MindEdit-Bench: Benchmarking Object-Level Counterfactual Spatial Reasoning in VLMs from In-the-Wild Photos
Pith reviewed 2026-07-02 14:58 UTC · model grok-4.3
The pith
Vision-language models reach only 8-31% accuracy on tasks requiring them to predict the effects of moving or rotating objects in real indoor photos, while humans reach 81-97%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
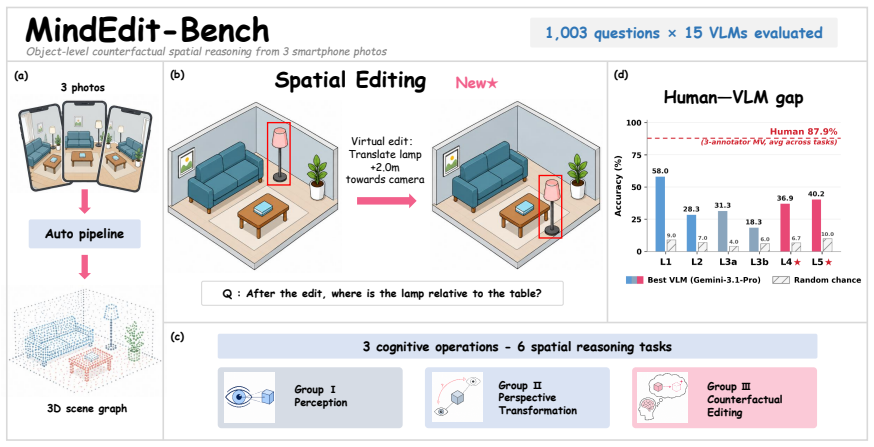
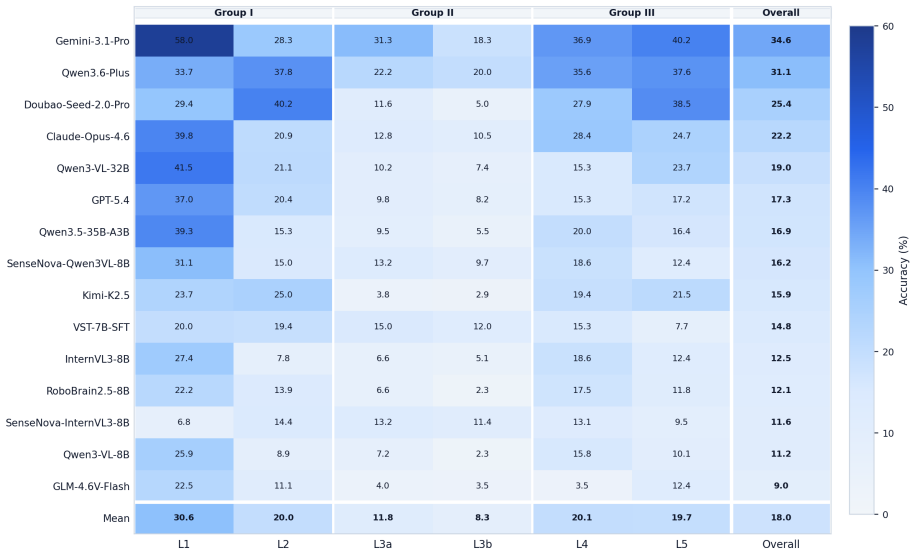
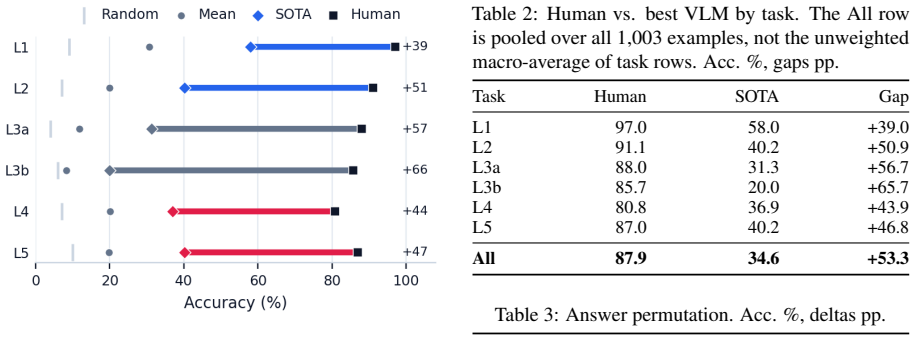
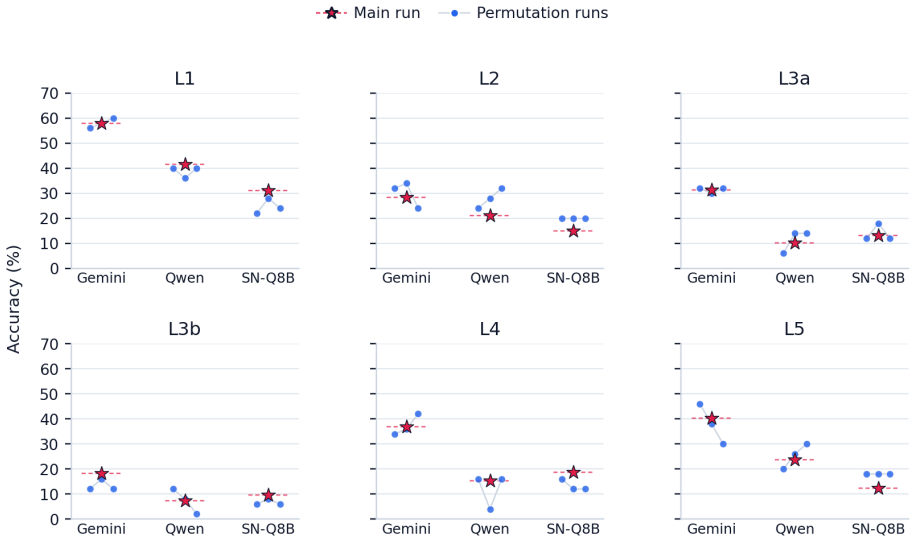
MindEdit-Bench shows that current VLMs lack reliable object-level counterfactual spatial reasoning: on L4 spatial-editing and L5 cross-view visibility-editing questions the correct answers are absent from all input images, yet models achieve only single-digit to low-thirty percent accuracy while human majority votes reach 81-97 percent, with the structured answer format exposing uneven failures such as weaker inference along the camera depth axis.
