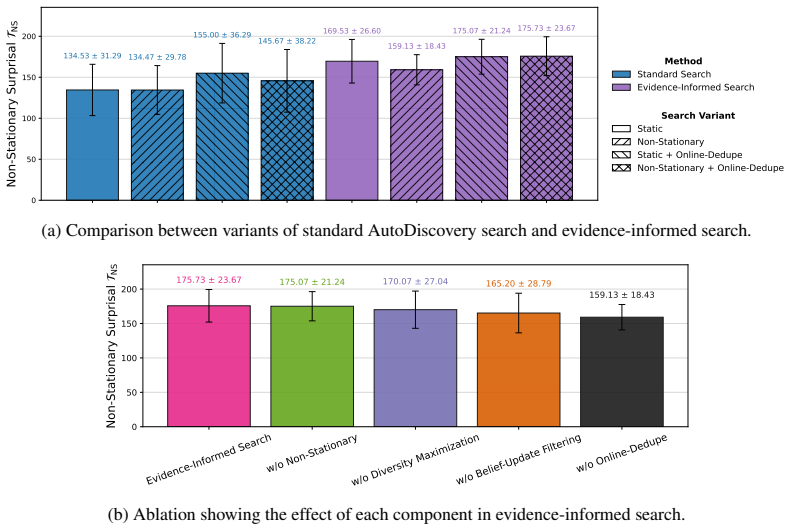
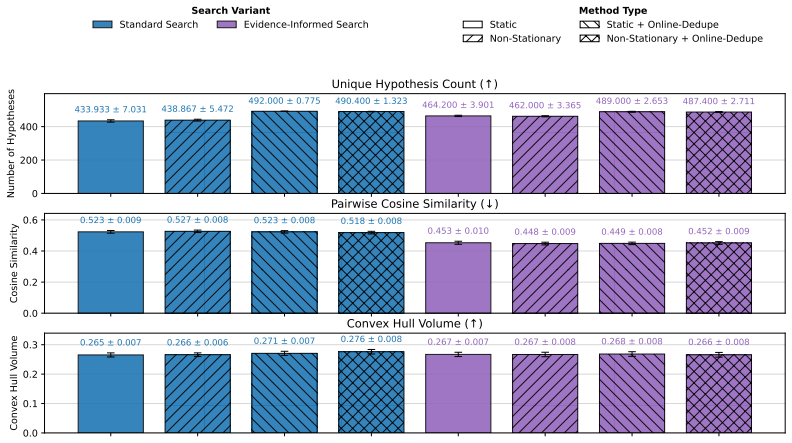
Evidence-informed LLM beliefs, formed by retrieval-augmented generation over prior discoveries, replace static surprisal with non-stationary surprisal; this correctly flags 37.5 percent of static values as spurious and, when paired with belief-update filtering plus diversity maximization, raises accumulated non-stationary surprisal by 30.62 percent relative to the unmodified search procedure.
What carries the argument
Evidence-informed LLM beliefs produced by embedding-based retrieval-augmented generation over prior discoveries, which supplies updated priors for computing non-stationary surprisal and supplies the filter used in modified search.
If this is right
- Search must filter out hypotheses whose surprisal disappears once prior evidence is incorporated.
- Diversity maximization is required in addition to belief filtering to sustain high non-stationary surprisal over long horizons.
- Non-stationary surprisal becomes the operative reward signal once beliefs are allowed to evolve.
- The same pattern holds across five distinct discovery domains.
Where Pith is reading between the lines
- Static surprise metrics may systematically over-count progress in any iterative LLM system that does not refresh its priors.
- The same retrieval-based updating mechanism could be applied to sequential reasoning tasks outside scientific discovery.
- The 30.62 percent gain suggests that redundancy avoidance, not merely better base models, is a first-order lever for continual discovery performance.
Load-bearing premise
Embedding-based retrieval over prior discoveries supplies an accurate forecast of the posterior the LLM would reach if it received direct evidence for the new hypothesis.
What would settle it
A direct test in which the LLM is given full evidence for a held-out set of hypotheses and the fraction of static surprisals still counted as spurious after the update is compared against the reported 37.5 percent.
