Cosmos 3: Omnimodal World Models for Physical AI
Pith reviewed 2026-06-28 15:06 UTC · model grok-4.3
The pith
A single mixture-of-transformers model jointly processes and generates language, images, video, audio, and actions for Physical AI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
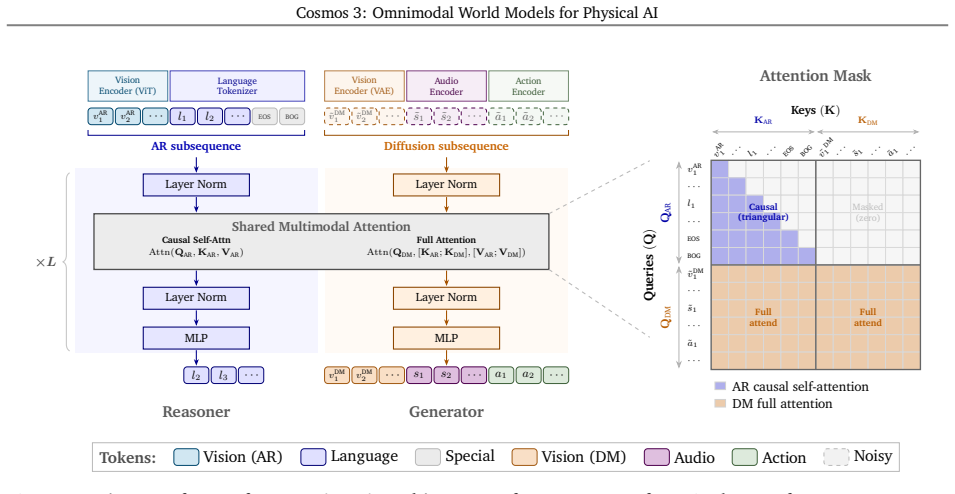
Cosmos 3 establishes a unified mixture-of-transformers architecture that jointly processes and generates sequences across language, image, video, audio, and action modalities, achieving new state-of-the-art performance on diverse tasks and serving as general-purpose backbones for embodied agents.
