Attend, Transform, or Silence: Operator-Level Visual Skipping for Efficient Multimodal LLM Inference
Pith reviewed 2026-07-01 05:41 UTC · model grok-4.3
The pith
Operator-level skipping of redundant attention and FFN on visual tokens cuts MLLM computation while retaining nearly full accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
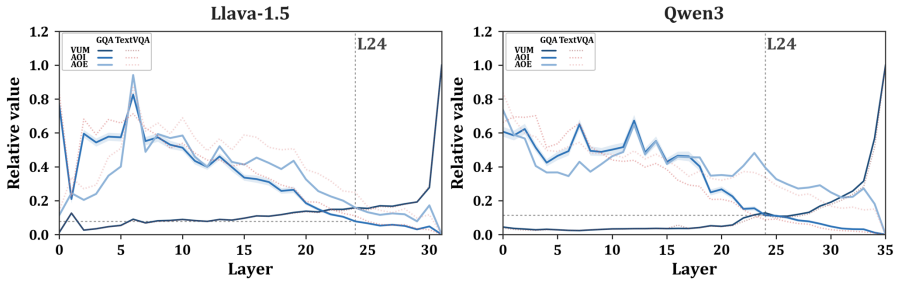
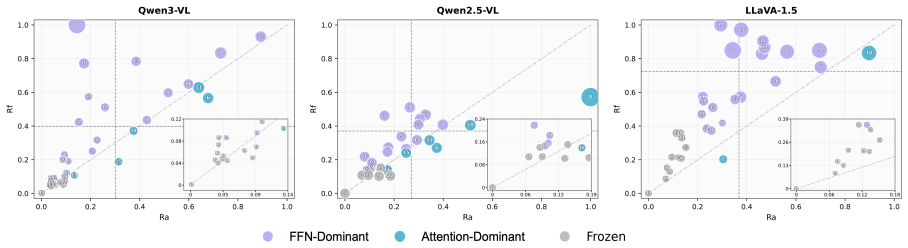
Late visual-token updates frequently exhibit answer-silent redundancy: their magnitude is high while their effect on answer-token representations is low. Useful visual computation is operator-dominant and layer-dependent, so an operator-level skipping policy that selectively bypasses attention, FFN, or both inside individual layers can preserve the complete visual-token sequence and still reduce overall computation.
What carries the argument
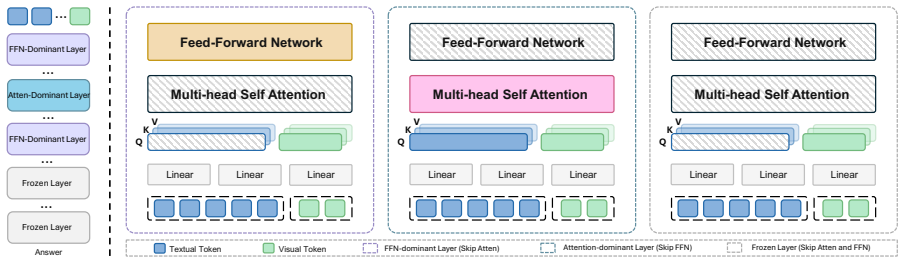
Operator-level visual-token skipping framework that decomposes each layer into attention and FFN operators and selectively bypasses only those shown to be redundant for the answer.
If this is right
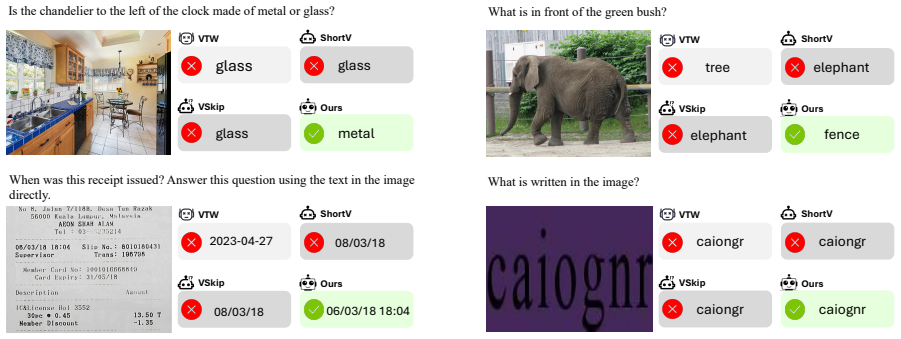
- The full visual-token sequence is retained, so fine-grained evidence is not discarded as it would be by token-removal methods.
- The same operator-level policy produces strong efficiency-accuracy trade-offs on three different MLLM architectures.
