Fast Enough to Act: Spatio-Temporal Visual Token Merging for Low-Latency Robotic VLMs and VLAs
Pith reviewed 2026-06-30 07:22 UTC · model grok-4.3
The pith
ST-Merge fuses redundant visual tokens across 3D space and time to deliver large inference speedups in robotic VLMs and VLAs while preserving task success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
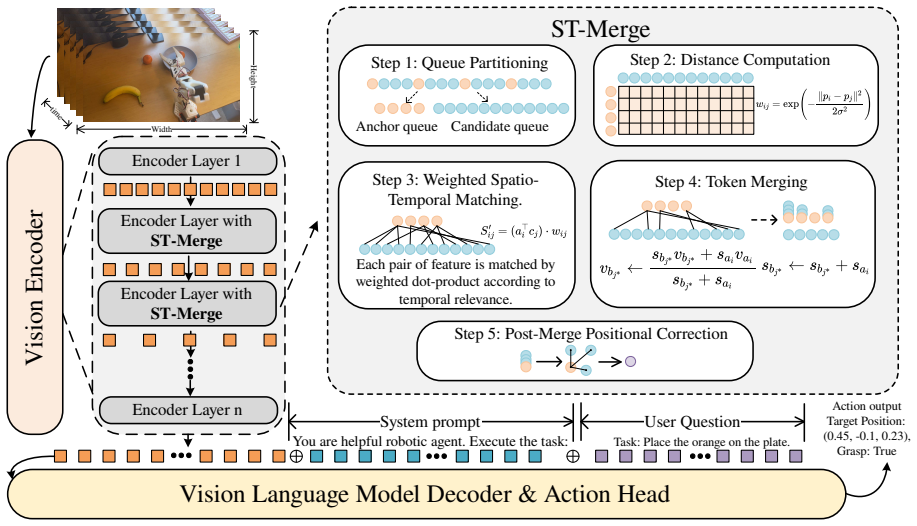
ST-Merge is a training-free framework that fuses redundant tokens during visual encoding by explicitly constructing 3D spatiotemporal coordinates, employing multi-queue parallel matching and weighted aggregation for geometrically consistent fusion across frames, and introducing a post-merge positional correction that dynamically re-evaluates the rotational position code of the weighted centroid to eliminate spatial deviation and maintain the high-precision spatial awareness required for dexterous robotic operation.
What carries the argument
Multi-queue parallel matching on 3D spatiotemporal coordinates combined with weighted-centroid positional correction after merging
If this is right
- On Qwen2.5-VL for video QA, the method produces a 2 times inference speedup with only a 1 percent loss in precision.
- On the π0.5 VLA policy at 1024 by 1024 resolution, it produces an 8.3 times speedup while matching the baseline task success rate.
- The framework operates without any additional training and can be inserted into existing visual encoders.
- At lower resolutions the accuracy impact remains small.
- High-resolution inputs become practical for real-time robotic policies that previously required downsampling.
Where Pith is reading between the lines
- If the spatial correction works reliably, the same merging logic could support longer video sequences or multi-camera inputs without proportional compute growth.
- The technique might combine with other efficiency methods such as quantization to produce further latency reductions in deployed systems.
- Similar coordinate-based merging could be tested on non-robotic real-time vision tasks that also suffer from token overload.
Load-bearing premise
That fusing tokens via similarity in 3D spatiotemporal coordinates and correcting positions with the weighted centroid will not remove or distort the spatial relationships needed for accurate robotic actions.
What would settle it
A controlled experiment showing a clear drop in success rate on a fine-grained manipulation task when ST-Merge is applied at 1024 by 1024 resolution compared with the unmerged baseline at identical resolution.
