Adapting Generalist Robot Policies with Semantic Reinforcement Learning
Pith reviewed 2026-07-01 05:06 UTC · model grok-4.3
The pith
Modulating language prompts lets generalist robot policies adapt to complex tasks via reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
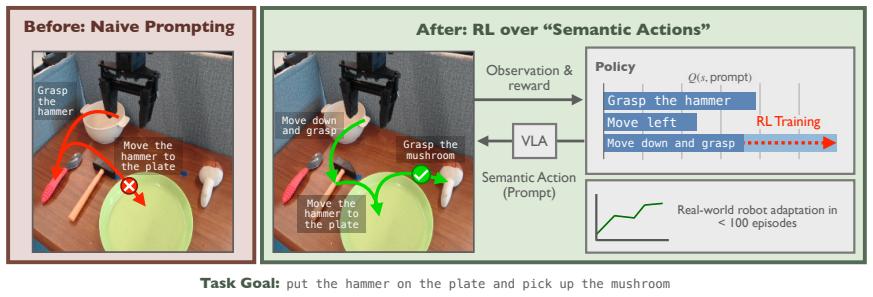
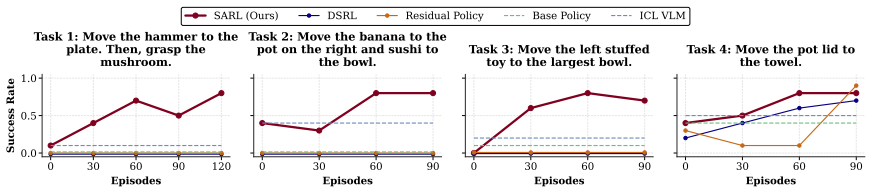
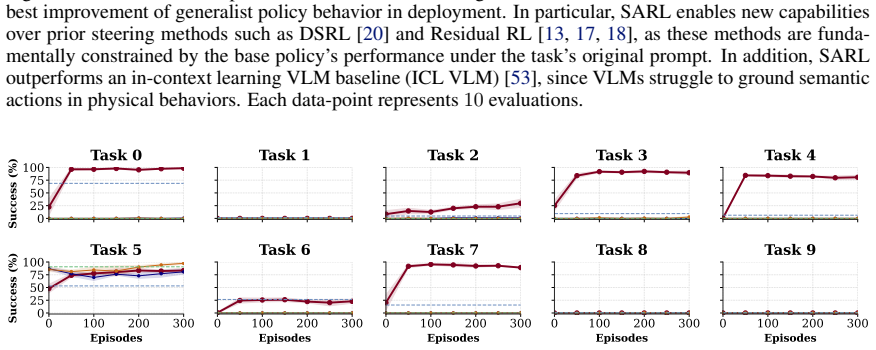
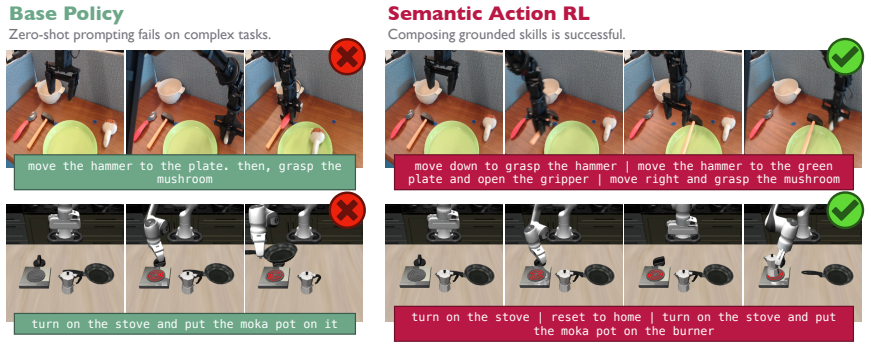
The paper's central claim is that, for sufficiently expressive generalist policies, language prompts form an effective optimization space for reinforcement learning: modulating the language input elicits skills already within the policy's repertoire and allows their composition to solve tasks beyond zero-shot performance. SARL learns a policy over prompt space through online interaction, treating the frozen generalist as a controllable skill prior. This yields semantically meaningful exploration, efficient online improvement, and prompts that become grounded in the actual behaviors they induce.
