World Narrative Model for Highly Controllable Video Generation: A Paradigm Shift from Pixel Sampling to Physical World Orchestration
Pith reviewed 2026-07-01 05:28 UTC · model grok-4.3
The pith
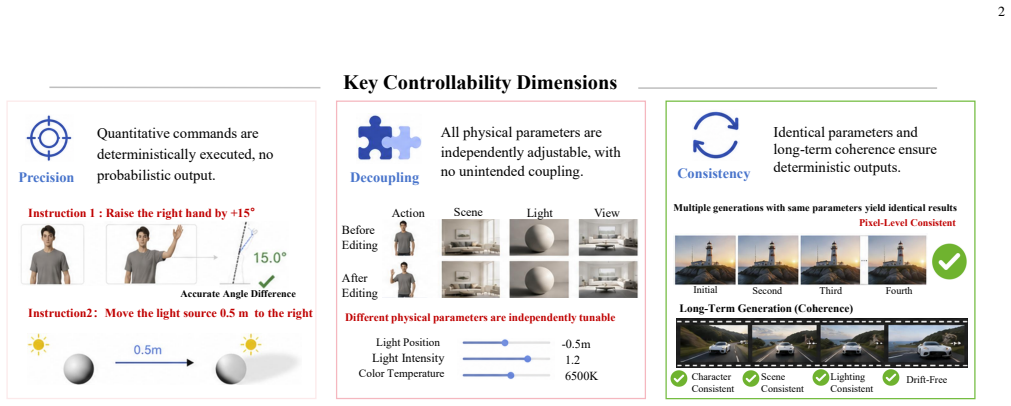
The World Narrative Model decouples structured 4D physical narratives from pixel sampling to drive controllable video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
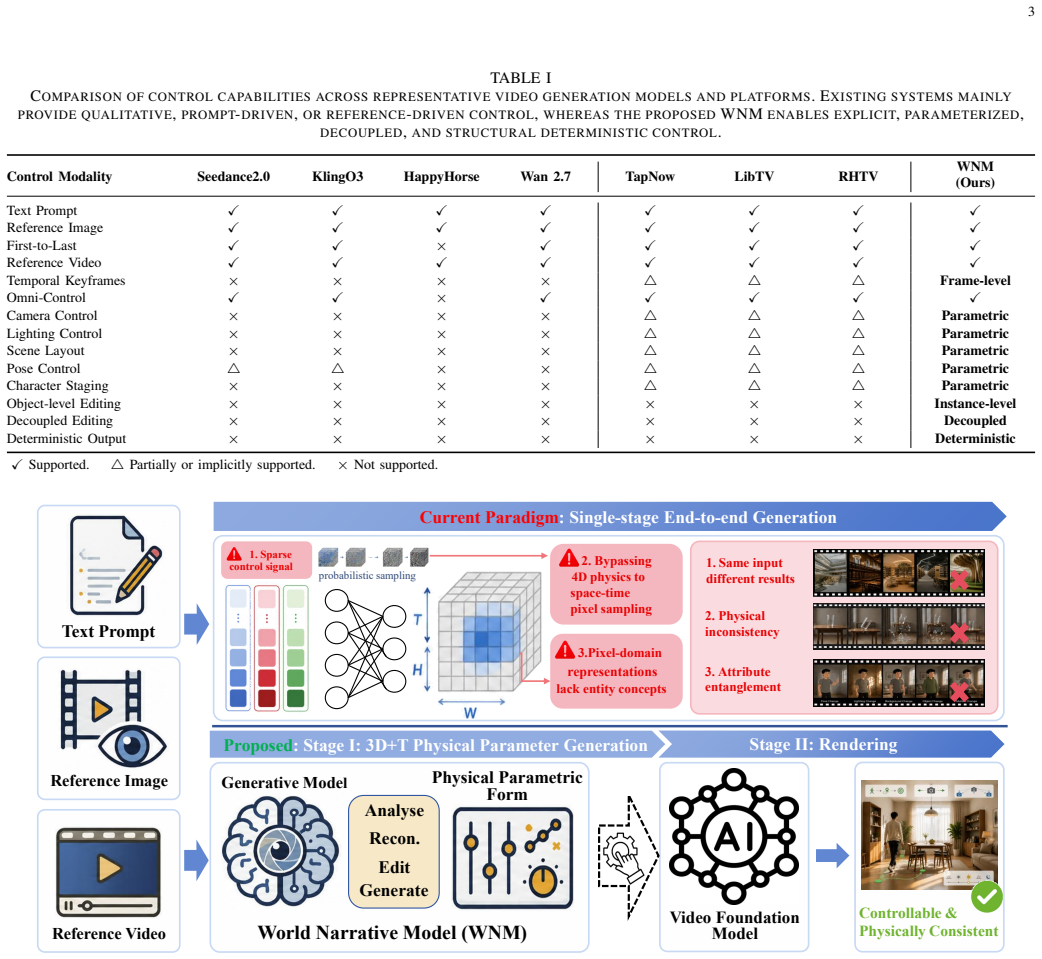
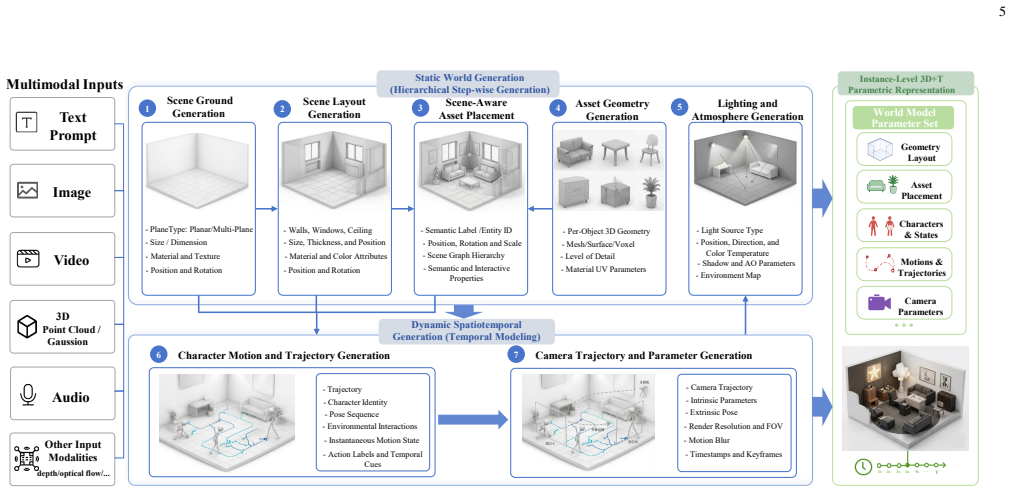
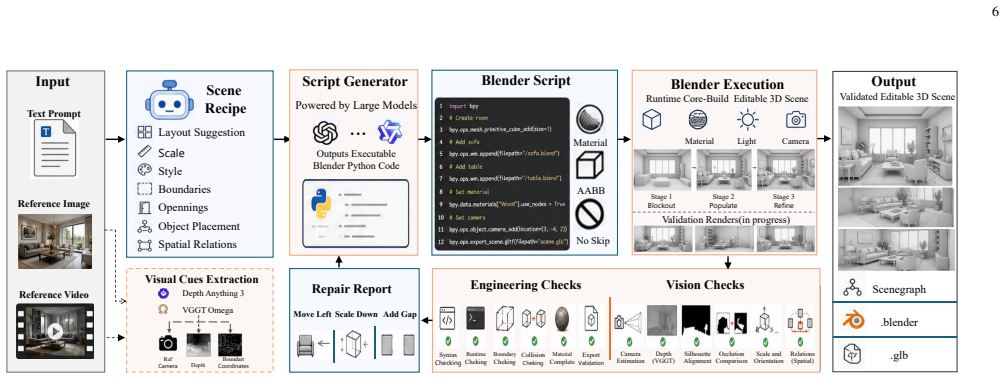
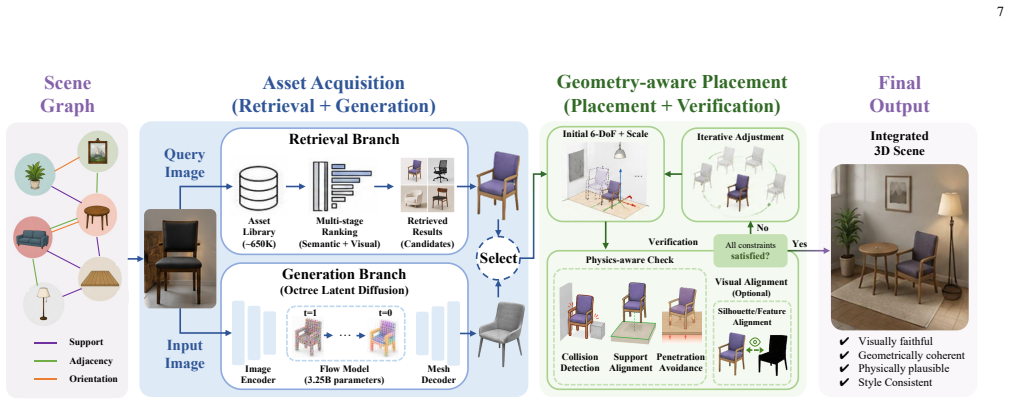
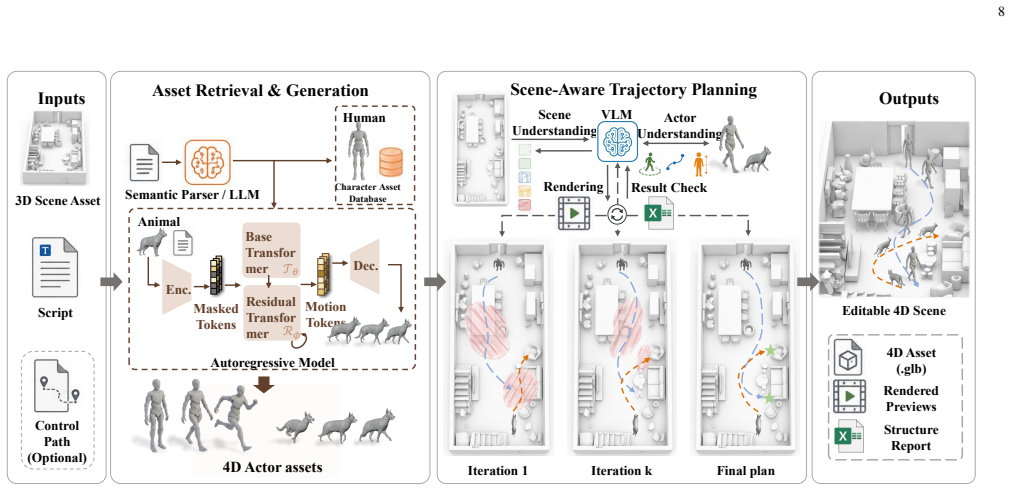
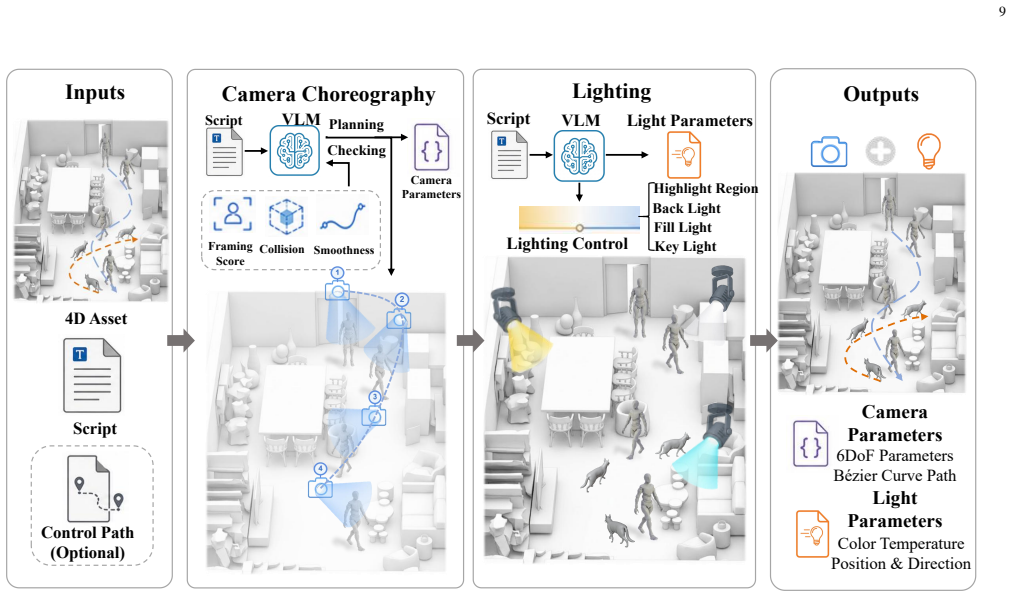
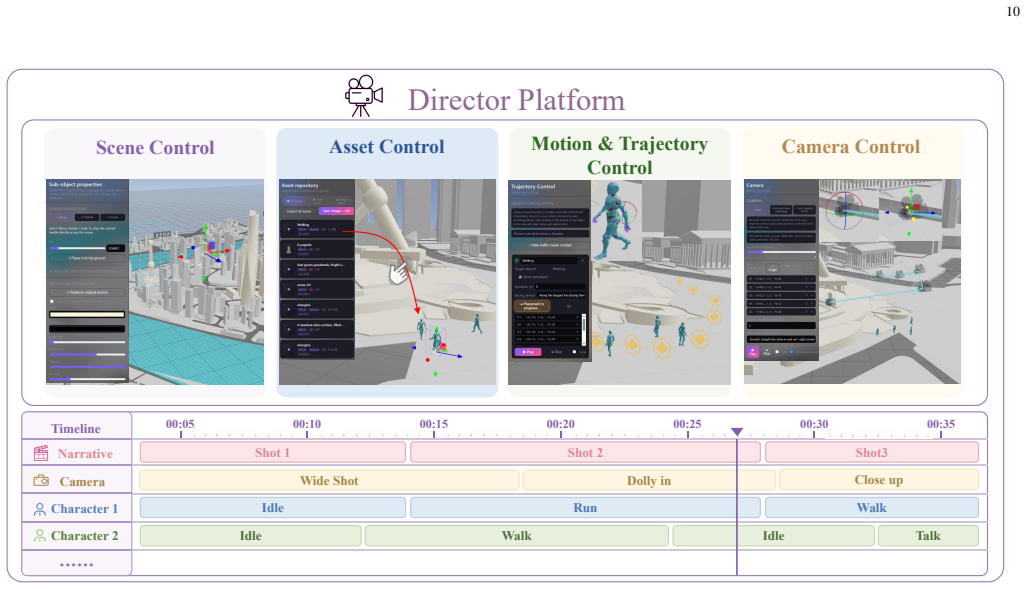