Figures



read the original abstract
Vision-language models and vision-language action models endow the robot with unprecedented capabilities. However, the input of video and high-resolution images yields a massive number of visual tokens, leading to extremely high inference latency and severely hindering the robot's real-time control. To break through this computational bottleneck, we propose ST-Merge, a plug-and-play, training-free framework that efficiently fuses redundant tokens directly during the visual encoding phase. By explicitly constructing 3D spatiotemporal coordinates, it employs a multi-queue parallel matching and weighted aggregation mechanism to achieve efficient and geometrically consistent fusion of redundant tokens across frames. In addition, we introduce a post-merge positional correction mechanism that effectively eliminates spatial deviation caused by merging by dynamically re-evaluating the rotational position code of the weighted centroid of the vision token, thereby ensuring the high-precision spatial awareness required for dexterous operation. In the Video Question Answering task on the mainstream VLM, Qwen2.5-VL, ST-Merge achieves a 2$\times$ inference speedup with only a tiny 1\% loss in precision. When deployed on the $\pi_{0.5}$ VLA policy, ST-Merge achieves an 8.3$\times$ speedup at 1024 $\times$ 1024 resolution and matches the baseline success rate at this high-resolution setting. At lower resolutions, it introduces a small drop in accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ST-Merge, a training-free, plug-and-play token-merging framework for VLMs and VLAs. It builds explicit 3D spatiotemporal coordinates, performs multi-queue parallel matching with weighted aggregation to fuse redundant visual tokens during encoding, and applies a post-merge positional correction that recomputes rotational position encodings from the weighted centroid of merged tokens. On Qwen2.5-VL video QA it reports 2× speedup with 1% precision loss; on the π0.5 VLA policy at 1024×1024 resolution it reports 8.3× speedup while matching baseline success rate (with a small accuracy drop at lower resolutions).
Significance. If the empirical claims and the spatial-preservation argument hold under rigorous verification, the method would directly address the latency barrier that currently prevents high-resolution visual input from being used in real-time robotic VLAs, offering a drop-in acceleration technique without retraining.
major comments (2)
- [Abstract / §4] Abstract and §4 (experimental claims): the headline results (8.3× speedup and matched success rate on π0.5 at 1024×1024; 2× speedup with 1% loss on Qwen2.5-VL) are stated without any description of baselines, number of trials, variance, error bars, or ablation studies. This absence prevents verification that the observed parity is attributable to the post-merge correction rather than task-specific tolerance.
- [Method (post-merge correction)] Method description (post-merge positional correction): the central claim that re-evaluating the rotational position code from the weighted centroid “eliminates spatial deviation” and preserves “high-precision spatial awareness required for dexterous operation” is load-bearing for the robotic application, yet the manuscript provides neither per-token position-error statistics nor an ablation that disables only the correction step. Without these, it is impossible to assess whether sub-pixel shifts introduced by averaging affect fine-grained control policies.
minor comments (2)
- [Method] Notation for the 3D coordinate construction and the multi-queue matching algorithm should be formalized with explicit equations rather than prose descriptions to allow reproducibility.
- [Abstract] The abstract states “matches the baseline success rate at this high-resolution setting” but does not specify the exact success-rate values or the number of evaluation episodes; these numbers should appear in the main text or a table.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to provide the requested verification.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (experimental claims): the headline results (8.3× speedup and matched success rate on π0.5 at 1024×1024; 2× speedup with 1% loss on Qwen2.5-VL) are stated without any description of baselines, number of trials, variance, error bars, or ablation studies. This absence prevents verification that the observed parity is attributable to the post-merge correction rather than task-specific tolerance.
Authors: We agree that the current experimental reporting lacks these details. In the revised manuscript we will expand §4 to specify the baselines, number of trials, variance measures with error bars, and include an ablation isolating the post-merge correction to confirm its contribution to the observed parity. revision: yes
-
Referee: [Method (post-merge correction)] Method description (post-merge positional correction): the central claim that re-evaluating the rotational position code from the weighted centroid “eliminates spatial deviation” and preserves “high-precision spatial awareness required for dexterous operation” is load-bearing for the robotic application, yet the manuscript provides neither per-token position-error statistics nor an ablation that disables only the correction step. Without these, it is impossible to assess whether sub-pixel shifts introduced by averaging affect fine-grained control policies.