What carries the argument
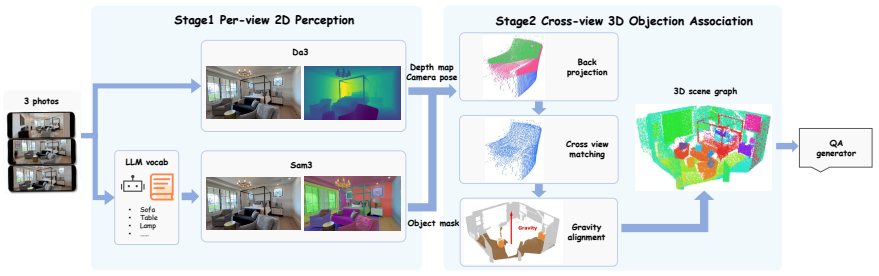
MindEdit-Bench, built from three-photo smartphone triplets via automatic 3D scene-graph extraction, supplies the six tasks and 8-24 structured answer choices that let the evaluation isolate spatial versus fallback errors on counterfactual object edits.
If this is right
- VLMs exhibit non-uniform spatial weaknesses, including poorer performance on depth-axis inferences and fallback errors on visibility-editing cases.
- The 53-point human-best-VLM gap holds across all six tasks and persists after controlling for public-data overlap by using private indoor scenes.
- Structured multiple-choice format with 8-24 options enables per-question diagnosis of whether models fail on perspective transformation, object permanence, or simple pattern matching.
