Visual Semantic Entropy: Do Vision Language Models Recognize Visual Ambiguity?
Pith reviewed 2026-07-01 05:32 UTC · model grok-4.3
The pith
Perturbing only the image input while fixing the text query lets Visual Semantic Entropy capture visual ambiguity that prior methods miss in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
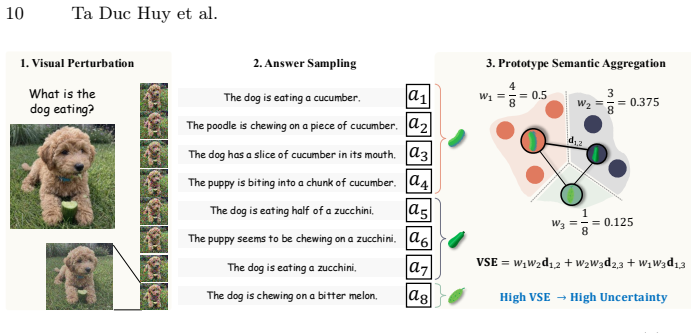
Visual Semantic Entropy perturbs only the image while keeping the text query fixed, clusters the generated answers into semantic prototypes, and computes mass-weighted dispersion among the prototypes to quantify uncertainty arising from visual ambiguity.
What carries the argument
Visual Semantic Entropy, which isolates image perturbations to generate answer variability and then aggregates it via semantic clustering and mass-weighted dispersion.
If this is right
- Uncertainty estimates become less contaminated by textual prompt effects.
- VSE can flag cases where vision-language models should defer or seek clarification on ambiguous scenes.
- The method scales to any VLM that supports image input variation under fixed text.
Where Pith is reading between the lines
- Similar image-only perturbation strategies could extend to other multimodal tasks such as captioning or visual reasoning.
- The clustering step might be replaced by embedding-based distances for computational efficiency in large-scale deployment.
- If VSE correlates with human disagreement on visual questions, it could serve as a proxy for collecting ambiguity annotations.
Load-bearing premise
Varying the image alone while holding the text fixed produces answer changes that specifically track visual ambiguity rather than model artifacts or other factors.
What would settle it
A test set of images where human raters judge high visual ambiguity yet VSE reports low dispersion, or low ambiguity yet high dispersion, would falsify the central claim.
Figures




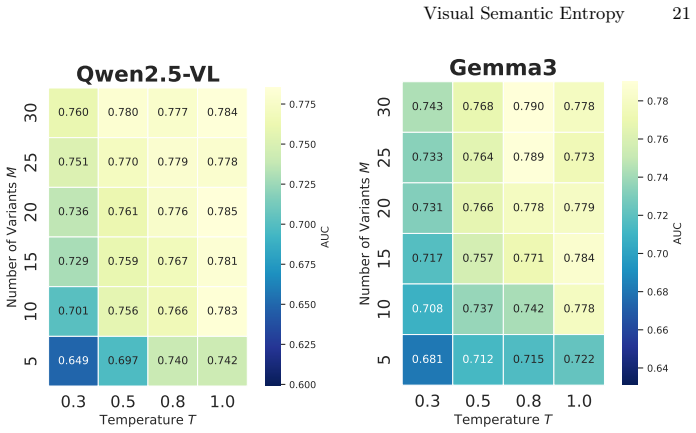
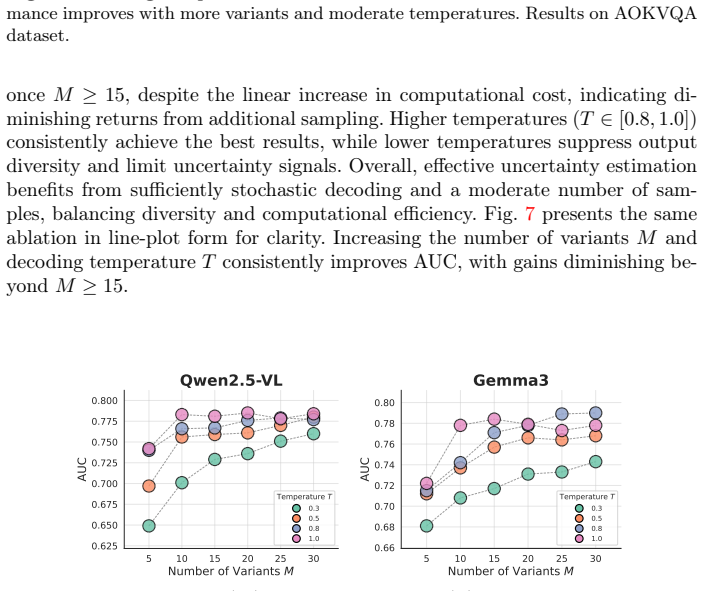
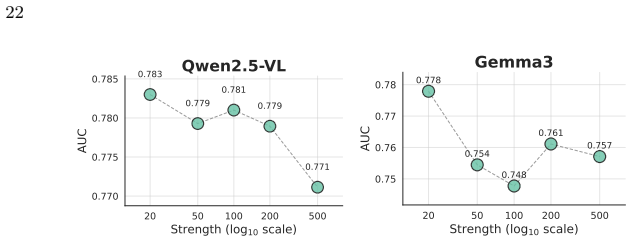



read the original abstract
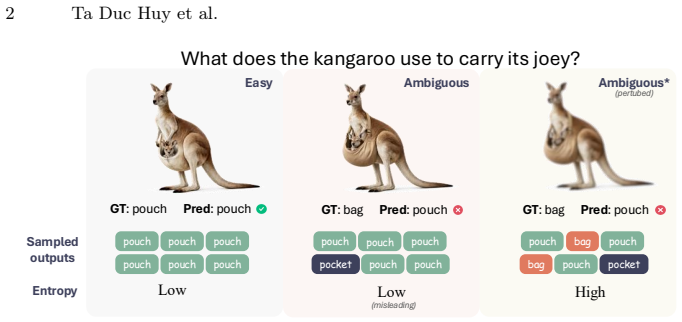