Authors: We acknowledge that the manuscript currently lacks per-token position-error statistics and an ablation disabling only the correction. The revised version will add these: position-error metrics before/after correction and an ablation removing solely the post-merge step, to quantify any effect of averaging on spatial precision and policy performance. revision: yes
Circularity Check
No circularity: empirical method with no self-referential derivations
full rationale
The paper describes ST-Merge as a training-free algorithmic framework using explicit 3D spatiotemporal coordinate construction, multi-queue matching, weighted aggregation, and post-merge centroid correction. No equations, fitted parameters, or derivations appear in the abstract that reduce predictions to inputs by construction. Reported speedups and success rates are framed as direct empirical measurements on Qwen2.5-VL and π0.5, not as quantities defined from self-citations or ansatzes. No load-bearing self-citation chains or uniqueness theorems are invoked. The approach is self-contained as an engineering proposal evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Ka- dian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al., “Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang et al., “Qwen2. 5-vl technical report,” arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y. Li, Z. Liu et al., “Llava-onevision: Easy visual task transfer,” arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Impedancegpt: Vlm-driven impedance control of swarm of mini-drones for intelligent navigation in dynamic environment,
F. Batool, Y. Yaqoot, M. Zafar, R. A. Khan, M. H. Khan, A. Fedoseev, and D. Tsetserukou, “Impedancegpt: Vlm-driven impedance control of swarm of mini-drones for intelligent navigation in dynamic environment,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2592–2597
2025
-
[8]
Rod-vlm: A framework of real-time robotic perception, reasoning and manipulation,
Y. Zhu, X. Wang, F. Yu, T. Lei, and Y. Sun, “Rod-vlm: A framework of real-time robotic perception, reasoning and manipulation,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 866–873
2025
-
[9]
On the safety concerns of deploying llms/vlms in robotics: Highlighting the risks and vulnerabilities,
X. Wu, R. Xian, T. Guan, J. Liang, S. Chakraborty, F. Liu, B. M. Sadler, D. Manocha, and A. Bedi, “On the safety concerns of deploying llms/vlms in robotics: Highlighting the risks and vulnerabilities,” in First Vision and Language for Autonomous Driving and Robotics Workshop, 2024
2024
-
[10]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Bal- akrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. San- keti et al., “Openvla: An open-source vision-language-action model,” arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai et al., “ π0.5: a vision-language-action model with open-world generaliza- tion,” arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[13]
Video token merging for long-form video understanding,
S.-H. Lee, J. Wang, Z. Zhang, D. Fan, and X. Li, “Video token merging for long-form video understanding,” arXiv preprint arXiv:2410.23782, 2024
-
[14]
Pumer: Pruning and merging tokens for efficient vision language models,
Q. Cao, B. Paranjape, and H. Hajishirzi, “Pumer: Pruning and merging tokens for efficient vision language models,” arXiv preprint arXiv:2305.17530, 2023
-
[15]
Token Merging: Your ViT But Faster
D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference,
Z. Lin, M. Lin, L. Lin, and R. Ji, “Boosting multimodal large language models with visual tokens withdrawal for rapid inference,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 5334–5342
2025
-
[17]
An image is worth 1/2 tokens after layer 2: Plug- and-play inference acceleration for large vision-language mod- els,
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, and B. Chang, “An image is worth 1/2 tokens after layer 2: Plug- and-play inference acceleration for large vision-language mod- els,” in European Conference on Computer Vision. Springer, 2024, pp. 19–35
2024
-
[18]
Framefusion: Combining similarity and importance for video token reduction on large vision language models,
T. Fu, T. Liu, Q. Han, G. Dai, S. Yan, H. Yang, X. Ning, and Y. Wang, “Framefusion: Combining similarity and importance for video token reduction on large vision language models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22 654–22 663
2025
-
[19]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y. Zhu, C. Gao, Y. Feng, Q. Liu, Y. Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” Advances in Neural Information Processing Sys- tems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[20]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” 2023
2023
-
[21]
An advanced driving agent with the multimodal large language model for autonomous vehicles,
J. Chen and S. Lu, “An advanced driving agent with the multimodal large language model for autonomous vehicles,” in 2024 IEEE International Conference on Mobility, Operations, Services and Technologies (MOST). IEEE, 2024, pp. 1–11
2024
-
[22]