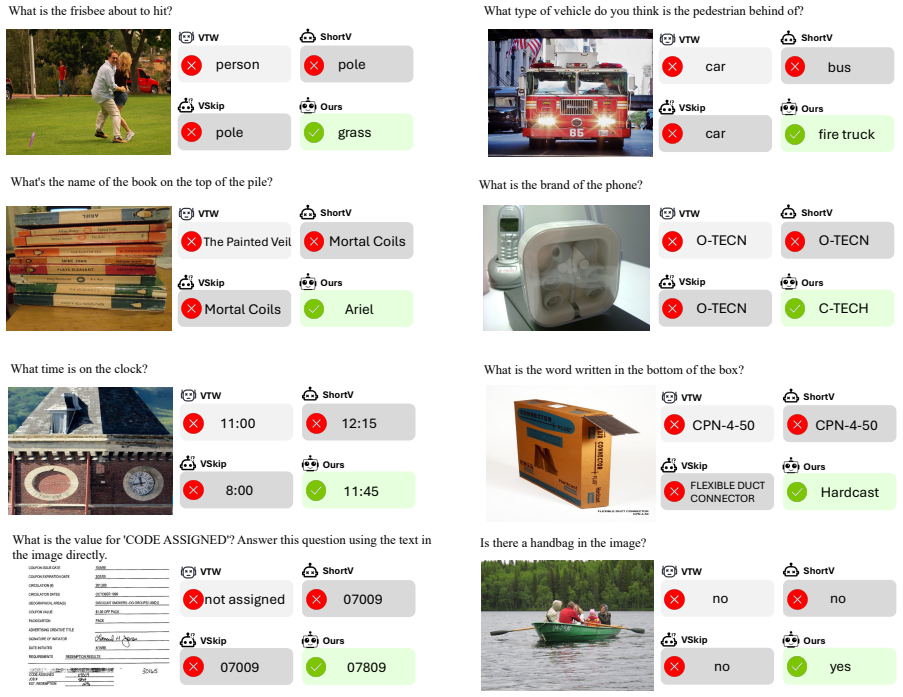
- Computation measured in TFLOPs drops by 33.7 percent on Qwen3-VL while 99.5 percent of original performance is kept across ten VQA benchmarks.
- Skipping decisions are made per operator and per layer rather than uniformly across an entire layer or the whole model.
Where Pith is reading between the lines
- The layer-dependent pattern of redundancy could be learned once per model family and reused across tasks.
- The same decomposition might expose similar silent operators in the text pathway or in non-visual modalities.
- Combining operator skipping with existing token-pruning techniques could compound the savings.
- The approach may scale to longer sequences such as video frames where the absolute compute reduction would be even larger.
Load-bearing premise
Late visual-token updates often remain large yet produce little change in the final answer-token representations.
What would settle it
Running the skipping policy on a held-out set of VQA examples and finding that the model's answers change on a substantial fraction of them compared with the unmodified model.
Figures

read the original abstract
Multimodal large language models (MLLMs) increasingly process long visual-token sequences, increasing the overall inference computation. Existing acceleration methods usually remove visual tokens or skip visual-token updates in entire layers, but these coarse strategies may discard fine-grained evidence or suppress useful operators together with redundant ones. In this paper, we study visual-token computation from an answer-observable perspective and find that late visual-token updates can remain large while having little effect on answer-token representations. Motivated by this answer-silent redundancy, we decompose each Transformer layer into attention and FFN operators and show that useful visual computation is often operator-dominant and layer-dependent. We propose an operator-level visual-token skipping framework that preserves the full visual-token sequence while selectively bypassing redundant attention, FFN, or both. Experiments across three MLLM architectures and 10 VQA benchmarks show that our method achieves strong efficiency-accuracy trade-offs, reducing \textbf{33.7\%} TFLOPs on Qwen3-VL while retaining \textbf{99.5\%} of the vanilla model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that late visual-token updates in MLLMs often exhibit answer-silent redundancy, allowing decomposition of each Transformer layer into attention and FFN operators where useful visual computation is operator-dominant and layer-dependent. It proposes selectively bypassing redundant attention, FFN, or both for visual tokens while preserving the full sequence, achieving up to 33.7% TFLOPs reduction on Qwen3-VL with 99.5% retention of vanilla performance across three MLLM architectures and 10 VQA benchmarks.