- Four perception tasks already show large gaps, indicating that even non-counterfactual spatial reasoning remains unreliable before counterfactual demands are added.
Where Pith is reading between the lines
- Training regimes that rely only on observational image-text pairs may be insufficient to produce robust counterfactual object reasoning.
- Robotics or augmented-reality systems that must simulate object rearrangements would need additional 3D simulation or explicit spatial modules beyond current VLMs.
- Extending the benchmark to outdoor scenes or video sequences could test whether the observed gaps generalize beyond controlled indoor triplets.
Load-bearing premise
The automatic 3D scene-graph pipeline produces accurate ground-truth labels and counterfactual answers for the editing tasks without systematic artifacts that would inflate the human-VLM gap.
What would settle it
A manual re-annotation of the L4 and L5 questions by multiple humans that yields VLM accuracies above 60 percent on the same items would falsify the reported capability gap.
Figures


read the original abstract
Benchmarks for vision-language models (VLMs) mostly test observational spatial reasoning: models describe relations already visible in the input. Existing what-if tasks typically vary the observer while keeping the scene fixed. Can VLMs instead predict the consequences of hypothetically moving or rotating an object? We introduce MindEdit-Bench, a benchmark of six spatial reasoning tasks built from three-photo smartphone triplets of newly captured indoor scenes via an automatic in-the-wild 3D scene-graph extraction pipeline. Four tasks probe perception and perspective transformation over observed structure; two new tasks, L4 (spatial editing) and L5 (cross-view visibility editing), probe object-level counterfactual reasoning, where correct answers are absent from all input images. Each question provides 8-24 structured answer choices, enabling answer-letter-level diagnosis of spatial and fallback errors. The benchmark covers 120 private indoor scenes not drawn from public datasets, reducing public-data pretraining-overlap risk. Across 15 VLMs on 1,003 human-verified questions, task-wise mean VLM accuracy is only 8%-31%, versus 81%-97% human majority-vote accuracy. The pooled human--best-VLM gap is 53 pp, with at least 39 pp on every task. The structured answer space further reveals non-uniform failures, including weaker camera-depth-axis inference and fallback behavior on difficult visibility-editing cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MindEdit-Bench, a benchmark of six spatial reasoning tasks constructed from three-photo smartphone triplets of 120 private indoor scenes using an automatic in-the-wild 3D scene-graph extraction pipeline. Four tasks address perception and perspective transformation on observed structure; L4 (spatial editing) and L5 (cross-view visibility editing) require object-level counterfactual reasoning where correct answers are absent from all input images. Each question offers 8-24 structured answer choices. On 1,003 human-verified questions, 15 VLMs achieve task-wise mean accuracies of 8%-31% versus 81%-97% for human majority votes, yielding a pooled gap of 53 pp (at least 39 pp per task). The structured answers enable diagnosis of specific spatial and fallback errors.
Significance. If the 3D pipeline produces reliable counterfactual ground truth, the benchmark would establish a clear, large gap between human and VLM performance on object-level counterfactual spatial reasoning from in-the-wild photos. Strengths include the use of private scenes to limit pretraining overlap, the multi-choice format for fine-grained error analysis, and the focus on editing tasks absent from prior observational benchmarks. Such a result would be relevant for robotics, AR, and planning applications where models must simulate hypothetical object manipulations.
major comments (1)
- [Methods (automatic in-the-wild 3D scene-graph extraction pipeline description)] The central claim that VLMs exhibit 39-53 pp gaps on L4/L5 counterfactual tasks rests on the accuracy of the automatic 3D scene-graph extraction pipeline for inferring object poses, depths, cross-view visibilities, and generating ground-truth answers absent from input photos. No quantitative validation (reconstruction error, human agreement on generated counterfactual labels, or error analysis restricted to L4/L5) is reported, so it is impossible to rule out systematic artifacts from camera calibration, occlusion handling, or 3D lifting that would inflate the reported human-VLM gap.
minor comments (2)
- [Abstract] The abstract reports 'task-wise mean VLM accuracy is only 8%-31%' without referencing the specific table or figure that breaks this down per task and per model; adding that pointer would improve traceability.