Cliport: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” in Conference on robot learning. PMLR, 2022, pp. 894–906
2022
-
[23]
Vima: General robot manipulation with multimodal prompts,
Y. Jiang, A. Gupta, Z. Zhang, G. Wang, Y. Dou, Y. Chen, L. Fei-Fei, A. Anandkumar, Y. Zhu, and L. Fan, “Vima: General robot manipulation with multimodal prompts,” in Fortieth International Conference on Machine Learning, 2023
2023
-
[24]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics,
C. H. Song, V. Blukis, J. Tremblay, S. Tyree, Y. Su, and S. Birchfield, “Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 768–15 780
2025
-
[26]
Physvlm: Enabling visual language models to understand robotic physical reachability,
W. Zhou, M. Tao, C. Zhao, H. Guo, H. Dong, M. Tang, and J. Wang, “Physvlm: Enabling visual language models to understand robotic physical reachability,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6940–6949
2025
-
[27]
Vlmpc: Vision-language model predictive control for robotic manipulation,
W. Zhao, J. Chen, Z. Meng, D. Mao, R. Song, and W. Zhang, “Vlmpc: Vision-language model predictive control for robotic manipulation,” arXiv preprint arXiv:2407.09829, 2024
-
[28]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti et al., “Smolvla: A vision-language-action model for affordable and efficient robotics,” arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” in European conference on computer vision. Springer, 2024, pp. 256–274
2024
-
[30]
Tr-dq: Time-rotation diffusion quantization,
Y. Shao, D. Lin, F. Zeng, M. Yan, M. Zhang, S. Chen, Y. Fan, Z. Yan, H. Wang, J. Guo et al., “Tr-dq: Time-rotation diffusion quantization,” arXiv preprint arXiv:2503.06564, 2025
-
[31]
Learning to merge tokens in vision transformers, 2022
C. Renggli, A. S. Pinto, N. Houlsby, B. Mustafa, J. Puigcerver, and C. Riquelme, “Learning to merge tokens in vision trans- formers,” arXiv preprint arXiv:2202.12015, 2022
-
[32]
Learned token pruning for transformers,
S. Kim, S. Shen, D. Thorsley, A. Gholami, W. Kwon, J. Hassoun, and K. Keutzer, “Learned token pruning for transformers,” in Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, 2022, pp. 784–794
2022
-
[33]
Exploring token pruning in vision state space models,
Z. Zhan, Z. Kong, Y. Gong, Y. Wu, Z. Meng, H. Zheng, X. Shen, S. Ioannidis, W. Niu, P. Zhao et al., “Exploring token pruning in vision state space models,” Advances in Neural Information Processing Systems, vol. 37, pp. 50 952–50 971, 2024
2024
-
[34]
Topv: Compatible token pruning with inference time optimization for fast and low- memory multimodal vision language model,
C. Yang, Y. Sui, J. Xiao, L. Huang, Y. Gong, C. Li, J. Yan, Y. Bai, P. Sadayappan, X. Hu et al., “Topv: Compatible token pruning with inference time optimization for fast and low- memory multimodal vision language model,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19 803–19 813
2025
-
[35]
Flashat- tention: Fast and memory-efficient exact attention with io- awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashat- tention: Fast and memory-efficient exact attention with io- awareness,” Advances in neural information processing sys- tems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[36]
arXiv preprint arXiv:2403.15388 (2024) 10
Y. Shang, M. Cai, B. Xu, Y. J. Lee, and Y. Yan, “Llava- prumerge: Adaptive token reduction for efficient large multi- modal models,” arXiv preprint arXiv:2403.15388, 2024
-
[37]
Rotary position embedding for vision transformer,
B. Heo, S. Park, D. Han, and S. Yun, “Rotary position embedding for vision transformer,” in European Conference on Computer Vision. Springer, 2024, pp. 289–305
2024
-
[38]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,” Advances in Neural Information Processing Systems, vol. 36, pp. 28 541–28 564, 2023
2023
-
[39]
Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu et al., “Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24 185– 24 198
2024
-
[40]
Roformer: Enhanced transformer with rotary position em- bedding,
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “Roformer: Enhanced transformer with rotary position em- bedding,” Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[41]
Tempme: Video temporal token merging for efficient text-video retrieval,
L. Shen, T. Hao, T. He, S. Zhao, Y. Zhang, P. Liu, Y. Bao, and G. Ding, “Tempme: Video temporal token merging for efficient text-video retrieval,” arXiv preprint arXiv:2409.01156, 2024
-
[42]
lerobot_ π0.5_base,
LeRobot, “lerobot_ π0.5_base,” https://huggingface.co/ lerobot/pi05_base, 2026, hugging Face model repository. Accessed: 2026-02-27
2026
-
[43]
A shortcut-aware video-qa benchmark for physical understanding via minimal video pairs,
B. Krojer, M. Komeili, C. Ross, Q. Garrido, K. Sinha, N. Bal- las, and M. Assran, “A shortcut-aware video-qa benchmark for physical understanding via minimal video pairs,” arXiv, 2025
2025
-
[44]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zoui- tine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github. com/huggingface/lerobot, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.