What carries the argument
mixture-of-transformers architecture supporting highly flexible input-output configurations across multiple modalities
If this is right
- Vision-language models, video generators, and world simulators become interchangeable components of one system.
- Embodied agents can use the same backbone for both perception and action planning without switching models.
- Open release of the models and synthetic datasets enables direct replication and extension by other researchers.
Where Pith is reading between the lines
- If the no-trade-off claim holds, training pipelines for robotics could shift from assembling multiple models to fine-tuning one omnimodal base.
- Real-world deployment would still require separate validation that simulated action sequences transfer to physical hardware.
Load-bearing premise
One shared architecture can reach top performance in every modality without substantial trade-offs in any single one.
What would settle it
A direct comparison where adding audio or action generation to the model produces a clear drop in text-to-image or image-to-video quality relative to specialized single-modality models.
Figures







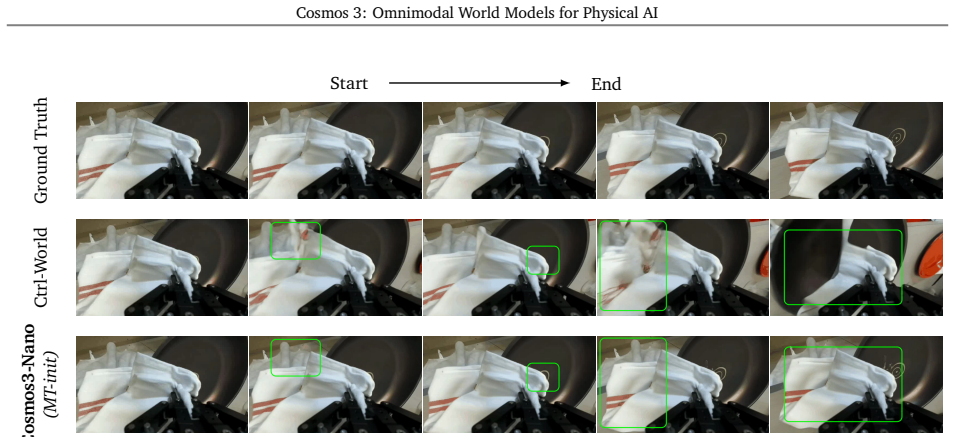

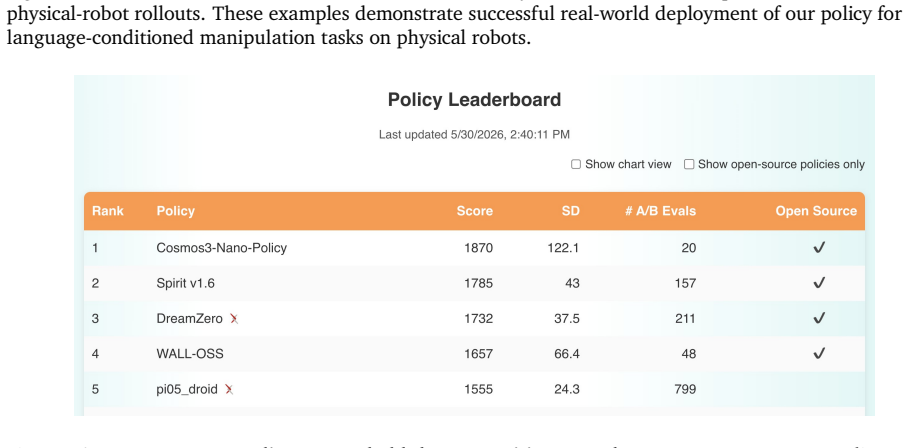
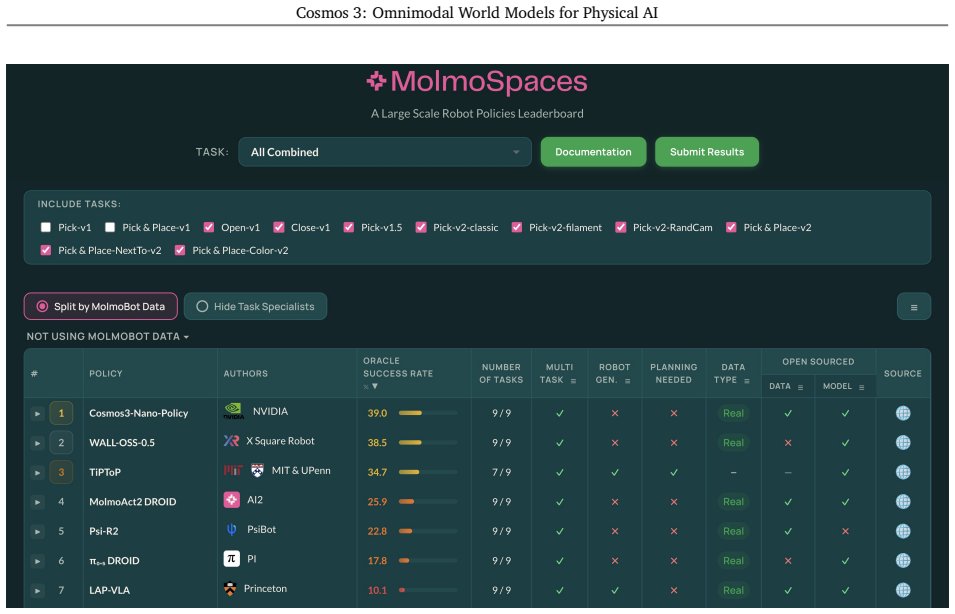
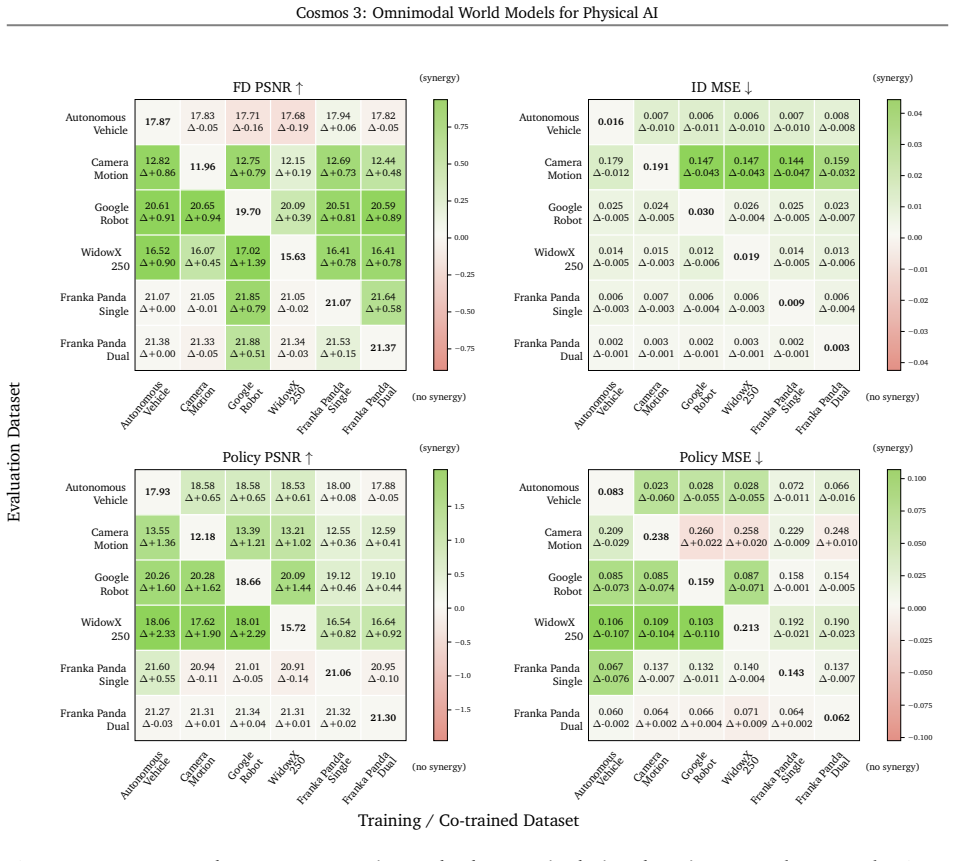







read the original abstract
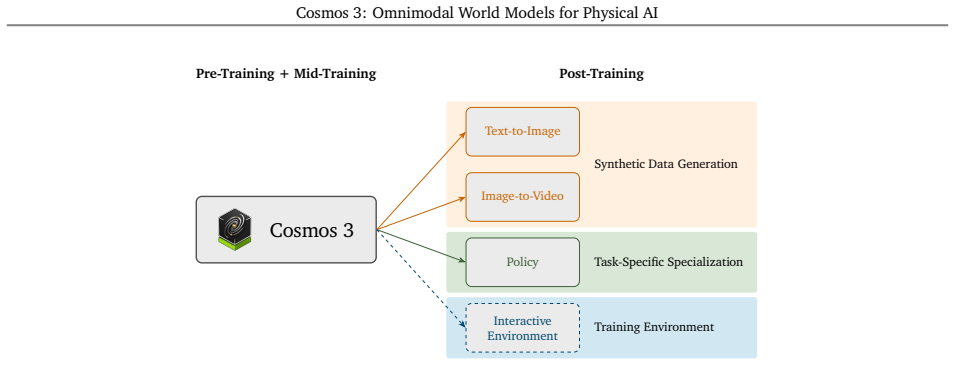
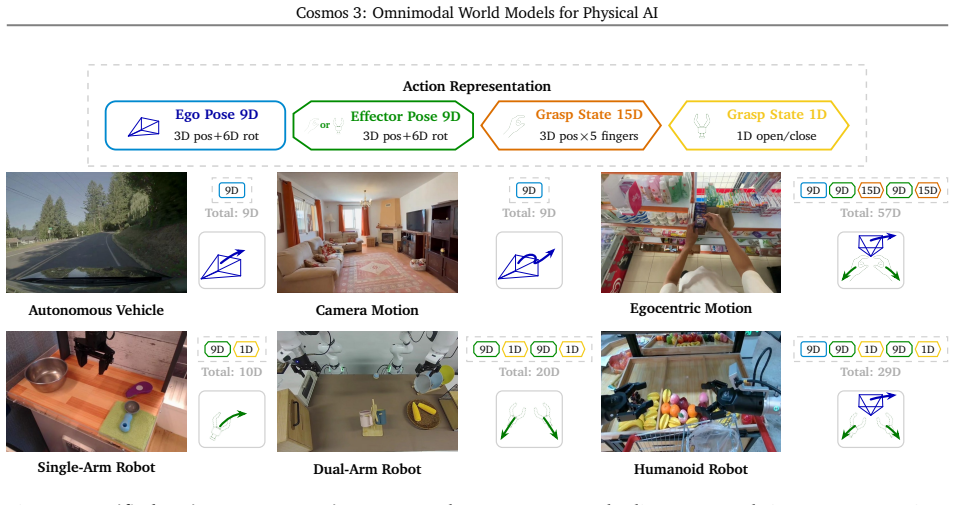
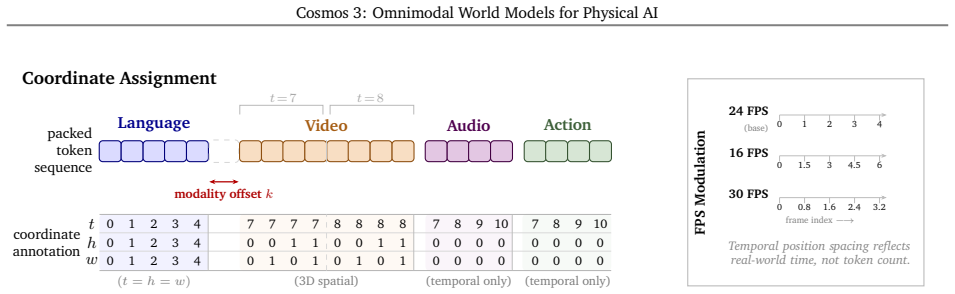
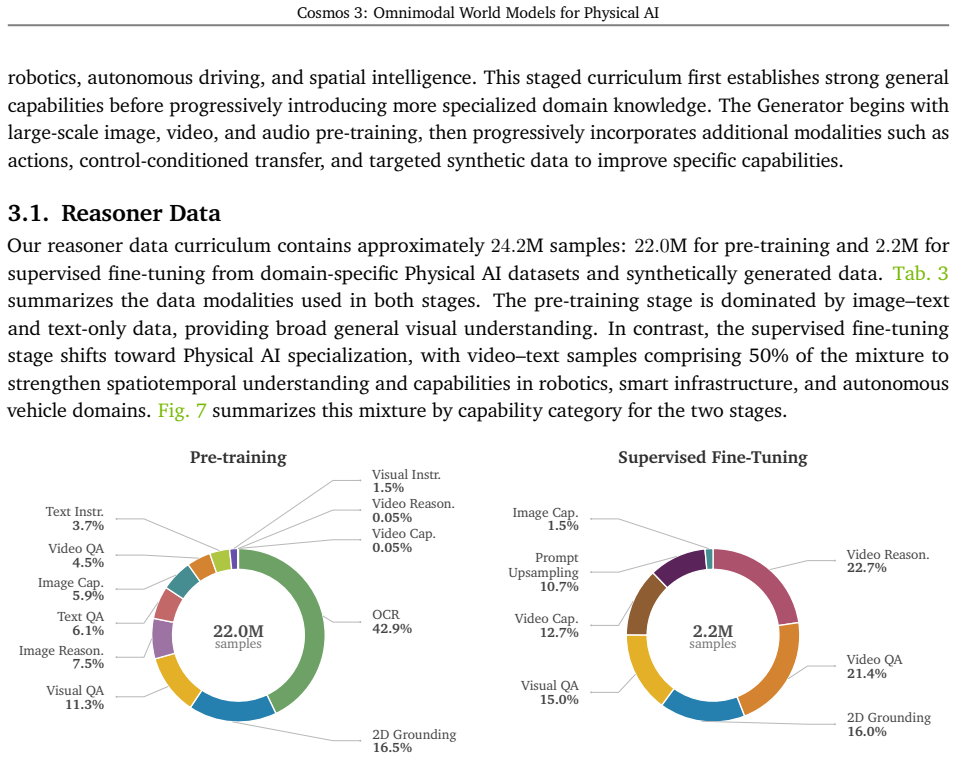
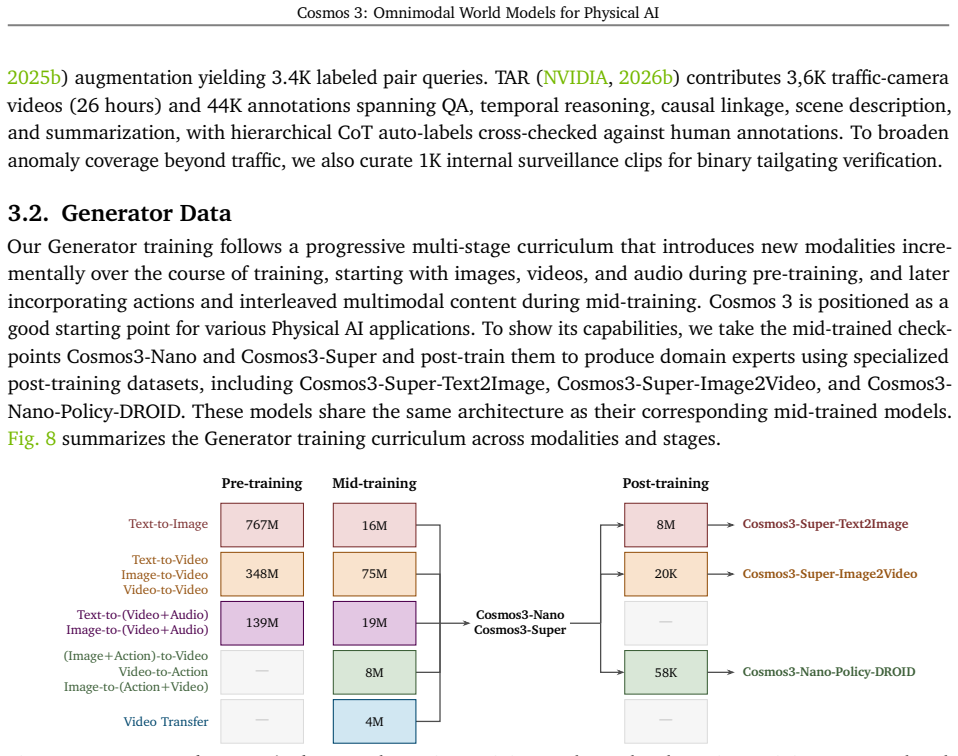
