SAM3D-Phys: Towards Multi-Object Interactive Simulation in Real World
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
SAM3D-Phys recovers complete object geometry from partial scene observations to enable physics-based multi-object simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
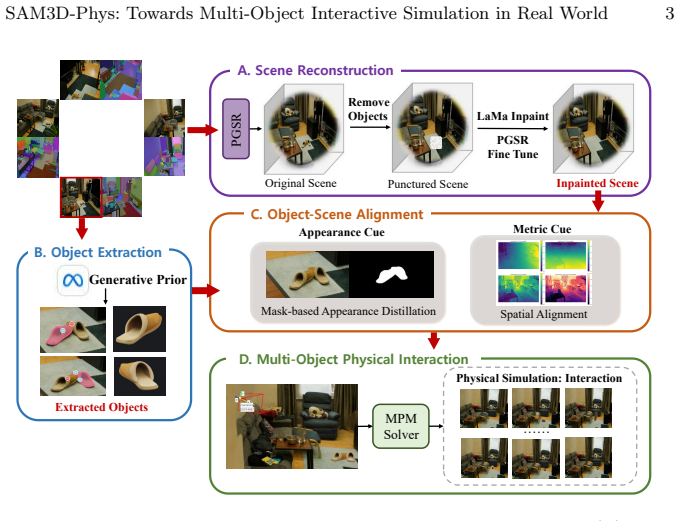
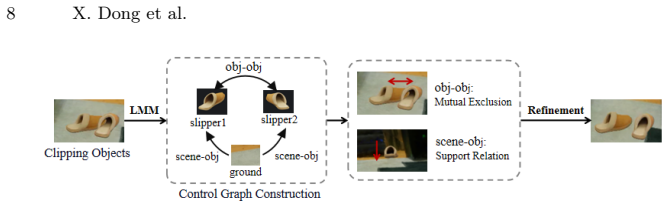
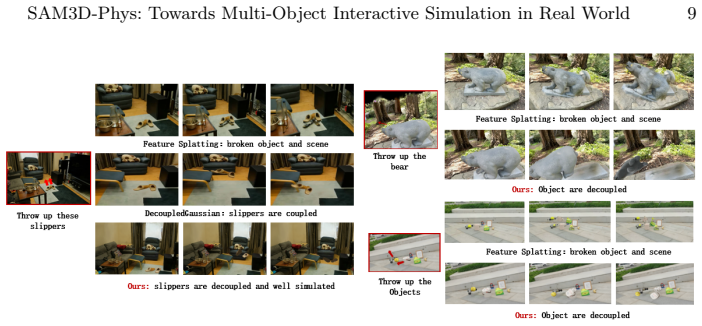
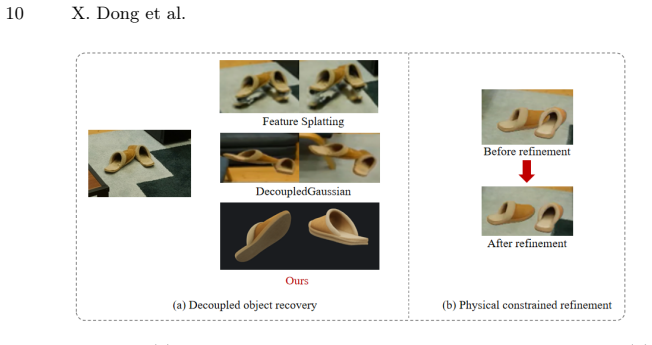
SAM3D-Phys integrates scene reconstruction from multi-view images with SAM3D to infer complete object geometry from partial observations. A physics-constrained spatial optimization algorithm iteratively aligns the recovered object to its original location, and a mask-guided appearance distillation module refines texture fidelity based on the observed images. By recovering complete object geometry and restoring its pose and appearance within the scene, SAM3D-Phys produces clean object representations suitable for physics-based simulation, enabling simultaneous and physically consistent interactive simulation of multiple objects within a reconstructed scene.
What carries the argument
SAM3D generative 3D priors combined with physics-constrained spatial optimization and mask-guided appearance distillation to restore scene-consistent object states after geometry completion.
If this is right
- Objects from real scenes become directly usable in physics engines without further manual completion.
- Multiple objects can undergo simultaneous simulation while preserving consistency with the original scene geometry.
- Interactive multi-object dynamics become possible from standard multi-view image captures alone.
