What Probing Reveals about Autonomous Driving: Linking Internal Prediction Errors to Ego Planning
Pith reviewed 2026-07-01 05:46 UTC · model grok-4.3
The pith
Autonomous driving policies with strong closed-loop performance often lack timely internal predictions of surrounding vehicles during near-collision events, which limits their ability to generate safe ego plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Despite good closed-loop performance, policies often fail to form timely surrounding-vehicle predictions during near-collision events, revealing a limitation in the predictive signals available for ego planning. Causal intervention shows that correcting mistaken predictions improves ego planning toward safer trajectories.
What carries the argument
Linear probing and targeted perturbations applied to internal layers of imitation and reinforcement learning driving policies to detect and manipulate prediction and planning representations.
If this is right
- Closed-loop simulator scores alone do not confirm the presence of internal prediction or planning capabilities in driving policies.
- Increasing dataset size or training duration does not guarantee stronger internal prediction and planning signals beyond improved heuristics.
- Policies from both behavior cloning and reinforcement learning exhibit similar failures to generate timely surrounding-vehicle predictions in critical scenarios.
- Correcting internal prediction errors produces measurable improvements in the safety of generated ego trajectories.
Where Pith is reading between the lines
- Probing methods of this type could be extended to diagnose internal reasoning in other end-to-end learned control systems beyond driving.
- Training procedures might incorporate explicit auxiliary objectives to encourage accurate internal predictions rather than relying solely on final trajectory performance.
- The results suggest that scaling data and compute may reach a plateau for certain safety-critical capabilities unless predictive representations are directly addressed.
Load-bearing premise
Linear probing reliably identifies whether internal prediction and planning representations exist in the policies, and targeted perturbations can alter those signals without creating unrelated side effects.
What would settle it
An experiment that applies the same interventions to the probed prediction signals during near-collision events but measures no resulting change in ego planning outputs or trajectory safety metrics.
Figures
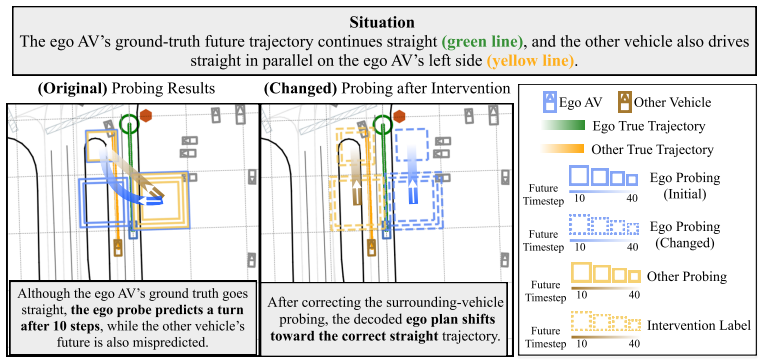
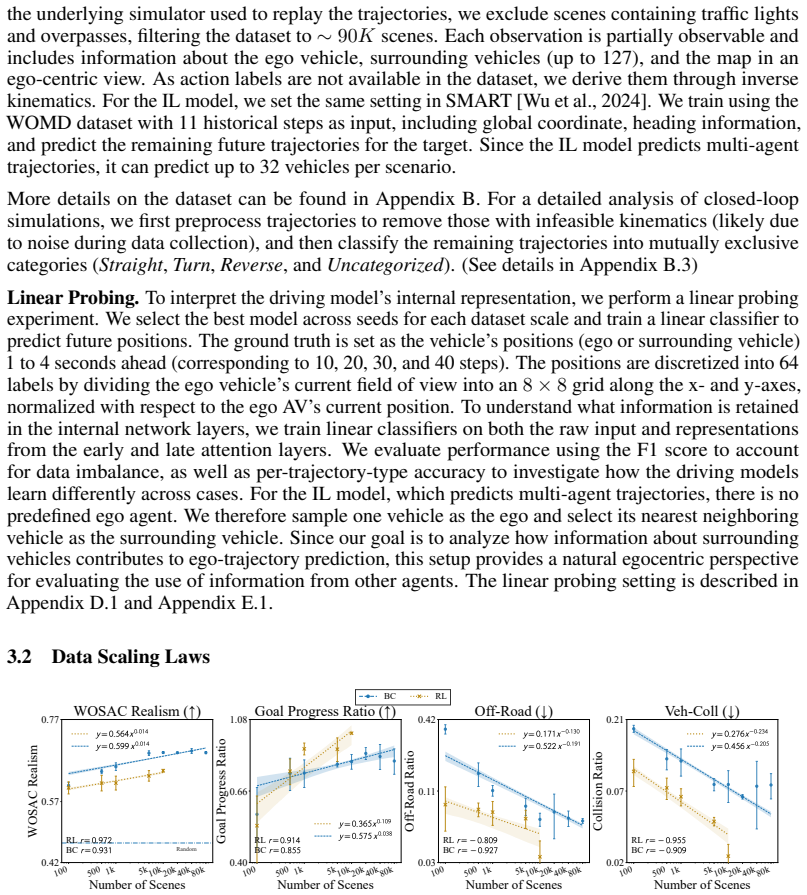
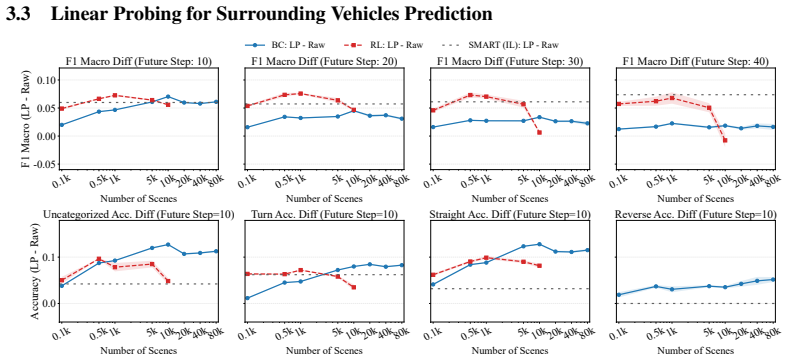
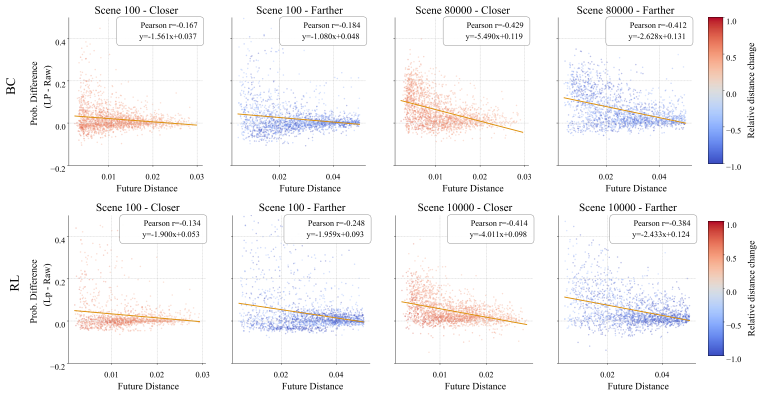

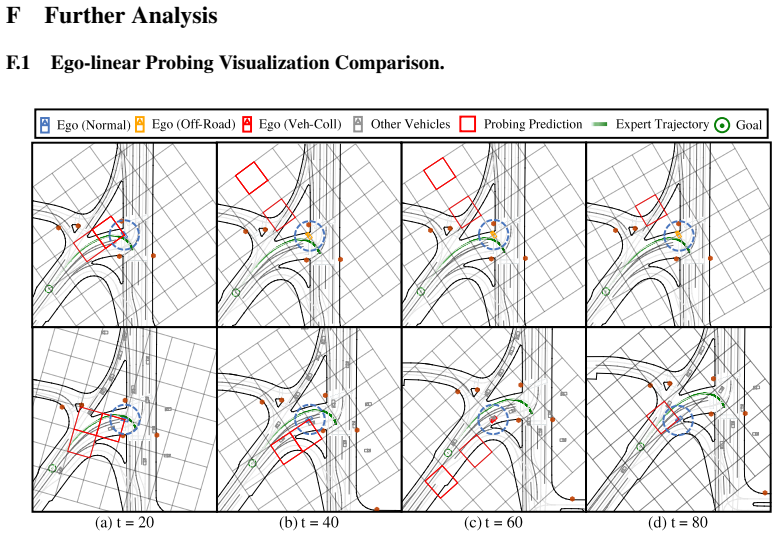
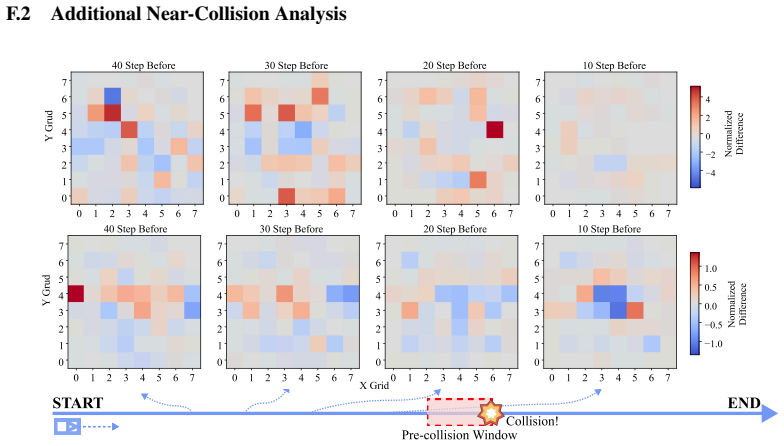