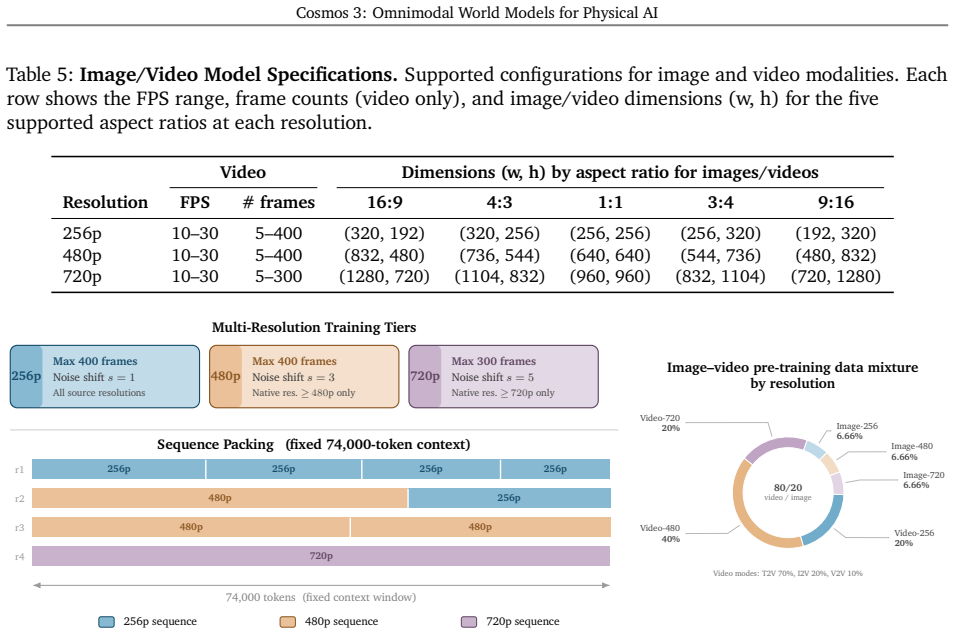
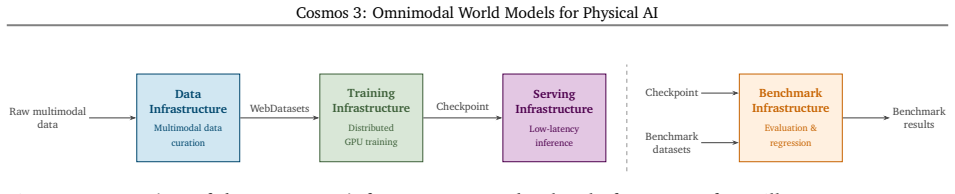
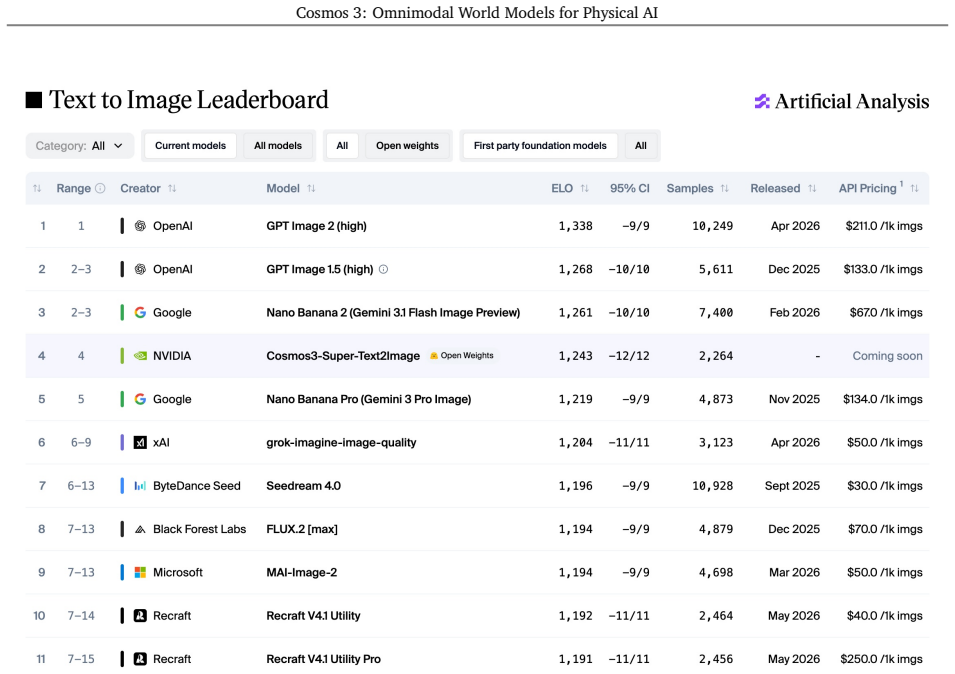
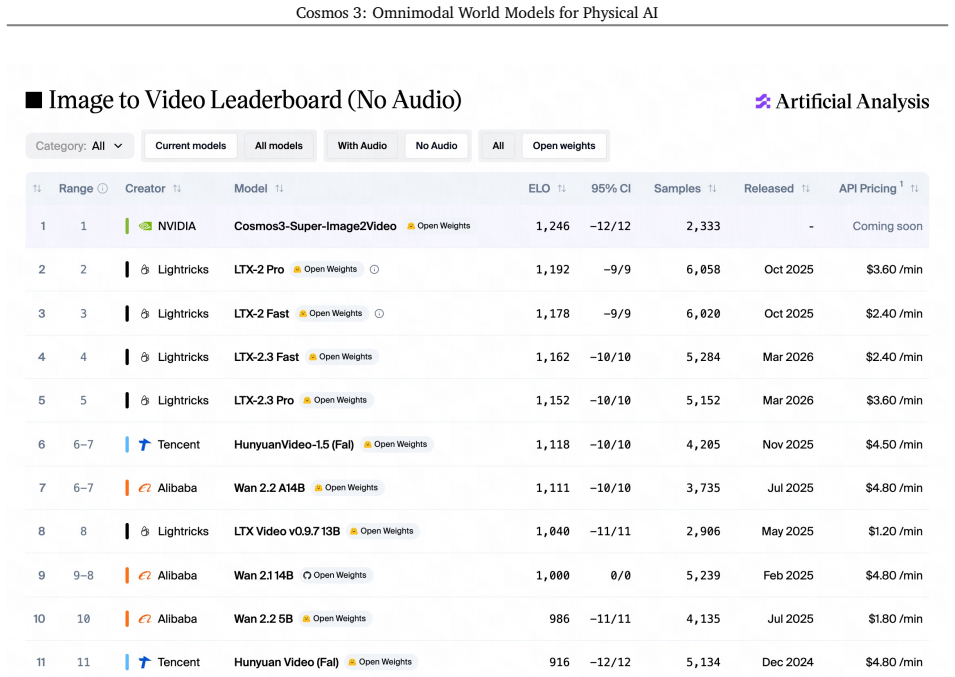
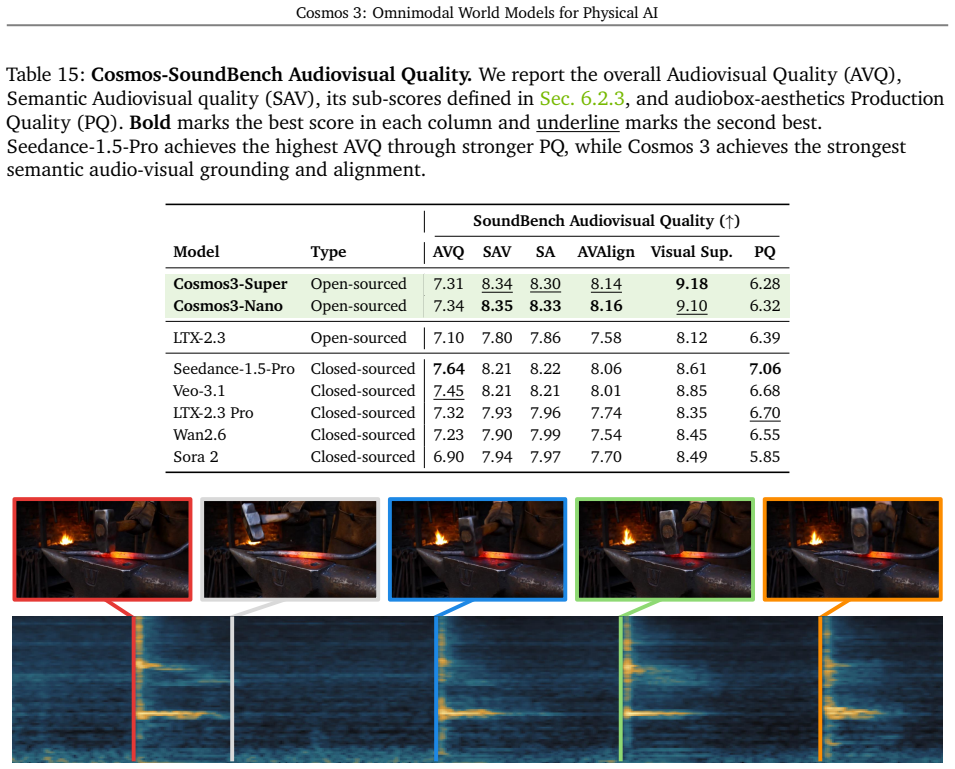
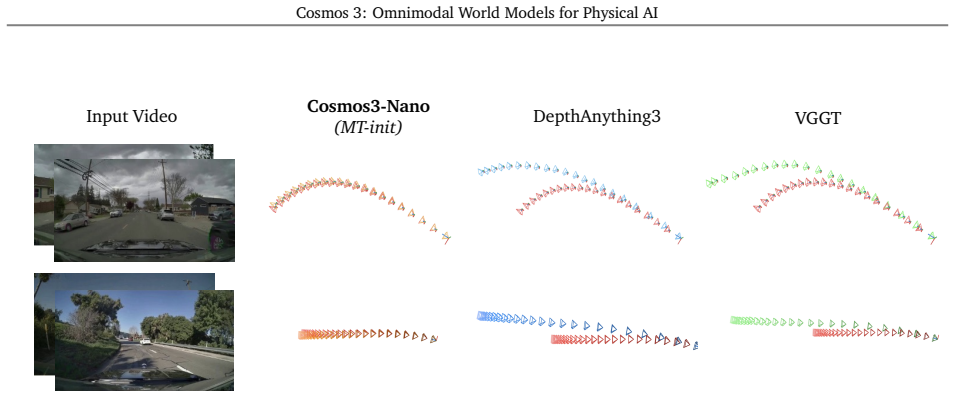
We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 License at https://github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3. The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cosmos 3, a family of omnimodal world models based on a mixture-of-transformers architecture that jointly processes and generates across language, image, video, audio, and action modalities. It claims to unify vision-language models, video generators, world simulators, and world-action models into a single framework, establishes new state-of-the-art performance on a diverse suite of understanding and generation tasks for Physical AI, and reports top rankings from external evaluations (Artificial Analysis for T2I/I2V and RoboArena for policy models). The work releases code, checkpoints, synthetic datasets, and benchmarks under the OpenMDW-1.1 license.