- [Abstract] The human verification process for the 1,003 questions is mentioned but the number of annotators per question and the exact majority-vote threshold are not stated in the abstract; these details belong in the main text or a methods subsection.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the 3D scene-graph extraction pipeline. We address the major comment below and commit to revisions that strengthen the manuscript's claims.
read point-by-point responses
-
Referee: The central claim that VLMs exhibit 39-53 pp gaps on L4/L5 counterfactual tasks rests on the accuracy of the automatic 3D scene-graph extraction pipeline for inferring object poses, depths, cross-view visibilities, and generating ground-truth answers absent from input photos. No quantitative validation (reconstruction error, human agreement on generated counterfactual labels, or error analysis restricted to L4/L5) is reported, so it is impossible to rule out systematic artifacts from camera calibration, occlusion handling, or 3D lifting that would inflate the reported human-VLM gap.
Authors: We agree this is a substantive limitation. The manuscript does not report quantitative metrics such as reconstruction error, human agreement rates on the generated counterfactual labels for L4/L5, or a dedicated error analysis of the pipeline outputs. While all 1,003 questions received human verification to confirm the final question-answer pairs, this does not directly quantify pipeline accuracy on object poses, depths, or cross-view visibilities. To address the concern, we will add a new subsection in the Methods and an appendix with (1) human agreement statistics on a random sample of 200 L4/L5 ground-truth labels, (2) qualitative error analysis of pipeline failures on occluded or depth-ambiguous cases, and (3) discussion of how such errors could affect the reported gaps. These additions will allow readers to assess whether systematic artifacts are present. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct accuracy measurements
full rationale
The paper introduces MindEdit-Bench as an empirical evaluation of VLMs on spatial reasoning tasks using human-verified questions from in-the-wild scenes. No derivations, equations, fitted parameters, or predictions are claimed that reduce to the authors' own inputs or prior self-citations. Task accuracies are computed directly from model outputs against ground-truth labels and human majority votes, with no self-definitional loops, fitted-input predictions, or load-bearing uniqueness theorems. The automatic 3D pipeline is an implementation detail whose accuracy is an external validity concern, not a circular reduction within the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brian and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei , booktitle =
-
[2]
Cheng, An-Chieh and Yin, Hongxu and Fu, Yang and Guo, Qiushan and Yang, Ruihan and Kautz, Jan and Wang, Xiaolong and Liu, Sifei , booktitle =
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[10]
Ma, Xiaojian and Yong, Silong and Zheng, Zilong and Li, Qing and Liang, Yitao and Zhu, Song-Chun and Huang, Siyuan , booktitle =
-
[14]
Science , volume =
Mental Rotation of Three-Dimensional Objects , author =. Science , volume =
-
[15]
1983 , publisher =
Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness , author =. 1983 , publisher =
1983
-
[16]
European Conference on Spatial Information Theory (COSIT) , pages =
Cognitive Maps, Cognitive Collages, and Spatial Mental Models , author =. European Conference on Spatial Information Theory (COSIT) , pages =
-
[17]
Trends in Cognitive Sciences , volume =
Mechanical Reasoning by Mental Simulation , author =. Trends in Cognitive Sciences , volume =
-
[18]
Proceedings of the National Academy of Sciences (PNAS) , volume =
Simulation as an Engine of Physical Scene Understanding , author =. Proceedings of the National Academy of Sciences (PNAS) , volume =
-
[19]
Trends in Cognitive Sciences , volume =
Counterfactual Simulation in Causal Cognition , author =. Trends in Cognitive Sciences , volume =. 2024 , doi =
2024
-
[20]
and Savva, Manolis and Halber, Maciej and Funkhouser, Thomas and Nie
Dai, Angela and Chang, Angel X. and Savva, Manolis and Halber, Maciej and Funkhouser, Thomas and Nie. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[23]
2026 , url =
System Card:. 2026 , url =
2026
-
[30]
Anthropic . 2026. https://www.anthropic.com/system-cards/ System card: Claude Opus 4.6 . Technical report, Anthropic
2026
-
[31]
Battaglia, Jessica B
Peter W. Battaglia, Jessica B. Hamrick, and Joshua B. Tenenbaum. 2013. Simulation as an engine of physical scene understanding. Proceedings of the National Academy of Sciences (PNAS), 110(45):18327--18332
2013
-
[32]
ByteDance Seed . 2026. https://seed.bytedance.com/en/seed2 Seed2.0 model card
2026
-
[33]
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, Tongxi Zhou, Jiaqi Li, Hui En Pang, Oscar Qian, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoyang Han, and 10 others. 2025 a . https://doi.org/10.48550/arXiv.2511.13719 Scaling spatial intelligence with multimodal foundation mod...
