Falsification, Not Exposure: An Internally Preregistered Placebo-Controlled Decomposition of Self-Repair Feedback in Frozen Small Code Models
Pith reviewed 2026-07-01 04:41 UTC · model grok-4.3
The pith
Feedback in frozen code models repairs programs by enabling comparison to executable counterexamples rather than by re-exposure to failing code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
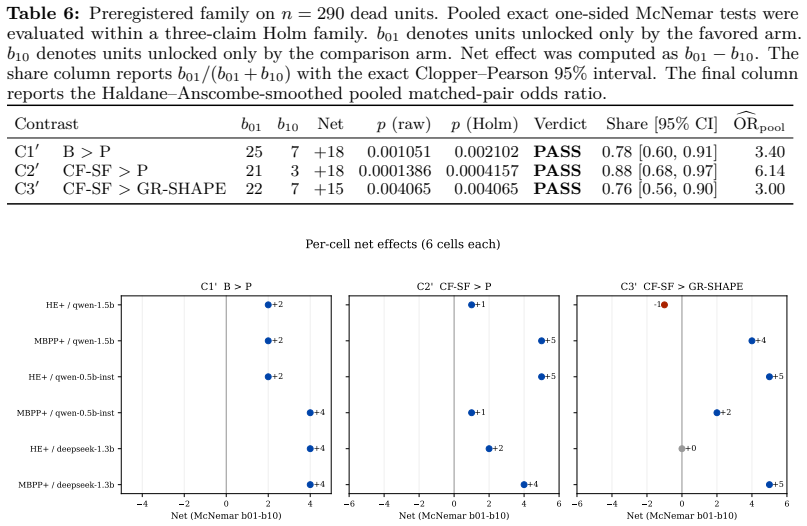
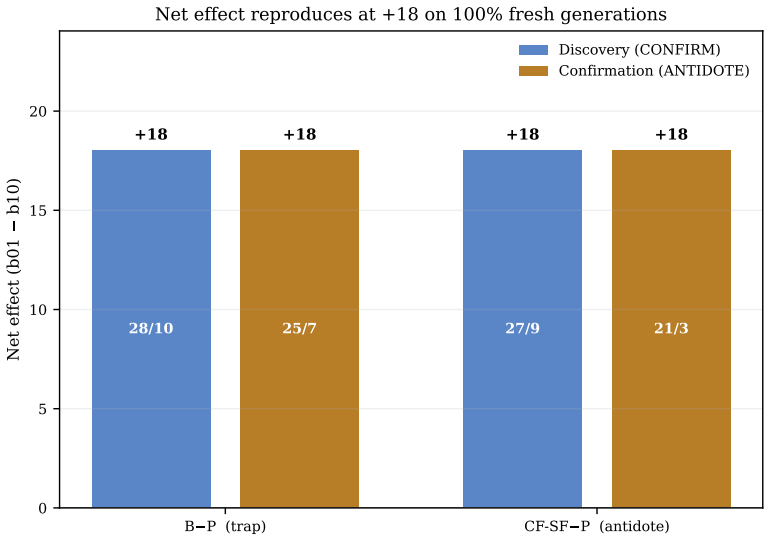
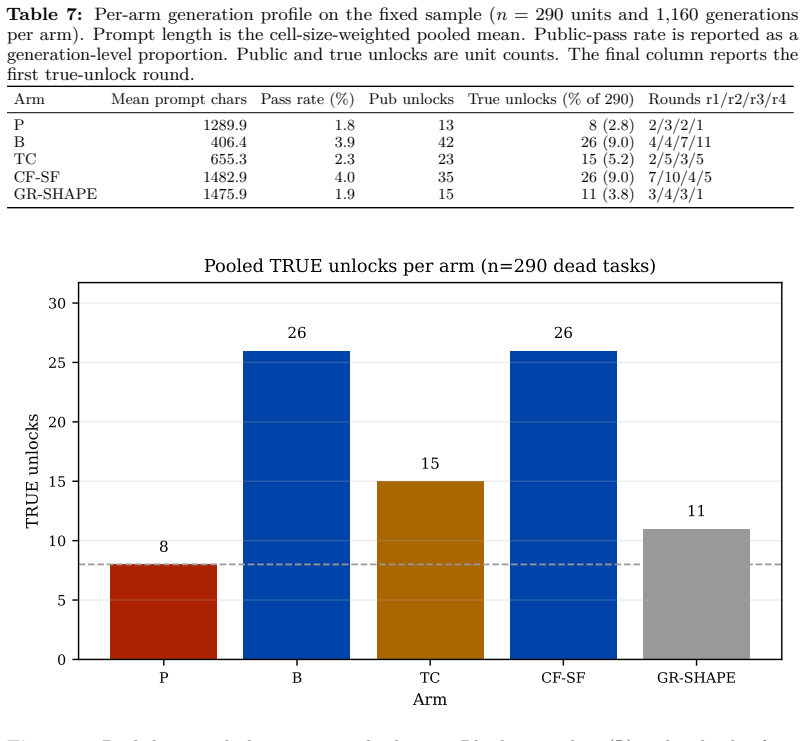
Across six HumanEval+/MBPP+ cells with three 0.5B-1.5B frozen models, 290 dead task-cell units were evaluated with 7,000 fresh generations in the main run and 1,400 more in a preregistered follow-up. Blind resampling exceeded bare-code retry by +18 net unlocks. Code-plus-facts recovered +18 over bare code and +15 over a generic-bullet placebo. An instruction-only effect was not distinguishable. Code-plus-facts and blind resampling tied at 26 unlocks each. Six external-controller follow-ups tied a content-free shape placebo. In this regime, falsification helped not as vocabulary or self-critique, but as comparison with external, executable counterexamples. The contribution is a reflexive meth
What carries the argument
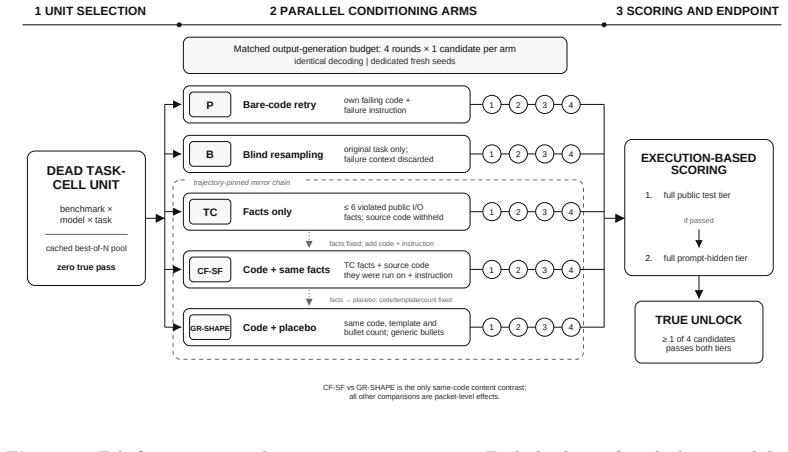
The placebo-controlled instrument that decomposes the feedback packet by contrasting its elements against a blind-resampling baseline at matched output-generation budget and content-free shape-matched placebos.
If this is right
- Blind resampling at matched budget produces more net repairs than retrying with the original failing code alone.
- Augmenting code with facts from test executions outperforms both bare code and generic-bullet placebos.
- Instruction-only feedback does not yield a distinguishable improvement over placebos.
- The decomposition method allows any feedback-content claim to be audited through fresh generations and external execution checks.
Where Pith is reading between the lines
- If the advantage requires executable test results rather than any descriptive text, then feedback prompts should be redesigned to surface verifiable counterexamples first.
- The same decomposition could be applied to non-code tasks such as mathematical derivations to test whether external criticism generalizes beyond program execution.
- Scaling the instrument to models above 1.5B parameters would show whether the falsification effect remains dominant or yields to other mechanisms.
- Repeating the discordant-pair tests on a different benchmark set would confirm whether the +18 unlock margin holds outside the six cells examined.
Load-bearing premise
The assumption that the placebo controls and blind resampling are truly content-free or matched in a way that isolates the falsification effect without introducing other variables like generation quality differences.
What would settle it
A follow-up run that keeps the same generation budget and shape but replaces the executable counterexamples with non-executable descriptive text, and finds that the net unlock advantage over bare code disappears.