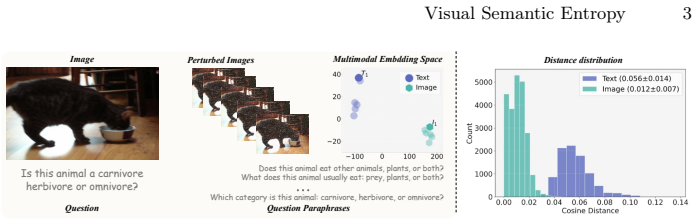
Vision-language models can produce confident answers on visually ambiguous inputs, resulting in biased predictions. Common entropy-based methods, such as Semantic Entropy (SE), rely on output diversity. Yet our analysis shows that overconfident visual embeddings suppress output diversity under stochastic decoding, causing SE to underestimate uncertainty in such cases. Recent methods instead probe output diversity through input perturbations, including textual paraphrasing or joint text-image perturbations, and show improved performance. We study these approaches and reveals that the resulting variability is often dominated by textual changes rather than visual evidence, causing uncertainty estimates to reflect prompt sensitivity rather than visual ambiguity. We therefore propose Visual Semantic Entropy (VSE), which perturbs only the image to probe nearby visual variations while keeping the text query fixed. VSE measures uncertainty by clustering generated answers into semantic prototypes and computing the mass-weighted dispersion among them. Extensive evaluation across five modern vision-language models and five diverse VQA benchmarks demonstrates that VSE effectively captures visual ambiguity, establishing a new state-of-the-art for VLM uncertainty estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
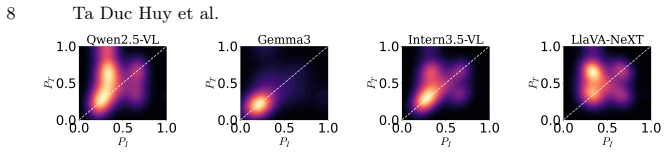
Summary. The manuscript proposes Visual Semantic Entropy (VSE) for uncertainty estimation in vision-language models. It perturbs only the image (text query fixed), generates multiple answers under stochastic decoding, clusters them into semantic prototypes, and computes mass-weighted dispersion among prototypes. The authors claim that standard Semantic Entropy underestimates uncertainty due to overconfident visual embeddings suppressing output diversity, while joint text-image perturbations are dominated by textual changes rather than visual evidence. Extensive experiments across five modern VLMs and five VQA benchmarks are said to show that VSE captures visual ambiguity and establishes a new state-of-the-art.