-
[34]
Zhongang Cai, Yubo Wang, Qingping Sun, Ruisi Wang, Chenyang Gu, Wanqi Yin, Zhiqian Lin, Zhitao Yang, Chen Wei, Oscar Qian, Hui En Pang, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen, Jiaqi Li, Xiangyu Fan, Hanming Deng, Lewei Lu, and 5 others. 2025 b . https://doi.org/10.48550/arXiv.2508.13142 Holistic evaluation of multimodal LLM s on spatial intelli...
-
[35]
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R \"a dle, and 19 others. 2025. https://doi.org/10.48550/arXiv.2511.16719 SAM 3: Segment anythi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.16719 2025
-
[36]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. SpatialVLM : Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[37]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. SpatialRGPT : Grounded spatial reasoning in vision language models. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[38]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nie ner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nie ner. 2017. ScanNet : Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[39]
Yuanyuan Gao, Hao Li, Yifei Liu, Xinhao Ji, Yuning Gong, Yuanjun Liao, Fangfu Liu, Manyuan Zhang, Yuchen Yang, Dan Xu, Xue Yang, Huaxi Huang, Hongjie Zhang, Ziwei Liu, Xiao Sun, Dingwen Zhang, and Zhihang Zhong. 2026. https://doi.org/10.48550/arXiv.2603.07660 Holi-Spatial : Evolving video streams into holistic 3d spatial intelligence . arXiv preprint arXi...
-
[40]
Tobias Gerstenberg. 2024. https://doi.org/10.1016/j.tics.2024.04.012 Counterfactual simulation in causal cognition . Trends in Cognitive Sciences, 28(10):924--936
-
[41]
Google DeepMind . 2026. https://deepmind.google/models/model-cards/gemini-3-1-pro Gemini 3.1 Pro model card . Technical report, Google DeepMind
2026
-
[42]
Mary Hegarty. 2004. Mechanical reasoning by mental simulation. Trends in Cognitive Sciences, 8(6):280--285
2004
-
[43]
Johnson-Laird
Philip N. Johnson-Laird. 1983. Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press
1983
-
[44]
Kimi Team . 2026. https://doi.org/10.48550/arXiv.2602.02276 Kimi K2.5 : Visual agentic intelligence . arXiv preprint arXiv:2602.02276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02276 2026
-
[45]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, Weiming Lu, and Yueting Zhuang. 2025. https://doi.org/10.48550/arXiv.2505.21500 ViewSpatial-Bench : Evaluating multi-perspective spatial localization in vision-language models . arXiv preprint arXiv:2505.21500
-
[46]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. 2025. https://doi.org/10.48550/arXiv.2511.10647 Depth anything 3: Recovering the visual space from any views . arXiv preprint arXiv:2511.10647
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.10647 2025
-
[47]
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. 2023. SQA3D : Situated question answering in 3d scenes. In International Conference on Learning Representations (ICLR)
2023
-
[48]
OpenAI . 2026. https://openai.com/index/gpt-5-4-thinking-system-card/ GPT-5.4 thinking system card
2026
-
[49]
Qwen Team . 2026 a . https://huggingface.co/Qwen/Qwen3.5-35B-A3B Qwen3.5-35B-A3B model card
2026
-
[50]
Qwen Team . 2026 b . https://qwen.ai/blog?id=qwen3.6 Qwen3.6-Plus : Towards real world agents
2026
-
[51]
