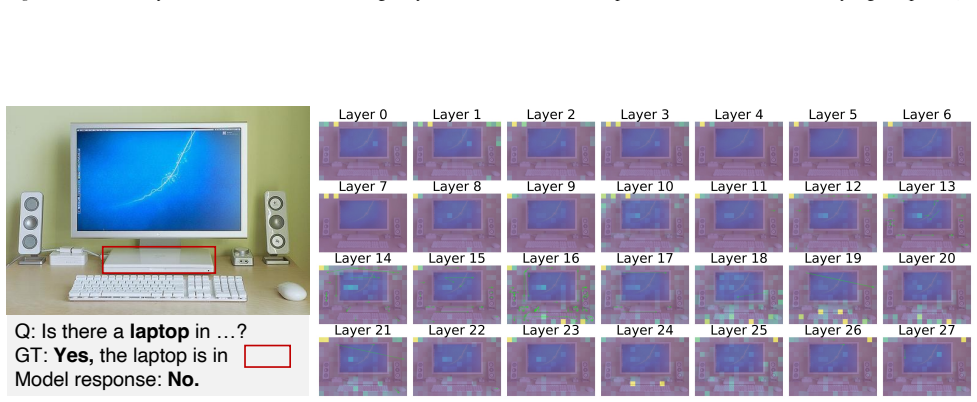
Recognition: unknown
Large Vision-Language Models Get Lost in Attention
Pith reviewed 2026-05-08 11:50 UTC · model grok-4.3
The pith
Large vision-language models perform as well or better on most datasets when learned attention weights are replaced by fixed values such as Gaussian noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Applying this unified framework reveals a fundamental functional decoupling: Attention acts as a subspace-preserving operator focused on reconfiguration, whereas FFNs serve as subspace-expanding operators driving semantic innovation. Strikingly, further experiments demonstrate that replacing learned attention weights with predefined values (e.g., Gaussian noise) yields comparable or even superior performance across a majority of datasets relative to vanilla models.
What carries the argument
The unified information-theoretic and geometric framework that quantifies the geometric and entropic nature of residual updates, which distinguishes attention as a subspace-preserving operator from FFNs as subspace-expanding operators.
If this is right
- Attention modules in LVLMs primarily reconfigure subspaces rather than expand them or introduce new semantics.
- FFNs carry the main responsibility for semantic innovation through subspace expansion.
- Learned attention weights contain substantial redundancy, since fixed or random weights suffice for comparable results.
- Model capacity may be misallocated toward attention at the expense of other components.
- Architectural changes that simplify or fix attention could preserve performance while reducing computation.
Where Pith is reading between the lines
- Architectures that use simpler fixed attention from the beginning of training might achieve similar capabilities with lower training cost.
- The observed decoupling could be tested in pure language or pure vision Transformers to see whether the same division of labor holds.
- Training objectives might be redesigned to encourage attention to focus more narrowly on reconfiguration instead of attempting broader roles.
- Efficiency gains could come from pruning or freezing attention layers once the model has learned basic subspace mapping.
Load-bearing premise
That replacing only the attention weights after training, while leaving all other components unchanged, provides a clean test of attention's role without side effects from training dynamics or interactions with the rest of the architecture.
What would settle it
Retraining an LVLM from scratch using only fixed predefined attention weights from the start and measuring whether it reaches or exceeds the accuracy of a fully learned model on the same set of vision-language benchmarks.
Figures









read the original abstract
Despite the rapid evolution of training paradigms, the decoder backbone of large vision--language models (LVLMs) remains fundamentally rooted in the residual-connection Transformer architecture. Therefore, deciphering the distinct roles of internal modules is critical for understanding model mechanics and guiding architectural optimization. While prior statistical approaches have provided valuable attribution-based insights, they often lack a unified theoretical basis. To bridge this gap, we propose a unified framework grounded in information theory and geometry to quantify the geometric and entropic nature of residual updates. Applying this unified framework reveals a fundamental functional decoupling: Attention acts as a subspace-preserving operator focused on reconfiguration, whereas FFNs serve as subspace-expanding operators driving semantic innovation. Strikingly, further experiments demonstrate that replacing learned attention weights with predefined values (e.g., Gaussian noise) yields comparable or even superior performance across a majority of datasets relative to vanilla models. These results expose severe misallocation and redundancy in current mechanisms, suggesting that state-of-the-art LVLMs effectively ``get lost in attention'' rather than efficiently leveraging visual context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified information-theoretic and geometric framework for quantifying residual updates in large vision-language models (LVLMs). It concludes that attention mechanisms function as subspace-preserving operators focused on reconfiguration, while feed-forward networks (FFNs) act as subspace-expanding operators driving semantic innovation. The central empirical claim is that post-training replacement of learned attention weights (or post-softmax scores) with predefined values such as Gaussian noise yields comparable or superior performance on a majority of evaluated datasets relative to the original models, implying severe redundancy and misallocation in current attention mechanisms.