WNM replaces end-to-end black-box sampling with orchestrated 4D pre-visualization for media generation. Collaborative agents translate sparse multimodal inputs, including text, reference videos, and sketches, into a fully editable world representation with scene geometry, object layouts, character/animal skeleton motion, trajectories, camera motion, and lighting at quantitative, physically meaningful granularity. This representation acts as a deterministic structural blueprint that drives existing video foundation models, either frozen or lightly adapted, to render final footage, turning the base model into a faithful neural shader.
What carries the argument
The orchestrated 4D pre-visualization, which creates an explicit editable world representation that acts as a deterministic blueprint driving base video models as neural shaders.
If this is right
- Creators can specify geometry, motion, camera parameters, and lighting in deterministic quantitative terms rather than through repeated random sampling.
- The number of probabilistic generation attempts needed to achieve desired results decreases substantially.
- The output videos follow creator-specified layout, motion, and cinematography more closely than direct sampling approaches.
- The overall system supports automatic pre-visualization and human refinement steps that align with professional filmmaking workflows.
Where Pith is reading between the lines
- The modular separation could allow direct substitution of physics-based simulators into the world representation stage for improved physical accuracy.
- Director consoles for refinement might lower the barrier for non-experts to produce videos with professional-level control.
- Because the world representation is fully editable, downstream tasks such as consistent multi-shot sequences or interactive editing become feasible without regenerating from scratch.
Load-bearing premise
Collaborative agents can reliably translate sparse multimodal inputs into a fully editable world representation with quantitative, physically meaningful granularity.
What would settle it
Generate videos from a world representation with precisely specified object trajectories and camera paths, then measure whether output frames match those trajectories and paths within a small quantitative error bound.