What carries the argument
Semantic Action Reinforcement Learning (SARL), the algorithm that performs reinforcement learning over the space of language prompts supplied to a fixed generalist policy rather than over the policy's raw action outputs.
If this is right
- Complex, long-horizon tasks outside the pretraining distribution become solvable by adapting visual-language-action models.
- Exploration during learning remains structured and semantically meaningful instead of unstructured in action space.
- Prompts become grounded in induced real-world behaviors, supporting robust task execution.
- Online improvement is substantially more sample-efficient than methods that learn new skills from scratch.
- The approach outperforms prior methods that attempt to improve deployed robot behavior through direct action-space RL.
Where Pith is reading between the lines
- The same prompt-space optimization idea could be tested on generalist policies that accept other conditioning signals besides language.
- If prompt optimization works reliably, it may reduce the data and compute needed to specialize large robot models for new environments.
- Limits of the method could be probed by measuring how performance scales with the diversity of skills present in the base policy.
- Techniques developed for optimizing prompts in language models might transfer directly to this robot setting.
Load-bearing premise
The generalist policy must already contain the component skills that language-prompt changes can reliably elicit and combine for the new task.
What would settle it
SARL produces no measurable improvement over the base policy or random prompting on a task for which no relevant sub-skills can be elicited from the generalist even after exhaustive prompt search.
Figures


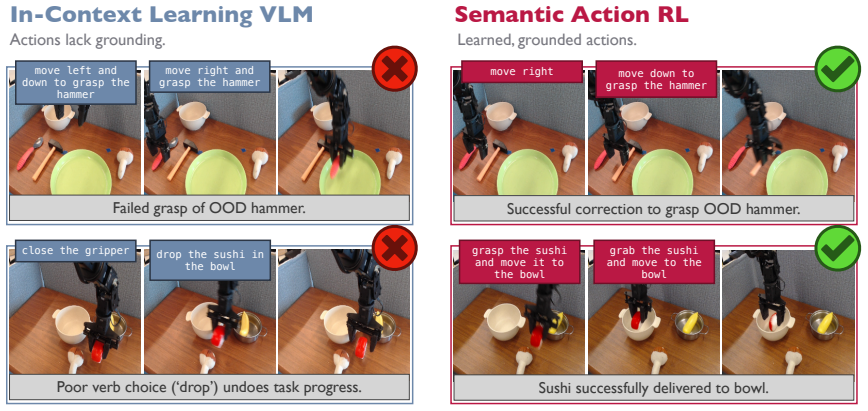
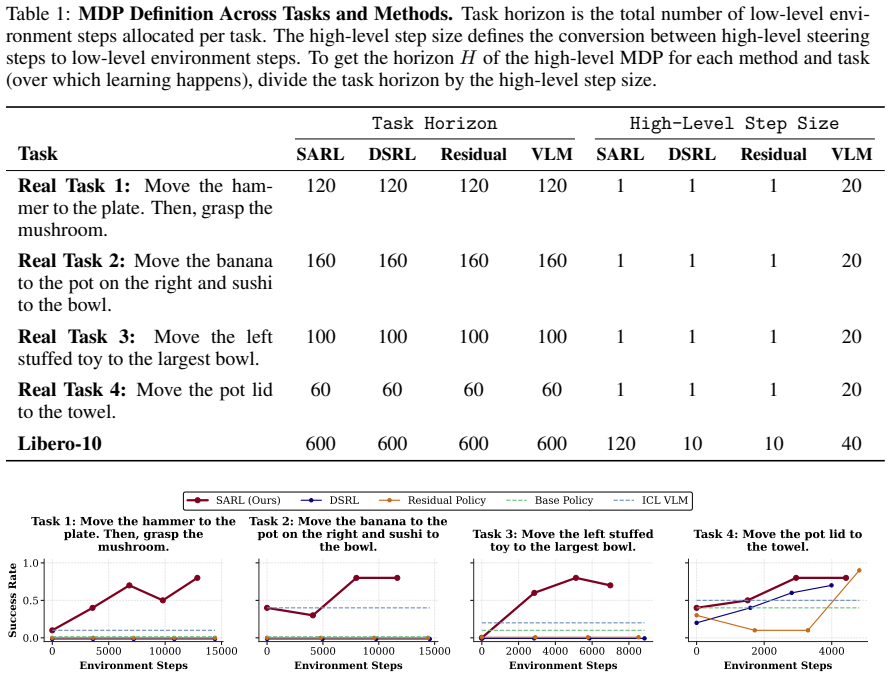







read the original abstract
Generalist robot policies learn a diverse repertoire of behaviors from large-scale pretraining. In principle, this makes them excellent priors for downstream adaptation via reinforcement learning (RL). In practice, however, standard RL methods leveraging this prior optimize directly over robot actions, requiring the base policy's action distribution to be close to that of a performant policy from the start. This assumption breaks down for complex or long-horizon tasks that fall outside the pretraining distribution. Our key insight is that, for sufficiently expressive generalist policies, language prompts are an effective alternative space for learning to solve such tasks: modulating language inputs elicits skills already within the policy's repertoire, which can be composed to solve tasks beyond its zero-shot capabilities. We propose Semantic Action Reinforcement Learning (SARL), which learns to optimize this prompt space through online interaction, treating the generalist policy as a controllable skill prior. Importantly, leveraging pretrained skills rather than learning new ones from scratch