- Pose and texture restoration prevents physical interactions from violating observed scene constraints.
Where Pith is reading between the lines
- The pipeline could support robotic planning by allowing simulated interactions inside scanned real environments.
- It might lower the data requirements for training models that predict physical outcomes from visual input.
- The same completion and consistency steps could extend to handling moving objects across video frames.
Load-bearing premise
The generative 3D priors produce object completions that remain consistent with the reconstructed scene after the optimization and distillation steps.
What would settle it
If completed objects still intersect scene surfaces or show appearance mismatches when rendered from new viewpoints after the two refinement steps, the claim of producing simulatable representations would be disproven.
Figures






read the original abstract
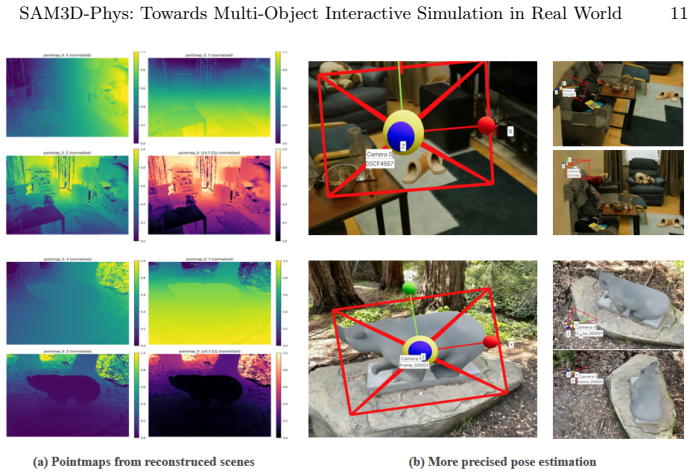
This work addresses the problem of recovering complete, simulatable object geometry from reconstructed real-world scenes, enabling physics-based interaction with objects embedded in the scene. While modern multi-view reconstruction methods can produce visually accurate environments, objects are often incomplete due to occlusions and limited observations, making them unsuitable for physics simulation. To address this limitation, we propose SAM3D-Phys, a framework that integrates scene reconstruction with generative 3D priors of SAM3D to recover physically simulatable objects. Our approach first reconstructs the scene from multi-view images to obtain scene geometry and partial observations of objects. We then leverage SAM3D to infer complete object geometry from these partial observations. To ensure that the recovered objects remain consistent with the reconstructed scene, we restore scene-consistent object states through two complementary strategies: a physics-constrained spatial optimization algorithm that iteratively aligns the recovered object to its original location, and a mask-guided appearance distillation module that refines texture fidelity based on the observed images. By recovering complete object geometry and restoring its pose and appearance within the scene, SAM3D-Phys produces clean object representations suitable for physics-based simulation, enabling simultaneous and physically consistent interactive simulation of multiple objects within a reconstructed scene. Project page: https://chnxindong.github.io/sam3d-phys/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SAM3D-Phys, a framework that reconstructs scenes from multi-view images, leverages SAM3D generative 3D priors to complete partial object geometries, and applies two per-object strategies—physics-constrained spatial optimization to restore pose and mask-guided appearance distillation to refine texture—to produce objects suitable for physics-based simulation, with the goal of enabling simultaneous, physically consistent interactive simulation of multiple objects in the reconstructed scene.
Significance. If the pipeline is shown to work, the integration of generative priors with explicit physics constraints for consistency restoration would address a practical barrier in using real-world reconstructions for simulation, with potential applications in robotics and AR. The emphasis on multi-object handling distinguishes it from single-object completion methods.
major comments (2)
- [Abstract] Abstract: the physics-constrained spatial optimization and mask-guided appearance distillation are described as operating independently per object ('iteratively aligns the recovered object to its original location'). No mechanism is specified to detect or resolve inter-object penetrations or collisions after independent completion, which directly undermines the central claim of 'physically consistent interactive simulation of multiple objects'.
- [Abstract] Abstract: the manuscript supplies no quantitative results, ablation studies, geometry or simulation error metrics, or baseline comparisons. Without these, it is impossible to assess whether the described steps support the claim that the recovered objects are suitable for physics simulation.
minor comments (1)
- [Abstract] The abstract refers to 'SAM3D' without a citation or brief description of whether it is an existing method or a component introduced here; adding this would improve clarity for readers unfamiliar with the base model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the physics-constrained spatial optimization and mask-guided appearance distillation are described as operating independently per object ('iteratively aligns the recovered object to its original location'). No mechanism is specified to detect or resolve inter-object penetrations or collisions after independent completion, which directly undermines the central claim of 'physically consistent interactive simulation of multiple objects'.