Figures

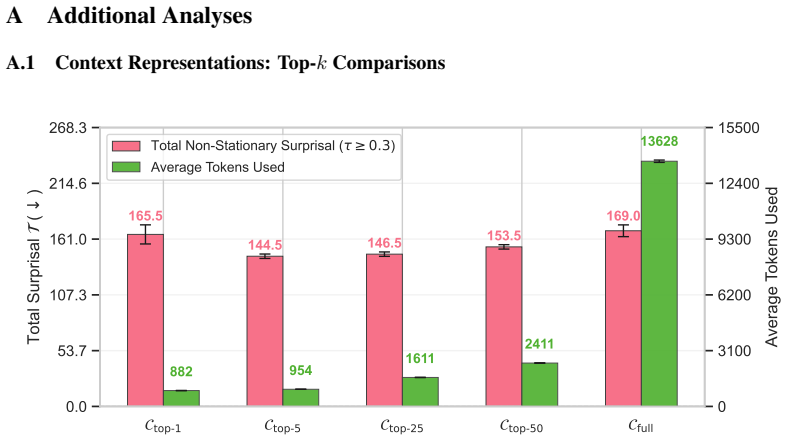
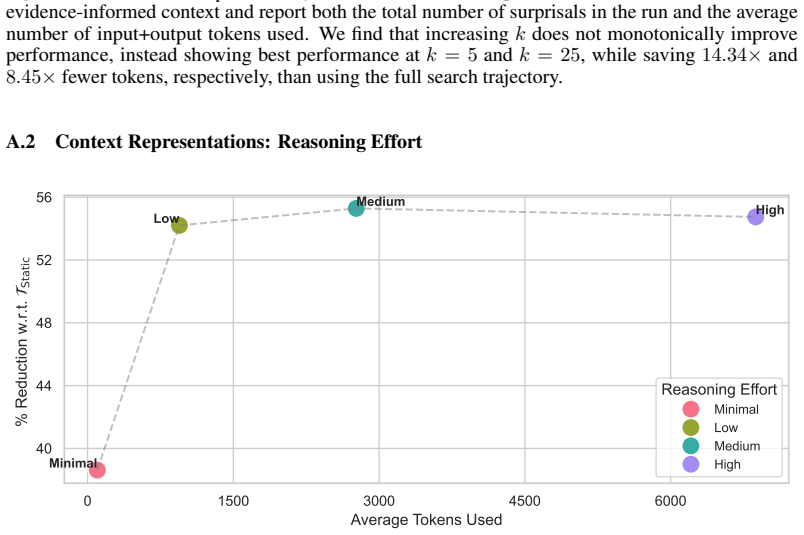
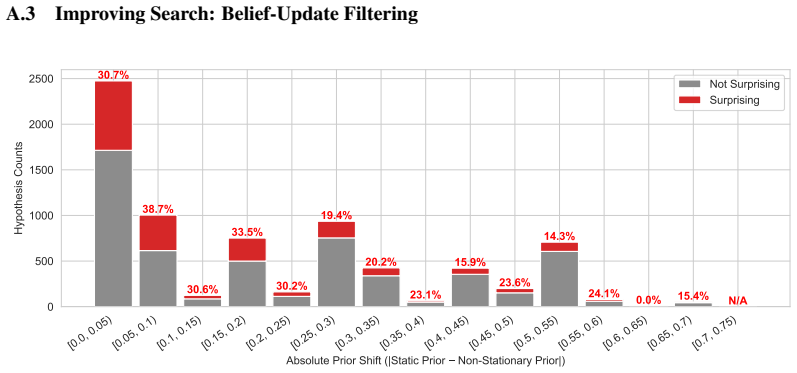
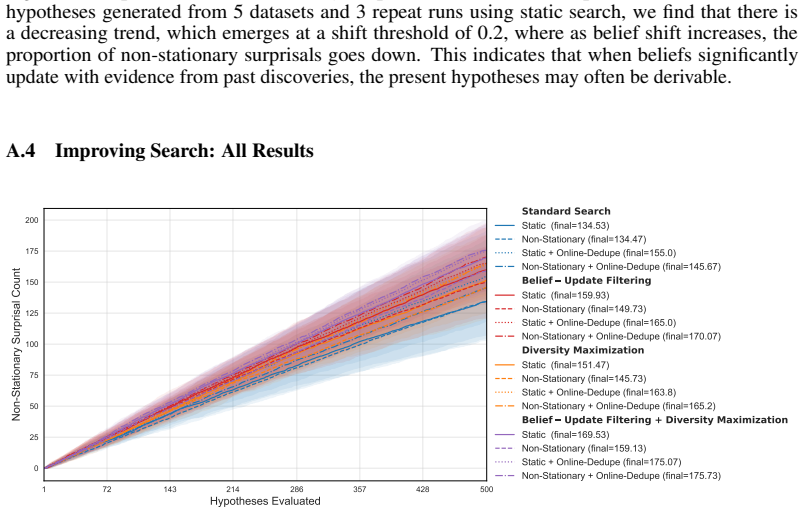
read the original abstract
Open-ended scientific discovery with large language models (LLMs) increasingly operates as a long-horizon loop of hypothesis search and verification, where a reward signal guides which hypotheses to test next. A notable recent example is AutoDiscovery, which uses "Bayesian surprise" - the belief shift an LLM undergoes after observing evidence for a hypothesis - as both a discovery metric and a reward for search. We first observe that AutoDiscovery treats surprisal as a static quantity, while surprisal in human reasoning is non-stationary - it is defined relative to beliefs that evolve with experience, a prerequisite for continual scientific discovery. We address this mismatch with evidence-informed LLM beliefs: priors updated with evidence from previous hypotheses to compute non-stationary surprisal for new hypotheses. We compare in-context belief-updating mechanisms and find that embedding-based retrieval-augmented generation over prior discoveries best anticipates eventual posteriors, identifying 37.5% of static surprisals as spurious. We then modify search to avoid these spurious rewards and prioritize hypotheses that remain surprising under non-stationary beliefs. Concretely, we introduce two complementary changes to the original search procedure: belief-update filtering and diversity maximization. Across five discovery domains, our method increases accumulated non-stationary surprisal by 30.62% on average compared to the original search procedure, demonstrating that continual scientific discovery with LLMs requires not only better belief measurement but also search procedures that avoid redundancy and encourage diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that AutoDiscovery's use of static Bayesian surprise is mismatched to continual scientific discovery, where surprisal should be non-stationary relative to evolving beliefs. It introduces evidence-informed LLM beliefs via in-context updates over prior discoveries, finds that embedding-based RAG best anticipates eventual posteriors (flagging 37.5% of static surprisals as spurious), and modifies the search procedure with belief-update filtering plus diversity maximization. Across five domains this yields a 30.62% average increase in accumulated non-stationary surprisal relative to the original procedure.
Significance. If the quantitative result and the RAG-based justification hold under robustness checks, the work would usefully highlight that belief measurement alone is insufficient and that search must actively avoid redundancy; the explicit comparison of update mechanisms and the two concrete search modifications constitute a clear, testable contribution to LLM-driven discovery loops.