yields structured, semantically meaningful exploration and highly efficient online improvement, and learning to modulate prompts through experience grounds them in induced real-world behaviors for robust task-solving. Across real-world settings and simulated benchmarks, we show SARL unlocks fundamentally new capabilities -- adapting VLA behavior to solve complex, long-horizon tasks -- and significantly outperforms existing approaches for improving robot behavior in deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for sufficiently expressive generalist robot policies, language prompts provide an effective alternative optimization space for RL adaptation on out-of-distribution tasks. SARL learns to modulate prompts online to elicit and compose pretrained skills, yielding structured exploration and efficient improvement over action-space RL. The method is reported to unlock new capabilities for complex long-horizon tasks and to outperform baselines across real-world settings and simulated benchmarks.
Significance. If the empirical claims hold, the work offers a promising direction for leveraging large-scale pretrained generalist policies in robotics by shifting RL to a semantically meaningful prompt space rather than raw actions. This could enable more practical adaptation without requiring the base policy's action distribution to already be near-optimal, with potential for broader impact on deployment of VLA-style models.
minor comments (2)
- The description of how the prompt space is parameterized (e.g., continuous vs. discrete embeddings, vocabulary constraints) and how the RL update is performed on it would benefit from an explicit algorithmic outline or pseudocode for reproducibility.
- The abstract states that SARL 'significantly outperforms existing approaches'; a concise table or set of key metrics (success rate, sample efficiency) comparing against the strongest baselines should be referenced early in the introduction or results overview.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our contributions, and recommendation for minor revision. We appreciate the recognition of SARL's potential impact on adapting generalist VLA policies for long-horizon tasks via prompt-space optimization.
Circularity Check
No significant circularity identified
full rationale
The paper proposes SARL as a method for adapting generalist policies via language prompt modulation in RL, with the central insight stated directly in the abstract and no derivation chain, equations, or fitted parameters presented. Claims rest on empirical evaluation across real-world and simulated settings rather than reducing to self-citations, ansatzes, or inputs by construction. No load-bearing steps match any of the enumerated circularity patterns, and the argument is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption For sufficiently expressive generalist policies, modulating language inputs elicits skills already within the policy's repertoire that can be composed for new tasks.
