MultiUAV-Plat: An LLM-Oriented Platform, Benchmark and Framework for Multi-UAV Collaborative Task Planning
Pith reviewed 2026-07-01 06:07 UTC · model grok-4.3
The pith
MultiUAV-Plat platform and benchmark enable evaluation of LLM agents for multi-UAV collaborative task planning, with Agent4Drone reaching 57.9 percent task pass rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
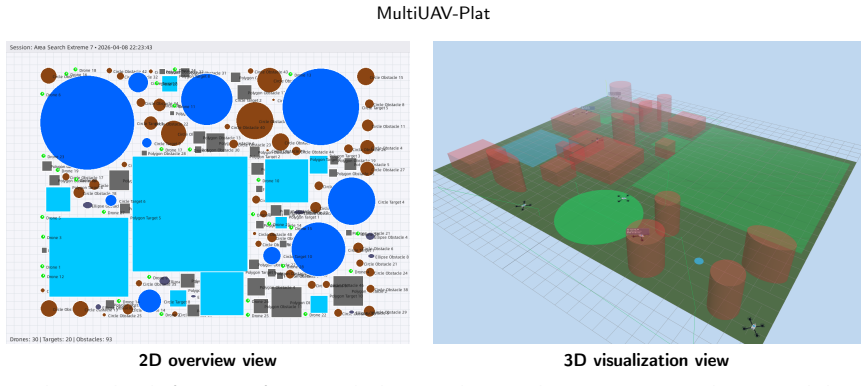
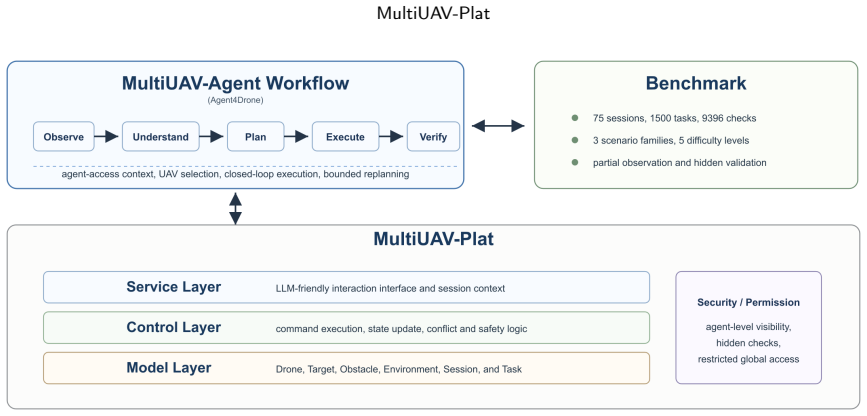
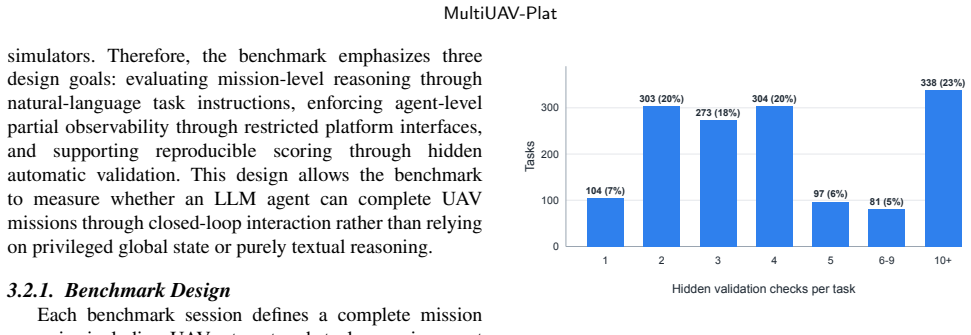
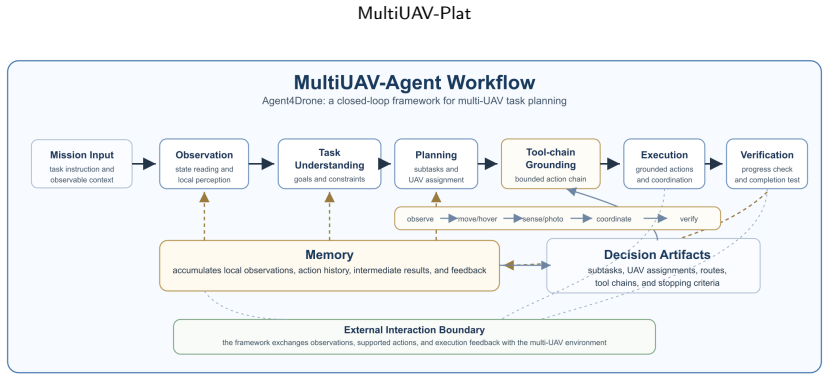
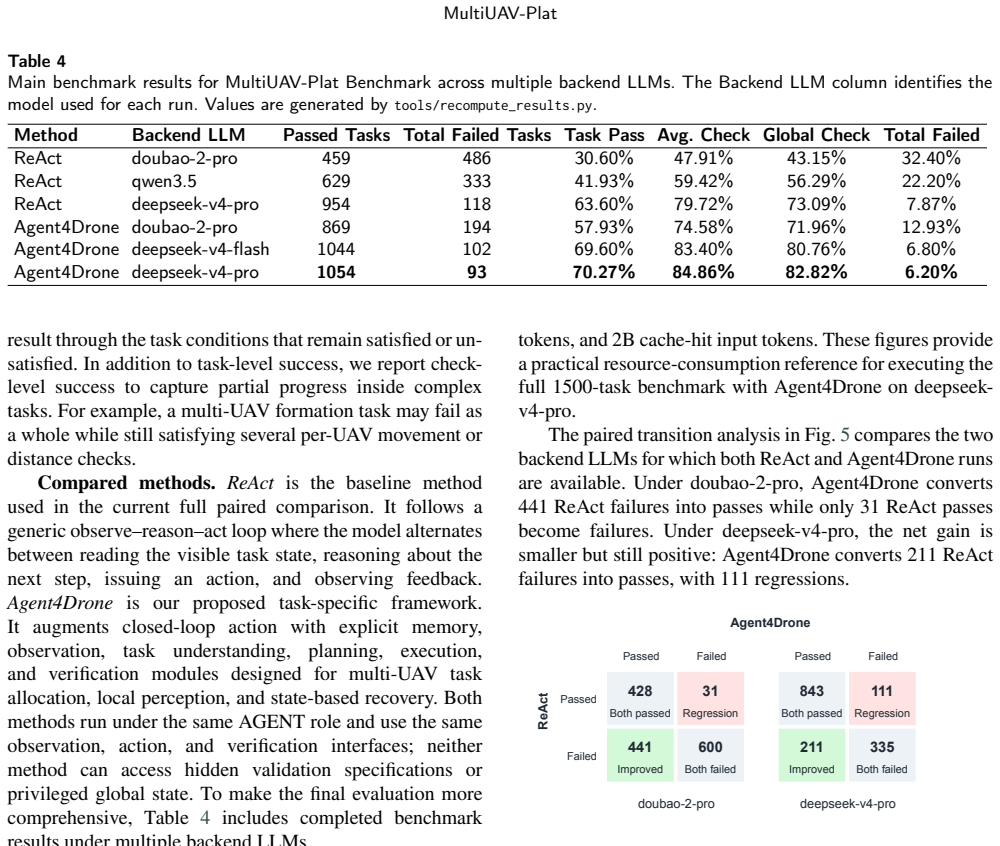
MultiUAV-Plat is a lightweight, LLM-agent-oriented simulation platform that uses concise RESTful APIs, agent-facing observations, role-based information access, and hidden validation logic to let agents interact with multi-UAV missions realistically. The associated benchmark covers target assignment, area search, and area assignment and patrol. Agent4Drone structures behavior into six stages and achieves 57.9% task pass rate, 74.6% average task check pass rate, and 72.0% global check pass rate, compared to 30.6%, 47.9%, and 43.1% for ReAct, while cutting failed tasks from 32.4% to 12.9%.
What carries the argument
Agent4Drone framework, which structures multi-UAV behavior into memory, observation, task understanding, planning, execution, and verification stages.
If this is right
- The benchmark allows direct comparison of LLM agents on tasks that require spatial coverage and multi-vehicle coordination.
- Agent4Drone's staged approach leads to higher pass rates on the 1500 tasks.
- The platform supports reproducible studies of LLM-driven multi-UAV autonomy.