Significance. If the empirical SOTA claims hold under independent verification, the work would be significant as a demonstration that a single scalable architecture can serve as a general-purpose backbone for embodied agents without modality-specific trade-offs. The open release of code, models, and benchmarks is a clear strength that directly enables reproducibility and falsification of the no-trade-off assumption.
major comments (1)
- Abstract: the central claim that Cosmos 3 'establishes a new state-of-the-art across a diverse suite of understanding and generation tasks' is unsupported by any metrics, baselines, evaluation protocols, or error analysis in the provided text, which is load-bearing for the primary contribution.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger support of the central SOTA claim. We address the point below and indicate planned revisions.
read point-by-point responses
-
Referee: [—] Abstract: the central claim that Cosmos 3 'establishes a new state-of-the-art across a diverse suite of understanding and generation tasks' is unsupported by any metrics, baselines, evaluation protocols, or error analysis in the provided text, which is load-bearing for the primary contribution.
Authors: The abstract is a concise summary; the full manuscript substantiates the claim with detailed metrics, baselines, protocols, and analyses in Sections 4 (omnimodal understanding benchmarks) and 5 (generation and simulation tasks), plus the external Artificial Analysis and RoboArena rankings. We agree the abstract would be stronger with explicit quantitative anchors or section pointers and will revise it to include key results (e.g., top scores on representative tasks) while retaining brevity. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript is an empirical model release describing an omnimodal architecture and its benchmark results. No equations, derivations, or first-principles claims appear in the abstract or described content. Central assertions rest on external third-party rankings and released code/checkpoints that enable independent verification rather than any self-referential fitting or self-citation chain. The work therefore contains no load-bearing steps that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 13 Pith papers
-
Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
Causal-rCM unifies teacher-forcing and self-forcing distillation for autoregressive video diffusion, delivering a 2-step model with VBench-T2V score 84.63 and enabling interactive world models on Cosmos 3 using only s...
-
DiffusionBench: On Holistic Evaluation of Diffusion Transformers
NanoGen unifies DiT training on ImageNet and T2I, reveals negative Pearson correlations (-0.377 to -0.580) in method rankings across metrics from 21 models, and motivates DiffusionBench for holistic evaluation.
-
ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
ImageWAM shows image editing models can replace video generation in world action models, delivering better performance with 6x lower FLOPs and 4x lower latency by using edit-derived KV caches as compact context.
-
SC3-Eval: Evaluating Robot Foundation Models via Self-Consistent Video Generation
SC3-Eval enforces three consistency constraints on video world models to evaluate robot manipulation policies, achieving 0.929 Pearson correlation with real-world rollouts across seven policies.
-
SC3-Eval: Evaluating Robot Foundation Models via Self-Consistent Video Generation
SC3-Eval enforces three consistencies on a video model to produce policy rollouts that correlate 0.929 with real-world performance across seven vision-language-action policies and reproduce observed failure modes.
-
ActWorld: From Explorable to Interactive World Model via Action-Aware Memory
ActWorld extends navigation-centric world models to support mid-rollout object interactions via chunk-autoregressive generation, action-aware memory routing, and a persistent memory bank, backed by a 100K annotated in...
-
PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
PhysisForcing applies trajectory and relational alignment losses to DiT features in video models, improving physical plausibility on R-Bench, PAI-Bench, and EZS-Bench while raising closed-loop robotic success rates fr...
-
Learning Action Priors for Cross-embodiment Robot Manipulation
A two-stage framework pretrains an action module with temporal motion priors from unconditioned trajectories using flow-matching, then transfers it to VLA training via decoder reuse and distillation, yielding better p...
-
Sol Video Inference Engine: Agent-Native Full-Stack Acceleration Framework for Efficient Video Generation
Sol Video Inference Engine uses parallel skill agents to optimize cache, sparse attention, token pruning, quantization, and kernel fusion, delivering over 2x end-to-end acceleration with near-lossless quality on three...
-
Physics-IQ Verified
Physics-IQ Verified refines 57.6% of samples and 34.8% of prompts from the original benchmark and produces moderate ranking shifts (Kendall's τ = 0.46) across six image-to-video models.
-
PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
PAIWorld adds explicit geometric cross-view mechanisms and 3D distillation to DiT world models to achieve multi-view 3D consistency in robotic manipulation benchmarks.