Significance. If the empirical observation of answer-silent redundancy and the operator-level detection rule generalize, the method offers a finer-grained efficiency technique than token pruning or full-layer skipping, better preserving fine-grained visual evidence. The multi-architecture, multi-benchmark evaluation strengthens the efficiency-accuracy trade-off claim and provides a useful empirical insight for MLLM inference optimization.
major comments (2)
- [§3] §3 (method description): the central premise that late visual-token updates are answer-silent and that skipping can be decided per-operator without dropping task-critical signals rests on post-hoc observation of representation change; the exact inference-time detection rule (how redundancy is measured and thresholds applied without access to answer tokens) is not specified in sufficient detail to verify that it recovers the observed redundancy without silent loss of fine-grained evidence.
- [§4] §4 (experiments): the 99.5% retention is reported across 10 VQA benchmarks, but no ablation or stress-test is provided on tasks that would require the late-layer operators being skipped (e.g., detailed spatial or fine-grained visual reasoning); this leaves open whether the chosen benchmarks under-stress the skipped operators as required for the operator-dominant claim to hold.
minor comments (2)
- [Figure 2] Figure 2: the diagram illustrating operator skipping could more explicitly annotate which operators are bypassed in each layer for clarity.
- Ensure all reported TFLOPs reductions include the exact baseline implementation details and hardware for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the method description and experimental validation. We address each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (method description): the central premise that late visual-token updates are answer-silent and that skipping can be decided per-operator without dropping task-critical signals rests on post-hoc observation of representation change; the exact inference-time detection rule (how redundancy is measured and thresholds applied without access to answer tokens) is not specified in sufficient detail to verify that it recovers the observed redundancy without silent loss of fine-grained evidence.
Authors: We agree that the inference-time detection rule requires more explicit specification. The current manuscript motivates the rule from post-hoc analysis of answer-silent redundancy but does not provide the precise measurement formula, threshold selection procedure, or pseudocode for operator decisions that operate solely on visual-token updates. In the revision we will expand §3 with a dedicated subsection containing the redundancy score definition (based on representation change norms), the threshold derivation from the observed redundancy statistics, and an algorithm for inference-time application. This will allow independent verification that the rule preserves fine-grained signals. revision: yes
-
Referee: [§4] §4 (experiments): the 99.5% retention is reported across 10 VQA benchmarks, but no ablation or stress-test is provided on tasks that would require the late-layer operators being skipped (e.g., detailed spatial or fine-grained visual reasoning); this leaves open whether the chosen benchmarks under-stress the skipped operators as required for the operator-dominant claim to hold.
Authors: The 10 VQA benchmarks contain tasks with spatial and fine-grained elements (e.g., GQA, VQAv2), yet we acknowledge the absence of targeted stress tests on the specific late-layer operators being skipped. In the revised manuscript we will add an ablation section that evaluates the method on additional fine-grained visual reasoning tasks (e.g., RefCOCO grounding and detailed visual question answering subsets) to directly test whether skipping those operators affects performance on queries that rely on the skipped computations. revision: yes
Circularity Check
No circularity; empirical method with external validation
full rationale
The paper presents an empirical observation of answer-silent redundancy in late visual-token updates, decomposes layers into attention/FFN operators, and proposes selective skipping, all validated directly via experiments on three MLLM architectures and 10 VQA benchmarks (e.g., 33.7% TFLOPs reduction with 99.5% retention). No derivation chain, equations, or predictions reduce to self-definitions, fitted inputs renamed as outputs, or self-citation chains; the central claims rest on post-hoc measurements and ablation results that are independently falsifiable against the vanilla baseline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. 2025. Divprune: Diversity-based visual token pruning for large multimodal models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9392--9401
2025
-
[2]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, and 4 others. 2025. https://arxiv.org/abs/2509.23661 Llava-onevision-1.5: Fully open framework for democratized multimodal traini...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025 a . https://arxiv.org/abs/2511.21631 Qwen3-vl technical report . Preprint, arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025 b . https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Junjie Chen, Xuyang Liu, Zichen Wen, Yiyu Wang, Siteng Huang, and Honggang Chen. 2026. Variation-aware vision token dropping for faster large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3489--3499
2026
-
[6]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2025. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In Computer Vision -- ECCV 2024, pages 19--35, Cham. Springer Nature Switzerland
2025
-
[7]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/file/d79a27cf2772fe00be7f341efc0eb517-Paper-Datasets_and_Benchmarks_Track.pdf Mme: A comprehensive evaluation benchmark for mult...