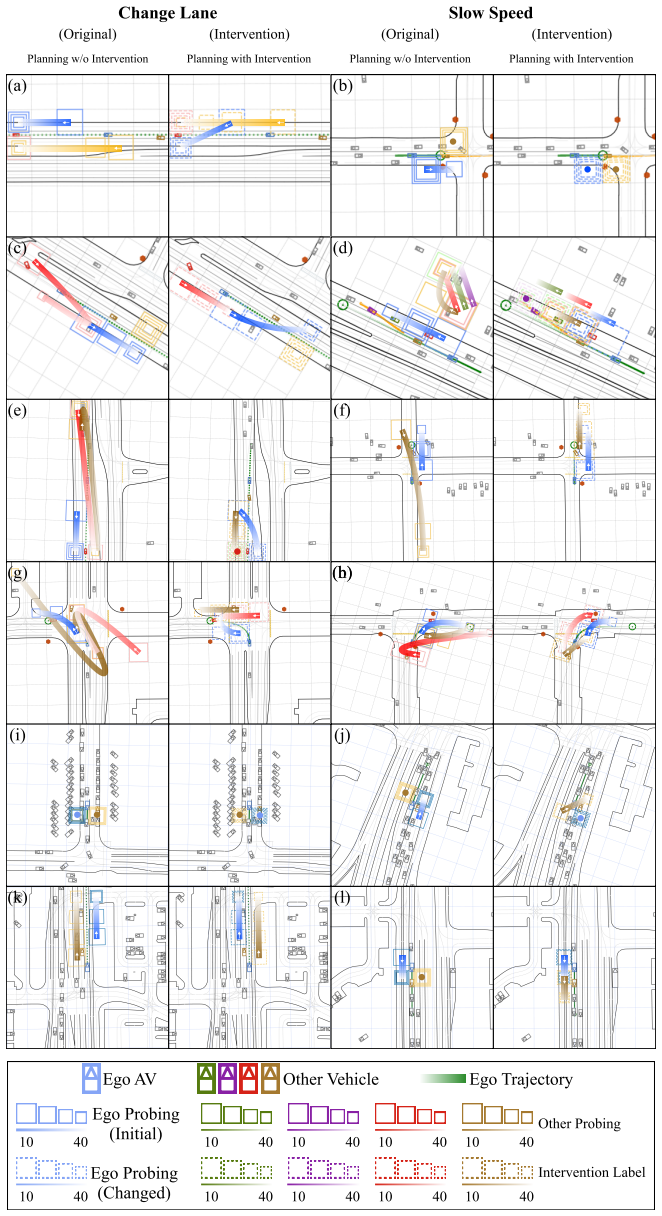
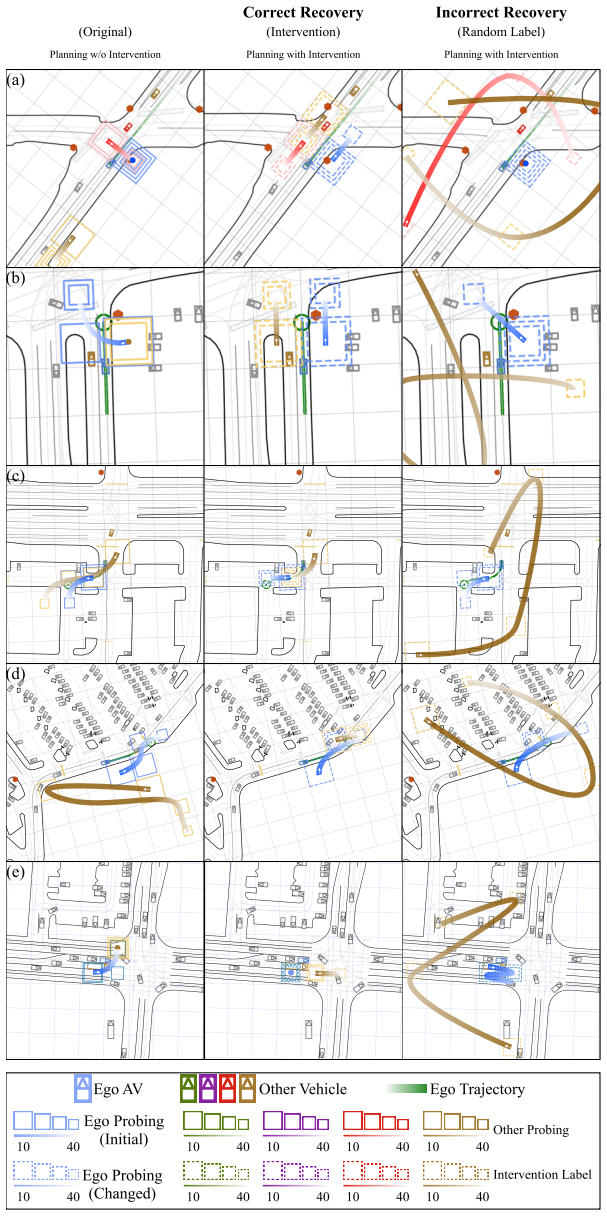
read the original abstract
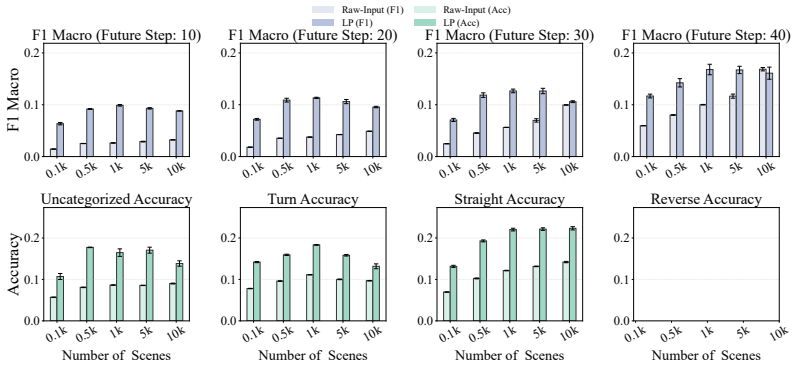
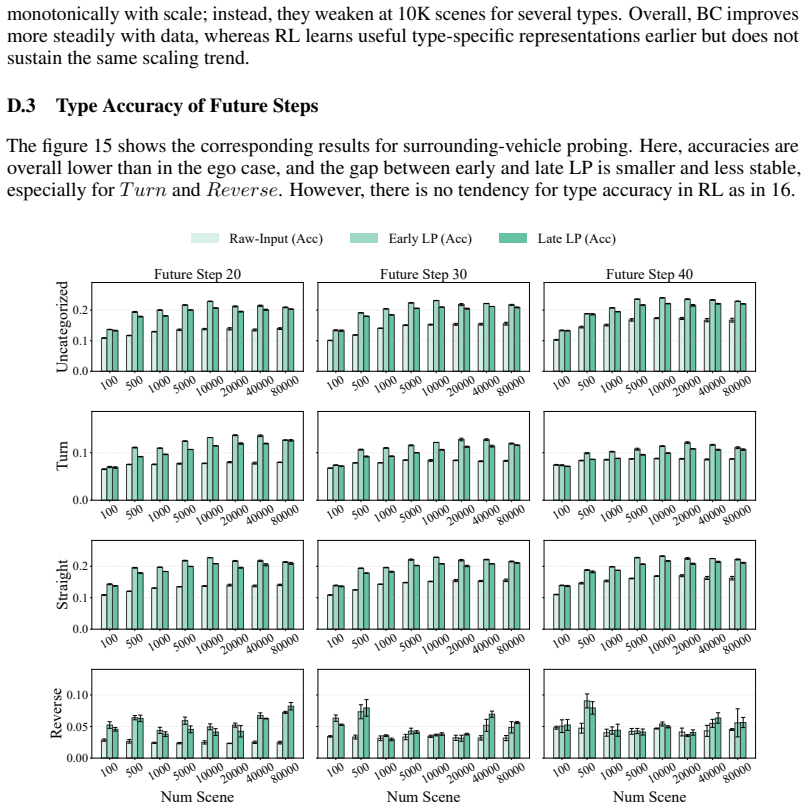
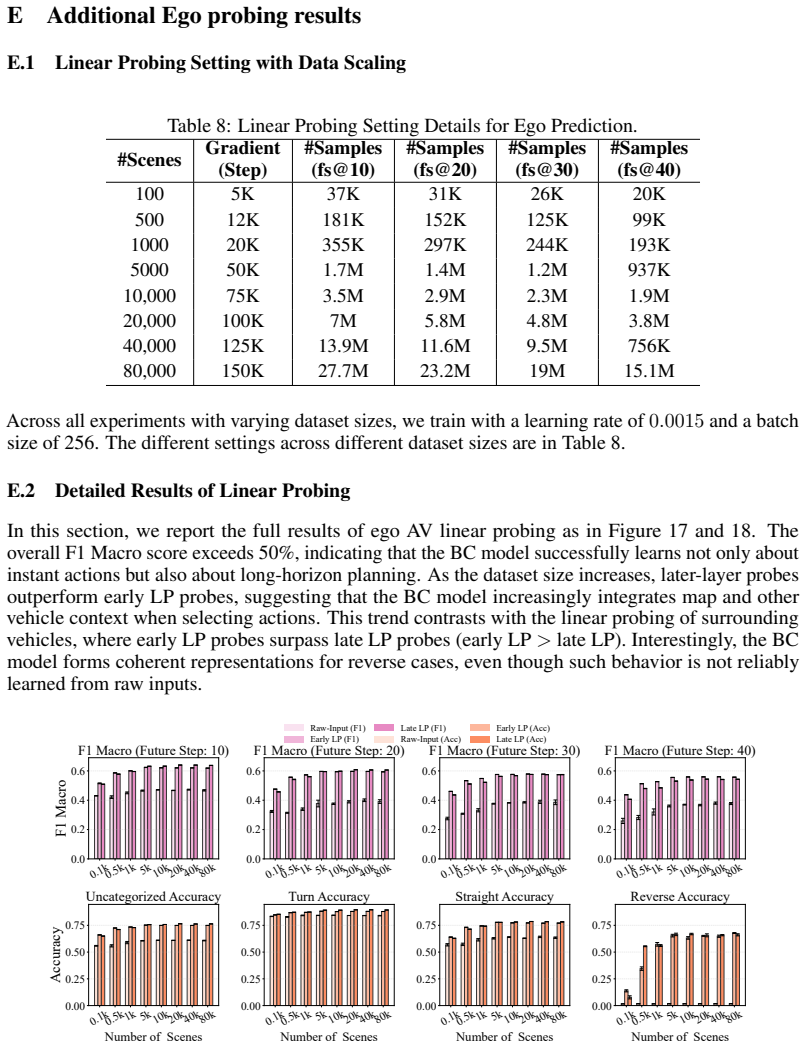
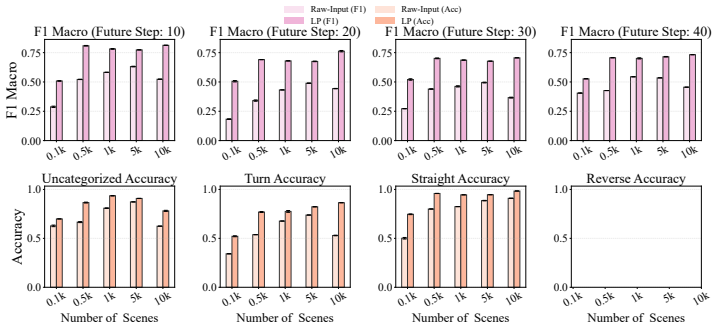
Large-scale datasets and fast simulators have enabled improvements in driving policies that appear safe and robust, yet strong performance in nominal scenarios can still mask flawed reasoning and unsafe heuristics. Summary scores from closed-loop simulators do not give significant insight into the policy, making it difficult to determine whether they truly predict the motion of surrounding vehicles, how the ego vehicle generates future plans, or whether they merely rely on brittle heuristics that happen to succeed in nominal scenarios. To better understand the limits and weaknesses of driving policies, we focus on probing for forms of prediction, i.e., where surrounding vehicles will move next, and planning, i.e., understanding how to generate safe trajectories. We focus on these two capabilities because they reflect behaviors expected of effective driving policies, and use their presence or absence to assess policy quality across data-driven behavior cloning and simulation-driven reinforcement learning policies. To evaluate the presence of these capabilities, we investigate them as a function