Open Problems in Constitutional Preference Reconstruction
Pith reviewed 2026-06-30 06:46 UTC · model grok-4.3
The pith
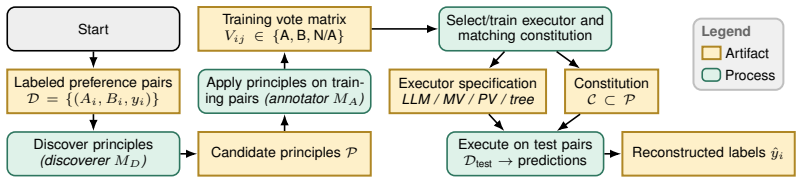
A constitution of principles is not yet an executable decision rule until paired with a specific executor and model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
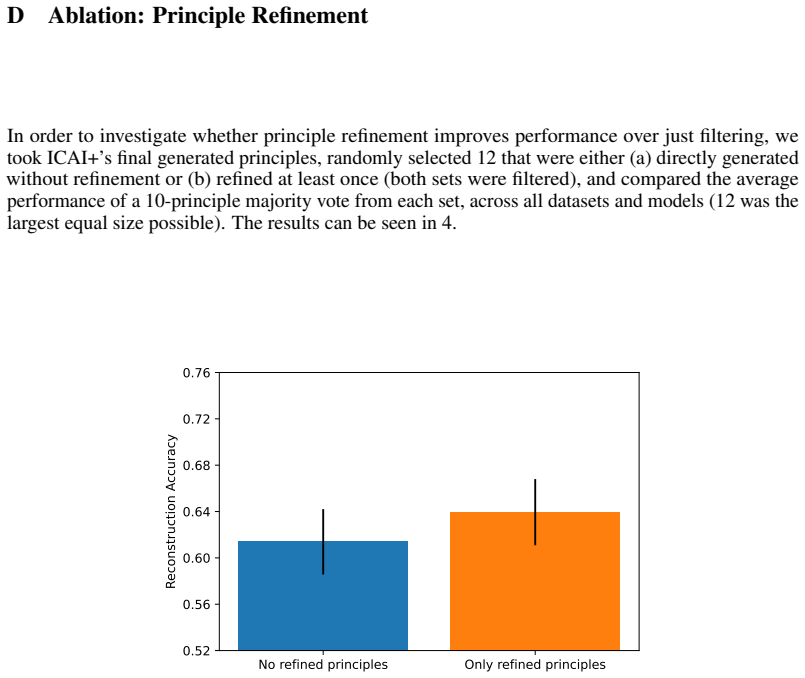
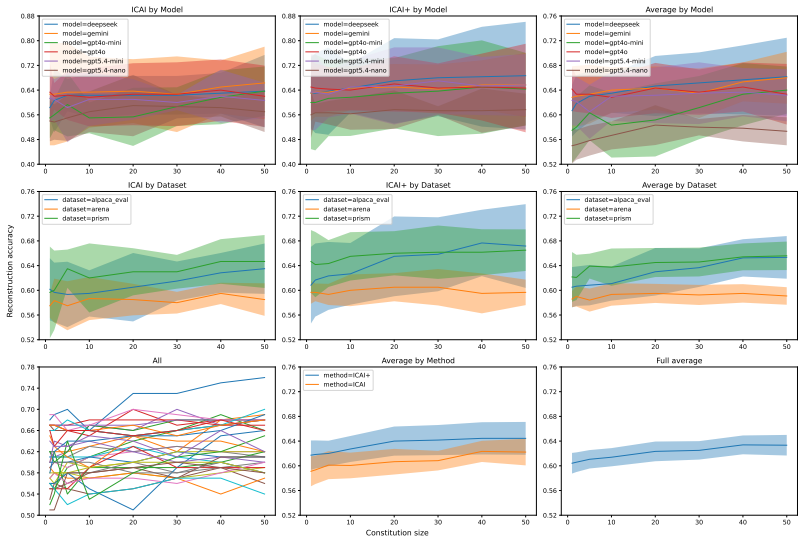
Holding principles fixed, different executors agree only 73 percent of the time and different models agree only 73 percent across models versus 81 percent within models; principle refinement improves executor agreement to 78 percent and lets transparent executors nearly match LLM-judge accuracy at 66 percent versus 67 percent.
