Occlusion-Robust Multi-Object Decoupling for Physics-Based Robotic Interaction
Pith reviewed 2026-07-01 06:57 UTC · model grok-4.3
The pith
Joint score distillation sampling reconstructs complete multi-object 3D models from occluded sparse views without masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
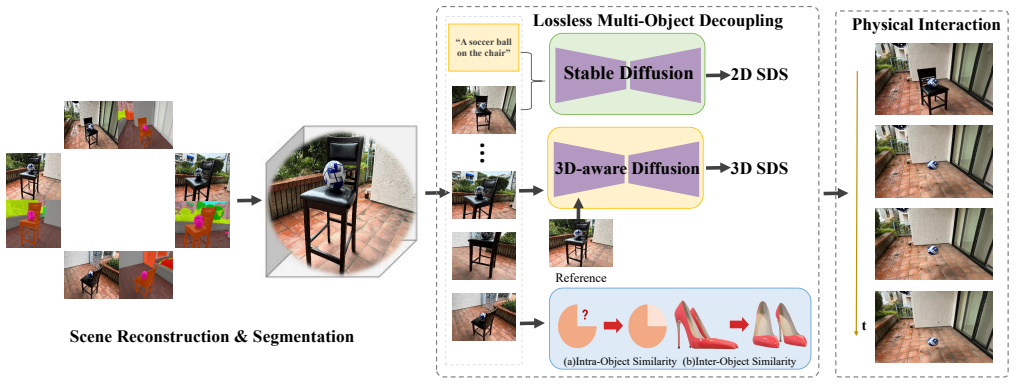
Formulating multi-object decoupling as a sparse-view reconstruction problem and solving it via joint SDS with 2D/3D diffusion priors and geometry-aware priors produces complete, simulation-ready 3D objects from fragmented geometries without requiring manual masks.
What carries the argument
joint Score Distillation Sampling (SDS) process that integrates reference-view supervision with novel-view synthesis guided by 2D and 3D diffusion priors, augmented by intra-object and inter-object similarity priors
If this is right
- Objects reconstructed this way can be dropped directly into MPM simulators for physically plausible robotic interactions.
- The same pipeline works on synthetic, robotic-arm, and real-world image sets without mask annotation.
- Coarse SAM2 partitions become sufficient starting points once the SDS stage is applied.
- Texture fidelity and geometric completeness are achieved simultaneously through the combined 2D/3D priors.
Where Pith is reading between the lines
- The method may allow 3D scene capture with fewer cameras or wider baselines than current multi-view pipelines require.
- If the priors remain effective at higher object counts, the approach could scale to crowded indoor scenes.
- Removing the mask requirement could shorten the pipeline from raw video to interactive digital twin.
Load-bearing premise
The joint SDS process together with 2D/3D diffusion priors and geometry-aware similarity terms can enforce both texture fidelity and 3D consistency on the fragmented pieces coming from coarse instance partitions.
What would settle it
Run MPM simulations on the output objects versus ground-truth objects and check whether the predicted trajectories and contact forces match within measurement error on the robotic and real-world test sequences.
Figures





read the original abstract
We propose a mask-free method for lossless multi-object 3D reconstruction from sparse and occluded real-world views, enabling physically plausible robotic interaction via Material Point Method (MPM) simulation. Our key insight is that object coupling stems from occlusion and limited viewpoints, which we address by formulating multi-object decoupling as a sparse-view reconstruction problem. Using 3D Gaussian Splatting as base representation, we first obtain coarse instance partitions with a SAM2-trained segmentation field. Rather than relying on masks, we reconstruct fragmented geometries by leveraging a joint Score Distillation Sampling (SDS) process, which integrates reference-view supervision with novel-view synthesis guided by 2D and 3D diffusion priors to enforce both texture fidelity and 3D consistency. Furthermore, we incorporate geometry-aware priors such as intra-object and inter-object similarity to regularize geometric reasoning. Experimental results demonstrate that our method produces complete, simulation-ready 3D objects without requiring manual masks, enabling realistic dynamic interactions on both synthetic, robotic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a mask-free method for multi-object 3D reconstruction from sparse and occluded views. It uses 3D Gaussian Splatting as the base representation, obtains coarse instance partitions via a SAM2-trained segmentation field, and reconstructs fragmented geometries via a joint Score Distillation Sampling (SDS) process that combines reference-view supervision with novel-view synthesis guided by 2D and 3D diffusion priors plus geometry-aware intra- and inter-object similarity priors. The resulting complete objects are intended for Material Point Method (MPM) simulation to enable realistic robotic interactions, with claims of success on synthetic, robotic, and real-world datasets without manual masks.