- Validation checks provide detailed feedback on assignment, coverage, and coordination failures.
- Optional visualization aids in understanding agent decisions.
Where Pith is reading between the lines
- The platform could be extended to include more dynamic elements like moving targets to test real-time replanning.
- Success in simulation may translate to field tests if the modeled constraints match physical UAV limitations.
- Other multi-agent domains such as ground robots could adopt similar benchmark designs.
- The reduction in failed tasks suggests potential for more reliable LLM planning in safety-critical applications.
Load-bearing premise
The simulation platform and its validation checks accurately capture the real-world constraints of multi-UAV operations such as partial observability, spatial coverage, assignment, and coordination.
What would settle it
Deploying Agent4Drone on real UAV hardware for the same mission types and measuring if the task pass rate stays near 57.9 percent or drops significantly due to unmodeled factors.
Figures

read the original abstract
Large language models (LLMs) provide a promising interface for high-level robotic task planning, but their use in multi-UAV collaboration remains difficult to evaluate systematically. Existing UAV simulators mainly emphasize dynamics, perception, or low-level control, while existing LLM-agent benchmarks rarely capture aerial-robotics constraints such as partial observability, spatial coverage, UAV assignment, and multi-vehicle coordination. To bridge this gap, we present MultiUAV-Plat, a lightweight, easy-to-use, LLM-agent-oriented simulation platform for multi-UAV collaborative task planning. The platform exposes concise RESTful APIs, agent-facing observations, role-based information access, hidden validation logic, and optional 2D/3D visualization, allowing agents to solve missions through realistic tool interaction rather than privileged simulator access. Built on this platform, the MultiUAV-Plat Benchmark contains 75 mission sessions, 1500 natural-language tasks, and 9396 validation checks across target assignment, area search, and area assignment and patrol scenarios. We further propose Agent4Drone, a task-specific LLM agent framework that structures multi-UAV behavior into memory, observation, task understanding, planning, execution, and verification. In a full paired benchmark comparison, Agent4Drone achieves a 57.9% task pass rate, a 74.6% average task check pass rate, and a 72.0% global check pass rate, substantially outperforming a ReAct baseline at 30.6%, 47.9%, and 43.1%, respectively. Agent4Drone also reduces the total failed task rate from 32.4% to 12.9%. These results demonstrate that MultiUAV-Plat and MultiUAV-Plat Benchmark provide a reproducible foundation for studying LLM-driven multi-UAV autonomy under realistic information and execution constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiUAV-Plat, a lightweight LLM-agent-oriented simulation platform for multi-UAV collaborative task planning that provides RESTful APIs, role-based partial observations, hidden validation logic, and optional visualization. It presents the MultiUAV-Plat Benchmark containing 75 mission sessions, 1500 natural-language tasks, and 9396 validation checks across target assignment, area search, and area assignment/patrol scenarios. The paper also proposes Agent4Drone, a structured LLM agent framework (memory-observation-task understanding-planning-execution-verification), and reports that it achieves 57.9% task pass rate, 74.6% average task check pass rate, and 72.0% global check pass rate, outperforming a ReAct baseline (30.6%, 47.9%, 43.1%) while reducing total failed task rate from 32.4% to 12.9%.
Significance. If the simulator's hidden checks accurately reflect real multi-UAV constraints, the work supplies a reproducible, agent-facing benchmark that bridges dynamics-focused UAV simulators and generic LLM-agent evaluations, enabling systematic study of coordination under partial observability. The explicit paired comparison and failure-rate reduction provide concrete evidence that structured agent loops can improve task completion within the platform.
major comments (2)
- [Experiments section] Experiments section: The comparative claims rest entirely on results inside MultiUAV-Plat; the manuscript reports no physical UAV flights, sensor-noise injection, packet-loss modeling, or cross-validation against real flight logs to establish that the hidden validation checks (target assignment, spatial coverage, coordination) match actual operational constraints.
- [Platform and Benchmark sections] Platform and Benchmark sections: The description states that validation logic is hidden and observations are role-based, yet no details are given on how the 9396 checks were designed, enumerated, or independently audited for completeness in capturing partial observability and multi-vehicle assignment limits.
minor comments (1)
- [Abstract and §3] Abstract and §3: The claim of 'realistic tool interaction' would be strengthened by an explicit statement of which UAV dynamics (e.g., wind, communication latency) are omitted from the simulator.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and valuable comments. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: The comparative claims rest entirely on results inside MultiUAV-Plat; the manuscript reports no physical UAV flights, sensor-noise injection, packet-loss modeling, or cross-validation against real flight logs to establish that the hidden validation checks (target assignment, spatial coverage, coordination) match actual operational constraints.