What carries the argument
The constitution-executor system, in which a flat list of natural-language principles is combined with a concrete decision procedure such as an LLM judge or majority vote.
If this is right
- Constitutions must be tested together with their chosen executor rather than as standalone lists.
- Principle refinement can measurably reduce executor disagreement.
- Transparent executors can reach accuracy comparable to LLM judges once principles are refined.
- Constitutions produced for one model do not transfer directly to another.
Where Pith is reading between the lines
- The same composition ambiguities are likely to appear when constitutions guide multi-turn conversations or open-ended generation.
- Standardizing the executor step could reduce model-to-model inconsistency in LLM-as-judge applications.
- The observed gaps suggest that interpretability gains from constitutions are currently limited by execution details rather than principle content alone.
Load-bearing premise
The pairwise setting is sufficient to reveal the composition ambiguities that would appear in richer preference or generation tasks.
What would settle it
Measure whether executor agreement and cross-model agreement rates remain below 80 percent when the same constitutions are applied to full generation or multi-turn preference data instead of isolated pairwise choices.
Figures



read the original abstract
Pairwise preference data is widely used for training and evaluating language models (e.g., RLHF), but each datapoint records a \emph{choice}, not the rationale behind it. Methods such as Inverse Constitutional AI (ICAI) attempt to improve interpretability by compressing datasets into short ``constitutions'' of natural-language principles. We argue this framing is under-specified: a flat list of principles is not yet an executable decision rule because it leaves principle composition implicit. We use the pairwise setting as a testbed to empirically characterize three open problems in constitutional methods. First, principle quality is hard to measure: coverage and accuracy are useful but incomplete proxies for end-to-end reconstruction. Second, \emph{composition is ambiguous}: holding principles fixed, different executors (LLM judge versus majority vote) agree only $73\%$ of the time. Third, \emph{constitutions differ between LLMs}: cross-model vote agreement is $73\%$, whereas intra-model agreement is $81\%$. Across PRISM, AlpacaEval, and Chatbot Arena, we show that principle refinement (ICAI+) may be a first step towards ameliorating these problems: inter-executor agreement rises to $78\%$, and transparent executors match LLM judge accuracy ($66\%$ vs.\ $67\%$). Our results highlight that constitutions should be evaluated as \emph{constitution--executor systems}, with implications for LLMs-as-a-judge broadly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that methods like Inverse Constitutional AI for reconstructing preferences from pairwise data are under-specified because they treat constitutions as flat lists of principles without specifying composition rules. Using pairwise preference data from PRISM, AlpacaEval, and Chatbot Arena, it empirically identifies three open problems: (1) principle quality is hard to measure via coverage/accuracy alone, (2) composition is ambiguous (different executors agree only 73% of the time), and (3) constitutions are model-specific (cross-model vote agreement 73% vs. intra-model 81%). It reports that an ICAI+ refinement raises inter-executor agreement to 78% and allows transparent executors to match LLM-judge accuracy (66% vs. 67%), concluding that constitutions must be evaluated as constitution-executor systems with implications for LLMs-as-a-judge.
Significance. If the empirical characterizations hold, the work provides a useful framing of under-specification in constitutional methods and supplies direct agreement counts that demonstrate the three problems across three datasets. The explicit credit to reproducible empirical counts (no fitted parameters) and the concrete ICAI+ proposal strengthen the contribution as an exploratory identification of open problems rather than a closed solution.
major comments (2)
- [Abstract] Abstract: The central claim that pairwise data suffices as a testbed to characterize the three open problems (and thus supports evaluating constitutions as constitution-executor systems) is load-bearing for the broader implications, yet the manuscript provides no direct comparison or argument showing that the observed 73% inter-executor and cross-model gaps persist under open-ended generation, multi-criteria scoring, or non-pairwise judgments.