Figures
read the original abstract
In deployment settings where retraining is infeasible, small frozen code models are routinely asked to repair a failed program after seeing their own failing output, usually treated as a retry mechanism. From a Popperian view, a generated program is a conjecture and a test-execution violation is an oracle-relative, executable counterexample, so feedback's value should be attributed not to re-exposure to failing code but to whether the conjecture is opened to external, executable criticism. As the third stage of a falsification-centered measurement program, this study builds a placebo-controlled instrument that decomposes the feedback packet against a blind-resampling baseline at matched output-generation budget and against content-free, shape-matched placebos. The contribution is not a new repair algorithm but a reflexive methodology (packet decomposition, placebo mirroring, matched-budget discordant-pair tests, fresh-generation confirmation, executable audits) that makes both the model's program conjecture and the researcher's "feedback content works" claim falsifiable. Across six HumanEval+/MBPP+ cells with three 0.5B-1.5B frozen models, 290 dead task-cell units (no best-of-8 candidate passing the public tier) were evaluated; the main run produced 7,000 fresh generations and a preregistered follow-up 1,400 more. Blind resampling exceeded bare-code retry by +18 net unlocks (25/7, Holm p=0.0021). Code-plus-facts recovered +18 over bare code (21/3, p=0.00042) and +15 over a generic-bullet placebo (p=0.0041). An instruction-only effect was not distinguishable (+3, p=0.36). Code-plus-facts and blind resampling tied at 26 unlocks each (not equivalence). Six external-controller follow-ups tied a content-free shape placebo. In this regime, falsification helped not as vocabulary or self-critique, but as comparison with external, executable counterexamples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feedback benefits in self-repair for small frozen code models (0.5B–1.5B) arise specifically from comparison against external, executable counterexamples rather than re-exposure to failing code, vocabulary, or self-critique. It introduces a reflexive, placebo-controlled decomposition instrument using blind resampling at matched output-generation budget and content-free shape-matched placebos on 290 dead HumanEval+/MBPP+ task-cells, reporting statistically significant net unlocks (blind resampling +18 over bare retry, Holm p=0.0021; code-plus-facts +15 over generic-bullet placebo, p=0.0041) across 7000+ fresh generations plus a preregistered follow-up, with external audits and no distinguishable instruction-only effect.
Significance. If the decomposition holds, the work supplies a falsifiable methodology (packet decomposition, placebo mirroring, matched-budget discordant-pair tests, executable audits) for attributing feedback effects in code repair, with explicit credit for preregistration, external audits, fresh-generation confirmation, and parameter-free statistical framing. It reframes self-repair as Popperian conjecture-criticism rather than retry, which could inform deployment practices where retraining is infeasible.
major comments (2)
- [Abstract] Abstract (controls and instrument description): The central claim that gains are due to 'comparison with external, executable counterexamples' rather than prompt-structure confounds rests on blind resampling and the generic-bullet placebo being content-free and shape-matched. The manuscript states these controls are budget-matched and shape-matched but does not report post-hoc audits confirming equivalence on generation statistics such as output length or syntactic variety; this is load-bearing because any systematic difference would undermine attribution of the reported +18 net unlocks (25/7) and +15 advantage (p=0.0041).
- [Abstract] Abstract (results paragraph): The statement that 'Code-plus-facts and blind resampling tied at 26 unlocks each (not equivalence)' is presented without a formal equivalence test or power analysis for the tie; given the small per-cell sample (290 dead units across six cells), this weakens the claim that the two conditions are interchangeable for isolating the falsification mechanism.
minor comments (2)
- [Abstract] The term 'net unlocks' is used repeatedly but its exact definition (e.g., how ties or partial improvements are scored) is not restated in the abstract; a one-sentence operational definition would improve readability.
- [Abstract] The six external-controller follow-ups are mentioned only in passing; a brief parenthetical on what 'tied a content-free shape placebo' means operationally would clarify the robustness check.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract's control descriptions and statistical framing. We address each point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (controls and instrument description): The central claim that gains are due to 'comparison with external, executable counterexamples' rather than prompt-structure confounds rests on blind resampling and the generic-bullet placebo being content-free and shape-matched. The manuscript states these controls are budget-matched and shape-matched but does not report post-hoc audits confirming equivalence on generation statistics such as output length or syntactic variety; this is load-bearing because any systematic difference would undermine attribution of the reported +18 net unlocks (25/7) and +15 advantage (p=0.0041).
Authors: We agree that post-hoc verification of generation statistics is warranted to confirm shape-matching. The revised manuscript will add explicit audits reporting mean/variance of output token lengths and syntactic variety (AST node counts and unique token-type diversity) for blind resampling versus the generic-bullet placebo, showing no material differences. These statistics were computed on the existing 7000+ generations but omitted for brevity; they will be inserted into the methods and results. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): The statement that 'Code-plus-facts and blind resampling tied at 26 unlocks each (not equivalence)' is presented without a formal equivalence test or power analysis for the tie; given the small per-cell sample (290 dead units across six cells), this weakens the claim that the two conditions are interchangeable for isolating the falsification mechanism.