of scale, asking whether the closed-loop gains from larger datasets and longer simulation training reflect stronger prediction and planning or merely better behavioral heuristics. We use linear probing and targeted perturbations in both imitation learning and reinforcement learning models to track when these internal signals emerge, plateau, or fail. Despite good closed-loop performance, policies often fail to form timely surrounding-vehicle predictions during near-collision events, revealing a limitation in the predictive signals available for ego planning. Finally, causal intervention shows that correcting mistaken predictions improves ego planning toward safer trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates internal representations in autonomous driving policies (imitation learning and reinforcement learning) by applying linear probing to detect prediction of surrounding vehicle motion and planning of ego trajectories, along with targeted perturbations for causal analysis. It claims that despite strong closed-loop performance, policies frequently fail to form timely surrounding-vehicle predictions during near-collision events, limiting the predictive signals available for ego planning; causal correction of mistaken predictions is shown to improve planning toward safer trajectories. The study examines these capabilities as a function of scale (dataset size and training length) to distinguish genuine predictive/planning improvements from behavioral heuristics.
Significance. If the probing and intervention results hold under rigorous validation, the work provides a mechanistic explanation for policy failures in edge cases that aggregate simulator scores obscure, directly linking prediction errors to planning deficiencies. This could guide improvements in policy architectures or training objectives. The empirical approach using external interventions (rather than self-referential derivations) is a positive feature, but its value depends on the validity of linear probes for complex representations.
major comments (2)
- [Probing and intervention methodology (as described in abstract)] The claim that policies 'often fail to form timely surrounding-vehicle predictions during near-collision events' (abstract) rests on linear probes reliably indicating absence of the relevant internal signals. If prediction information is encoded non-linearly (common in deep policies), linear probes can report absence even when the signal exists and is used downstream; this directly undermines the central conclusion about limitations in predictive signals for ego planning.
- [Causal intervention experiments (as described in abstract)] The causal claim that 'correcting mistaken predictions improves ego planning toward safer trajectories' requires that targeted perturbations isolate the intended prediction signals without confounding artifacts or off-target effects on the network. The abstract supplies no details on model architectures, exact perturbation methods, statistical controls, or validation that interventions are specific and causal, which is load-bearing for the intervention results.
minor comments (1)
- [Abstract] The abstract would benefit from explicit definitions of key terms such as 'timely' predictions and 'near-collision events' to allow readers to assess the scope of the reported failures.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments focus on the validity of linear probing and the specificity of causal interventions; both are central to our claims. We respond point by point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Probing and intervention methodology (as described in abstract)] The claim that policies 'often fail to form timely surrounding-vehicle predictions during near-collision events' (abstract) rests on linear probes reliably indicating absence of the relevant internal signals. If prediction information is encoded non-linearly (common in deep policies), linear probes can report absence even when the signal exists and is used downstream; this directly undermines the central conclusion about limitations in predictive signals for ego planning.