Figures

read the original abstract
The fundamental obstacle to industrial grade video generation is the lack of controllability: existing models treat video as a pixel distribution sampling problem, bypassing the explicit, instance level $4D$ $(3D + T)$ physical world. Consequently, content creators cannot specify geometry, motion, camera parameters, or lighting in a deterministic, quantitative way, leading to the infamous ''gacha'' loop that makes professional content creation prohibitively inefficient and expensive. To address this, we introduce the World Narrative Model (WNM), a paradigm that decouples what to render -- the structured physical narrative -- from how to render -- the pixel generation process. WNM replaces end-to-end black-box sampling with orchestrated $4D$ pre-visualization for media generation. Collaborative agents translate sparse multimodal inputs, including text, reference videos, and sketches, into a fully editable world representation with scene geometry, object layouts, character/animal skeleton motion, trajectories, camera motion, and lighting at quantitative, physically meaningful granularity. This representation acts as a deterministic structural blueprint that drives existing video foundation models, either frozen or lightly adapted, to render final footage, turning the base model into a faithful neural shader. Built on this engine, our human-AI platform supports automatic world generation and pre-visualization aligned with professional filmmaking pipelines, while director consoles enable seamless human refinement. Experiments show that WNM greatly reduces probabilistic ``gacha'' calls and produces videos whose layout, motion, and cinematography closely follow creator intent. The framework is open and modular, allowing each component, such as world representation, control agents, and adapters, to be independently improved. Project website: https://glassroom.sjtu.edu.cn/WNM/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing video generation models suffer from poor controllability due to treating video as pixel sampling, leading to inefficient 'gacha' iteration. It introduces the World Narrative Model (WNM) to decouple the structured 4D physical world narrative from pixel rendering: collaborative agents convert sparse multimodal inputs (text, videos, sketches) into a fully editable 4D representation (geometry, layouts, skeletons, trajectories, camera, lighting) at quantitative granularity; this blueprint then drives frozen or lightly adapted video foundation models as a 'neural shader'. The approach is said to enable professional filmmaking pipelines via a human-AI platform, with experiments purportedly showing reduced gacha calls and better intent following. The framework is presented as open and modular.
Significance. If the agent-driven 4D orchestration can be shown to deliver reliable quantitative representations, the decoupling could meaningfully advance controllable video synthesis by aligning generation with deterministic production workflows rather than probabilistic sampling. The explicit emphasis on modularity and openness (allowing independent refinement of world representation, agents, and adapters) is a constructive design choice that could support incremental progress.
major comments (2)
- [Abstract] Abstract (collaborative agents paragraph): the load-bearing claim that agents translate sparse inputs into a 4D blueprint 'with scene geometry, object layouts, character/animal skeleton motion, trajectories, camera motion, and lighting at quantitative, physically meaningful granularity' supplies no algorithm, architecture, loss functions, training procedure, or completeness metric; without this, the asserted decoupling from end-to-end sampling and elimination of gacha loops cannot be evaluated.
- [Abstract] Abstract (final sentence before website): the assertion 'Experiments show that WNM greatly reduces probabilistic ``gacha'' calls and produces videos whose layout, motion, and cinematography closely follow creator intent' is unsupported by any experimental section, datasets, quantitative metrics, baselines, or ablation results in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify our contribution. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract (collaborative agents paragraph): the load-bearing claim that agents translate sparse inputs into a 4D blueprint 'with scene geometry, object layouts, character/animal skeleton motion, trajectories, camera motion, and lighting at quantitative, physically meaningful granularity' supplies no algorithm, architecture, loss functions, training procedure, or completeness metric; without this, the asserted decoupling from end-to-end sampling and elimination of gacha loops cannot be evaluated.
Authors: We acknowledge that the abstract presents a high-level description without specifying algorithms, architectures, loss functions, training procedures, or completeness metrics for the collaborative agents. The manuscript outlines the overall paradigm but does not provide these implementation details. We will revise the manuscript to include the requested technical specifications for the agent system that generates the quantitative 4D representation. revision: yes
-
Referee: [Abstract] Abstract (final sentence before website): the assertion 'Experiments show that WNM greatly reduces probabilistic ``gacha'' calls and produces videos whose layout, motion, and cinematography closely follow creator intent' is unsupported by any experimental section, datasets, quantitative metrics, baselines, or ablation results in the manuscript.
Authors: We agree that the current manuscript contains no experimental section, datasets, quantitative metrics, baselines, or ablations to support the claim. The statement refers to qualitative demonstrations on the project website. We will revise the abstract to remove or qualify the experimental assertion and, if appropriate, add a preliminary experimental section with supporting evidence in the revised manuscript. revision: yes
Circularity Check
No significant circularity; conceptual proposal without derivations or fittings
full rationale
The paper introduces a conceptual paradigm (WNM) that decouples world representation from pixel rendering via collaborative agents, but supplies no equations, parameter fittings, uniqueness theorems, or derivation steps. The abstract states the agents' translation capability as a given without exhibiting any reduction of outputs to inputs by construction. No self-citations, ansatzes, or renamings of known results appear in the load-bearing claims. This is a standard non-finding for a high-level architectural proposal lacking mathematical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing video foundation models can be driven by a structural 4D blueprint to act as neural shaders.