Authors: The parenthetical qualifier was added specifically to avoid any implication of equivalence. We will nevertheless strengthen the revision by including a post-hoc power calculation for detecting a difference of 5 unlocks (given observed variance and n=290) and a brief note that the data remain consistent with comparable performance. The primary claims rest on the significant contrasts versus bare retry and the generic placebo, not on interchangeability of the two high-performing conditions. revision: yes
Circularity Check
No circularity: empirical results from external benchmarks and preregistered controls
full rationale
The paper reports an empirical decomposition using HumanEval+/MBPP+ tasks, net-unlock counts, Holm-adjusted p-values, and matched-budget baselines. No equations, fitted parameters, or self-citations are invoked to derive the central claims; the +18 net unlocks and placebo comparisons are direct experimental outcomes rather than reductions of the inputs. The methodology is presented as falsifiable and reflexive, with no load-bearing self-referential definitions or ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Statistical tests like Holm correction for multiple comparisons are valid for the reported p-values.
- domain assumption The task cells with no best-of-8 passing are appropriate for testing repair feedback.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
austin2021mbpp APACrefauthors Austin, J. , Odena, A. , Nye, M. , Bosma, M. , Michalewski, H. , Dohan, D. , Jiang, E. , Cai, C. , Terry, M. , Le, Q. \ Sutton, C. APACrefauthors \ 2021 . Program Synthesis with Large Language Models. Program synthesis with large language models. APACrefURL https://arxiv.org/abs/2108.07732 APACrefURL
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
brown2024monkeys APACrefauthors Brown, B. , Juravsky, J. , Ehrlich, R. , Clark, R. , Le, Q V. , R \'e , C. \ Mirhoseini, A. APACrefauthors \ 2024 . Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Large language monkeys: Scaling inference compute with repeated sampling. APACrefURL https://arxiv.org/abs/2407.21787 APACrefURL
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
brucks2025prompt APACrefauthors Brucks, M. \ Toubia, O. APACrefauthors \ 2025 . Prompt Architecture Induces Methodological Artifacts in Large Language Models Prompt architecture induces methodological artifacts in large language models . PLOS ONE 20 4 e0319159 . APACrefDOI doi:10.1371/journal.pone.0319159 APACrefDOI
-
[4]
chen2024funcoder APACrefauthors Chen, J. , Tang, H. , Chu, Z. , Chen, Q. , Wang, Z. , Liu, M. \ Qin, B. APACrefauthors \ 2024 . Divide-and-Conquer Meets Consensus: Unleashing the Power of Functions in Code Generation Divide-and-conquer meets consensus: Unleashing the power of functions in code generation . Advances in Neural Information Processing Systems...
-
[5]
Evaluating Large Language Models Trained on Code
chen2021humaneval APACrefauthors Chen, M. , Tworek, J. , Jun, H. , Yuan, Q. , de Oliveira Pinto, H P. , Kaplan, J. , Edwards, H. , Burda, Y. , Joseph, N. , Brockman, G. , Ray, A. , Puri, R. , Krueger, G. , Petrov, M. , Khlaaf, H. , Sastry, G. , Mishkin, P. , Chan, B. , Gray, S. , Ryder, N. , Pavlov, M. , Power, A. , Kaiser, L. , Bavarian, M. , Winter, C. ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Teaching Large Language Models to Self-Debug
chen2024selfdebug APACrefauthors Chen, X. , Lin, M. , Sch\" a rli, N. \ Zhou, D. APACrefauthors \ 2024 . Teaching Large Language Models to Self-Debug Teaching large language models to self-debug . The Twelfth International Conference on Learning Representations. The twelfth international conference on learning representations. APACrefURL https://arxiv.org...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
cho2025cocos APACrefauthors Cho, J. , Kang, D. , Kim, H. \ Lee, G G. APACrefauthors \ 2025 . Self-Correcting Code Generation Using Small Language Models Self-correcting code generation using small language models . Findings of the Association for Computational Linguistics: EMNLP 2025 Findings of the association for computational linguistics: Emnlp 2025 \ ...
-
[8]
chow2025inferenceaware APACrefauthors Chow, Y. , Tennenholtz, G. , Gur, I. , Zhuang, V. , Dai, B. , Thiagarajan, S. , Boutilier, C. , Agarwal, R. , Kumar, A. \ Faust, A. APACrefauthors \ 2025 . Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models Inference-aware fine-tuning for best-of-n sampling in large language models . Internati...