Qwen Team, Alibaba . 2025. https://doi.org/10.48550/arXiv.2511.21631 Qwen3-VL technical report . arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[52]
Shepard and Jacqueline Metzler
Roger N. Shepard and Jacqueline Metzler. 1971. Mental rotation of three-dimensional objects. Science, 171(3972):701--703
1971
-
[53]
Huajie Tan, Enshen Zhou, Zhiyu Li, Yijie Xu, Yuheng Ji, Xiansheng Chen, Cheng Chi, Pengwei Wang, Huizhu Jia, Yulong Ao, Mingyu Cao, Sixiang Chen, Zhe Li, Mengzhen Liu, Zixiao Wang, Shanyu Rong, Yaoxu Lyu, Zhongxia Zhao, Peterson Co, and 16 others. 2026. https://doi.org/10.48550/arXiv.2601.14352 RoboBrain 2.5 : Depth in sight, time in mind . arXiv preprint...
-
[54]
Barbara Tversky. 1993. Cognitive maps, cognitive collages, and spatial mental models. In European Conference on Spatial Information Theory (COSIT), pages 14--24
1993
-
[55]
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. 2024. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[56]
Qineng Wang, Baiqiao Yin, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Jiajun Wu, Li Fei-Fei, and Manling Li. 2025. https://doi.org/10.48550/arXiv.2506.21458 MindCube : Spatial mental modeling from limited views . arXiv preprint arXiv:2506.21458
-
[57]
Haoning Wu, Xiao Huang, Yaohui Chen, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2025. https://doi.org/10.48550/arXiv.2505.17012 SpatialScore : Towards comprehensive evaluation for spatial intelligence . arXiv preprint arXiv:2505.17012
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.17012 2025
-
[58]
Yicheng Xiao, Wenhu Zhang, Lin Song, Yukang Chen, Wenbo Li, Nan Jiang, Tianhe Ren, Haokun Lin, Wei Huang, Haoyang Huang, Xiu Li, Nan Duan, and Xiaojuan Qi. 2026. https://doi.org/10.48550/arXiv.2604.04911 SpatialEdit : Benchmarking fine-grained image spatial editing . arXiv preprint arXiv:2604.04911
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04911 2026
-
[59]
Yuxi Xiao, Longfei Li, Shen Yan, Xinhang Liu, Sida Peng, Yunchao Wei, Xiaowei Zhou, and Bingyi Kang. 2025. https://doi.org/10.48550/arXiv.2512.20617 SpatialTree : How spatial abilities branch out in MLLM s . arXiv preprint arXiv:2512.20617
-
[60]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025 a . https://openaccess.thecvf.com/content/CVPR2025/html/Yang_Thinking_in_Space_How_Multimodal_Large_Language_Models_See_Remember_CVPR_2025_paper.html Thinking in space: How multimodal large language models see, remember, and recall spaces . In Proceedings of the IEEE/...
2025
-
[61]
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, Yi Lin, and Hengshuang Zhao. 2025 b . https://doi.org/10.48550/arXiv.2511.05491 Visual spatial tuning . arXiv preprint arXiv:2511.05491
-
[62]
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. 2025 c . https://doi.org/10.48550/arXiv.2505.23764 MMSI-Bench : A benchmark for multi-image spatial intelligence . arXiv preprint arXiv:2505.23764
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.23764 2025
-
[63]
Z.ai . 2025. https://huggingface.co/zai-org/GLM-4.6V-Flash GLM-4.6V-Flash model card
2025
-
[64]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, and 32 others. 2025. https://doi.org/10.48550/arXiv.2504.10479 InternVL3 : Exploring advanced training and test-time recipes f...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.10479 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.