Significance. If the joint SDS process and geometry-aware priors reliably complete fragmented geometries into simulation-ready, 3D-consistent objects, the work would offer a practical advance for mask-free reconstruction pipelines that directly support physics-based robotic manipulation, extending established diffusion-prior techniques to multi-object decoupling.
major comments (1)
- [Abstract] Abstract: the central claim that 'experimental results demonstrate that our method produces complete, simulation-ready 3D objects' is unsupported because the abstract (and the provided manuscript description) contains no quantitative results, baselines, error metrics, ablation studies, or validation details; without these, the soundness of the joint SDS + geometry-prior pipeline cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experimental results demonstrate that our method produces complete, simulation-ready 3D objects' is unsupported because the abstract (and the provided manuscript description) contains no quantitative results, baselines, error metrics, ablation studies, or validation details; without these, the soundness of the joint SDS + geometry-prior pipeline cannot be assessed.
Authors: We agree that the abstract is concise and omits specific numerical results, which limits immediate assessment of the pipeline. The full manuscript (Section 4) contains quantitative evaluations including baseline comparisons, reconstruction error metrics (e.g., Chamfer distance, PSNR), ablation studies on the intra-/inter-object priors and joint SDS, and success rates for MPM simulation across synthetic, robotic, and real-world datasets. To directly support the central claim and improve readability, we will revise the abstract to incorporate key quantitative highlights from the experiments. revision: yes
Circularity Check
No significant circularity; derivation relies on external priors
full rationale
The paper describes a pipeline starting from 3D Gaussian Splatting as base representation, coarse partitions via a SAM2-trained field, then joint SDS integrating reference supervision with 2D/3D diffusion priors plus intra/inter-object similarity regularizers. These components are drawn from established external literature rather than defined in terms of the target output or fitted on the evaluation data and relabeled as predictions. No equations, self-citations, or uniqueness theorems are shown reducing the central reconstruction-to-MPM claim to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 3D Gaussian Splatting serves as an effective base representation for object geometries
- domain assumption Diffusion priors can guide novel-view synthesis for 3D consistency
Reference graph
Works this paper leans on
-
[1]
Interactive learning of physical object properties through robot manipulation and database of object measure- ments,
Andrej Kruzliak, Jiri Hartvich, Shubhan P Patni, Lukas Rustler, Jan Kristof Behrens, Fares J Abu-Dakka, Krystian Mikolajczyk, Ville Kyrki, and Matej Hoffmann, “Interactive learning of physical object properties through robot manipulation and database of object measure- ments,” inIROS, 2024, pp. 7596–7603
2024
-
[2]
Manigaussian: Dynamic gaussian splatting for multi- task robotic manipulation,
Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang, “Manigaussian: Dynamic gaussian splatting for multi- task robotic manipulation,” inECCV, 2024, pp. 349–366
2024
-
[3]
Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid representation,