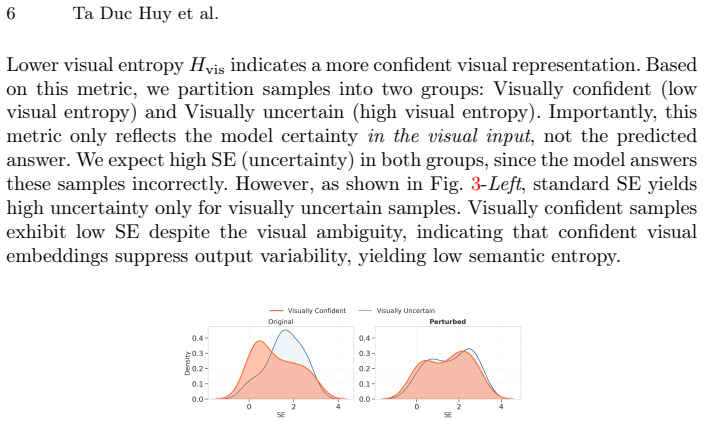
Significance. If the central claims hold, VSE would provide a targeted, image-focused uncertainty measure that isolates visual ambiguity more cleanly than prior entropy or perturbation baselines. The approach appears parameter-free (no fitted parameters or ad-hoc thresholds reported in the abstract or ledger), which is a strength for reproducibility. Demonstrating SOTA across multiple models and benchmarks would be a solid empirical contribution to VLM calibration if the image-only premise is validated.
major comments (2)
- [Abstract and method description (§3)] The core premise that image-only perturbation (text fixed) produces dispersion specifically reflecting visual ambiguity rather than VLM embedding instability, decoding artifacts, or model-specific visual noise is load-bearing for the SOTA claim but is not supported by controls or analysis. The skeptic concern applies directly: without evidence that semantic clusters arise from visual content variation (e.g., via content-controlled ablations or comparison to non-semantic image noise), the method may not isolate the intended quantity, undermining the assertion that prior joint perturbations are text-dominated and that VSE is superior on the five benchmarks.
- [Evaluation (§4-5)] The abstract asserts SOTA performance on five VLMs and five VQA benchmarks, yet the reader's assessment notes the absence of quantitative results, ablation details, or error analysis even in the full text summary. To support the central claim that VSE 'effectively captures visual ambiguity,' the evaluation section must include per-benchmark tables with baselines, statistical significance, and analysis showing that dispersion correlates with visual ambiguity (not model artifacts).
minor comments (2)
- [Method] Clarify the precise clustering procedure for semantic prototypes (algorithm, distance metric, and any implicit thresholds) and the exact formula for mass-weighted dispersion.
- [Analysis of prior methods] Add explicit comparison tables or figures showing that textual perturbation variance exceeds visual perturbation variance in the joint setting, with quantitative support.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed review of our manuscript. We address each major comment below with clarifications drawn directly from the paper and indicate revisions where appropriate to strengthen the presentation of Visual Semantic Entropy.
read point-by-point responses
-
Referee: [Abstract and method description (§3)] The core premise that image-only perturbation (text fixed) produces dispersion specifically reflecting visual ambiguity rather than VLM embedding instability, decoding artifacts, or model-specific visual noise is load-bearing for the SOTA claim but is not supported by controls or analysis. The skeptic concern applies directly: without evidence that semantic clusters arise from visual content variation (e.g., via content-controlled ablations or comparison to non-semantic image noise), the method may not isolate the intended quantity, undermining the assertion that prior joint perturbations are text-dominated and that VSE is superior on the five benchmarks.