-
What Spatial Memory Must Store: Occlusion as the Test for Language-Agent Memory
Geometry-led weighting outperforms blended memory recall for spatial queries, and a DDA-based visibility predicate correctly flags occluded targets while recall remains occlusion-blind.
-
Critique of Agent Model
Distinguishes agentic (externally scaffolded) from agentive (internally structured) AI systems and proposes the Goal-Identity-Configurator architecture for endogenous autonomy.
Reference graph
Works this paper leans on
-
[1]
Revisiting feature prediction for learning visual representations from video
77 Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. InICLR, 2025. 76 James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improv...
Pith/arXiv arXiv 2025
-
[2]
76 Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. InIROS, 2025. 25, 63, 78 Junhao Cai, Zetao Cai, Jiafei Cao, Yilun Chen, Zeyu He, Lei Jiang, Hang Li, Hengjie Li, Yang Li, Yufei L...
arXiv 2025
-
[3]
79 Chilam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, et al. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. 78 Atoosa Chegini, Keivan Rezaei, Hamid Eghbalzadeh, and Soheil Feizi. RePanda: Pandas-powered tabular verification and reasoning. InACL, 2025. 75 Boyuan ...
Pith/arXiv arXiv 2024
-
[4]
Out of time: Automated lip sync in the wild
25 Joon Son Chung and Andrew Zisserman. Out of time: Automated lip sync in the wild. InACCV Workshops,
-
[5]
Gramaccioni, Emilian Postolache, Emanuele Rodola, Danilo Comminiello, and Joshua D
24, 78 Marco Comunita, Riccardo F. Gramaccioni, Emilian Postolache, Emanuele Rodola, Danilo Comminiello, and Joshua D. Reiss. SyncFusion: Multimodal onset-synchronized video-to-audio foley synthesis. InICASSP, 2024. 78 AgiBot World Colosseum contributors. AgiBot world colosseum. https://github.com/OpenDriveLab/AgiBot-World, 2024. 78 Jade Copet, Felix Kreu...
arXiv 2024
-
[6]
Prompt expansion for adaptive text-to-image generation
52, 53 Siddhartha Datta, Alexander Ku, Deepak Ramachandran, and Peter Anderson. Prompt expansion for adaptive text-to-image generation. InACL, 2024. 74 Google DeepMind. Veo 3, 5 2025. URLhttps://deepmind.google/technologies/veo/veo-3/. 77, 79 Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas M...
Pith/arXiv arXiv 2024
-
[7]
VLMEvalKit: An open-source toolkit for evaluating large multi-modality models
54 Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. VLMEvalKit: An open-source toolkit for evaluating large multi-modality models. In ACM MM, 2024. 50, 52 Andreas Dürr. The city generator.https://superhivemarket.com/products/the-city-generator/, 5
2024
-
[8]
ElevenLabs Sound Effects.https://elevenlabs.io/sound-effects, 2024
102 ElevenLabs. ElevenLabs Sound Effects.https://elevenlabs.io/sound-effects, 2024. 78 Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, and Michael Rubinstein. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation.ACM TOG, 2018. 78 Weixi Feng, Wanrong...
arXiv 2024
-
[9]
75 Harvard-MIT Mathematics Tournament. HMMT February 2025, 2025. URL https://hmmt-archive.s3.amazonaws.com/tournaments/2025/feb/comb/solutions.pdf. 106 Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi. Neighborhood attention transformer. In CVPR, 2023. 40 Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Ya...
Pith/arXiv arXiv 2025
-
[10]
Accessed: 2026-05-20. 35 Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. Voicebox: Text-guided multilingual universal speech generation at scale. InNeurIPS, 2023. 78 Julien Le Dem. Parquet: Columnar storage for the people. Strata + Hadoop World, New York, https:/...
Pith/arXiv arXiv 2026
-
[11]
33 Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching CLIP to count to ten. InICCV, 2023. 52 130 Cosmos 3: Omnimodal World Models for Physical AI Brahma S. Pavse, Faraz Torabi, Josiah P. Hanna, Garrett Warnell, and Peter Stone. RIDM: Reinforced inverse dynamics modeling for learning from a single observe...
Pith/arXiv arXiv 2023
-
[12]
22 David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023. 106 Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhang...
Pith/arXiv arXiv 2023
-
[13]
MM-Diffusion: Learning multi-modal diffusion models for joint audio and video generation
66 Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. MM-Diffusion: Learning multi-modal diffusion models for joint audio and video generation. In CVPR, 2023. 79 Runway. Gen-3 Alpha, 2024. URLhttps://runwayml.com/research/introducing-gen-3-alpha. 77 Runway. Runway Gen-4.https://runwayml.com/res...
arXiv 2023
-
[14]
Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025
76 Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025. 31 World Labs. Marble: A multimodal world model.https://www.worldlabs.ai/blog/marble-world-model,
Pith/arXiv arXiv 2025
-
[15]
World Labs blog post, accessed 2026-05-04. 76 135 Cosmos 3: Omnimodal World Models for Physical AI Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InCVPR, 2023a. 21, 63, 108 Hongtao Wu, ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.