Authors: The optimization operates per object but is constrained against the full scene geometry recovered from the multi-view reconstruction, which includes all other objects; this prevents inter-object penetrations by design during pose restoration. Any residual contacts are then handled by the downstream physics simulator during interactive use. We will revise the abstract and add explicit discussion of multi-object consistency in the method section to clarify this point. revision: yes
-
Referee: [Abstract] Abstract: the manuscript supplies no quantitative results, ablation studies, geometry or simulation error metrics, or baseline comparisons. Without these, it is impossible to assess whether the described steps support the claim that the recovered objects are suitable for physics simulation.
Authors: The current manuscript emphasizes the framework and qualitative results. We agree that quantitative validation is required and will add geometry completion metrics (e.g., Chamfer distance, volumetric IoU), simulation stability and success rates, ablation studies on the physics-constrained optimization and appearance distillation, and comparisons against single-object baselines in the revised version. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper describes a pipeline that first reconstructs scene geometry from multi-view images, then applies SAM3D generative priors for object completion, followed by per-object physics-constrained spatial optimization and mask-guided appearance distillation. These are presented as sequential, independent modules without any equations, fitted parameters renamed as predictions, or self-citations that reduce the central claim to its own inputs. No load-bearing step equates outputs to inputs by construction, consistent with the default non-circular finding for method-description papers lacking quantitative derivations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Occlusion-Robust Multi-Object Decoupling for Physics-Based Robotic Interaction
A pipeline combining SAM2 segmentation, 3D Gaussian Splatting, and joint Score Distillation Sampling with 2D/3D diffusion priors reconstructs decoupled multi-object geometries from occluded sparse views for MPM simulation.
-
Occlusion-Robust Multi-Object Decoupling for Physics-Based Robotic Interaction
A new pipeline for occlusion-robust multi-object 3D reconstruction from sparse views supports physics-based robotic interaction.
Reference graph
Works this paper leans on
-
[1]
In: ICML (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: ICML (2024)
2024
-
[2]
Cai, D., Heikkilä, J., Rahtu, E.: Gs-pose: Generalizable segmentation-based 6d object pose estimation with 3d gaussian splatting (2024)
2024
-
[3]
In: CVPR
Cao, T., Luo, F., Qin, J., Jiang, Y., Wang, Y., Xiao, C.: ig-6dof: Model-free 6dof pose estimation for unseen object via iterative 3d gaussian splatting. In: CVPR. pp. 6436–6446 (2025)
2025
-
[4]
IEEE TVCG31, 6100–6111 (2024)
Chen, D., Li, H., Ye, W., Wang, Y., Xie, W., Zhai, S., Wang, N., Liu, H., Bao, H., Zhang, G.: Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction. IEEE TVCG31, 6100–6111 (2024)
2024
-
[5]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: CVPR
Deng, W., Campbell, D., Sun, C., Zhang, J., Kanitkar, S., Shaffer, M.E., Gould, S.: Pos3r: 6d pose estimation for unseen objects made easy. In: CVPR. pp. 16818– 16828 (2025)
2025
-
[7]
Feng, J., Li, X., Lin, J., Liu, J., Liu, G., Lou, W., Ma, S., Shi, G., Wang, Q., Wang, J., et al.: Seed3d 1.0: From images to high-fidelity simulation-ready 3d assets (2025)
2025
-
[8]
In: CVPR
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Aytar, Y., Rubinstein, M., Sun, C., et al.: Motion prompting: Controlling video generation with motion trajectories. In: CVPR. pp. 1–12 (2025)
2025