Reference graph
Works this paper leans on
-
[1]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manip- ulation.arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [6]
-
[7]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
- [11]
-
[12]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control, 2018. URLhttps://arxiv.org/abs/1812. 03201
2018
-
[13]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement-residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
2025
- [14]
- [15]
-
[16]
P. Dong, Q. Li, D. Sadigh, and C. Finn. Expo: Stable reinforcement learning with expressive policies. arXiv preprint arXiv:2507.07986, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. Rl token: Bootstrapping online rl with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [19]
-
[20]
Wagenmaker, M
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.Conference on Robot Learning, 2025
2025
-
[21]
A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foun- dation models via value guidance.arXiv preprint arXiv:2410.13816, 2024
- [24]
-
[25]
J. Hu, R. Hendrix, A. Farhadi, A. Kembhavi, R. Mart ´ın-Mart´ın, P. Stone, K.-H. Zeng, and K. Ehsani. Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine- tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3617–3624. IEEE, 2025
2025
- [26]
-
[27]
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
-
[29]
Daniel, G
C. Daniel, G. Neumann, O. Kroemer, and J. Peters. Hierarchical relative entropy policy search.Journal of Machine Learning Research, 17(93):1–50, 2016
2016
-
[30]
T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation.Advances in neural information processing systems, 29, 2016. 11
2016
-
[31]
X. B. Peng, G. Berseth, K. Yin, and M. Van De Panne. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning.Acm transactions on graphics (tog), 36(4):1–13, 2017
2017
-
[32]
Riedmiller, R
M. Riedmiller, R. Hafner, T. Lampe, M. Neunert, J. Degrave, T. Wiele, V . Mnih, N. Heess, and J. T. Springenberg. Learning by playing solving sparse reward tasks from scratch. InInternational confer- ence on machine learning, pages 4344–4353. PMLR, 2018
2018
-
[33]
Nachum, S
O. Nachum, S. S. Gu, H. Lee, and S. Levine. Data-efficient hierarchical reinforcement learning.Ad- vances in neural information processing systems, 31, 2018
2018
-
[34]
Gehring, G
J. Gehring, G. Synnaeve, A. Krause, and N. Usunier. Hierarchical skills for efficient exploration.Ad- vances in Neural Information Processing Systems, 34:11553–11564, 2021
2021
-
[35]
Neural probabilistic motor primitives for humanoid control
J. Merel, L. Hasenclever, A. Galashov, A. Ahuja, V . Pham, G. Wayne, Y . W. Teh, and N. Heess. Neural probabilistic motor primitives for humanoid control.arXiv preprint arXiv:1811.11711, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [36]
- [37]
-
[38]
Pertsch, Y
K. Pertsch, Y . Lee, and J. Lim. Accelerating reinforcement learning with learned skill priors. InCon- ference on robot learning, pages 188–204. PMLR, 2021
2021
-
[39]
S. Nasiriany, T. Gao, A. Mandlekar, and Y . Zhu. Learning and retrieval from prior data for skill-based imitation learning.arXiv preprint arXiv:2210.11435, 2022
-
[40]
M. Wilcoxson, Q. Li, K. Frans, and S. Levine. Leveraging skills from unlabeled prior data for efficient online exploration.arXiv preprint arXiv:2410.18076, 2024
-
[41]
Huang, P
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
2022
-
[42]
A. Zeng, M. Attarian, B. Ichter, K. Choromanski, A. Wong, S. Welker, F. Tombari, A. Purohit, M. Ryoo, V . Sindhwani, et al. Socratic models: Composing zero-shot multimodal reasoning with language.arXiv preprint arXiv:2204.00598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Cheb- otar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
2023
- [47]
- [48]
-
[49]
H. Ha, P. Florence, and S. Song. Scaling up and distilling down: Language-guided robot skill acquisi- tion. InConference on Robot Learning, pages 3766–3777. PMLR, 2023
2023
-
[50]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [51]
-
[52]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language-action models. arXiv preprint arXiv:2502.19417, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control. arXiv preprint arXiv:2602.13193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [54]
- [55]
-
[56]
T. Shin, Y . Razeghi, R. L. L. Iv, E. Wallace, and S. Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 4222–4235, 2020
2020
-
[57]
Y . Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba. Large language models are human-level prompt engineers. InThe eleventh international conference on learning representations, 2022
2022
-
[58]
gradient descent