invented entities (3)
-
World Narrative Model (WNM)
no independent evidence
-
Collaborative agents
no independent evidence
-
4D pre-visualization blueprint
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Y . Liu, K. Zhang, Y . Li, Z. Yan, C. Gao, R. Chen, Z. Yuan, Y . Huang, H. Sun, J. Gao, L. He, and L. Sun, “Sora: A review on background, technology, limitations, and opportunities of large vision models,”arXiv preprint arXiv:2402.17177, 2024. [Online]. Available: https://arxiv.org/abs/2402.17177
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Kling-MotionControl technical report,
Kling Team, J. Chen, Y . Ding, Z. Fang, K. Gai, K. He, X. He, J. Hua, M. Lao, X. Li, H. Liu, J. Liu, X. Liu, F. Shi, X. Shi, P. Sun, S. Tang, P. Wan, T. Wen, Z. Wu, H. Zhang, R. Zhao, Y . Zhang, and Y . Zhou, “Kling-MotionControl technical report,” arXiv preprint arXiv:2603.03160, Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.03160
-
[3]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y . Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Li, X. Li, Y . Li, S. Lin, Z. Lin, J. Liu, S. Liu, X. Nie, Z. Qing, Y . Ren, L. Sun, Z. Tian, R. Wang, S. Wang, G. Wei, G. Wu, J. Wu, R. Xia, F. Xiao, X. Xiao, J. Yan, C. Yang, J. Yang, R. Yang, T. Yang, Y . Yang, Z. Ye, X. Zeng, Y . Zeng, H. Zhang, Y . Zhao, X. Zheng, P. Zhu,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedanceet al., “Seedance 1.5 pro: A native audio-visual joint generation foundation model,” 2025, seedance 1.5 pro Technical Report. [Online]. Available: https://arxiv.org/abs/2512.13507
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Seedance 2.0: Advancing Video Generation for World Complexity
——, “Seedance 2.0: Advancing video generation for world complexity,” Apr. 2026, seedance 2.0 Model Card. [Online]. Available: https: //arxiv.org/abs/2604.14148
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
TapNow: Your agentic creative canvas,
TapNow, “TapNow: Your agentic creative canvas,” Official website, 2026, accessed: 2026-06-28. [Online]. Available: https://www.tapnow.ai/
2026
-
[8]
Lovart: The world’s first ai design agent,
Lovart, “Lovart: The world’s first ai design agent,” Official website, 2026, accessed: 2026-06-28. [Online]. Available: https://www.lovart.ai/
2026
-
[9]
Seko: World-class ai video generation platform,
SenseTime, “Seko: World-class ai video generation platform,” Official website, 2026, accessed: 2026-06-28. [Online]. Available: https: //seko.sensetime.com/
2026
-
[10]
CapCut: AI-Powered Photo and Video Editor for Everyone,
CapCut, “CapCut: AI-Powered Photo and Video Editor for Everyone,” https://www.capcut.com/, 2026, accessed: 2026-06-29
2026
-
[11]
Nano AI: Your Personal Super Agent,
360 Group, “Nano AI: Your Personal Super Agent,” https://www.n.cn/, 2026, accessed: 2026-06-29
2026
-
[12]
LibTV: Professional video creation platform,
LiblibAI, “LibTV: Professional video creation platform,” Official website, 2026, accessed: 2026-06-28. [Online]. Available: https: //www.liblib.tv/
2026
-
[13]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017, pp. 5998–6008. [Online]. Available: https://proceedings.neurips.cc/paper/7181-attention-is-all-you-need
2017
-
[14]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 6840–6851. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/ 4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2020
-
[15]
Self-supervised learning from images with a joint-embedding predictive architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rab- bat, Y . LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2023, pp. 15 619–15 629
2023
-
[16]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas, “V-JEPA 2: Self-supervised...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Marble: A multimodal world model,
World Labs, “Marble: A multimodal world model,” Official product announcement, Nov. 2025, published November 12, 2025; accessed: 2026-06-28. [Online]. Available: https://www.worldlabs.ai/ blog/marble-world-model
2025
-
[18]
WorldGen: From text to traversable and interactive 3D worlds,
D. Wang, H. Jung, T. Monnier, K. Sohn, C. Zou, X. Xiang, Y .-Y . Yeh, D. Liu, Z. Huang, T. Nguyen-Phuoc, Y . Fan, S. Oprea, Z. Wang, R. Shapovalov, N. Sarafianos, T. Groueix, A. Toisoul, P. Dhar, X. Chu, M. Chen, G. Y . Park, M. Gupta, Y . Azziz, R. Ranjan, and A. Vedaldi, “WorldGen: From text to traversable and interactive 3D worlds,”arXiv preprint arXiv...