Authors: The primary contribution of this work is a simulation platform and benchmark designed to enable systematic evaluation of LLM agents for multi-UAV task planning in a controlled, reproducible environment. The hidden validation checks are constructed to reflect key operational constraints including partial observability, spatial requirements, and coordination limits, drawing from established multi-UAV mission principles. We agree that physical validation would provide additional confidence; however, the manuscript does not claim equivalence to real-world dynamics and instead focuses on the agent-facing simulation interface. Introducing sensor noise or packet loss would require extending the platform beyond its current lightweight design, which is outside the scope of the present study. revision: no
-
Referee: [Platform and Benchmark sections] Platform and Benchmark sections: The description states that validation logic is hidden and observations are role-based, yet no details are given on how the 9396 checks were designed, enumerated, or independently audited for completeness in capturing partial observability and multi-vehicle assignment limits.
Authors: We acknowledge that additional details on the validation check design would improve transparency. In the revised version of the manuscript, we will include a new subsection in the Benchmark section that describes the process of designing and enumerating the 9396 checks. This will cover how checks were derived from the three scenario types (target assignment, area search, area assignment/patrol), the enumeration criteria to ensure coverage of partial observability and assignment constraints, and the internal review process conducted by the authors to verify completeness. Examples of representative checks will also be provided. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of self-defined quantities
full rationale
The paper presents a new simulation platform, benchmark with 75 missions and 9396 validation checks, and an LLM agent framework. Reported metrics (57.9% task pass rate etc.) are direct measurements on this benchmark against a ReAct baseline. No equations, fitted parameters, or derivation steps exist that reduce any claim to its own inputs by construction. No self-citation chains or ansatzes are invoked as load-bearing. The evaluation is self-contained against the explicitly defined benchmark tasks and checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be used for high-level robotic task planning through tool interaction
invented entities (2)
-
MultiUAV-Plat
no independent evidence
-
Agent4Drone
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do as i can, not as i say: Grounding language in robotic affordances
Ahn, M., Brohan,A., Brown, N., Chebotar, Y.,Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Ho, D., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jang, E., Jauregui Ruano, R., Jeffrey, K., Jesmonth, S., Joshi, N.J., Julian, R., Kalashnikov, D., Kuang, Y., Lee, K.H., Levine, S., Lu, Y., Luu, L., Parada, C., Pastor, P., Qu...
Pith/arXiv arXiv 2022
-
[2]
Besta,M.,Blach,N.,Kubicek,A.,Gerstenberger,R.,Podstawski,M., Gianinazzi,L.,Gajda,J.,Lehmann,T.,Niewiadomski,H.,Nyczyk,P., Hoefler,T.,2024.Graphofthoughts:Solvingelaborateproblemswith large language models, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 17682–17690. URL:https://arxiv.org/ abs/2308.09687, doi:10.1609/aaai.v38i16.29720
-
[3]
A survey on open-source simulation platforms for multi-copter uav swarms
Chen, Z., Yan, J., Ma, B., Shi, K., Yu, Q., Yuan, W., 2023. A survey on open-source simulation platforms for multi-copter uav swarms. Robotics 12, 53. doi:10.3390/robotics12020053
-
[4]
Dai, S., Ma, Z., Luo, Z., Yang, X., Huang, Y., Zhang, W., Chen, C., Guo, Z., Xu, W., Sun, Y., Sun, M., 2025. Mm-uavbench: How well do multimodal large language models see, think, and plan in low-altitude uav scenarios? arXiv preprint arXiv:2512.23219 URL:https://arxiv.org/abs/2512.23219, doi:10.48550/arXiv.2512. 23219. arXiv preprint, posted 29 December 2025