2025
-
[8]
Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P
Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P. Bigham. 2018. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
- [9]
-
[10]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2019
-
[11]
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. 2016. A diagram is worth a dozen images. In Computer Vision -- ECCV 2016, pages 235--251, Cham. Springer International Publishing
2016
-
[12]
Jiwan Kim, Kibum Kim, Wonjoong Kim, Byung-Kwan Lee, and Chanyoung Park. 2026. https://arxiv.org/abs/2604.12358 Why and when visual token pruning fails? a study on relevant visual information shift in mllms decoding . Preprint, arXiv:2604.12358
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023 a . https://proceedings.mlr.press/v202/li23q.html BLIP -2: Bootstrapping language-image pre-training with frozen image encoders and large language models . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19730-...
2023
-
[16]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 a . Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296--26306
2024
-
[17]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024 b . https://llava-vl.github.io/blog/2024-01-30-llava-next/ Llava-next: Improved reasoning, ocr, and world knowledge
2024
-
[18]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2025. Mmbench: Is your multi-modal model an all-around player? In Computer Vision -- ECCV 2024, pages 216--233, Cham. Springer Nature Switzerland
2025
-
[20]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/11332b6b6cf4485b84afadb1352d3a9a-Paper-Conference.pdf Learn to explain: Multimodal reasoning via thought chains for science question answering . In Advances in Neural...
2022
-
[21]
Jie Ma, Zhike Qiu, Jiayi Ji, Xiaoshuai Sun, and Rongrong Ji. 2026 a . https://arxiv.org/abs/2606.08511 Look less, reason more: Block-wise attention skipping for efficient multimodal llms . Preprint, arXiv:2606.08511
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Qiankun Ma, Ziyao Zhang, Haofei Wang, Zhen Song, Jie Chen, and Hairong Zheng. 2026 b . Apet: Approximation-error guided token compression for efficient vlms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26306--26316
2026
-
[23]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. 2025. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22857--22867
2025
-
[24]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards vqa models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2019
-
[25]
Yahong Wang, Juncheng Wu, Zhangkai Ni, Longzhen Yang, Yihang Liu, Chengmei Yang, Ying Wen, Lianghua He, Xianfeng Tang, Hui Liu, and Yuyin Zhou. 2026. When token pruning is worse than random: Understanding visual token information in vllms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 31910--31919
2026
-
[27]
Gongli Xi, Ye Tian, Mengyu Yang, Huahui Yi, Liang Lin, Xiaoshuai Hao, Kun Wang, and Wendong Wang. 2026. https://arxiv.org/abs/2605.05668 Large vision-language models get lost in attention . Preprint, arXiv:2605.05668
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. 2025. https://arxiv.org/abs/2410.17247 Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction . Preprint, arXiv:2410.17247
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. 2025. Visionzip: Longer is better but not necessary in vision language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19792--19802
2025
-
[30]
Qianhao Yuan, Qingyu Zhang, Yanjiang Liu, Jiawei Chen, Yaojie Lu, Hongyu Lin, Jia Zheng, Xianpei Han, and Le Sun. 2025. Shortv: Efficient multimodal large language models by freezing visual tokens in ineffective layers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 329--339
2025
-
[31]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, and 3 others. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In P...
2024
-
[32]
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/file/2433fec2144ccf5fea1c9c5ebdbc3924-Paper-Conference.pdf Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms . In Advances in Neural Information Processing...
2025
-
[33]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[34]
Publications Manual , year = "1983", publisher =
1983
-
[35]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[36]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[37]
Dan Gusfield , title =. 1997
1997
-
[38]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[39]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[40]
2023 , editor =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =. 2023 , editor =
2023
-
[41]
Visual Instruction Tuning , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , url =
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[43]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[44]
An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
Chen, Liang and Zhao, Haozhe and Liu, Tianyu and Bai, Shuai and Lin, Junyang and Zhou, Chang and Chang, Baobao. An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models. Computer Vision -- ECCV 2024. 2025
2024
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Senqiao and Chen, Yukang and Tian, Zhuotao and Wang, Chengyao and Li, Jingyao and Yu, Bei and Jia, Jiaya , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Shang, Yuzhang and Cai, Mu and Xu, Bingxin and Lee, Yong Jae and Yan, Yan , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Junjie and Liu, Xuyang and Wen, Zichen and Wang, Yiyu and Huang, Siteng and Chen, Honggang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Ma, Qiankun and Zhang, Ziyao and Wang, Haofei and Song, Zhen and Chen, Jie and Zheng, Hairong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[49]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Yuan, Qianhao and Zhang, Qingyu and Liu, Yanjiang and Chen, Jiawei and Lu, Yaojie and Lin, Hongyu and Zheng, Jia and Han, Xianpei and Sun, Le , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[50]
2026 , eprint=
Look Less, Reason More: Block-wise Attention Skipping for Efficient Multimodal LLMs , author=. 2026 , eprint=
2026
-
[51]
2026 , eprint=
Large Vision-Language Models Get Lost in Attention , author=. 2026 , eprint=
2026
-
[52]
and Manning, Christopher D
Hudson, Drew A. and Manning, Christopher D. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Singh, Amanpreet and Natarajan, Vivek and Shah, Meet and Jiang, Yu and Chen, Xinlei and Batra, Dhruv and Parikh, Devi and Rohrbach, Marcus , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[54]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , url =
Fu, Chaoyou and Chen, Peixian and Shen, Yunhang and Qin, Yulei and Zhang, Mengdan and Lin, Xu and Yang, Jinrui and Zheng, Xiawu and Li, Ke and Sun, Xing and Wu, Yunsheng and Ji, Rongrong and Shan, Caifeng and He, Ran , booktitle =. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , url =
-
[55]
MMBench: Is Your Multi-modal Model an All-Around Player?
