Goku: A Million-Scale Universal Dataset and Benchmark for Instruction-Based Video Editing
Pith reviewed 2026-06-30 05:58 UTC · model grok-4.3
The pith
A 2-million-pair dataset extends video editing to multi-task and structural manipulations like subject movement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
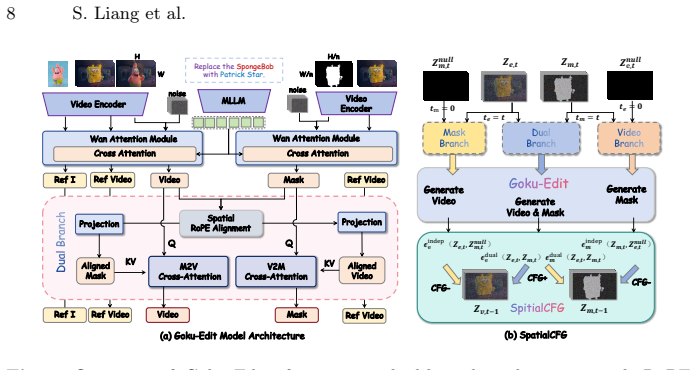
Goku supplies two million high-quality instruction-aligned video editing pairs that cover multi-task and structural manipulations, created through a decomposition pipeline with progressive filtering; Goku-Edit uses this data with an MLLM encoder and decoupled dual-branch design to achieve stronger instruction following on the accompanying Goku-Bench benchmark.
What carries the argument
The efficient data synthesis pipeline that decomposes complex edits into controllable sub-problems combined with progressive filtering, paired with Goku-Edit's decoupled dual-branch architecture using an MLLM as text encoder.
If this is right
- Models can perform precise structural edits such as controlled subject movement in response to natural language instructions.
- Instruction following accuracy in video editing rises by measurable margins across diverse tasks when trained on the new scale of data.
- Standardized evaluation becomes possible through Goku-Bench's human-verified cases and dedicated editing metrics.
- Data creation for complex editing tasks scales to millions of examples without requiring full manual annotation.
Where Pith is reading between the lines
- The dual-branch separation of structure and appearance may apply to other generative video tasks that need independent control dimensions.
- Datasets built this way could support downstream creative tools that let users specify both motion and appearance changes in one instruction.
- If the decomposition approach generalizes, similar pipelines might accelerate data collection for related domains such as 3D scene editing.
Load-bearing premise
The synthesis pipeline that decomposes edits into sub-problems and applies progressive filtering produces reliable, high-quality instruction-aligned pairs without systematic artifacts or biases.
What would settle it
A random sample of Goku pairs examined by independent human reviewers showing frequent misalignment between instructions and edited video content would falsify the reliability of the generated dataset.
Figures


read the original abstract
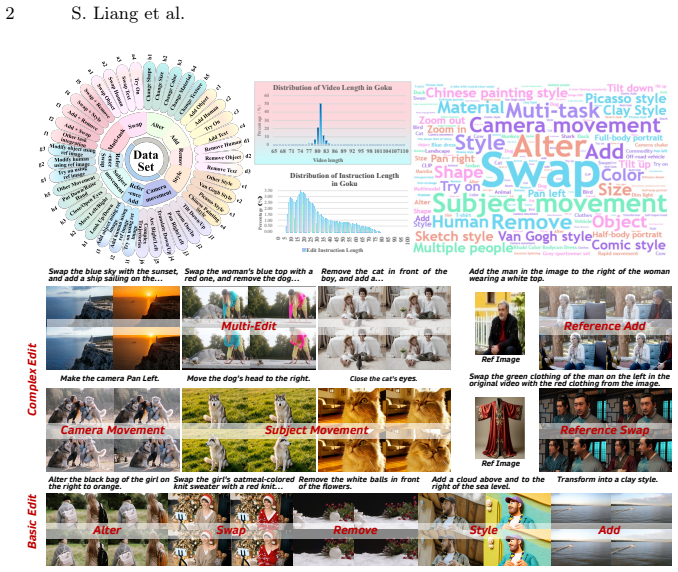
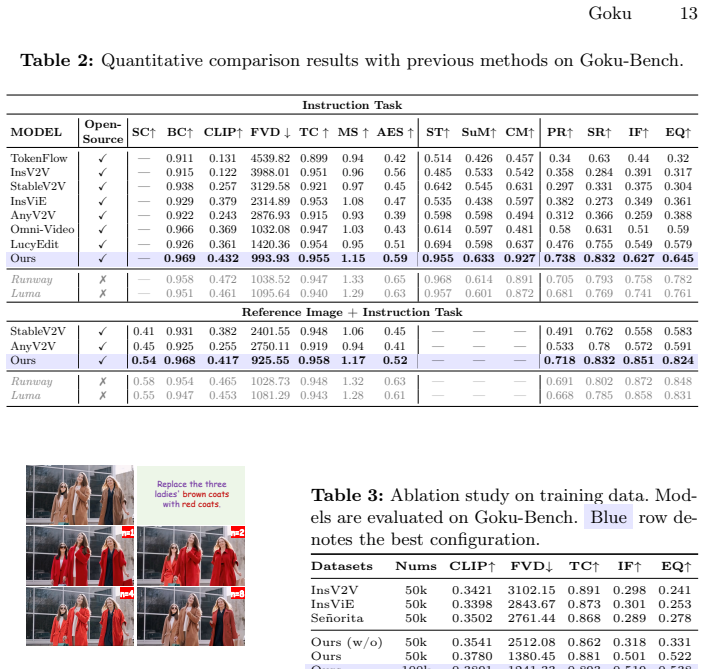
Existing instruction-based video editing datasets commonly focus on single-task appearance editing, failing to meet the complex creative demands of real-world scenarios. To bridge this gap, we present Goku, a large-scale dataset featuring 2 million high-quality, instruction-aligned video editing pairs, which is the first to extend task boundaries from basic appearance editing to multi-task and structural manipulations(e.g., precise control of subject movement). To tackle the data synthesis challenges inherent in these complex tasks, we design an efficient data synthesis pipeline that decomposes complex edits into controllable sub-problems and introduce a progressive filtering system for data reliability throughout the whole process. Furthermore, we explore the optimal network structures on Goku, and propose Goku-Edit. To deeply comprehend complex editing instructions, Goku-Edit leverages an MLLM as its text encoder and adopts a decoupled dual-branch design: a dedicated mask branch handles structural control, freeing the main branch for appearance rendering. A comprehensive video editing benchmark, Goku-Bench, is also proposed with 1,000 human-verified test cases and 7 novel editing-specific metrics. Evaluated on Goku-Bench, Goku-Edit obtains up to +8% improvement on other open-source models in terms of instruction following.