-
[6]
arXiv preprint arXiv:2601.03281 URL:https://arxiv.org/abs/2601.03281, doi:10.48550/arXiv.2601
Ferrag, M.A., Lakas, A., Debbah, M., 2026.𝛼 3-bench: A uni- fied benchmark of safety, robustness, and efficiency for llm-based uav agents over 6g networks. arXiv preprint arXiv:2601.03281 URL:https://arxiv.org/abs/2601.03281, doi:10.48550/arXiv.2601. 03281. arXiv preprint, posted 1 January 2026
-
[7]
Say the Mission, Execute the Swarm: Agent-Enhanced LLM Reasoning in the Web-of-Drones
Iannoli, A., Gigli, L., Sciullo, L., Trotta, A., Di Felice, M., 2026. Saythemission,executetheswarm:Agent-enhancedllmreasoningin the web-of-drones. arXiv preprint arXiv:2605.03788 URL:https:// arxiv.org/abs/2605.03788, doi:10.48550/arXiv.2605.03788. accepted forpresentationatthe27thIEEEInternationalSymposiumonaWorld of Wireless, Mobile and Multimedia Netw...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.03788 2026
-
[8]
Smart-llm:Smart multi-agent robot task planning using large language models
Kannan,S.S.,Venkatesh,V.L.N.,Min,B.C.,2023. Smart-llm:Smart multi-agent robot task planning using large language models. arXiv preprint arXiv:2309.10062 URL:https://arxiv.org/abs/2309.10062, doi:10.48550/arXiv.2309.10062
-
[9]
Kong, X., Zhou, Y., Li, Z., Wang, S., 2024. Multi-uav simultaneous target assignment and path planning based on deep reinforcement learning in dynamic multiple obstacles environments. Frontiers in Neurorobotics 17, 1302898. doi:10.3389/fnbot.2023.1302898
-
[10]
Large Language Models for Multi-Robot Systems: A Survey
Li, P., An, Z., Abrar, S., Zhou, L., 2025. Large language models for multi-robot systems: A survey. arXiv preprint arXiv:2502.03814 URL:https://arxiv.org/abs/2502.03814, doi:10.48550/arXiv.2502. 03814
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502 2025
-
[11]
Code as Policies: Language Model Programs for Embodied Control
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Flo- rence,P.,Zeng,A.,2022.Codeaspolicies:Languagemodelprograms for embodiedcontrol. arXiv preprintarXiv:2209.07753 URL:https: //arxiv.org/abs/2209.07753, doi:10.48550/arXiv.2209.07753
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.07753 2022
-
[12]
Liu, K., Tang, Z., Wang, D., Wang, Z., Li, X., Zhao, B., 2024. Coherent: Collaboration of heterogeneous multi-robot system with largelanguagemodels.arXivpreprintarXiv:2409.15146URL:https: //arxiv.org/abs/2409.15146, doi:10.48550/arXiv.2409.15146
-
[13]
AgentBench: Evaluating LLMs as Agents
Liu, X., Yu, H., Zhang, H., Xu, Y., Lei, X., Lai, H., Gu, Y., Ding, H., Men, K., Yang, K., Zhang, S., Deng, X., Zeng, A., Du, Z., Zhang, C., Shen, S., Zhang, T., Su, Y., Sun, H., Huang, M., Dong, Y., Tang, J., 2023. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688 URL:https://arxiv.org/abs/2308.03688, doi:10.48550/arXiv.2308.03688
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03688 2023
-
[14]
arXiv preprint arXiv:2406.00006 URL:https://arxiv.org/abs/2406.00006, doi:10.48550/arXiv.2406
Liu,Y.,2024.Aprompt-driventaskplanningmethodformulti-drones based on large language model. arXiv preprint arXiv:2406.00006 URL:https://arxiv.org/abs/2406.00006, doi:10.48550/arXiv.2406. 00006
-
[15]
Roco: Dialectic multi- robot collaboration with large language models
Mandi, Z., Jain, S., Song, S., 2023. Roco: Dialectic multi- robot collaboration with large language models. arXiv preprint arXiv:2307.04738 URL:https://arxiv.org/abs/2307.04738, doi:10. 48550/arXiv.2307.04738
arXiv 2023
-
[16]
Llamar: Long-horizon planning for multi-agent robots in partially observable environments
Nayak, S., Orozco, A.M., Ten Have, M., Thirumalai, V., Zhang, J., Chen, D., Kapoor, A., Robinson, E., Gopalakrishnan, K., Harri- son, J., Ichter, B., Mahajan, A., Balakrishnan, H., 2024. Llamar: Long-horizon planning for multi-agent robots in partially observable environments. arXiv preprint arXiv:2407.10031 URL:https:// arxiv.org/abs/2407.10031,doi:10.48...