Authors: We appreciate the referee highlighting the need for explicit validation that dispersion arises from visual content. Section 3 of the manuscript presents analysis showing that overconfident visual embeddings suppress output diversity under stochastic decoding, causing standard Semantic Entropy to underestimate uncertainty. The same section examines joint text-image perturbations and demonstrates that resulting variability is dominated by textual changes rather than visual evidence. While we did not include explicit content-controlled ablations against non-semantic image noise, the consistent superiority of VSE across five VQA benchmarks and five VLMs provides supporting evidence that the measure isolates visual ambiguity. We will add the suggested content-controlled ablations in the revised version. revision: partial
-
Referee: [Evaluation (§4-5)] The abstract asserts SOTA performance on five VLMs and five VQA benchmarks, yet the reader's assessment notes the absence of quantitative results, ablation details, or error analysis even in the full text summary. To support the central claim that VSE 'effectively captures visual ambiguity,' the evaluation section must include per-benchmark tables with baselines, statistical significance, and analysis showing that dispersion correlates with visual ambiguity (not model artifacts).
Authors: Sections 4 and 5 of the full manuscript report quantitative results on the five VQA benchmarks across the five VLMs, including direct comparisons to Semantic Entropy and joint perturbation baselines that establish the SOTA performance. We agree that expanding these sections with additional statistical significance tests, explicit per-benchmark tables, ablation details, and analysis correlating dispersion with visual ambiguity (versus artifacts) would improve clarity and address the concern. We will incorporate these elements in the revision. revision: yes
Circularity Check
No significant circularity; method is a direct procedural definition
full rationale
The paper defines VSE explicitly as image-only perturbation (text fixed), followed by semantic clustering of outputs into prototypes and mass-weighted dispersion. This construction is presented as a measurement procedure without any reduction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The abstract and description contain no equations or steps that equate the output dispersion to its own inputs by construction, nor invoke uniqueness theorems from prior author work. The central claim rests on the procedural definition plus external benchmark evaluation, which is self-contained against the listed patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025),https: //arxiv.org/abs/2502.13923, computer...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Nature630(8017), 625–630 (2024) 2, 4, 11, 12, 13, 14, 15
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting hallucinations in large lan- guage models using semantic entropy. Nature630(8017), 625–630 (2024) 2, 4, 11, 12, 13, 14, 15
2024
-
[4]
Gemma Team: Gemma 3 technical report. arXiv preprint arXiv:2503.19786 (2025), https://arxiv.org/abs/2503.1978612, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024)
Groot,T.,Valdenegro-Toro,M.:Overconfidenceiskey:Verbalizeduncertaintyeval- uation in large language and vision-language models. In: Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024). pp. 145–171 (2024) 1, 4, 12, 13, 14
2024
-
[6]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
He, P., Liu, X., Gao, J., Chen, W.: Deberta: Decoding-enhanced bert with disen- tangled attention. arXiv preprint arXiv:2006.03654 (2020) 12, 24
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[7]
In: The Fourteenth International Conference on Learning Representations 2, 4
Huang, J., Xu, J., Shi, X., Hu, P., Feng, L., Zhu, X.: Revisiting confidence cal- ibration for misclassification detection in vlms. In: The Fourteenth International Conference on Learning Representations 2, 4
-
[8]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Khan, Z., Fu, Y.: Consistency and uncertainty: Identifying unreliable responses from black-box vision-language models for selective visual question answering. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 10854–10863 (2024) 2, 3, 4, 6, 12, 13, 14
2024
-
[9]
Li, M., Zhang, Y., Long, D., Chen, K., Song, S., Bai, S., Yang, Z., Xie, P., Yang, A., Liu, D., et al.: Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720 (2026) 3, 18