- [Abstract] Abstract and results sections: The reported figures (73% inter-executor agreement, 81% intra-model, 66% vs. 67% accuracy) are presented without error bars, dataset sizes per split, or details on how data splits and executor prompts were fixed in advance; this directly affects the reliability of the evidence offered for the existence and severity of the three problems.
minor comments (1)
- [Abstract] The abstract states that 'transparent executors match LLM judge accuracy' but does not define the transparent executors or their implementation in sufficient detail for readers to replicate the 66%/67% comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below. We agree that additional methodological details are required and will incorporate them. On the scope of the pairwise testbed, we will revise to avoid overclaiming generality while preserving the exploratory contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that pairwise data suffices as a testbed to characterize the three open problems (and thus supports evaluating constitutions as constitution-executor systems) is load-bearing for the broader implications, yet the manuscript provides no direct comparison or argument showing that the observed 73% inter-executor and cross-model gaps persist under open-ended generation, multi-criteria scoring, or non-pairwise judgments.
Authors: The manuscript explicitly frames pairwise preferences as a controlled testbed because this format is standard in preference modeling and RLHF pipelines. The three problems are characterized empirically within this setting, and the conclusion that constitutions should be evaluated as constitution-executor systems is drawn from the observed ambiguities in that setting. We do not provide, and do not claim to provide, direct evidence that the precise agreement gaps persist in open-ended generation or multi-criteria scoring. We will revise the abstract and discussion sections to state more precisely that the characterization applies to pairwise data and that extension to other judgment formats remains an open question. revision: partial
-
Referee: [Abstract] Abstract and results sections: The reported figures (73% inter-executor agreement, 81% intra-model, 66% vs. 67% accuracy) are presented without error bars, dataset sizes per split, or details on how data splits and executor prompts were fixed in advance; this directly affects the reliability of the evidence offered for the existence and severity of the three problems.
Authors: We agree that the absence of error bars, per-split dataset sizes, and explicit details on prompt fixation and data splits reduces the reliability assessment of the reported percentages. In the revised version we will add standard errors (or bootstrap confidence intervals) for all agreement and accuracy figures, report the exact number of preference pairs used per dataset and per split, and include a dedicated experimental-setup subsection describing how splits were constructed and how executor prompts were written and held fixed. revision: yes
Circularity Check
No circularity; empirical counts are independent measurements
full rationale
The paper reports direct empirical agreement percentages (73% inter-executor, 81% intra-model, 78% after ICAI+) between fixed executors on extracted constitutions from pairwise data across three datasets. These are straightforward observational counts with no equations, fitted parameters, or derivations that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The use of the pairwise setting is explicitly framed as a testbed for characterization rather than a self-defining premise, and the recommendation to evaluate constitution-executor systems follows from these independent measurements without tautological reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agreement percentage between two decision procedures is a meaningful proxy for composition ambiguity
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[2]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[3]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[4]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference, 2024. URL https://arxiv.org/abs/2403.04132
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models.https://github.com/tatsu-lab/alpaca_eval, 5 2023
2023
-
[6]
Loss aversion in riskless choice: A reference-dependent model.The quarterly journal of economics, 106(4):1039–1061, 1991
Amos Tversky and Daniel Kahneman. Loss aversion in riskless choice: A reference-dependent model.The quarterly journal of economics, 106(4):1039–1061, 1991
1991
-
[7]
Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research, 2023
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research, 2023
2023
-
[8]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
In- verse constitutional ai: Compressing preferences into principles
Arduin Findeis, Timo Kaufmann, Eyke Hüllermeier, Samuel Albanie, and Robert Mullins. In- verse constitutional ai: Compressing preferences into principles. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/ forum?id=9FRwkPw3Cn
2025
-
[10]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. URL https://arxiv.org/ abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 74...
-
[13]
Prometheus 2: An open source language model specialized in evaluating other language models,
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Gra- ham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source lan- guage model specialized in evaluating other language models.arXiv preprint arXiv:2405.01535, 2024. 11
-
[14]
Hannah Rose Kirk, Alexander Whitefield, Paul Rottger, Andrew M Bean, Katerina Margatina, Rafael Mosquera-Gomez, Juan Ciro, Max Bartolo, Adina Williams, He He, et al. The prism alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models.Advances in...