major comments (3)
- [Abstract] Abstract: the central quantitative claim (30.62% increase in accumulated non-stationary surprisal) is reported without error bars, per-domain breakdowns, dataset sizes, or verification across random seeds; this directly undermines in the reported superiority of the modified search.
- [Belief-updating comparison (likely §3)] The section comparing in-context belief-updating mechanisms: the claim that embedding-based RAG 'best anticipates eventual posteriors' (thereby identifying 37.5% spurious static surprisals) is load-bearing for both the non-stationary framing and the subsequent search modifications, yet no controls for prompt sensitivity, LLM dependence in posterior construction, or alternative retrieval methods are described.
- [Search modification experiments (likely §4)] The experimental results on modified search: the 30.62% gain is measured against the authors' own baseline procedure after the two changes (belief-update filtering and diversity maximization) have been introduced; without an ablation isolating each change or a comparison to an external non-stationary baseline, attribution of the gain remains unclear.
minor comments (2)
- [Introduction / Preliminaries] Notation for non-stationary surprisal versus static Bayesian surprise should be introduced with an explicit equation early in the paper to avoid ambiguity when the two are contrasted.
- [Experimental setup] The five discovery domains are referenced but not listed with their characteristics or citation; adding a short table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important aspects for improving the clarity and robustness of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim (30.62% increase in accumulated non-stationary surprisal) is reported without error bars, per-domain breakdowns, dataset sizes, or verification across random seeds; this directly undermines in the reported superiority of the modified search.
Authors: We agree that the presentation of the quantitative results can be strengthened with additional details. In the revised version, we will report per-domain breakdowns, include the sizes of the datasets used in each of the five domains, and provide results from multiple random seeds with corresponding error bars to better support the 30.62% average increase. revision: yes
-
Referee: [Belief-updating comparison (likely §3)] The section comparing in-context belief-updating mechanisms: the claim that embedding-based RAG 'best anticipates eventual posteriors' (thereby identifying 37.5% spurious static surprisals) is load-bearing for both the non-stationary framing and the subsequent search modifications, yet no controls for prompt sensitivity, LLM dependence in posterior construction, or alternative retrieval methods are described.