-
[17]
Tacos: Task agnostic coordinator of a multi-drone system
Nazzari, A., Rubinacci, R., Lovera, M., 2026. Tacos: Task agnostic coordinator of a multi-drone system. Drones 10, 251. URL:https: //www.mdpi.com/2504-446X/10/4/251, doi:10.3390/drones10040251
-
[18]
Obata, K., Aoki, T., Horii, T., Taniguchi, T., Nagai, T., 2024. Lip- llm: Integrating linear programming and dependency graph with large language models for multi-robot task planning. arXiv preprint arXiv:2410.21040 URL:https://arxiv.org/abs/2410.21040, doi:10. 48550/arXiv.2410.21040
arXiv 2024
-
[19]
Panerati, J., Zheng, H., Zhou, S., Xu, J., Prorok, A., Schoellig, A.P.,
-
[20]
URL:https://arxiv.org/abs/2103
Learning to fly–a gym environment with pybullet physics for reinforcement learning of multi-agent quadcopter control, in: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS),pp.7512–7519. URL:https://arxiv.org/abs/2103. 02142, doi:10.1109/IROS51168.2021.9635857
-
[21]
Rahman, M., Sarkar, N.I., Lutui, R., 2025. A survey on multi-uav path planning: Classification, algorithms, open research problems, and future directions. Drones 9, 263. doi:10.3390/drones9040263
-
[22]
Uav-codeagents: Scalable uav mission planning via multi-agent react and vision-language reason- ing
Sautenkov,O.,Yaqoot,Y.,Mustafa,M.A.,Batool,F.,Sam,J.,Lykov, A., Wen, C.Y., Tsetserukou, D., 2025. Uav-codeagents: Scalable uav mission planning via multi-agent react and vision-language reason- ing. arXiv preprint arXiv:2505.07236 URL:https://arxiv.org/abs/ 2505.07236, doi:10.48550/arXiv.2505.07236
-
[23]
AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles
Shah, S., Dey, D., Lovett, C., Kapoor, A., 2017. Airsim: High- fidelity visual and physical simulation for autonomous vehicles, in: Field and Service Robotics, Springer. pp. 621–635. URL:https: //arxiv.org/abs/1705.05065, doi:10.1007/978-3-319-67361-5_40
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-319-67361-5_40 2017
-
[24]
Alfworld: Aligning text and embodied environments for interactive learning, in: Proceedings of the 9th International Conference on Learning Representations
Shridhar, M., Yuan, X., Cote, M.A., Bisk, Y., Trischler, A., Hausknecht, M., 2021. Alfworld: Aligning text and embodied environments for interactive learning, in: Proceedings of the 9th International Conference on Learning Representations. URL:https: //openreview.net/forum?id=0IOX0YcCdTn
2021
-
[25]
Survey on mission planning of multiple unmanned aerial vehicles
Song, J., Zhao, K., Liu, Y., 2023. Survey on mission planning of multiple unmanned aerial vehicles. Aerospace 10, 208. doi:10.3390/ Zhang et al.:Preprint submitted to arXivPage 12 of 13 MultiUAV-Plat aerospace10030208
2023
-
[26]
Song, Y., Naji, S., Kaufmann, E., Loquercio, A., Scaramuzza, D.,
-
[27]
URL:https://arxiv.org/abs/ 2009.00563
Flightmare: A flexible quadrotor simulator, in: Proceedings of the4thConferenceonRobotLearning. URL:https://arxiv.org/abs/ 2009.00563
arXiv 2009
-
[28]
Multi-agent pathfinding: Definitions, variants, and benchmarks, in: Proceedings of the International Symposium on Combinatorial Search, pp
Stern, R., Sturtevant, N.R., Felner, A., Koenig, S., Ma, H., Walker, T.K., Li, J., Atzmon, D., Cohen, L., Kumar, T.K.S., Boyarski, E., Bartak, R., 2019. Multi-agent pathfinding: Definitions, variants, and benchmarks, in: Proceedings of the International Symposium on Combinatorial Search, pp. 151–158. URL:https://movingai.com/ benchmarks/mapf.html
2019
-
[29]
Benchmarks for grid-based pathfinding