-
[9]
damani2024hard APACrefauthors Damani, M. , Shenfeld, I. , Peng, A. , Bobu, A. \ Andreas, J. APACrefauthors \ 2025 . Learning How Hard to Think: Input-Adaptive Allocation of LM Computation Learning how hard to think: Input-adaptive allocation of LM computation . International Conference on Learning Representations (ICLR). International conference on learni...
-
[10]
ding2024cycle APACrefauthors Ding, Y. , Min, M J. , Kaiser, G. \ Ray, B. APACrefauthors \ 2024 . CYCLE : Learning to Self-Refine the Code Generation CYCLE : Learning to self-refine the code generation . Proceedings of the ACM on Programming Languages (OOPSLA). Proceedings of the acm on programming languages (oopsla). APACrefURL https://arxiv.org/abs/2403....
-
[11]
dinh2023bugs APACrefauthors Dinh, T. , Zhao, J. , Tan, S. , Negrinho, R. , Lausen, L. , Zha, S. \ Karypis, G. APACrefauthors \ 2023 . Large Language Models of Code Fail at Completing Code with Potential Bugs Large language models of code fail at completing code with potential bugs . Advances in Neural Information Processing Systems 36 (NeurIPS). Advances ...
-
[12]
fagerland2013mcnemar APACrefauthors Fagerland, M W. , Lydersen, S. \ Laake, P. APACrefauthors \ 2013 . The McNemar test for binary matched-pairs data: mid-p and asymptotic are better than exact conditional The McNemar test for binary matched-pairs data: mid-p and asymptotic are better than exact conditional . BMC Medical Research Methodology 13 1 91 . APA...
-
[13]
gorman2019splits APACrefauthors Gorman, K. \ Bedrick, S. APACrefauthors \ 2019 . We Need to Talk about Standard Splits We need to talk about standard splits . Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) Proceedings of the 57th annual meeting of the association for computational linguistics (acl) \ ( \ 2786...
-
[14]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
guo2024deepseekcoder APACrefauthors Guo, D. , Zhu, Q. , Yang, D. , Xie, Z. , Dong, K. , Zhang, W. , Chen, G. , Bi, X. , Wu, Y. , Li, Y K. , Luo, F. , Xiong, Y. \ Liang, W. APACrefauthors \ 2024 . DeepSeek-Coder : When the Large Language Model Meets Programming -- The Rise of Code Intelligence. DeepSeek-Coder : When the large language model meets programmi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
hofman2023prereg APACrefauthors Hofman, J M. , Chatzimparmpas, A. , Sharma, A. , Watts, D J. \ Hullman, J. APACrefauthors \ 2023 . Pre-registration for Predictive Modeling. Pre-registration for predictive modeling. APACrefURL https://arxiv.org/abs/2311.18807 APACrefURL
-
[16]
APACrefauthors \ 1979
holm1979simple APACrefauthors Holm, S. APACrefauthors \ 1979 . A Simple Sequentially Rejective Multiple Test Procedure A simple sequentially rejective multiple test procedure . Scandinavian Journal of Statistics 6 2 65--70
1979
-
[17]
, Chen, X
huang2024cannot APACrefauthors Huang, J. , Chen, X. , Mishra, S. , Zheng, H S. , Yu, A W. , Song, X. \ Zhou, D. APACrefauthors \ 2024 . Large Language Models Cannot Self-Correct Reasoning Yet Large language models cannot self-correct reasoning yet . The Twelfth International Conference on Learning Representations. The twelfth international conference on l...
2024
-
[18]
Qwen2.5-Coder Technical Report
hui2024qwen25coder APACrefauthors Hui, B. , Yang, J. , Cui, Z. , Yang, J. , Liu, D. , Zhang, L. , Liu, T. , Zhang, J. , Yu, B. , Lu, K. , Dang, K. , Fan, Y. , Zhang, Y. , Yang, A. , Men, R. , Huang, F. , Zheng, B. , Miao, Y. , Quan, S. , Feng, Y. , Ren, X. , Ren, X. , Zhou, J. \ Lin, J. APACrefauthors \ 2024 . Qwen2.5-Coder Technical Report. Qwen2.5-Coder...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
iscan2026scaffold APACrefauthors \. I s can, M. APACrefauthors \ 2026 1 . Scaffold, Not Vocabulary? A Controlled, Two-Tier, Pre-Registered Study of a Popperian Code-Generation Skill. Scaffold, not vocabulary? a controlled, two-tier, pre-registered study of a popperian code-generation skill. APACrefURL https://arxiv.org/abs/2606.06454 APACrefURL
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
iscan2026selection APACrefauthors \. I s can, M. APACrefauthors \ 2026 2 . Selection Without Signal, Recovery Through Expression: A Measurement Study of Post-Hoc Falsification Operators for Frozen Small Code Models. Selection without signal, recovery through expression: A measurement study of post-hoc falsification operators for frozen small code models. ...