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
LRM: Large Reconstruction Model for Single Image to 3D
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
WorldAct: Activating Monolithic 3D Worlds into Interactive-Ready Object-Centric Scenes
Hu, J., Guo, J., Cen, J., Yang, C., Li, S., Shen, W.: Worldact: Activating monolithic 3d worlds into interactive-ready object-centric scenes. arXiv preprint arXiv:2605.15843 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
ACM Transactions on Graphics (TOG)37(4), 1–14 (2018)
Hu, Y., Fang, Y., Ge, Z., Qu, Z., Zhu, Y., Pradhana, A., Jiang, C.: A moving least squares material point method with displacement discontinuity and two-way rigid body coupling. ACM Transactions on Graphics (TOG)37(4), 1–14 (2018)
2018
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Hu, Y., Ye, S., Zhao, W., Lin, M., He, Y., Wen, Y.H., He, Y., Liu, Y.J.: Oˆ 2-recon: Completing3dreconstructionofoccludedobjectsinthescenewithapre-trained2d diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 2285–2293 (2024)
2024
-
[14]
In: AAAI
Hu, Y., Ye, S., Zhao, W., Lin, M., He, Y., Wen, Y.H., He, Y., Liu, Y.J.: O2-recon: completing 3d reconstruction of occluded objects in the scene with a pre-trained 2d diffusion model. In: AAAI. vol. 38, pp. 2285–2293 (2024)
2024
-
[15]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Huang, T., Zhang, H., Zeng, Y., Zhang, Z., Li, H., Zuo, W., Lau, R.W.: Dream- physics: Learning physics-based 3d dynamics with video diffusion priors. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3733–3741 (2025)
2025
-
[16]
In: ACM SIGGRAPH
Jiang, Y., Yu, C., Xie, T., Li, X., Feng, Y., Wang, H., Li, M., Lau, H., Gao, F., Yang, Y., et al.: Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. In: ACM SIGGRAPH. pp. 1–1 (2024) 16 X. Dong et al
2024
-
[17]
ACM TOG42(4), 139–1 (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM TOG42(4), 139–1 (2023)
2023
-
[18]
In: IROS
Kruzliak, A., Hartvich, J., Patni, S.P., Rustler, L., Behrens, J.K., Abu-Dakka, F.J., Mikolajczyk, K., Kyrki, V., Hoffmann, M.: Interactive learning of physical object properties through robot manipulation and database of object measurements. In: IROS. pp. 7596–7603 (2024)
2024
-
[19]
In: CoRL (2022)
Labbé, Y., Manuelli, L., Mousavian, A., Tyree, S., Birchfield, S., Tremblay, J., Carpentier, J., Aubry, M., Fox, D., Sivic, J.: Megapose: 6d pose estimation of novel objects via render & compare. In: CoRL (2022)
2022
-
[20]
arXiv preprint arXiv:2509.07920 (2025)
Li, A., Liu, J., Zhu, Y., Tang, Y.: Scorehoi: Physically plausible reconstruc- tion of human-object interaction via score-guided diffusion. arXiv preprint arXiv:2509.07920 (2025)
-
[21]
arXiv preprint arXiv:2303.05512 (2023)
Li, X., Qiao, Y.L., Chen, P.Y., Jatavallabhula, K.M., Lin, M., Jiang, C., Gan, C.: Pac-nerf: Physics augmented continuum neural radiance fields for geometry- agnostic system identification. arXiv preprint arXiv:2303.05512 (2023)
-
[22]
In: CVPR
Li, Z., Tucker, R., Snavely, N., Holynski, A.: Generative image dynamics. In: CVPR. pp. 24142–24153 (2024)
2024
-
[23]
ICLR (2025)
Lin, Y., Lin, C., Xu, J., Mu, Y.: Omniphysgs: 3d constitutive gaussians for general physics-based dynamics generation. ICLR (2025)
2025
-
[24]
Liu,F.,Wang,H.,Yao,S.,Zhang,S.,Zhou,J.,Duan,Y.:Physics3d:Learningphys- ical properties of 3d gaussians via video diffusion. arXiv preprint arXiv:2406.04338 (2024)
-
[25]
In: ECCV
Liu, S., Ren, Z., Gupta, S., Wang, S.: Physgen: Rigid-body physics-grounded image-to-video generation. In: ECCV. pp. 360–378 (2024)
2024
-
[26]
In: CVPR
Liu, Z., Ye, W., Luximon, Y., Wan, P., Zhang, D.: Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation. In: CVPR. pp. 11016–11025 (2025)
2025
-
[27]
In: ICRA