2024
-
[15]
Collective constitutional ai: Aligning a language model with public input
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli. Collective constitutional ai: Aligning a language model with public input. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1395–1417, 2024
2024
-
[16]
What’s In My Human Feedback? Learning Interpretable Descriptions of Preference Data, October 2025
Rajiv Movva, Smitha Milli, Sewon Min, and Emma Pierson. What’s In My Human Feedback? Learning Interpretable Descriptions of Preference Data, October 2025
2025
-
[17]
Democratic icai: Debating our way to steering principles from preferences
Kevin Kingslin, Anish Natekar, Ashutosh Ranjan, Vivek Srivastava, Savita Bhat, and Shirish Karande. Democratic icai: Debating our way to steering principles from preferences. InICLR 2026 Workshop-From Human Cognition to AI Reasoning: Models, Methods, and Applications, 2026
2026
-
[18]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5):206–215, 2019
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5):206–215, 2019
2019
-
[20]
Wadsworth International Group, 1984
Leo Breiman, Jerome H Friedman, Richard A Olshen, and Charles J Stone.Classification and Regression Trees. Wadsworth International Group, 1984
1984
-
[21]
Random forests.Machine Learning, 45:5–32, 2001
Leo Breiman. Random forests.Machine Learning, 45:5–32, 2001
2001
-
[22]
Lightgbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[23]
Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
2011
-
[24]
OpenAI. Gpt-4o system card, 2024. URLhttps://arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024
2024
-
[26]
Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https://arxiv.org/abs/ 2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 12 A Reproducibility All code and other resources required to reproduce the results in this paper is released open source and can be found athttps:/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Select the response that uses bullet points for clarity
-
[31]
Select the response that avoids unnecessary spacing in the output
-
[33]
Select the response that includes character development and progression
-
[34]
Select the response that includes more specific hashtags
-
[35]
Select the response that acknowledges historical complexity and uncertainty
-
[36]
Select the response that emphasizes mood-setting elements
-
[37]
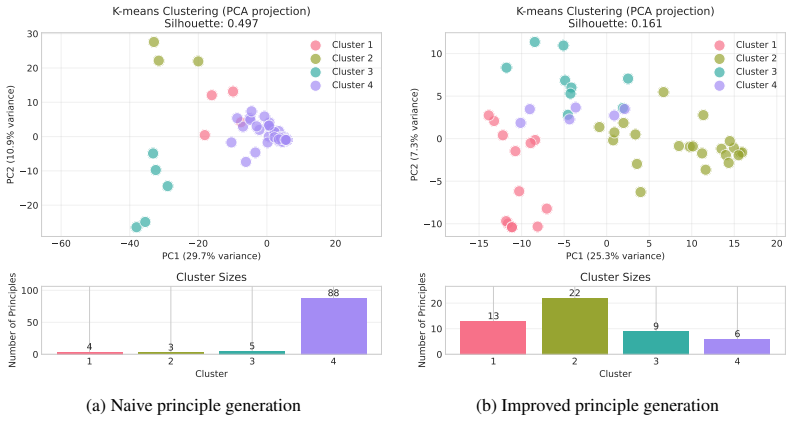
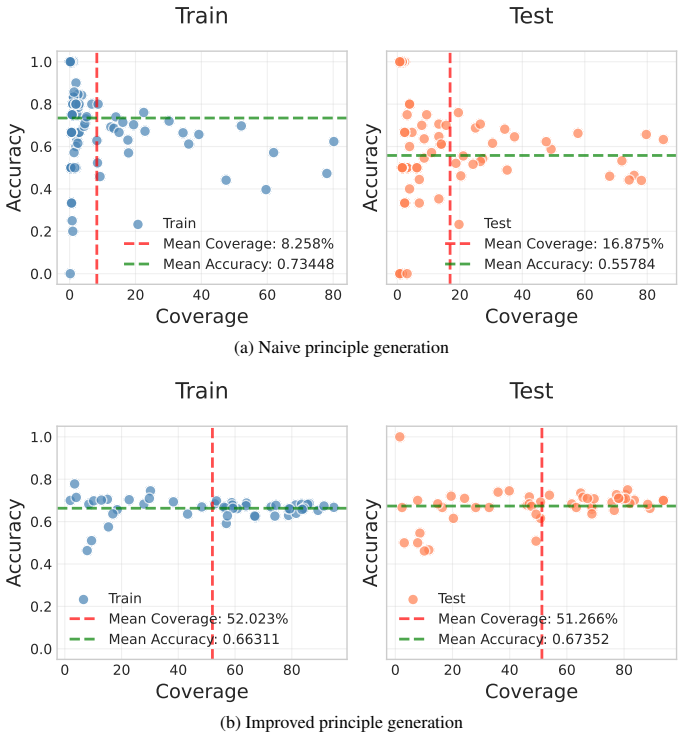
(a) Naive principle generation
Select the response that provides a concrete code example. (a) Naive principle generation
-
[39]
Select the response that provides concrete feature specifics, except when the prompt requests brevity or a simplified format
-
[40]
Select the response that provides actionable steps for implementing instructions, unless the prompt explicitly requests general concepts or product recommendations
-
[41]
Select the response that precisely follows quantitative constraints, unless it introduces factual inaccuracies or omits key elements
-
[42]
Select the response that offers precise measurements and clear instructions for reliable execution
-
[43]
Select the response that uses formatting like bullet points and numbered steps for enhanced readability
-
[44]
Select the response that correctly interprets numerical input constraints
-
[45]
Select the response that uses metaphors only when they creatively clarify or simplify complex concepts, not for straightforward factual descriptions
-
[46]
Select the response that provides accurate, actionable instructions, unless correctness of the instructions is itself the primary focus, then prioritize accuracy
-
[47]