-
[21]
jiang2024ledex APACrefauthors Jiang, N. , Li, X. , Wang, S. , Zhou, Q. , Hossain, S B. , Ray, B. , Kumar, V. , Ma, X. \ Deoras, A. APACrefauthors \ 2024 . LeDex : Training LLMs to Better Self-Debug and Explain Code LeDex : Training LLMs to better self-debug and explain code . Advances in Neural Information Processing Systems 37 (NeurIPS). Advances in neur...
-
[22]
jin2025selfcritiquefail APACrefauthors Jin, H. \ Chen, H. APACrefauthors \ 2025 . Uncovering Systematic Failures of LLMs in Verifying Code Against Natural Language Specifications Uncovering systematic failures of LLMs in verifying code against natural language specifications . 2025 40th IEEE/ACM International Conference on Automated Software Engineering (...
-
[23]
jones2022cognitivebiases APACrefauthors Jones, E. \ Steinhardt, J. APACrefauthors \ 2022 . Capturing Failures of Large Language Models via Human Cognitive Biases Capturing failures of large language models via human cognitive biases . Advances in Neural Information Processing Systems 35 (NeurIPS). Advances in neural information processing systems 35 (neur...
-
[24]
khojah2025promptprogramming APACrefauthors Khojah, R. , de Oliveira Neto, F G. , Mohamad, M. \ Leitner, P. APACrefauthors \ 2025 . The Impact of Prompt Programming on Function-Level Code Generation The impact of prompt programming on function-level code generation . IEEE Transactions on Software Engineering 51 8 2381--2401 . APACrefDOI doi:10.1109/TSE.202...
-
[25]
lam2025codecrash APACrefauthors Lam, M H. , Wang, C. , Huang, J t. \ Lyu, M R. APACrefauthors \ 2025 . CodeCrash : Stress Testing LLM Reasoning under Structural and Semantic Perturbations. CodeCrash : Stress testing LLM reasoning under structural and semantic perturbations. APACrefURL https://arxiv.org/abs/2504.14119 APACrefURL
- [26]
-
[27]
, Xia, C S
liu2023evalplus APACrefauthors Liu, J. , Xia, C S. , Wang, Y. \ Zhang, L. APACrefauthors \ 2023 . Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation . Advances in Neural Informat...
2023
-
[28]
Self-Refine: Iterative Refinement with Self-Feedback
madaan2023selfrefine APACrefauthors Madaan, A. , Tandon, N. , Gupta, P. , Hallinan, S. , Gao, L. , Wiegreffe, S. , Alon, U. , Dziri, N. , Prabhumoye, S. , Yang, Y. , Gupta, S. , Majumder, B P. , Hermann, K. , Welleck, S. , Yazdanbakhsh, A. \ Clark, P. APACrefauthors \ 2023 . Self-Refine : Iterative Refinement with Self-Feedback Self-Refine : Iterative ref...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
mayospanos2006severe APACrefauthors Mayo, D G. \ Spanos, A. APACrefauthors \ 2006 . Severe Testing as a Basic Concept in a Neyman--Pearson Philosophy of Induction Severe testing as a basic concept in a Neyman--Pearson philosophy of induction . The British Journal for the Philosophy of Science 57 2 323--357 . Advance Access published April 11, 2006 APACref...
-
[30]
mcnemar1947note APACrefauthors McNemar, Q. APACrefauthors \ 1947 . Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages Note on the sampling error of the difference between correlated proportions or percentages . Psychometrika 12 2 153--157 . APACrefDOI doi:10.1007/BF02295996 APACrefDOI
-
[31]
, Inala, J P
olausson2024selfrepair APACrefauthors Olausson, T X. , Inala, J P. , Wang, C. , Gao, J. \ Solar-Lezama, A. APACrefauthors \ 2024 . Is Self-Repair a Silver Bullet for Code Generation? Is self-repair a silver bullet for code generation? Proceedings of the Twelfth International Conference on Learning Representations (ICLR). Proceedings of the twelfth interna...