Significance. If the replacement results and the decoupling framework hold after addressing methodological gaps, the work would challenge the assumed centrality of learned attention in LVLMs and motivate simpler, more efficient architectures. The information-geometry lens offers a potential advance over purely attribution-based analyses, provided the measures are shown to be independent of the fitted parameters and experimental perturbations.
major comments (3)
- [Experiments] Experiments section (noise-replacement protocol): The claim that swapping only attention weights (while keeping FFN weights, layer norms, and residuals fixed) isolates attention's functional role is undermined by end-to-end training. Because FFNs and residual pathways are co-adapted to the specific output distribution of the learned Q/K/V projections, the substitution perturbs inputs to all subsequent modules. No controls or ablations are described that would distinguish true attention redundancy from compensatory behavior in the rest of the network. This directly affects the load-bearing performance comparison.
- [Framework] Framework definition (subspace-preserving vs. subspace-expanding operators): The geometric and entropic quantifications are not shown to remain invariant under the attention-weight perturbation used in the experiments. If the measures depend on the same fitted parameters or on the original attention outputs, the reported decoupling risks circularity and cannot be used to interpret the replacement results.
- [Abstract / Experiments] Abstract and Experiments: No derivation details, full dataset list, statistical significance tests, variance across runs, or explicit controls (e.g., replacement of FFN weights as a baseline) are provided for the noise-replacement experiments. Without these, it is impossible to assess whether the reported performance parity or gains are robust or artifactual.
minor comments (2)
- [Framework] Notation for the information-theoretic quantities (entropy, subspace dimension) should be defined explicitly with equations before being used in the framework section.
- [Figures] Figure captions for any performance tables or geometric visualizations should include exact replacement method (projection matrices vs. post-softmax scores), number of datasets, and error bars.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important methodological considerations that we will address to strengthen the empirical claims and framework. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section (noise-replacement protocol): The claim that swapping only attention weights (while keeping FFN weights, layer norms, and residuals fixed) isolates attention's functional role is undermined by end-to-end training. Because FFNs and residual pathways are co-adapted to the specific output distribution of the learned Q/K/V projections, the substitution perturbs inputs to all subsequent modules. No controls or ablations are described that would distinguish true attention redundancy from compensatory behavior in the rest of the network. This directly affects the load-bearing performance comparison.
Authors: We agree that the absence of controls leaves open the possibility of compensatory behavior in co-adapted modules. In the revised manuscript we will add FFN-weight replacement ablations (Gaussian noise on FFNs while retaining learned attention) as a direct baseline, report the resulting performance drops, and include analysis of input-distribution shifts to downstream layers after attention replacement. These additions will allow readers to assess whether performance parity is attributable to attention redundancy rather than network-wide compensation. revision: yes
-
Referee: [Framework] Framework definition (subspace-preserving vs. subspace-expanding operators): The geometric and entropic quantifications are not shown to remain invariant under the attention-weight perturbation used in the experiments. If the measures depend on the same fitted parameters or on the original attention outputs, the reported decoupling risks circularity and cannot be used to interpret the replacement results.
Authors: The measures are defined on the geometry and entropy of residual updates and do not explicitly depend on the original attention weights. Nevertheless, to eliminate any appearance of circularity we will add a dedicated invariance check: recompute the subspace and entropy statistics on the noise-replaced models and verify that the reported decoupling pattern persists. The revised manuscript will present these results alongside the original figures. revision: partial
-
Referee: [Abstract / Experiments] Abstract and Experiments: No derivation details, full dataset list, statistical significance tests, variance across runs, or explicit controls (e.g., replacement of FFN weights as a baseline) are provided for the noise-replacement experiments. Without these, it is impossible to assess whether the reported performance parity or gains are robust or artifactual.