Sturtevant, N.R., 2012. Benchmarks for grid-based pathfinding. IEEETransactionsonComputationalIntelligenceandAIinGames4, 144–148. URL:https://www.movingai.com/benchmarks/, doi:10.1109/ TCIAIG.2012.2197681
arXiv 2012
-
[30]
Sun,L.,Jha,D.K.,Hori,C.,Jain,S.,Corcodel,R.,Zhu,X.,Tomizuka, M., Romeres, D., 2024. Interactive planning using large language modelsforpartiallyobservablerobotictasks.2024IEEEInternational Conference on Robotics and Automation (ICRA) URL:https:// arxiv.org/abs/2312.06876, doi:10.1109/ICRA57147.2024.10610981
-
[31]
Dart-llm:Dependency-awaremulti- robottaskdecompositionandexecutionusinglargelanguagemodels
Wang, Y., Xiao, R., Kasahara, J.Y.L., Yajima, R., Nagatani, K., Yamashita,A.,Asama,H.,2024. Dart-llm:Dependency-awaremulti- robottaskdecompositionandexecutionusinglargelanguagemodels. arXiv preprint arXiv:2411.09022 URL:https://arxiv.org/abs/2411. 09022, doi:10.48550/arXiv.2411.09022
-
[32]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei,J.,Wang,X.,Schuurmans,D.,Bosma,M.,Ichter,B.,Xia,F.,Chi, E.,Le,Q.,Zhou,D.,2022.Chain-of-thoughtpromptingelicitsreason- inginlargelanguagemodels. arXivpreprintarXiv:2201.11903URL: https://arxiv.org/abs/2201.11903, doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[33]
Yang, R., Chen, H., Zhang, J., Zhao, M., Qian, C., Wang, K., Wang, Q., Koripella, T.V., Movahedi, M., Li, M., Ji, H., Zhang, H., Zhang, T., 2025. Embodiedbench: Comprehensive benchmark- ing multi-modal large language models for vision-driven embod- ied agents. arXiv preprint arXiv:2502.09560 URL:https://arxiv. org/abs/2502.09560,doi:10.48550/arXiv.2502.09...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09560.codeanddataset: 2025
-
[34]
Yao,S.,Chen,H.,Yang,J.,Narasimhan,K.,2022.Webshop:Towards scalable real-world web interaction with grounded language agents, in: Advances in Neural Information Processing Systems, pp. 20744– 20757. URL:https://arxiv.org/abs/2207.01206
arXiv 2022
-
[35]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan,K.,2023a. Treeofthoughts:Deliberateproblemsolving with large language models. arXiv preprint arXiv:2305.10601 URL: https://arxiv.org/abs/2305.10601, doi:10.48550/arXiv.2305.10601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601
-
[36]
React: Synergizing reasoning and acting in language models, in: Proceedings of the 11th International Conference on Learning Representations
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y., 2023b. React: Synergizing reasoning and acting in language models, in: Proceedings of the 11th International Conference on Learning Representations. URL:https://openreview.net/forum?id= WE_vluYUL-X
-
[37]
Safeagentbench: A benchmark for safe task planning of embodied llm agents
Yin, S., Pang, X., Ding, Y., Chen, M., Bi, Y., Xiong, Y., Huang, W., Xiang, Z., Shao, J., Chen, S., 2024. Safeagentbench: A benchmark for safe task planning of embodied llm agents. arXiv preprint arXiv:2412.13178 URL:https://arxiv.org/abs/2412.13178, doi:10. 48550/arXiv.2412.13178
arXiv 2024
-
[38]
Zha, J., Fan, Y., Zhang, T., Chen, G., Chen, Y., Gao, C., Chen, X.,
-
[39]
arXiv preprint arXiv:2511.11025 URL:https://arxiv.org/abs/2511.11025, doi:10.48550/arXiv.2511
Aircopbench: A benchmark for multi-drone collaborative em- bodied perception and reasoning. arXiv preprint arXiv:2511.11025 URL:https://arxiv.org/abs/2511.11025, doi:10.48550/arXiv.2511. 11025. preprint metadata used because title and publication metadata differed from the AAAI page at audit time. Zhang et al.:Preprint submitted to arXivPage 13 of 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.