Authors: We agree that linear probes can only detect linearly decodable information and therefore cannot rule out non-linear encodings. Our methodology follows the standard practice in mechanistic interpretability of using linear probes as a lower-bound test for the presence of accessible internal signals. The observed correlation between probe failure in near-collision regimes and subsequent planning deficiencies, together with the intervention results, supports the interpretation that predictive signals are limited. Nevertheless, the referee's point is valid: the manuscript language should not equate absence of a linear signal with complete absence of any representation. In revision we will (i) qualify all claims to refer specifically to linearly extractable prediction signals and (ii) add an explicit limitations paragraph discussing non-linear encodings and possible future non-linear probe experiments. revision: partial
-
Referee: [Causal intervention experiments (as described in abstract)] The causal claim that 'correcting mistaken predictions improves ego planning toward safer trajectories' requires that targeted perturbations isolate the intended prediction signals without confounding artifacts or off-target effects on the network. The abstract supplies no details on model architectures, exact perturbation methods, statistical controls, or validation that interventions are specific and causal, which is load-bearing for the intervention results.
Authors: The full manuscript contains the requested details: architectures for both imitation-learning and RL policies, the perturbation procedure (activation editing along probe-derived directions), control experiments that measure off-target effects, and statistical reporting of intervention outcomes. The abstract, however, is deliberately concise and therefore omits these elements. We will revise the abstract to include a short clause describing the intervention approach and will ensure the methods and results sections contain explicit validation of specificity (e.g., null interventions on unrelated directions). These changes will make the causal evidence more transparent without altering the experimental design. revision: yes
Circularity Check
Empirical probing study with no derivation chain
full rationale
The paper is an empirical investigation that applies linear probing and targeted perturbations to existing imitation and RL driving policies, then measures outcomes via closed-loop simulation and causal interventions. No equations, fitted parameters, or self-referential definitions are introduced whose outputs are later presented as independent predictions. All load-bearing claims rest on external experimental measurements rather than any internal reduction to the paper's own inputs or prior self-citations. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
nuScenes: A multimodal dataset for autonomous driving , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
2023 IEEE international conference on robotics and automation (ICRA) , pages=
Trafficgen: Learning to generate diverse and realistic traffic scenarios , author=. 2023 IEEE international conference on robotics and automation (ICRA) , pages=. 2023 , organization=
2023
-
[3]
2021 , booktitle=
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting , author=. 2021 , booktitle=
2021
-
[4]
Advances in Neural Information Processing Systems , volume=
Model-based imitation learning for urban driving , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Reinforcement Learning Conference , year=
Human-compatible driving agents through data-regularized self-play reinforcement learning , author=. Reinforcement Learning Conference , year=
-
[6]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[7]
European Conference on Computer Vision , pages=
Beyond the Data Imbalance: Employing the Heterogeneous Datasets for Vehicle Maneuver Prediction , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Argoverse: 3d tracking and forecasting with rich maps , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Advances in Neural Information Processing Systems , volume=
Waymax: An accelerated, data-driven simulator for large-scale autonomous driving research , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Revisiting neural scaling laws in language and vision , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Scaling Laws for Autoregressive Generative Modeling
Scaling laws for autoregressive generative modeling , author=. arXiv preprint arXiv:2010.14701 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
2025 , url=
Saman Kazemkhani and Aarav Pandya and Daphne Cornelisse and Brennan Shacklett and Eugene Vinitsky , booktitle=. 2025 , url=
2025
-
[13]
Advances in Neural Information Processing Systems , volume=
Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Motion transformer with global intention localization and local movement refinement , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Wayformer: Motion forecasting via simple & efficient attention networks , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[16]
Conference on Robot Learning , pages=
MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction , author=. Conference on Robot Learning , pages=. 2020 , organization=
2020
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Motionlm: Multi-agent motion forecasting as language modeling , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
European conference on computer vision , pages=