Authors: The referee is correct that robustness to prompt variations and LLM choice would increase confidence in the finding. We will conduct additional experiments in the revision to test sensitivity to different prompt formulations and alternative LLMs for constructing the posteriors. We will also compare embedding-based RAG to other retrieval approaches such as BM25 to confirm its performance. revision: yes
-
Referee: [Search modification experiments (likely §4)] The experimental results on modified search: the 30.62% gain is measured against the authors' own baseline procedure after the two changes (belief-update filtering and diversity maximization) have been introduced; without an ablation isolating each change or a comparison to an external non-stationary baseline, attribution of the gain remains unclear.
Authors: We will add an ablation study in the revised manuscript to isolate the contribution of belief-update filtering versus diversity maximization to the overall gain. For an external baseline, the original AutoDiscovery procedure serves as the direct comparison point from the literature; we will clarify this and discuss why direct implementation of other non-stationary methods may not be straightforward, while acknowledging this as a limitation. revision: partial
Circularity Check
No significant circularity; derivation is empirically grounded
full rationale
The paper defines non-stationary surprisal via evidence-informed belief updates, performs an empirical comparison of in-context mechanisms against eventual posteriors to select embedding-based RAG (flagging 37.5% spurious), applies two search modifications, and reports a 30.62% average increase in the target metric versus the original AutoDiscovery procedure across five domains. No quoted step reduces a claimed prediction or result to a fitted parameter, self-citation, or definitional equivalence by construction; the central improvement is measured against an external baseline procedure and the belief-update choice rests on an observable anticipation metric rather than internal tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Surprisal in human reasoning is non-stationary and defined relative to beliefs that evolve with experience
Reference graph
Works this paper leans on
-
[1]
Agarwal, M
D. Agarwal, M. G. Arivazhagan, R. Das, S. Swamy, S. Khosla, and R. Gangadharaiah. Searching for optimal solutions with LLM s via bayesian optimization. In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=aVfDrl7xDV
2025
-
[2]
Agarwal, B
D. Agarwal, B. P. Majumder, R. Adamson, M. Chakravorty, S. R. Gavireddy, A. Parashar, H. Surana, B. D. Mishra, A. McCallum, A. Sabharwal, and P. Clark. Autodiscovery: Open-ended scientific discovery via bayesian surprise. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b . URL https://openreview.net/forum?id=kJqTkj2HhF
2025
-
[3]
Agrawal, K
S. Agrawal, K. V. Kher, S. Mittal, S. Maheshwari, and V. N. Balasubramanian. Mira: Memory-integrated reconfigurable adapters: A unified framework for settings with multiple tasks. In Advances in Neural Information Processing Systems, 2025
2025
-
[4]
C. E. Alchourr \'o n, P. G \"a rdenfors, and D. Makinson. On the logic of theory change: Partial meet contraction and revision functions. The journal of symbolic logic, 50 0 (2): 0 510--530, 1985
1985
-
[5]
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, and P. Schwaller. Augmenting large language models with chemistry tools. Nature Machine Intelligence, 6: 0 525 -- 535, 2023. URL https://api.semanticscholar.org/CorpusID:258059792
2023
-
[6]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[7]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Cou \"e toux, J.-B
A. Cou \"e toux, J.-B. Hoock, N. Sokolovska, O. Teytaud, and N. Bonnard. Continuous upper confidence trees. In Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011. Selected Papers 5, pages 433--445. Springer, 2011
2011
-
[9]
R. Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, pages 72--83. Springer, 2006
2006
-
[10]
J. Earman. Bayes or bust?: A critical examination of Bayesian confirmation theory, volume 92. MIT Press Cambridge, MA, 1992
1992
-
[11]
G \"a rdenfors
P. G \"a rdenfors. Knowledge in flux: Modeling the dynamics of epistemic states. The MIT Press, 1988
1988
- [12]
-
[13]
J. Gottweis, W.-H. Weng, A. Daryin, T. Tu, A. Palepu, P. Sirkovic, A. Myaskovsky, F. Weissenberger, K. Rong, R. Tanno, K. Saab, D. Popovici, J. Blum, F. Zhang, K. Chou, A. Hassidim, B. Gokturk, A. Vahdat, P. Kohli, Y. Matias, A. Carroll, K. Kulkarni, N. Tomasev, Y. Guan, V. Dhillon, E. D. Vaishnav, B. Lee, T. R. D. Costa, J. R. Penadés, G. Peltz, Y. Xu, A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Howson and P
C. Howson and P. Urbach. Scientific reasoning: the Bayesian approach. Open Court Publishing, 2006
2006
- [16]
-
[17]
Itti and P
L. Itti and P. Baldi. Bayesian surprise attracts human attention. Advances in neural information processing systems, 18, 2005
2005
-
[18]
Generating Literature-Driven Scientific Theories at Scale
P. Jansen, P. Clark, D. Downey, and D. S. Weld. Generating literature-driven scientific theories at scale, 2026. URL https://arxiv.org/abs/2601.16282
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
J. Kang, M. Ji, Z. Zhao, and T. Bai. Memory OS of AI agent. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V. Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961--25970, Suzhou, China, Nov. 2025. Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi:10.18653/v1/2025.em...