Haozhe Lou, Yurong Liu, Yike Pan, Yiran Geng, Jianteng Chen, Wenlong Ma, Chenglong Li, Lin Wang, Hengzhen Feng, Lu Shi, et al., “Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid representation,” inICRA, 2025, pp. 15379–15386
2025
-
[4]
Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality,
Ying Jiang, Chang Yu, Tianyi Xie, Xuan Li, Yutao Feng, Huamin Wang, Minchen Li, Henry Lau, Feng Gao, Yin Yang, et al., “Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality,” inACM SIGGRAPH, 2024, pp. 1–1
2024
-
[5]
Live-gs: Llm powers interactive vr by enhancing gaussian splatting,
Haotian Mao, Zhuoxiong Xu, Siyue Wei, Yule Quan, Nianchen Deng, and Xubo Yang, “Live-gs: Llm powers interactive vr by enhancing gaussian splatting,” inIEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 2025, pp. 1234–1235
2025
-
[6]
Wonderworld: Interactive 3d scene generation from a single image,
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T Freeman, and Jiajun Wu, “Wonderworld: Interactive 3d scene generation from a single image,” inCVPR, 2025, pp. 5916–5926
2025
-
[7]
Physgen: Rigid-body physics-grounded image-to-video generation,
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang, “Physgen: Rigid-body physics-grounded image-to-video generation,” in ECCV, 2024, pp. 360–378
2024
-
[8]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu, “Physctrl: Generative physics for con- trollable and physics-grounded video generation,”arXiv preprint arXiv:2509.20358, 2025
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai, “Animatediff: An- imate your personalized text-to-image diffusion models without specific tuning,”arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
SAM3D-Phys: Towards Multi-Object Interactive Simulation in Real World
Xin Dong, Weijian Deng, Lihan Zhang, Tianru Dai, Wenfeng Deng, and Yansong Tang, “Sam3d-phys: Towards multi-object interactive simulation in real world,”arXiv preprint arXiv:2605.30239, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics,
Tianyi Xie, Zeshun Zong, Yuxing Qiu, and et al., “Physgaussian: Physics-integrated 3d gaussians for generative dynamics,” inCVPR, 2024, pp. 4389–4398
2024
-
[12]
Physdreamer: Physics-based interaction with 3d objects via video generation,
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, and et al., “Physdreamer: Physics-based interaction with 3d objects via video generation,” in ECCV, 2024, pp. 388–406
2024
-
[13]
Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation,
Zhuoman Liu, Weicai Ye, Yan Luximon, Pengfei Wan, and Di Zhang, “Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation,” inCVPR, 2025, pp. 11016–11025
2025
-
[14]
Omniphysgs: 3d constitutive gaussians for general physics-based dynamics genera- tion,
Yuchen Lin, Chenguo Lin, Jianjin Xu, and Yadong Mu, “Omniphysgs: 3d constitutive gaussians for general physics-based dynamics genera- tion,”ICLR, 2025
2025
-
[15]
Gaussian-informed con- tinuum for physical property identification and simulation,
Junhao Cai, Yuji Yang, Weihao Yuan, Yisheng He, Zilong Dong, Liefeng Bo, Hui Cheng, and Qifeng Chen, “Gaussian-informed con- tinuum for physical property identification and simulation,”ArXiv, vol. abs/2406.14927, 2024
-
[16]
Feature splatting: Language-driven physics-based scene synthesis and editing,
Ri-Zhao Qiu, Ge Yang, Weijia Zeng, and Xiaolong Wang, “Feature splatting: Language-driven physics-based scene synthesis and editing,” arXiv preprint arXiv:2404.01223, 2024
-
[17]
3d gaussian splatting for real-time radiance field rendering.,
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis, “3d gaussian splatting for real-time radiance field rendering.,” ACM TOG, vol. 42, no. 4, pp. 139–1, 2023