Drivelm: Driving with graph visual question answering , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[19]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Drama: Joint risk localization and captioning in driving , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[20]
2025 , booktitle=
WOMD-Reasoning: A Large-Scale Dataset for Interaction Reasoning in Driving , author=. 2025 , booktitle=
2025
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Is ego status all you need for open-loop end-to-end autonomous driving? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes , author=. arXiv preprint arXiv:2305.10430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
CausalAgents: A robustness benchmark for motion forecasting , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[24]
The Thirteenth International Conference on Learning Representations , year=
Interpreting Emergent Planning in Model-Free Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[25]
International conference on machine learning , pages=
An investigation of model-free planning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[26]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[27]
Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
Linguistic regularities in continuous space word representations , author=. Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
2013
-
[28]
arXiv preprint arXiv:2412.02689 , year=
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving , author=. arXiv preprint arXiv:2412.02689 , year=
-
[29]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Data Scaling Laws for End-to-End Autonomous Driving , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[30]
Scaling Laws of Motion Forecasting and Planning--A Technical Report , author=. arXiv preprint arXiv:2506.08228 , year=
-
[31]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[32]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[33]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[36]
IEEE Transactions on Robotics , volume=
Interactive autonomous navigation with internal state inference and interactivity estimation , author=. IEEE Transactions on Robotics , volume=. 2024 , publisher=
2024
-
[37]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Reinforcement learning for autonomous driving with latent state inference and spatial-temporal relationships , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
2021
-
[38]
Scene Transformer: A unified architecture for predicting future trajectories of multiple agents , author=
-
[39]
European Conference on Computer Vision , pages=
Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[40]
2024 , booktitle=
Trajeglish: Traffic Modeling as Next-Token Prediction , author=. 2024 , booktitle=
2024
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
On exposing the challenging long tail in future prediction of traffic actors , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Shared cross-modal trajectory prediction for autonomous driving , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Pedestrian and ego-vehicle trajectory prediction from monocular camera , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
Forecasting From LiDAR via Future Object Detection , booktitle =
Peri, Neehar and Luiten, Jonathon and Li, Mengtian and O. Forecasting From LiDAR via Future Object Detection , booktitle =. 2022 , pages =
2022
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Dian and Kr\"ahenb\"uhl, Philipp , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scept: Scene-consistent, policy-based trajectory predictions for planning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Hu, Yihan and Yang, Jiazhi and Chen, Li and Li, Keyu and Sima, Chonghao and Zhu, Xizhou and Chai, Siqi and Du, Senyao and Lin, Tianwei and Wang, Wenhai and Lu, Lewei and Jia, Xiaosong and Liu, Qiang and Dai, Jifeng and Qiao, Yu and Li, Hongyang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2...
2023
-
[48]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[49]
Conference on Robot Learning , pages=
Jfp: Joint future prediction with interactive multi-agent modeling for autonomous driving , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[50]
arXiv preprint arXiv:2504.11521 , year=
LANGTRAJ: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation , author=. arXiv preprint arXiv:2504.11521 , year=
-
[51]
Conference on Robot Learning , pages=
Action-based representation learning for autonomous driving , author=. Conference on Robot Learning , pages=. 2021 , organization=
2021
-
[52]
Advances in Neural Information Processing Systems , volume=
The waymo open sim agents challenge , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
2025 , note =
Daphne Cornelisse and Spencer Cheng and Pragnay Mandavilli and Julian Hunt and Kevin Joseph and Wa. 2025 , note =
2025
-
[54]
International Conference on Learning Representations , volume=
Words in motion: Extracting interpretable control vectors for motion transformers , author=. International Conference on Learning Representations , volume=
-
[55]
Transformer Circuits Thread , volume=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Smart: Scalable multi-agent real-time motion generation via next-token prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Building reliable sim driving agents by scaling self-play , author=. arXiv preprint arXiv:2502.14706 , year=
-
[58]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.