-
[20]
N. Kassner, O. Tafjord, H. Sch \"u tze, and P. Clark. B elief B ank: Adding memory to a pre-trained language model for a systematic notion of belief. In M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8849--8861, Online and Punta Cana, Dominican Repu...
-
[21]
Kuratov, M
Y. Kuratov, M. Kairov, A. Bulatov, I. Rodkin, and M. Burtsev. Gradmem: Learning to write context into memory with test-time gradient descent. In Third Workshop on Test-Time Updates (Main Track), 2026. URL https://openreview.net/forum?id=GidQ1tmQ2G
2026
-
[22]
L Griffiths, C
T. L Griffiths, C. Kemp, and J. B Tenenbaum. Bayesian models of cognition. Carnegie Mellon University, 2008
2008
-
[23]
T. Liu, N. Astorga, N. Seedat, and M. van der Schaar. Large language models to enhance bayesian optimization. In International Conference on Learning Representations, 2024
2024
-
[24]
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https://arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id...
2023
-
[26]
B. P. Majumder, H. Surana, D. Agarwal, S. Hazra, A. Sabharwal, and P. Clark. Position: data-driven discovery with large generative models. In Forty-first International Conference on Machine Learning, 2024
2024
-
[27]
B. P. Majumder, H. Surana, D. Agarwal, B. D. Mishra, A. Meena, A. Prakhar, T. Vora, T. Khot, A. Sabharwal, and P. Clark. Discoverybench: Towards data-driven discovery with large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=vyflgpwfJW
2025
-
[28]
Martin and D
E. Martin and D. Osherson. Scientific discovery based on belief revision. The Journal of Symbolic Logic, 62 0 (4): 0 1352--1370, 1997
1997
-
[29]
Kosmos: An AI Scientist for Autonomous Discovery
L. Mitchener, A. Yiu, B. Chang, M. Bourdenx, T. Nadolski, A. Sulovari, E. C. Landsness, D. L. Barabasi, S. Narayanan, N. Evans, et al. Kosmos: An ai scientist for autonomous discovery. arXiv preprint arXiv:2511.02824, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Rezazadeh, Z
A. Rezazadeh, Z. Li, W. Wei, and Y. Bao. From isolated conversations to hierarchical schemas: Dynamic tree memory representation for LLM s. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=moXtEmCleY
2025
-
[32]
Y. Sun, X. Wang, Z. Liu, J. Miller, A. A. Efros, and M. Hardt. Test-time training with self-supervision for generalization under distribution shifts. In Proceedings of the 37th International Conference on Machine Learning, pages 9229--9248. PMLR, 2020
2020
-
[33]
J. B. Tenenbaum, T. L. Griffiths, and C. Kemp. Theory-based bayesian models of inductive learning and reasoning. Trends in cognitive sciences, 10 0 (7): 0 309--318, 2006
2006
-
[34]
J. B. Tenenbaum, C. Kemp, T. L. Griffiths, and N. D. Goodman. How to grow a mind: Statistics, structure, and abstraction. science, 331 0 (6022): 0 1279--1285, 2011
2011
-
[35]
P. Thagard. Explanatory coherence. Behavioral and brain sciences, 12 0 (3): 0 435--467, 1989
1989
-
[36]
P. Thagard. Conceptual Revolutions. Princeton University Press, 1992. URL http://www.jstor.org/stable/j.ctv36zq4g
1992
-
[37]
C. Xiao, P. Zhang, X. Han, G. Xiao, Y. Lin, Z. Zhang, Z. Liu, and M. Sun. Inf LLM : Training-free long-context extrapolation for LLM s with an efficient context memory. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=bTHFrqhASY
2024
-
[38]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Y. Yamada, R. T. Lange, C. Lu, S. Hu, C. Lu, J. Foerster, J. Clune, and D. Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025. URL https://arxiv.org/abs/2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
C. Yang, X. Wang, Y. Lu, H. Liu, Q. V. Le, D. Zhou, and X. Chen. Large language models as optimizers. In International Conference on Learning Representations, 2024
2024
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.