Lou, H., Liu, Y., Pan, Y., Geng, Y., Chen, J., Ma, W., Li, C., Wang, L., Feng, H., Shi, L., et al.: Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid representation. In: ICRA. pp. 15379–15386 (2025)
2025
-
[28]
In: ECCV
Lu, G., Zhang, S., Wang, Z., Liu, C., Lu, J., Tang, Y.: Manigaussian: Dynamic gaussian splatting for multi-task robotic manipulation. In: ECCV. pp. 349–366 (2024)
2024
-
[29]
In: IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)
Mao, H., Xu, Z., Wei, S., Quan, Y., Deng, N., Yang, X.: Live-gs: Llm powers interactive vr by enhancing gaussian splatting. In: IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW). pp. 1234–1235 (2025)
2025
-
[30]
CACM 65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. CACM 65(1), 99–106 (2021)
2021
-
[31]
Feature splatting: Language-driven physics-based scene synthesis and editing,
Qiu, R.Z., Yang, G., Zeng, W., Wang, X.: Feature splatting: Language-driven physics-based scene synthesis and editing. arXiv preprint arXiv:2404.01223 (2024)
-
[32]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
arXiv preprint arXiv:2109.07161 (2021)
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A., Ashukha, A., Silvestrov, A., Kong, N., Goka, H., Park, K., Lempitsky, V.: Resolution-robust large mask inpainting with fourier convolutions. arXiv preprint arXiv:2109.07161 (2021) SAM3D-Phys: Towards Multi-Object Interactive Simulation in Real World 17
-
[35]
48550/arXiv.2402.05054,https://arxiv.org/abs/2402.05054
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi- view gaussian model for high-resolution 3d content creation. arXiv preprint arXiv:2402.05054 (2024)
-
[36]
Team, T.H.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation (2025)
2025
-
[37]
Wang, C., Chen, C., Huang, Y., Dou, Z., Liu, Y., Gu, J., Liu, L.: Physctrl: Genera- tive physics for controllable and physics-grounded video generation. arXiv preprint arXiv:2509.20358 (2025)
-
[38]
In: CVPR
Wang, M., Zhang, Y., Xu, W., Ma, R., Zou, C., Morris, D.: Decoupledgaussian: Object-scene decoupling for physics-based interaction. In: CVPR. pp. 11361–11372 (2025)
2025
-
[40]
Wu, T., Zheng, C., Guan, F., Vedaldi, A., Cham, T.J.: Amodal3r: Amodal 3d reconstruction from occluded 2d images (2025)
2025
-
[41]
Amodal3r: Amodal 3d reconstruc- tion from occluded 2d images
Wu, T., Zheng, C., Guan, F., Vedaldi, A., Cham, T.J.: Amodal3r: Amodal 3d reconstruction from occluded 2d images. arXiv preprint arXiv:2503.13439 (2025)
-
[42]
NeurIPS38, 32501–32524 (2026)
Xia, H., Lin, C.H., Hsu, H.Y., Leboutet, Q., Gao, K., Paulitsch, M., Ummenhofer, B.,Wang,S.:Holoscene:Simulation-readyinteractive3dworldsfromasinglevideo. NeurIPS38, 32501–32524 (2026)
2026
-
[43]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21469–21480 (2025)
2025
-
[45]
In: CVPR
Xie, T., Zong, Z., Qiu, Y., et al.: Physgaussian: Physics-integrated 3d gaussians for generative dynamics. In: CVPR. pp. 4389–4398 (2024)
2024
-
[46]
In: Proceedings of the CVPR
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language- aware vision transformer for referring image segmentation. In: Proceedings of the CVPR. pp. 18155–18165 (2022)
2022
-
[47]
In: CVPR
Yu, H.X., Duan, H., Herrmann, C., Freeman, W.T., Wu, J.: Wonderworld: Inter- active 3d scene generation from a single image. In: CVPR. pp. 5916–5926 (2025)
2025
-
[48]
In: ECCV
Zhang, T., Yu, H.X., Wu, R., et al.: Physdreamer: Physics-based interaction with 3d objects via video generation. In: ECCV. pp. 388–406 (2024)
2024
-
[49]
Zhang, X., Chen, Y., Fang, Y., Qu, W., Huang, H., Zhang, C., Xu, F., Li, X.: Telephysics: Physics-grounded multi-object scene generation from a single image with real-time interaction (2026),https://arxiv.org/abs/2605.20290 18 X. Dong et al. Supplementary Material A Zoomed-in Comparisons with Baselines To better highlight the differences between our metho...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.