2024
-
[32]
panickssery2024selfrecognition APACrefauthors Panickssery, A. , Bowman, S R. \ Feng, S. APACrefauthors \ 2024 . LLM Evaluators Recognize and Favor Their Own Generations LLM evaluators recognize and favor their own generations . Advances in Neural Information Processing Systems 37 (NeurIPS 2024). Advances in neural information processing systems 37 (neurip...
-
[33]
APACrefauthors \ 1959
popper1959logic APACrefauthors Popper, K R. APACrefauthors \ 1959 . The Logic of Scientific Discovery The logic of scientific discovery . London Hutchinson . English translation of Logik der Forschung (1934); degree of corroboration C(h,e) in Appendix *ix
1959
-
[34]
APACrefauthors \ 1963
popper1963conjectures APACrefauthors Popper, K R. APACrefauthors \ 1963 . Conjectures and Refutations: The Growth of Scientific Knowledge Conjectures and refutations: The growth of scientific knowledge . London Routledge and Kegan Paul . Verisimilitude/truthlikeness in ch. 10 and Addenda
1963
-
[35]
rizqullah2026tdp APACrefauthors Rizqullah, M. \ Albassam, E. APACrefauthors \ 2026 . Model-Agnostic Empirical Evaluation of Test-Driven Prompt Engineering on Improving Accuracy and Efficiency in Large Language Models Python Code Generation Model-agnostic empirical evaluation of test-driven prompt engineering on improving accuracy and efficiency in large l...
-
[36]
sclar2024formatting APACrefauthors Sclar, M. , Choi, Y. , Tsvetkov, Y. \ Suhr, A. APACrefauthors \ 2024 . Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design, or: How I Learned to Start Worrying about Prompt Formatting Quantifying language models' sensitivity to spurious features in prompt design, or: How I learned to start worr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Reflexion: Language Agents with Verbal Reinforcement Learning
shinn2023reflexion APACrefauthors Shinn, N. , Cassano, F. , Berman, E. , Gopinath, A. , Narasimhan, K. \ Yao, S. APACrefauthors \ 2023 . Reflexion : Language Agents with Verbal Reinforcement Learning Reflexion : Language agents with verbal reinforcement learning . Advances in Neural Information Processing Systems (NeurIPS). Advances in neural information ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
singhi2025solve APACrefauthors Singhi, N. , Bansal, H. , Hosseini, A. , Grover, A. , Chang, K W. , Rohrbach, M. \ Rohrbach, A. APACrefauthors \ 2025 . When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning When to solve, when to verify: Compute-optimal problem solving and generative verification for LL...
-
[39]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
snell2024testtime APACrefauthors Snell, C. , Lee, J. , Xu, K. \ Kumar, A. APACrefauthors \ 2025 . Scaling LLM Test-Time Compute Optimally Can Be More Effective than Scaling Model Parameters Scaling LLM test-time compute optimally can be more effective than scaling model parameters . International Conference on Learning Representations (ICLR). Internationa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
song2025mindthegap APACrefauthors Song, Y. , Zhang, H. , Eisenach, C. , Kakade, S M. , Foster, D. \ Ghai, U. APACrefauthors \ 2025 . Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models Mind the gap: Examining the self-improvement capabilities of large language models . International Conference on Learning Representations (IC...
-
[41]
stechly2025selfverification APACrefauthors Stechly, K. , Valmeekam, K. \ Kambhampati, S. APACrefauthors \ 2025 . On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks On the self-verification limitations of large language models on reasoning and planning tasks . International Conference on Learning Representations (...
-
[42]
takallou2026llms APACrefauthors Takallou, M A. , Gautam, A. \ Shirolkar, P. APACrefauthors \ 2026 . LLMs for End-to-End Machine Learning: A Comprehensive Review LLMs for end-to-end machine learning: A comprehensive review . IEEE Access 14 47717--47738 . APACrefDOI doi:10.1109/ACCESS.2026.3678429 APACrefDOI
-
[43]
tian2024debugbench APACrefauthors Tian, R. , Ye, Y. , Qin, Y. , Cong, X. , Lin, Y. , Pan, Y. , Wu, Y. , Hui, H. , Liu, W. , Liu, Z. \ Sun, M. APACrefauthors \ 2024 . DebugBench : Evaluating Debugging Capability of Large Language Models DebugBench : Evaluating debugging capability of large language models . Findings of the Association for Computational Lin...
