Revocable Learned State via Process Sidecars
Pith reviewed 2026-07-01 06:41 UTC · model grok-4.3
The pith
A two-coefficient sidecar edit recovers the safety-only model up to second order by correcting for how safety training transports the memory direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The exact sidecar using the true transported direction R_{S←M} at (λ,γ)=(1,1) recovers the counterfactual safety-only oracle θ_AS up to second order. The proof treats AdamW as an augmented-state map over parameters, first moments, and second moments. Whenever future safety training bends the memory direction, every scalar task-arithmetic edit leaves first-order counterfactual error, while the process-sidecar edit remains second-order accurate. The practical implementation approximates the transported direction with a centered secant through the realized safety-training process at ε=1.
What carries the argument
The process sidecar edit family θ̂(λ,γ)=θ_AMS−λΔ_M−γR̂_{S←M}, where R̂_{S←M} is the centered secant estimate of the direction in which safety training transports the memory update.
If this is right
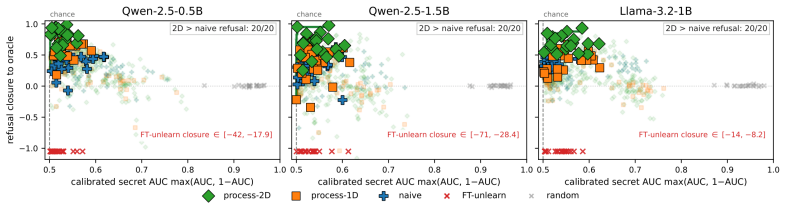
- The validation-selected two-dimensional edit improves held-out refusal closure over naive task arithmetic in all trials across three models.
- The two-dimensional edit outperforms the γ=λ process-JVP subfamily in all paired trials.
- Process information from the safety-training trajectory is required for second-order accuracy once safety training bends the memory direction.
Where Pith is reading between the lines
- The same sidecar construction could be tested on sequential training pipelines that do not involve safety, such as continued pre-training followed by fine-tuning.
- If the augmented-state treatment of AdamW extends to other first-order methods, similar second-order corrections might apply without requiring full trajectory replay.
- The approach suggests a general pattern for editing states that have been altered by later optimization steps rather than treating each update as an independent vector.
Load-bearing premise
The centered secant through the realized future AdamW safety-training process at ε=1 provides a sufficiently accurate estimate of the true transported direction R_{S←M} for the second-order recovery to hold in practice.
What would settle it
A direct comparison, on held-out data, showing that the sidecar edit at (1,1) with the secant estimate deviates from the true safety-only oracle θ_AS by more than second-order terms when safety training has bent the memory direction.
Figures
read the original abstract
Language models are often adapted in stages: a public skill phase, a private memory phase, and a later safety phase that learns to refuse outputs tied to the remembered entities. Revoking the memory after the safety phase is not the same problem as subtracting the memory update: the later safety optimizer has transported the memory direction. We introduce process sidecars, a two-coefficient edit family $\hat{\theta}(\lambda,\gamma)=\theta_{\mathrm{AMS}}-\lambda\Delta_{\mathrm{M}}-\gamma\hat{R}_{\mathrm{S}\leftarrow\mathrm{M}}$, with $\hat{R}_{\mathrm{S}\leftarrow\mathrm{M}}=\hat{J}_{\mathrm{S},\varepsilon}(\Delta_{\mathrm{M}})-\Delta_{\mathrm{M}}$, where $\hat{J}_{\mathrm{S},\varepsilon}$ is a centered secant through the realized future AdamW safety-training process. The implementation uses $\varepsilon=1$ at the natural memory-edit scale; it reuses $\theta_{\mathrm{AMS}}$ as the positive endpoint and computes one additional safety trace at $\theta_{\mathrm{A}}-\Delta_{\mathrm{M}}$. We prove two things. First, the exact sidecar, using the true transported direction $R_{\mathrm{S}\leftarrow\mathrm{M}}$ rather than the secant estimate, at $(\lambda,\gamma)=(1,1)$ recovers the counterfactual safety-only oracle $\theta_{\mathrm{AS}}$ up to second order; the proof treats AdamW as an augmented-state map over parameters, first moments, and second moments. Second, this process information is necessary: whenever future safety training bends the memory direction, every scalar task-arithmetic edit leaves first-order counterfactual error, while the process-sidecar edit is second-order accurate. Across three models, the validation-selected 2D edit improves held-out refusal closure over naive task arithmetic in all trials, and over the $\gamma=\lambda$ process-JVP subfamily, the diagonal slice of the cached 2D grid, in all paired trials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces process sidecars, a two-coefficient edit family hetâ(λ,γ) = θ_AMS − λ Δ_M − γ R̂_{S←M} where R̂ is a centered secant through the realized AdamW safety-training trajectory. It proves that the exact sidecar (true transported direction R_{S←M}) at (λ,γ)=(1,1) recovers the counterfactual safety-only oracle θ_AS up to second order by treating AdamW as an augmented-state map on (θ, m, v); it further proves that any scalar task-arithmetic edit necessarily incurs first-order counterfactual error whenever safety training bends the memory direction; and it reports that the practical secant implementation (ε=1, one extra safety trace) with validation-selected (λ,γ) improves held-out refusal closure over naive task arithmetic and over the γ=λ process-JVP slice on three models.