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Goku, a dataset of 2 million instruction-aligned video editing pairs that extends beyond single-task appearance editing to multi-task and structural manipulations such as subject movement control. It describes an efficient synthesis pipeline that decomposes complex edits into sub-problems with progressive filtering, proposes the Goku-Edit architecture using an MLLM text encoder and a decoupled dual-branch design (mask branch for structural control), and presents Goku-Bench containing 1,000 human-verified test cases together with 7 novel editing-specific metrics. The central empirical claim is that models trained on Goku achieve up to +8% improvement in instruction following over other open-source baselines when evaluated on Goku-Bench.
Significance. If the synthesis pipeline demonstrably yields instruction-aligned pairs without systematic artifacts on structural and multi-task cases, the work would supply a substantial public resource that expands the scope of instruction-based video editing research. The benchmark and dual-branch architecture could also become reference points for future model development in this area.
major comments (3)
- [Abstract / data synthesis pipeline] Abstract and data synthesis pipeline section: the assertion that the decomposition-plus-progressive-filtering pipeline produces reliable, high-quality pairs for structural manipulations is load-bearing for the entire contribution, yet the manuscript provides no quantitative validation (human agreement rates, artifact statistics, or failure-mode breakdown on subject-movement cases).
- [Abstract / experimental results] Abstract and results section: the reported '+8% improvement' on instruction following is central to the performance claim, but the manuscript does not specify how the figure was computed, which exact metric(s) it aggregates, or whether baseline models were trained or evaluated under identical conditions and data scales.
- [Goku-Bench section] Goku-Bench description: the claim of 1,000 human-verified test cases is used to establish benchmark reliability, yet the manuscript supplies no details on verification protocol, inter-annotator agreement, or criteria applied to structural-edit cases.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction use the phrase 'first to extend task boundaries' without citing prior multi-task video editing datasets; a brief related-work comparison would clarify novelty.
- [Goku-Edit architecture] Notation for the decoupled dual-branch architecture (mask branch vs. main branch) is introduced without an accompanying diagram or equation defining the information flow between branches.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate the requested clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / data synthesis pipeline] Abstract and data synthesis pipeline section: the assertion that the decomposition-plus-progressive-filtering pipeline produces reliable, high-quality pairs for structural manipulations is load-bearing for the entire contribution, yet the manuscript provides no quantitative validation (human agreement rates, artifact statistics, or failure-mode breakdown on subject-movement cases).