Authors: We will expand the Experiments section with: (i) explicit derivations of the information-theoretic and geometric operators, (ii) the complete list of datasets and evaluation protocols, (iii) statistical significance tests (paired t-tests or Wilcoxon signed-rank) together with standard deviations across at least three random seeds, and (iv) the FFN-replacement baseline already planned in response to the first comment. These details will be added to both the main text and the appendix. revision: yes
Circularity Check
No significant circularity detected; framework and experiments remain independent
full rationale
The paper introduces a unified information-theoretic and geometric framework to analyze residual updates, applies it to conclude that attention acts as a subspace-preserving operator while FFNs are subspace-expanding, and separately reports that post-training replacement of attention weights with predefined values (e.g., Gaussian noise) yields comparable or superior performance. No equations, definitions, or self-citations in the provided text reduce the framework's quantifications to the experimental outcomes by construction, nor do any 'predictions' collapse to fitted parameters or self-referential inputs. The derivation chain is self-contained, with the framework functioning as an external analytical lens rather than being defined in terms of its own results or the replacement experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[3]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[4]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[5]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review arXiv
-
[7]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[8]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[9]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[10]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[11]
Advances in neural information processing systems , volume=
The evolution of statistical induction heads: In-context learning markov chains , author=. Advances in neural information processing systems , volume=
-
[12]
Attention is not explanation , author=. arXiv preprint arXiv:1902.10186 , year=
work page Pith review arXiv 1902
-
[13]
arXiv preprint arXiv:1906.03731 , year=
Is attention interpretable? , author=. arXiv preprint arXiv:1906.03731 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Diff-erank: A novel rank-based metric for evaluating large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Layer by layer: Uncovering hidden representations in language models , author=. arXiv preprint arXiv:2502.02013 , year=
-
[16]
On the role of attention heads in large language model safety , author=. arXiv preprint arXiv:2410.13708 , year=
-
[17]
arXiv preprint arXiv:2505.15807 , year=
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation , author=. arXiv preprint arXiv:2505.15807 , year=
-
[18]
arXiv preprint arXiv:2505.13737 , year=
Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers , author=. arXiv preprint arXiv:2505.13737 , year=
-
[19]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Inferring functionality of attention heads from their parameters , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Transactions of the Association for Computational Linguistics , volume=
Analysis methods in neural language processing: A survey , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[21]
arXiv preprint arXiv:1805.01070 , year=
What you can cram into a single vector: Probing sentence embeddings for linguistic properties , author=. arXiv preprint arXiv:1805.01070 , year=
-
[22]
A structural probe for finding syntax in word representations , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[23]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review arXiv
-
[24]
Advances in Neural Information Processing Systems , volume=
Transcoders find interpretable llm feature circuits , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:1908.04626 , year=
Attention is not not explanation , author=. arXiv preprint arXiv:1908.04626 , year=
-
[26]
Entropy , volume=
Information-Theoretical Analysis of a Transformer-Based Generative AI Model , author=. Entropy , volume=. 2025 , publisher=
2025
-
[27]
See what you are told: Visual attention sink in large multimodal models , author=. arXiv preprint arXiv:2503.03321 , year=
-
[28]
More Thinking, Less Seeing? Assessing Amplified Hallucination in Multimodal Reasoning Models , author=. arXiv preprint arXiv:2505.21523 , year=
-
[29]
arXiv preprint arXiv:2310.00535 , year=
Joma: Demystifying multilayer transformers via joint dynamics of mlp and attention , author=. arXiv preprint arXiv:2310.00535 , year=
-
[30]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
The shape of learning: Anisotropy and intrinsic dimensions in transformer-based models , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[31]
Transformer Circuits Thread , volume=
Circuit tracing: Revealing computational graphs in language models , author=. Transformer Circuits Thread , volume=
-
[32]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review arXiv
-
[33]
arXiv preprint arXiv:2509.17588 , year=
Interpreting Attention Heads for Image-to-Text Information Flow in Large Vision-Language Models , author=. arXiv preprint arXiv:2509.17588 , year=
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-turn jailbreaking large language models via attention shifting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
Advances in Neural Information Processing Systems , volume=
-ReQ: Assessing Representation Quality in Self-Supervised Learning by measuring eigenspectrum decay , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Entropy-lens: The information signature of transformer computations , author=. arXiv preprint arXiv:2502.16570 , year=
-
[37]
Journal of Machine Learning Research , volume=
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is? , author=. Journal of Machine Learning Research , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