Significance. If the secant approximation preserves the second-order property in practice, the work supplies a principled, optimizer-aware editing technique that goes beyond scalar task arithmetic for post-training revocation of learned state. The formal modeling of the full AdamW process (parameters plus moments) as a map and the necessity argument that distinguishes process information from scalar edits are genuine strengths; the empirical demonstration that the 2D edit outperforms both baselines in all trials adds practical support.
major comments (3)
- [Proof of second-order recovery (exact sidecar)] Proof of second-order recovery: the argument establishes O(‖Δ_M‖²) accuracy only for the exact transported direction R_{S←M}; the implemented method substitutes the centered secant R̂_{S,ε=1} computed at the natural memory-edit scale without a remainder bound or expansion showing that the secant error is o(‖Δ_M‖) rather than O(‖Δ_M‖), which is required to carry the second-order claim over to the practical edit family.
- [Necessity argument] Necessity argument: the claim that every scalar task-arithmetic edit leaves first-order counterfactual error relies on the safety-training map bending the memory direction; the precise condition under which the first-order term vanishes (or does not) should be stated explicitly, as it is load-bearing for the motivation that process information is required.
- [Empirical evaluation] Implementation and validation: the reported gains use a validation-selected (λ,γ) pair together with a single extra safety trace at θ_A − Δ_M; because the selection is performed on held-out data that also informs the refusal metric, an ablation showing performance for fixed (λ,γ)=(1,1) or for the exact sidecar (when computable) would be needed to separate the contribution of the secant from hyperparameter tuning.
minor comments (2)
- [Notation] Notation: the centered secant is written both as R̂_{S←M} and as Ĵ_{S,ε}(Δ_M) − Δ_M; a single consistent symbol and an explicit definition of the centering point would improve readability.
- [Figures] Figure clarity: the 2D grid plots of (λ,γ) performance should include contour lines or a marked validation-selected point so readers can see how far the chosen coefficients lie from the (1,1) corner.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for acknowledging the formal contributions of the process-sidecar framework and the empirical improvements. We respond to each major comment below and will revise the manuscript accordingly to address the points raised.
read point-by-point responses
-
Referee: Proof of second-order recovery (exact sidecar): the argument establishes O(‖Δ_M‖²) accuracy only for the exact transported direction R_{S←M}; the implemented method substitutes the centered secant R̂_{S,ε=1} computed at the natural memory-edit scale without a remainder bound or expansion showing that the secant error is o(‖Δ_M‖) rather than O(‖Δ_M‖), which is required to carry the second-order claim over to the practical edit family.
Authors: We agree that the O(‖Δ_M‖²) guarantee is established only for the exact transported direction. The manuscript presents the secant implementation as a practical approximation at the natural edit scale (ε=1) without claiming that the second-order property automatically transfers. We will revise the text to explicitly distinguish the exact-sidecar theorem from the practical secant method and to note that the latter is a heuristic whose error depends on the curvature of the safety-training trajectory. revision: yes
-
Referee: Necessity argument: the claim that every scalar task-arithmetic edit leaves first-order counterfactual error relies on the safety-training map bending the memory direction; the precise condition under which the first-order term vanishes (or does not) should be stated explicitly, as it is load-bearing for the motivation that process information is required.
Authors: The necessity claim holds whenever the safety-training map produces a nonzero transverse component in the transported direction, i.e., when the directional derivative of the safety map applied to Δ_M is not collinear with Δ_M. Equivalently, the first-order error term in scalar edits vanishes only if the Jacobian of the safety map at the relevant point maps Δ_M into a scalar multiple of itself. We will add an explicit statement of this condition (including the mathematical criterion for vanishing) in the revised manuscript. revision: yes
-
Referee: Implementation and validation: the reported gains use a validation-selected (λ,γ) pair together with a single extra safety trace at θ_A − Δ_M; because the selection is performed on held-out data that also informs the refusal metric, an ablation showing performance for fixed (λ,γ)=(1,1) or for the exact sidecar (when computable) would be needed to separate the contribution of the secant from hyperparameter tuning.