R. Pryzant, D. Iter, J. Li, Y . Lee, C. Zhu, and M. Zeng. Automatic prompt optimization with “gradient descent” and beam search. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7957–7968, 2023
2023
-
[59]
M. Deng, J. Wang, C.-P. Hsieh, Y . Wang, H. Guo, T. Shu, M. Song, E. Xing, and Z. Hu. Rlprompt: Optimizing discrete text prompts with reinforcement learning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369–3391, 2022
2022
- [60]
-
[61]
Jung and K.-J
H. Jung and K.-J. Kim. Discrete prompt compression with reinforcement learning.IEEE Access, 12: 72578–72587, 2024
2024
-
[62]
X. Wang, C. Li, Z. Wang, F. Bai, H. Luo, J. Zhang, N. Jojic, E. Xing, and Z. Hu. Promptagent: Strategic planning with language models enables expert-level prompt optimization. InInternational Conference on Learning Representations, volume 2024, pages 23967–24001, 2024. 13
2024
-
[63]
Q. Guo, R. Wang, J. Guo, B. Li, K. Song, X. Tan, G. Liu, J. Bian, and Y . Yang. Evoprompt: Connecting llms with evolutionary algorithms yields powerful prompt optimizers.arXiv e-prints, pages arXiv–2309, 2023
2023
- [64]
-
[65]
Jafari, D
Y . Jafari, D. Mekala, R. Yu, and T. Berg-Kirkpatrick. Morl-prompt: An empirical analysis of multi- objective reinforcement learning for discrete prompt optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9878–9889, 2024
2024
-
[66]
PRL: Prompts from Reinforcement Learning
P. Batorski, A. Kosmala, and P. Swoboda. Prl: Prompts from reinforcement learning.arXiv preprint arXiv:2505.14412, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
W. Kong, S. Hombaiah, M. Zhang, Q. Mei, and M. Bendersky. Prewrite: Prompt rewriting with rein- forcement learning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 594–601, 2024
2024
-
[68]
M. Kwon, G. Kim, J. Kim, H. Lee, and J. Kim. Stableprompt: Automatic prompt tuning using re- inforcement learning for large language model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9868–9884, 2024
2024
-
[69]
Mirchandani, S
S. Mirchandani, S. Karamcheti, and D. Sadigh. Ella: Exploration through learned language abstraction. Advances in neural information processing systems, 34:29529–29540, 2021
2021
-
[70]
J. Mu, V . Zhong, R. Raileanu, M. Jiang, N. Goodman, T. Rockt¨aschel, and E. Grefenstette. Improving intrinsic exploration with language abstractions.Advances in Neural Information Processing Systems, 35:33947–33960, 2022
2022
-
[71]
A. Tam, N. Rabinowitz, A. Lampinen, N. A. Roy, S. Chan, D. Strouse, J. Wang, A. Banino, and F. Hill. Semantic exploration from language abstractions and pretrained representations.Advances in neural information processing systems, 35:25377–25389, 2022
2022
-
[72]
Y . Du, O. Watkins, Z. Wang, C. Colas, T. Darrell, P. Abbeel, A. Gupta, and J. Andreas. Guiding pre- training in reinforcement learning with large language models. InInternational Conference on Machine Learning, pages 8657–8677. PMLR, 2023
2023
-
[73]
Carta, P.-Y
T. Carta, P.-Y . Oudeyer, O. Sigaud, and S. Lamprier. Eager: Asking and answering questions for automatic reward shaping in language-guided rl.Advances in neural information processing systems, 35:12478–12490, 2022
2022
-
[74]
Using Natural Language for Reward Shaping in Reinforcement Learning
P. Goyal, S. Niekum, and R. J. Mooney. Using natural language for reward shaping in reinforcement learning.arXiv preprint arXiv:1903.02020, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[75]
A. Peng, I. Sucholutsky, B. Li, T. Sumers, T. L. Griffiths, J. Andreas, and J. Shah. Learning with language-guided state abstractions. InInternational Conference on Learning Representations, volume 2024, pages 38711–38744, 2024
2024
-
[76]
Branavan, D
S. Branavan, D. Silver, and R. Barzilay. Learning to win by reading manuals in a monte-carlo frame- work.Journal of Artificial Intelligence Research, 43:661–704, 2012
2012
-
[77]
K. M. Hermann, F. Hill, S. Green, F. Wang, R. Faulkner, H. Soyer, D. Szepesvari, W. M. Czarnecki, M. Jaderberg, D. Teplyashin, et al. Grounded language learning in a simulated 3d world.arXiv preprint arXiv:1706.06551, 2017. 14
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[78]
Misra, J
D. Misra, J. Langford, and Y . Artzi. Mapping instructions and visual observations to actions with rein- forcement learning. InProceedings of the 2017 conference on empirical methods in natural language processing, pages 1004–1015, 2017
2017
-
[79]
Narasimhan, R
K. Narasimhan, R. Barzilay, and T. Jaakkola. Grounding language for transfer in deep reinforcement learning.Journal of Artificial Intelligence Research, 63:849–874, 2018
2018
-
[80]
A. G. Barto. Reinforcement learning: An introduction. by richard’s sutton.SIAM Rev, 6(2):423, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.