Select the response that provides accurate and complete information, addressing all explicit sub-questions in the prompt. (b) Improved principle generation Figure 6: First 10 principles selected by Algorithm 2 from generation on AlpacaEval using DeepSeek v3.1 Chat 16 I Greedy majority vote selection compared to metric-only selection of principles This app...
-
[48]
Select the response that uses more specific and professional language
-
[49]
Select the response that is more descriptive and elaborate
-
[50]
Select the response that provides a conclusive and meaningful resolution
-
[51]
Select the response that provides detailed justification
-
[52]
Select the response that includes specific examples of benefits
-
[53]
Select the response that provides more detailed actionable steps
-
[54]
Select the response that uses clearer and more direct language
-
[55]
Select the response that includes full phrases not just words
-
[56]
Select the response that is scientifically accurate
-
[57]
(a) Naive principle generation
Select the response that uses a list format for clarity. (a) Naive principle generation
-
[58]
Select the response with correct syntax and formatting, unless exact wording or coherent narrative continuity is required
-
[59]
Select the response that conveys information accurately and completely, avoiding both unnecessary wordiness and insufficient detail
-
[60]
Select the response that provides the most correct and complete essential information, unless excessive detail obscures accuracy
-
[61]
Select the response that provides concrete examples or specific details, unless they are irrelevant, incorrect, or reduce clarity
-
[62]
Select the response that provides specific examples or actionable details unless they are incomplete, misleading, or lack sufficient context
-
[63]
Select the response that provides specific, accurate details, unless the response contains incorrect or unverified claims
-
[64]
Select the response that answers all parts of the instruction explicitly and precisely
-
[65]
Select the response that provides specific, concrete examples unless the request is hypothetical, imaginative, or emphasizes simplicity
-
[66]
Select the response that provides comprehensive detail while avoiding speculative claims, unless summarizing existing knowledge
-
[67]
explanation
Select the response that provides concrete examples or computational methods, unless brevity is requested or explanation is purely conceptual. (b) Improved principle generation Figure 7: First 10 principles selected by ICAI’s default principle quality metric (correct votes minus incorrect votes) from generation on AlpacaEval using DeepSeek v3.1 Chat Table...
-
[68]
Select the response that provides complete arguments without abrupt cutoff
-
[69]
Select the response that provides more detailed subtopics
-
[70]
Select the response that acknowledges multiple stated and unstated reasons
-
[71]
Select the response that focuses on interpersonal relationships context
-
[72]
Select the response that expresses understanding of the user’s concern
-
[73]
Select the response that follows instruction format precisely
-
[74]
Select the response that fully embodies the character’s traits
-
[75]
Select the response that covers a broader range of conflict areas
-
[76]
Select the response that includes personal fulfillment as a goal
-
[77]
Select the response that provides more detailed meal descriptions (a) DeepSeek v3.1 Chat
-
[78]
Select the response that invites further elaboration on topics
-
[79]
Select the response that provides more detailed cleaning steps
-
[80]
Select the response that avoids mentioning previous recipe failures
-
[81]
Select the response that includes practical cashflow management advice
-
[82]
Select the response that acknowledges complexity in celebrity influence
-
[83]
Select the response that acknowledges individual couple’s needs
-
[84]
Select the response that suggests regular maintenance for longevity
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.