Authors: We acknowledge that validation-based selection on data tied to the evaluation metric limits the ability to isolate the secant contribution. In the revision we will add an ablation reporting performance for the fixed pair (λ,γ)=(1,1) on all three models, as well as for the γ=λ process-JVP slice, thereby separating the effect of the two-coefficient edit from hyperparameter tuning. revision: yes
Circularity Check
No circularity: proof for exact sidecar is independent modeling of AdamW dynamics
full rationale
The core derivation consists of two explicit mathematical claims: (1) the exact sidecar with true R_{S←M} at (λ,γ)=(1,1) recovers θ_AS to second order by treating the full AdamW process as an augmented-state dynamical system on (θ,m,v), and (2) scalar task-arithmetic edits necessarily incur first-order error whenever safety training bends the memory direction. Both statements are proven from the optimizer equations rather than fitted to data or reduced to prior self-citations. The implemented secant approximation and validation-selected (λ,γ) appear only in the empirical section and are not invoked inside the proof; the paper does not rename the secant result as a prediction or smuggle an ansatz via citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- λ, γ
axioms (1)
- domain assumption AdamW training can be treated as an augmented-state map over parameters, first moments, and second moments
invented entities (2)
-
process sidecar edit family
no independent evidence
-
R̂_{S←M} (centered secant estimate)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
IEEE Symposium on Security and Privacy , year =
Machine Unlearning , author =. IEEE Symposium on Security and Privacy , year =
-
[3]
2024 , howpublished =
2024
- [4]
-
[5]
Proceedings of the 34th International Conference on Machine Learning , series =
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[6]
Goddard, Charles and Siriwardhana, Shamane and Ehghaghi, Malikeh and Meyers, Luke and Karpukhin, Vladimir and Benedict, Brian and McQuade, Mark and Solawetz, Jacob , booktitle =. Arcee's. 2024 , publisher =. doi:10.18653/v1/2024.emnlp-industry.36 , url =
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2020 , url =
2020
-
[8]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , year =. The. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proceedings of the 37th International Conference on Machine Learning , series =
Certified Data Removal from Machine Learning Models , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[10]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
2022
-
[11]
Unlearning or Obfuscating? Jogging the Memory of Unlearned
Hu, Shengyuan and Fu, Yiwei and Wu, Zhiwei Steven and Smith, Virginia , booktitle =. Unlearning or Obfuscating? Jogging the Memory of Unlearned. 2025 , url =
2025
-
[12]
International Conference on Learning Representations , year =
Editing Models with Task Arithmetic , author =. International Conference on Learning Representations , year =
-
[13]
Knowledge Unlearning for Mitigating Privacy Risks in Language Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , publisher =. doi:10.18653/v1/2023.acl-long.805 , url =
-
[14]
and Ba, Jimmy , booktitle =
Kingma, Diederik P. and Ba, Jimmy , booktitle =. 2015 , url =
2015
-
[15]
Proceedings of the 34th International Conference on Machine Learning , series =
Understanding Black-Box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[16]
and Dombrowski, Ann-Kathrin and Goel, Shashwat and Mukobi, Gabriel and others , booktitle =
Li, Nathaniel and Pan, Alexander and Gopal, Anjali and Yue, Summer and Berrios, Daniel and Gatti, Alice and Li, Justin D. and Dombrowski, Ann-Kathrin and Goel, Shashwat and Mukobi, Gabriel and others , booktitle =. The. 2024 , publisher =
2024
-
[17]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , series =
Optimizing Millions of Hyperparameters by Implicit Differentiation , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , series =. 2020 , publisher =
2020
-
[18]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[19]
Transactions on Machine Learning Research , year =
An Adversarial Perspective on Machine Unlearning for. Transactions on Machine Learning Research , year =
-
[20]
Proceedings of the 32nd International Conference on Machine Learning , series =
Gradient-Based Hyperparameter Optimization through Reversible Learning , author =. Proceedings of the 32nd International Conference on Machine Learning , series =. 2015 , publisher =
2015
-
[21]
and Kolter, J
Maini, Pratyush and Feng, Zhili and Schwarzschild, Avi and Lipton, Zachary C. and Kolter, J. Zico , booktitle =. 2024 , url =
2024
-
[22]
and Raffel, Colin A
Matena, Michael S. and Raffel, Colin A. , booktitle =. Merging Models with. 2022 , url =
2022
-
[23]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[24]
2023 , publisher =
Park, Sung Min and Georgiev, Kristian and Ilyas, Andrew and Leclerc, Guillaume and Madry, Aleksander , booktitle =. 2023 , publisher =
2023
-
[25]
, journal =
Pearlmutter, Barak A. , journal =. Fast Exact Multiplication by the. 1994 , doi =
1994
-
[26]
2025 , howpublished =
2025
-
[27]
2026 , howpublished =
2026
-
[28]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[29]
Advances in Neural Information Processing Systems , volume =
Meta-Learning with Implicit Gradients , author =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
2019
-
[30]
and Zhang, Chiyuan , booktitle =
Shi, Weijia and Lee, Jaechan and Huang, Yangsibo and Malladi, Sadhika and Zhao, Jieyu and Holtzman, Ari and Liu, Daogao and Zettlemoyer, Luke and Smith, Noah A. and Zhang, Chiyuan , booktitle =. 2025 , url =
2025
-
[31]
Proceedings of the 39th International Conference on Machine Learning , series =
Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy without Increasing Inference Time , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[32]
2023 , url =
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin and Bansal, Mohit , booktitle =. 2023 , url =
2023
-
[33]
Proceedings of the 41st International Conference on Machine Learning , series =
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[34]
Conference on Language Modeling (COLM) , year =
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author =. Conference on Language Modeling (COLM) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.