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and Chen, Kai and Lin, Dahua. MMBench: Is Your Multi-modal Model an All-Around Player?. Computer Vision -- ECCV 2024. 2025
2024
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , title =...
2024
-
[57]
Evaluating Object Hallucination in Large Vision-Language Models
Li, Yifan and Du, Yifan and Zhou, Kun and Wang, Jinpeng and Zhao, Xin and Wen, Ji-Rong. Evaluating Object Hallucination in Large Vision-Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.20
-
[58]
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , url =
Lu, Pan and Mishra, Swaroop and Xia, Tanglin and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Kalyan, Ashwin , booktitle =. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , url =
-
[59]
A Diagram is Worth a Dozen Images
Kembhavi, Aniruddha and Salvato, Mike and Kolve, Eric and Seo, Minjoon and Hajishirzi, Hannaneh and Farhadi, Ali. A Diagram is Worth a Dozen Images. Computer Vision -- ECCV 2016. 2016
2016
-
[60]
and Guo, Anhong and Lin, Chi and Grauman, Kristen and Luo, Jiebo and Bigham, Jeffrey P
Gurari, Danna and Li, Qing and Stangl, Abigale J. and Guo, Anhong and Lin, Chi and Grauman, Kristen and Luo, Jiebo and Bigham, Jeffrey P. , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[61]
LMM s-Eval: Reality Check on the Evaluation of Large Multimodal Models
Zhang, Kaichen and Li, Bo and Zhang, Peiyuan and Pu, Fanyi and Cahyono, Joshua Adrian and Hu, Kairui and Liu, Shuai and Zhang, Yuanhan and Yang, Jingkang and Li, Chunyuan and Liu, Ziwei. LMM s-Eval: Reality Check on the Evaluation of Large Multimodal Models. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025....
-
[62]
Science China Information Sciences , year =
Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang , title =. Science China Information Sciences , year =. doi:10.1007/s11432-024-4235-6 , url =
-
[63]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Lin, Zhihang and Lin, Mingbao and Lin, Luxi and Ji, Rongrong , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =. doi:10.1609/aaai.v39i5.32567 , url =
-
[65]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[66]
2025 , eprint=
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training , author=. 2025 , eprint=
2025
-
[67]
2026 , eprint=
N\"uwa: Mending the Spatial Integrity Torn by VLM Token Pruning , author=. 2026 , eprint=
2026
-
[68]
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs , url =
Zhang, Qizhe and Liu, Mengzhen and Li, Lichen and Lu, Ming and Zhang, Yuan and Pan, Junwen and She, Qi and Zhang, Shanghang , booktitle =. Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs , url =
-
[69]
2025 , eprint=
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction , author=. 2025 , eprint=
2025
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Yahong and Wu, Juncheng and Ni, Zhangkai and Yang, Longzhen and Liu, Yihang and Yang, Chengmei and Wen, Ying and He, Lianghua and Tang, Xianfeng and Liu, Hui and Zhou, Yuyin , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Alvar, Saeed Ranjbar and Singh, Gursimran and Akbari, Mohammad and Zhang, Yong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[72]
2026 , eprint=
Why and When Visual Token Pruning Fails? A Study on Relevant Visual Information Shift in MLLMs Decoding , author=. 2026 , eprint=
2026
-
[73]
Token Pruning in Multimodal Large Language Models: Are We Solving the Right Problem?
Wen, Zichen and Gao, Yifeng and Li, Weijia and He, Conghui and Zhang, Linfeng. Token Pruning in Multimodal Large Language Models: Are We Solving the Right Problem?. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.802
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.