2023
-
[18]
Dreamphysics: Learning physics- based 3d dynamics with video diffusion priors,
Tianyu Huang, Haoze Zhang, Yihan Zeng, Zhilu Zhang, Hui Li, Wang- meng Zuo, and Rynson WH Lau, “Dreamphysics: Learning physics- based 3d dynamics with video diffusion priors,” inAAAI, 2025, vol. 39, pp. 3733–3741
2025
-
[19]
O2-recon: completing 3d reconstruction of occluded objects in the scene with a pre-trained 2d diffusion model,
Yubin Hu, Sheng Ye, Wang Zhao, Matthieu Lin, Yuze He, Yu-Hui Wen, Ying He, and Yong-Jin Liu, “O2-recon: completing 3d reconstruction of occluded objects in the scene with a pre-trained 2d diffusion model,” inAAAI, 2024, vol. 38, pp. 2285–2293
2024
-
[21]
Decoupledgaussian: Object-scene decoupling for physics-based interaction,
Miaowei Wang, Yibo Zhang, Weiwei Xu, Rui Ma, Changqing Zou, and Daniel Morris, “Decoupledgaussian: Object-scene decoupling for physics-based interaction,” inCVPR, 2025, pp. 11361–11372
2025
-
[22]
Physically guided generative adversarial network for holographic 3d content generation from multi- view light field,
Yunhui Zeng, Zhenwei Long, Yawen Qiu, Shiyi Wang, Junjie Wei, Xin Jin, Hongkun Cao, and Zhiheng Li, “Physically guided generative adversarial network for holographic 3d content generation from multi- view light field,”IEEE JETCAS, 2024
2024
-
[23]
arXiv preprint arXiv:2411.12789 , year=
Haoyu Zhao, Hao Wang, Xingyue Zhao, Hao Fei, Hongqiu Wang, Chengjiang Long, and Hua Zou, “Efficient physics simulation for 3d scenes via mllm-guided gaussian splatting,”arXiv preprint arXiv:2411.12789, 2024
-
[24]
Imfine: 3d inpainting via geometry-guided multi-view refinement,
Zhihao Shi, Dong Huo, Yuhongze Zhou, Yan Min, Juwei Lu, and Xinxin Zuo, “Imfine: 3d inpainting via geometry-guided multi-view refinement,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 26694–26703
2025
-
[25]
arXiv preprint arXiv:2404.11613 , year=
Zhiheng Liu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jie Xiao, Kai Zhu, Nan Xue, Yu Liu, Yujun Shen, and Yang Cao, “Infusion: Inpainting 3d gaussians via learning depth completion from diffusion prior,”arXiv preprint arXiv:2404.11613, 2024
-
[26]
Amodal3r: Amodal 3d reconstruc- tion from occluded 2d images
Tianhao Wu, Chuanxia Zheng, Frank Guan, Andrea Vedaldi, and Tat- Jen Cham, “Amodal3r: Amodal 3d reconstruction from occluded 2d images,”arXiv preprint arXiv:2503.13439, 2025
-
[27]
Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction,
Danpeng Chen, Hai Li, Weicai Ye, Yifan Wang, Weijian Xie, Shangjin Zhai, Nan Wang, Haomin Liu, Hujun Bao, and Guofeng Zhang, “Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction,”IEEE TVCG, vol. 31, pp. 6100–6111, 2024
2024
-
[28]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall, “Dream- fusion: Text-to-3d using 2d diffusion,”ArXiv, vol. abs/2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Magic123: One image to high- quality 3d object generation using both 2d and 3d diffusion priors,
Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, Peter Wonka, Sergey Tulyakov, and Bernard Ghanem, “Magic123: One image to high- quality 3d object generation using both 2d and 3d diffusion priors,” in ICLR, 2024
2024
-
[30]
Zero-1-to-3: Zero-shot one image to 3d object,
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick, “Zero-1-to-3: Zero-shot one image to 3d object,”ICCV, pp. 9264–9275, 2023
2023
-
[31]
Fangfu Liu, Hanyang Wang, Shunyu Yao, and et al., “Physics3d: Learning physical properties of 3d gaussians via video diffusion,”ArXiv, vol. abs/2406.04338, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.