-
[19]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, “Cosmos world foundation model platform for physical AI,”arXiv preprint arXiv:2501.03575, Jan. 2025. [Online]. Available: https://arxiv.org/abs/2501.03575
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Cosmos 3: Omnimodal World Models for Physical AI
——, “Cosmos 3: Omnimodal world models for physical AI,” arXiv preprint arXiv:2606.02800, Jun. 2026. [Online]. Available: https://arxiv.org/abs/2606.02800
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
InSpatio Team, D. Shen, G. Zhang, H. Liu, H. Ji, H. Bao, H. Zhai, J. Liu, J. Guo, N. Wang, S. Pan, W. Pan, W. Xie, X. Liu, X. Xiang, X. Zhang, X. Chen, Y . Wang, Y . Chen, Z. Fan, Z. Le, Z. Ye, and Z. Zhao, “INSPATIO-WORLD: A real-time 4D world simulator via spatiotemporal autoregressive modeling,”arXiv preprint arXiv:2604.07209, 2026. [Online]. Available...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[23]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, October 2023, pp. 3836–3847. [Online]. Available: https://openaccess.thecvf. com/content/ICCV2023/html/Zhang Adding Conditional Control to Text-to-Image Diffusion Models ICCV 2023 paper.html
2023
-
[24]
SAM 3D: 3dfy anything in images,
SAM 3D Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, A. Lin, J. Liu, Z. Ma, A. Sagar, B. Song, X. Wang, J. Yang, B. Zhang, P. Doll ´ar, G. Gkioxari, M. Feiszli, and J. Malik, “SAM 3D: 3dfy anything in images,” Nov
-
[25]
SAM 3D: 3Dfy Anything in Images
[Online]. Available: https://arxiv.org/abs/2511.16624
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2602.15989 (2026)
X. Yang, D. Kukreja, D. Pinkus, A. Sagar, T. Fan, J. Park, S. Shin, J. Cao, J. Liu, N. Ugrinovic, M. Feiszli, J. Malik, P. Doll ´ar, and K. Kitani, “SAM 3D Body: Robust full-body human mesh recovery,” Feb. 2026. [Online]. Available: https://arxiv.org/abs/2602.15989
-
[27]
VGGT: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual geometry grounded transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2025, pp. 5294–5306. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2025/html/Wang VGGT Visual Geometry Grounded Transformer CV...
2025
-
[28]
J. Wang, M. Chen, S. Zhang, N. Karaev, J. Sch ¨onberger, P. Labatut, P. Bojanowski, D. Novotny, A. Vedaldi, and C. Rupprecht, “VGGT-ω,” 18 inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2026, pp. 21 486–21 499. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2026/ html/Wang VGGT-ohm CVPR 202...
2026
-
[29]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth Anything 3: Recovering the visual space from any views,” Nov. 2025. [Online]. Available: https://arxiv.org/abs/2511.10647
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Native and compact structured latents for 3D generation,
J. Xiang, X. Chen, S. Xu, R. Wang, Z. Lv, Y . Deng, H. Zhu, Y . Dong, H. Zhao, N. J. Yuan, and J. Yang, “Native and compact structured latents for 3D generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2026, pp. 14 419–14 429. [Online]. Available: https://openaccess.thecvf. com/content/CVPR2026/htm...
2026
-
[31]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2022, pp. 11 523–11 532
2022
-
[32]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H ´enaff, J. Harmsen, A. Steiner, and X. Zhai, “SigLIP 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025. [Online]. Available...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Introducing Codex,
OpenAI, “Introducing Codex,” https://openai.com/index/ introducing-codex/, May 2025
2025
-
[34]
GPT-5.5 System Card,
——, “GPT-5.5 System Card,” OpenAI, Tech. Rep., Apr. 2026. [Online]. Available: https://openai.com/index/gpt-5-5-system-card/
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.