Authors: We agree that explicit quantitative validation for structural manipulations is essential. The current manuscript describes the pipeline but does not report the requested statistics. In revision we will add human agreement rates (from our internal annotation rounds), artifact statistics, and a failure-mode breakdown focused on subject-movement cases, drawn from the progressive filtering logs and spot-checks performed during dataset construction. revision: yes
-
Referee: [Abstract / experimental results] Abstract and results section: the reported '+8% improvement' on instruction following is central to the performance claim, but the manuscript does not specify how the figure was computed, which exact metric(s) it aggregates, or whether baseline models were trained or evaluated under identical conditions and data scales.
Authors: The '+8%' figure is the maximum observed gain in instruction-following scores (averaged over the seven editing-specific metrics) when comparing Goku-Edit to the strongest open-source baseline on Goku-Bench. We will revise the abstract and results section to state the exact aggregation method, list the contributing metrics, and clarify that all models were evaluated under identical inference settings on the same 1,000-case test set; training-scale differences will also be explicitly noted. revision: yes
-
Referee: [Goku-Bench section] Goku-Bench description: the claim of 1,000 human-verified test cases is used to establish benchmark reliability, yet the manuscript supplies no details on verification protocol, inter-annotator agreement, or criteria applied to structural-edit cases.
Authors: We will expand the Goku-Bench section with a dedicated subsection describing the verification protocol, the inter-annotator agreement (Cohen's kappa or equivalent), and the specific criteria used to accept or reject structural-edit cases. These details were collected during benchmark curation but were omitted from the initial submission for brevity. revision: yes
Circularity Check
No circularity: empirical dataset construction and benchmark evaluation
full rationale
The paper describes an empirical pipeline for synthesizing 2M video editing pairs via decomposition and progressive filtering, followed by training Goku-Edit (MLLM text encoder + dual-branch architecture) and evaluating on the human-verified Goku-Bench with 7 metrics. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text. Performance gains (+8% instruction following) are reported as direct empirical comparisons against external open-source models on an independently human-verified test set, with no reduction to inputs by construction. This is a standard dataset+model paper whose central claims rest on external validation rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complex video edits can be decomposed into controllable sub-problems that a progressive filtering system can reliably validate.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14834–14844 (2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bai, Q., Wang, Q., Ouyang, H., Yu, Y., Wang, H., Wang, W., Cheng, K.L., Ma, S., Zeng, Y., Liu, Z., et al.: Scaling instruction-based video editing with a high-quality synthetic dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 37971–37981 (2026)
2026
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22563–22575 (2023)
2023
-
[7]
Brooks, T., Hellsten, J., Aittala, M., Wang, T.C., Aila, T., Lehtinen, J., Liu, M.Y., Efros,A.,Karras,T.:Generatinglongvideosofdynamicscenes.AdvancesinNeural Information Processing Systems35, 31769–31781 (2022)
2022
-
[8]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[9]
In: International Conference on Learning Representations
Cheng, J., Xiao, T., He, T.: Consistent video-to-video transfer using synthetic dataset. In: International Conference on Learning Representations. vol. 2024, pp. 16867–16879 (2024)
2024
-
[10]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
In: European Conference on Computer Vision
Gupta, A., Yu, L., Sohn, K., Gu, X., Hahn, M., Li, F.F., Essa, I., Jiang, L., Lezama, J.: Photorealistic video generation with diffusion models. In: European Conference on Computer Vision. pp. 393–411. Springer (2024)
2024
-
[12]
arXiv preprint arXiv:2512.07826 (2025)
He, H., Wang, J., Zhang, J., Xue, Z., Bu, X., Yang, Q., Wen, S., Xie, L.: Openve- 3m: A large-scale high-quality dataset for instruction-guided video editing. arXiv preprint arXiv:2512.07826 (2025)
-
[13]
Advances in neural information processing systems35, 8633– 8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633– 8646 (2022)
2022
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) Goku 17
2024
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025)
2025
-
[16]
EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning
Ju, X., Wang, T., Zhou, Y., Zhang, H., Liu, Q., Zhao, N., Zhang, Z., Li, Y., Cai, Y., Liu, S., et al.: Editverse: Unifying image and video editing and generation with in-context learning. arXiv preprint arXiv:2509.20360 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Ku, M., Wei, C., Ren, W., Yang, H., Chen, W.: Anyv2v: A tuning-free framework for any video-to-video editing tasks. arXiv preprint arXiv:2403.14468 (2024)
-
[18]
In: Proceedings of the AAAI conference on artificial intelligence
Li, Y., Min, M., Shen, D., Carlson, D., Carin, L.: Video generation from text. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, S., Guan, F., Zhang, Y., Li, X., Chen, Z.: Cot-edit: Let cot guide instruction video editing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 37960–37970 (2026)
2026
-
[20]
SpongeBob: Sync-Aware Harmonious Audio-Visual Generative Editing
Liang, S., Wang, C., Guan, F., Yu, Z., Lu, Y., Wang, Y., Zhou, Y., Li, X., Chen, Z.: Spongebob: Sync-aware harmonious audio-visual generative editing. arXiv preprint arXiv:2605.25193 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
arXiv preprint arXiv:2506.01801 (2025)
Liang, S., Yu, Z., Zhou, Z., Hu, T., Wang, H., Chen, Y., Lin, Q., Zhou, Y., Li, X., Lu, Q., et al.: Omniv2v: Versatile video generation and editing via dynamic content manipulation. arXiv preprint arXiv:2506.01801 (2025)
-
[22]
arXiv preprint arXiv:2501.08316 (2025)
Lin, S., Xia, X., Ren, Y., Yang, C., Xiao, X., Jiang, L.: Diffusion adversarial post- training for one-step video generation. arXiv preprint arXiv:2501.08316 (2025)
-
[23]
IEEE Transactions on Circuits and Systems for Video Technology (2025)
Liu,C.,Li,R.,Zhang,K.,Lan,Y.,Liu,D.:Stablev2v:Stabilizingshapeconsistency in video-to-video editing. IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[24]
Ma, Y., Feng, K., Zhang, X., Liu, H., Zhang, D.J., Xing, J., Zhang, Y., Yang, A., Wang, Z., Chen, Q.: Follow-your-creation: Empowering 4d creation through video inpainting. arXiv preprint arXiv:2506.04590 (2025)
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ma, Y., He, Y., Cun, X., Wang, X., Chen, S., Li, X., Chen, Q.: Follow your pose: Pose-guided text-to-video generation using pose-free videos. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4117–4125 (2024)
2024
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 2545–2555 (2025)
2025
-
[27]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
arXiv preprint arXiv:2507.06119 (2025)
Tan, Z., Yang, H., Qin, L., Gong, J., Yang, M., Li, H.: Omni-video: Democratiz- ing unified video understanding and generation. arXiv preprint arXiv:2507.06119 (2025)
-
[30]
Team, D.: Lucy edit: Open-weight text-guided video editing (2025)
2025
-
[31]
ModelScope Text-to-Video Technical Report
Wang, J., Yuan, H., Chen, D., Zhang, Y., Wang, X., Zhang, S.: Modelscope text- to-video technical report. arXiv preprint arXiv:2308.06571 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Wang, Q., Shi, Y., Ou, J., Chen, R., Lin, K., Wang, J., Jiang, B., Yang, H., Zheng, M., Tao, X., et al.: Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 8428–8437 (2025) 18 S. Liang et al
2025
-
[33]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Wang, Y., Bilinski, P., Bremond, F., Dantcheva, A.: Imaginator: Conditional spatio-temporal gan for video generation. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1160–1169 (2020)
2020
-
[34]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Wu, Y., Chen, L., Li, R., Wang, S., Xie, C., Zhang, L.: Insvie-1m: Effective instruction-based video editing with elaborate dataset construction. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 16692– 16701 (2025)
2025
-
[35]
MagicVideo: Efficient Video Generation With Latent Diffusion Models
Zhou, D., Wang, W., Yan, H., Lv, W., Zhu, Y., Feng, J.: Magicvideo: Efficient video generation with latent diffusion models. arXiv preprint arXiv:2211.11018 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
arXiv preprint arXiv:2410.15458 (2024)
Zhou, Y., Wang, Q., Cai, Y., Yang, H.: Allegro: Open the black box of commercial- level video generation model. arXiv preprint arXiv:2410.15458 (2024)
-
[37]
Advances in Neural Infor- mation Processing Systems38, 75518–75547 (2026)
Zi, B., Peng, W., Qi, X., Wang, J., Zhao, S., Xiao, R., Wong, K.F.: Minimax- remover: Taming bad noise helps video object removal. Advances in Neural Infor- mation Processing Systems38, 75518–75547 (2026)
2026
-
[38]
Advances in Neural Information Processing Systems38(2026)
Zi, B., Ruan, P., Chen, M., Qi, X., Hao, S., Zhao, S., Huang, Y., Liang, B., Xiao, R., Wong, K.F.: Señorita-2m: A high-quality instruction-based dataset for gen- eral video editing by video specialists. Advances in Neural Information Processing Systems38(2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.