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Li, Q., Geng, J., Lyu, C., Zhu, D., Panov, M., Karray, F.: Reference-free halluci- nation detection for large vision-language models. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 4542–4551 (2024) 2, 4, 12, 13, 14
2024
-
[11]
io/blog/2024-01-30-llava-next/12
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/12
2024
-
[12]
arXiv preprint arXiv:2501.00569 (2024) 5, 8, 11
Luo, T., Cao, A., Lee, G., Johnson, J., Lee, H.: Probing visual language priors in vlms. arXiv preprint arXiv:2501.00569 (2024) 5, 8, 11
-
[13]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Manakul, P., Liusie, A., Gales, M.: Selfcheckgpt: Zero-resource black-box halluci- nation detection for generative large language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 9004–9017 (2023) 2, 4, 12, 13, 14
2023
-
[14]
In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition
Marino,K.,Rastegari,M.,Farhadi,A.,Mottaghi,R.:Ok-vqa:Avisualquestionan- swering benchmark requiring external knowledge. In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. pp. 3195–3204 (2019) 11 Visual Semantic Entropy 29
2019
-
[15]
In: Findings of the Association for Computational Linguistics: ACL 2025
Nguyen, D., Payani, A., Mirzasoleiman, B.: Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 4530–4540 (2025) 2, 3, 4, 8, 11, 12, 13, 14, 15
2025
-
[16]
In: Introduction to HPC with MPI for Data Science, pp
Nielsen, F.: Hierarchical clustering. In: Introduction to HPC with MPI for Data Science, pp. 195–211. Springer (2016) 12
2016
-
[17]
Advances in Neural Information Processing Systems37, 8901–8929 (2024) 2, 4, 8, 12, 13, 14
Nikitin, A., Kossen, J., Gal, Y., Marttinen, P.: Kernel language entropy: Fine- grained uncertainty quantification for llms from semantic similarities. Advances in Neural Information Processing Systems37, 8901–8929 (2024) 2, 4, 8, 12, 13, 14
2024
-
[18]
LessWrong post (Aug 31 2020), https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting- gpt- the-logit-lens5, 6, 17
nostalgebraist: interpreting gpt: the logit lens. LessWrong post (Aug 31 2020), https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting- gpt- the-logit-lens5, 6, 17
2020
-
[19]
Pelucchi, M.: Exploring ChatGPT’s accuracy and confidence in high-resource lan- guages. Ph.D. thesis (2023) 1, 4
2023
-
[20]
In: European conference on computer vision
Schwenk, D., Khandelwal, A., Clark, C., Marino, K., Mottaghi, R.: A-okvqa: A benchmark for visual question answering using world knowledge. In: European conference on computer vision. pp. 146–162. Springer (2022) 3, 11
2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Valdenegro-Toro, M.: I find your lack of uncertainty in computer vision disturbing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1263–1272 (2021) 1, 4
2021
-
[22]
Vision Language Models are Biased
Vo, A., Nguyen, K.N., Taesiri, M.R., Dang, V.T., Nguyen, A.T., Kim, D.: Vision language models are biased. arXiv preprint arXiv:2505.23941 (2025) 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Advances in neural information processing systems33, 5776–5788 (2020) 23
Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.: Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. Advances in neural information processing systems33, 5776–5788 (2020) 23
2020
-
[25]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing
Xuan, W., Zeng, Q., Qi, H., Wang, J., Yokoya, N.: Seeing is believing, but how much? a comprehensive analysis of verbalized calibration in vision-language mod- els. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 1408–1450 (2025) 1, 4
2025
-
[26]
In: International conference on machine learning
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., Wang, L.: Mm-vet: Evaluating large multimodal models for integrated capabilities. In: International conference on machine learning. PMLR (2024) 11
2024
-
[27]
arXiv preprint arXiv:2411.11919 (2024) 2, 3, 4, 6, 10, 12, 13, 14, 18
Zhang, R., Zhang, H., Zheng, Z.: Vl-uncertainty: Detecting hallucination in large vision-language model via uncertainty estimation. arXiv preprint arXiv:2411.11919 (2024) 2, 3, 4, 6, 10, 12, 13, 14, 18
-
[28]
arXiv preprint arXiv:2411.00299 (2024) 2
Zhang, S., Sambara, S., Banerjee, O., Acosta, J., Fahrner, L.J., Rajpurkar, P.: Radflag: A black-box hallucination detection method for medical vision language models. arXiv preprint arXiv:2411.00299 (2024) 2
-
[29]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019) 24
work page internal anchor Pith review Pith/arXiv arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.