Understanding scaling laws with statistical and approximation theory for transformer neural networks on intrinsically low-dimensional data , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2108.03418 , year=
Information bottleneck approach to spatial attention learning , author=. arXiv preprint arXiv:2108.03418 , year=
-
[40]
2013 , publisher=
Matrix computations , author=. 2013 , publisher=
2013
-
[41]
Psychometrika , volume=
The approximation of one matrix by another of lower rank , author=. Psychometrika , volume=. 1936 , publisher=
1936
-
[42]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[43]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[44]
IEEE Transactions on Information Theory , volume=
Measures of entropy from data using infinitely divisible kernels , author=. IEEE Transactions on Information Theory , volume=. 2014 , publisher=
2014
-
[45]
arXiv preprint arXiv:2301.08164 , year=
Dime: Maximizing mutual information by a difference of matrix-based entropies , author=. arXiv preprint arXiv:2301.08164 , year=
-
[46]
2000 , publisher=
Linear estimation , author=. 2000 , publisher=
2000
-
[47]
SIAM Journal on Optimization , volume =
Low-Rank Matrix Completion by Riemannian Optimization , author =. SIAM Journal on Optimization , volume =. 2013 , doi =
2013
-
[48]
Optimization Algorithms on Matrix Manifolds , author =
-
[49]
Qwen2.5-VL , url =
Qwen Team , month =. Qwen2.5-VL , url =
-
[50]
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL , author=. arXiv preprint arXiv:2505.15436 , year=
-
[51]
arXiv preprint arXiv:2504.13169 , year=
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling , author=. arXiv preprint arXiv:2504.13169 , year=
-
[52]
2025 , eprint =
MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning , author =. 2025 , eprint =
2025
-
[53]
One RL to See Them All: Visual Triple Unified Reinforcement Learning
One RL to See Them All: Visual Triple Unified Reinforcement Learning , author=. arXiv preprint arXiv:2505.18129 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Ming, Lingfeng and Li, Yadong and Chen, Song and Xu, Jianhua and Zhou, Zenan and Chen, Weipeng , title =
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
2024 , eprint=
Yi: Open Foundation Models by 01.AI , author=. 2024 , eprint=
2024
-
[57]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review arXiv
-
[58]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[59]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , address =
Evaluating Object Hallucination in Large Vision-Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , address =. 2023 , doi =
2023
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3dsrbench: A comprehensive 3d spatial reasoning benchmark , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
2024 , note =
RealWorldQA , author =. 2024 , note =
2024
-
[62]
Yue, Xingyu and Qu, Gaole and Chen, Xiuyu and others , journal =
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhang, Yuhui and Su, Yuchang and Liu, Yiming and Wang, Xiaohan and Burgess, James and Sui, Elaine and Wang, Chenyu and Aklilu, Josiah and Lozano, Alejandro and Wei, Anjiang and Schmidt, Ludwig and Yeung-Levy, Serena , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[64]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author =. arXiv preprint arXiv:2310.02255 , year =
work page internal anchor Pith review arXiv
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Guan, Tianrui and Liu, Fuxiao and Wu, Xiyang and Xian, Ruiqi and Li, Zongxia and Liu, Xiaoyu and Wang, Xijun and Chen, Lichang and Huang, Furong and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[66]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
arXiv preprint arXiv:2402.12233 , year=
Empirical study on updating key-value memories in transformer feed-forward layers , author=. arXiv preprint arXiv:2402.12233 , year=
-
[68]
Advances in Neural Information Processing Systems , volume=
Savit: Structure-aware vision transformer pruning via collaborative optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[70]
arXiv preprint arXiv:2502.11501 , year=
Token Pruning in Multimodal Large Language Models: Are We Solving the Right Problem? , author=. arXiv preprint arXiv:2502.11501 , year=
-
[71]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[72]
arXiv preprint arXiv:2510.21518 , year=
Head Pursuit: Probing Attention Specialization in Multimodal Transformers , author=. arXiv preprint arXiv:2510.21518 , year=
-
[73]
Forty-first International Conference on Machine Learning , year=
Exploring intrinsic dimension for vision-language model pruning , author=. Forty-first International Conference on Machine Learning , year=
-
[74]
arXiv preprint arXiv:2402.18048 , year=
Characterizing truthfulness in large language model generations with local intrinsic dimension , author=. arXiv preprint arXiv:2402.18048 , year=
-
[75]
arXiv preprint arXiv:2406.15812 , year=
Intrinsic dimension correlation: uncovering nonlinear connections in multimodal representations , author=. arXiv preprint arXiv:2406.15812 , year=
-
[76]
Forty-second International Conference on Machine Learning,
Yuri Gardinazzi and Karthik Viswanathan and Giada Panerai and Alessio Ansuini and Alberto Cazzaniga and Matteo Biagetti , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
2025
-
[77]
Forty-second International Conference on Machine Learning,
Kento Nishi and Rahul Ramesh and Maya Okawa and Mikail Khona and Hidenori Tanaka and Ekdeep Singh Lubana , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
2025
-
[78]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[79]
Microsoft COCO: Common Objects in Context , booktitle =
Tsung. Microsoft COCO: Common Objects in Context , booktitle =. 2014 , doi =
2014
-
[80]
Lost in embeddings: Information loss in vision-language models , author=. arXiv preprint arXiv:2509.11986 , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.