-
[44]
tversky1974judgment APACrefauthors Tversky, A. \ Kahneman, D. APACrefauthors \ 1974 . Judgment under Uncertainty: Heuristics and Biases Judgment under uncertainty: Heuristics and biases . Science 185 4157 1124--1131 . APACrefDOI doi:10.1126/science.185.4157.1124 APACrefDOI
-
[45]
valmeekam2023self APACrefauthors Valmeekam, K. , Marquez, M. \ Kambhampati, S. APACrefauthors \ 2023 . Can Large Language Models Really Improve by Self-critiquing Their Own Plans? Can Large Language Models Really Improve by Self-critiquing Their Own Plans? APACrefURL https://arxiv.org/abs/2310.08118 APACrefURL Preprint. arXiv:2310.08118, 12 Oct 2023
-
[46]
wang2025plansearch APACrefauthors Wang, E. , Cassano, F. , Wu, C. , Bai, Y. , Song, W. , Nath, V. , Han, Z. , Hendryx, S. , Yue, S. \ Zhang, H. APACrefauthors \ 2025 . Planning in Natural Language Improves LLM Search for Code Generation Planning in natural language improves LLM search for code generation . International Conference on Learning Representati...
-
[47]
wang2024software APACrefauthors Wang, J. , Huang, Y. , Chen, C. , Liu, Z. , Wang, S. \ Wang, Q. APACrefauthors \ 2024 . Software Testing With Large Language Models: Survey, Landscape, and Vision Software testing with large language models: Survey, landscape, and vision . IEEE Transactions on Software Engineering 50 4 911--936 . APACrefDOI doi:10.1109/TSE....
-
[48]
yang2024cotton APACrefauthors Yang, G. , Zhou, Y. , Chen, X. , Zhang, X. , Zhuo, T Y. \ Chen, T. APACrefauthors \ 2024 . Chain-of-Thought in Neural Code Generation: From and for Lightweight Language Models Chain-of-thought in neural code generation: From and for lightweight language models . IEEE Transactions on Software Engineering 50 9 2437--2457 . APAC...
-
[49]
zhang2023algo APACrefauthors Zhang, K. , Wang, D. , Xia, J. , Wang, W Y. \ Li, L. APACrefauthors \ 2023 . ALGO : Synthesizing Algorithmic Programs with LLM -Generated Oracle Verifiers ALGO : Synthesizing algorithmic programs with LLM -generated oracle verifiers . Advances in Neural Information Processing Systems 36 (NeurIPS). Advances in neural informatio...
-
[50]
zheng2025multiturn APACrefauthors Zheng, K. , Decugis, J. , Gehring, J. , Cohen, T. , Negrevergne, B. \ Synnaeve, G. APACrefauthors \ 2025 . What Makes Large Language Models Reason in (Multi-Turn) Code Generation? What makes large language models reason in (multi-turn) code generation? International Conference on Learning Representations (ICLR). Internati...
-
[51]
zheng2024opencodeinterpreter APACrefauthors Zheng, T. , Zhang, G. , Shen, T. , Liu, X. , Lin, B Y. , Fu, J. , Chen, W. \ Yue, X. APACrefauthors \ 2024 . OpenCodeInterpreter : Integrating Code Generation with Execution and Refinement OpenCodeInterpreter : Integrating code generation with execution and refinement . Findings of the Association for Computatio...
-
[52]
zheng2025understanding APACrefauthors Zheng, Z. , Ning, K. , Zhong, Q. , Chen, J. , Chen, W. , Guo, L. , Wang, W. \ Wang, Y. APACrefauthors \ 2025 . Towards an Understanding of Large Language Models in Software Engineering Tasks Towards an understanding of large language models in software engineering tasks . Empirical Software Engineering 30 2 50 . APACr...
-
[53]
zhong2024ldb APACrefauthors Zhong, L. , Wang, Z. \ Shang, J. APACrefauthors \ 2024 . Debug like a Human: A Large Language Model Debugger via Verifying Runtime Execution Step by Step Debug like a human: A large language model debugger via verifying runtime execution step by step . Findings of the Association for Computational Linguistics: ACL 2024 Findings...
-
[54]
zubair2025repair APACrefauthors Zubair, F. , Al-Hitmi, M. \ Catal, C. APACrefauthors \ 2025 . The Use of Large Language Models for Program Repair The use of large language models for program repair . Computer Standards & Interfaces 93 103951 . APACrefDOI doi:10.1016/j.csi.2024.103951 APACrefDOI
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.