Restore3D: Breathing Life into Broken Objects with Shape and Texture Restoration
Pith reviewed 2026-07-02 14:39 UTC · model grok-4.3
The pith
Restore3D restores both shape and texture of broken 3D objects from multi-view images using a mask self-perceiver and data synthesis pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
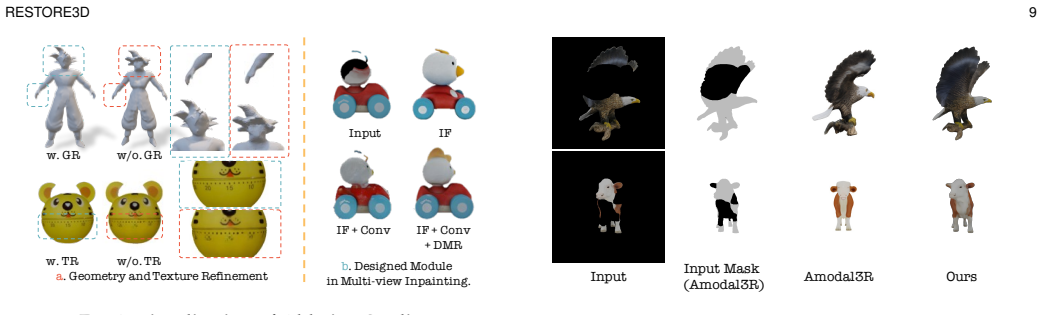
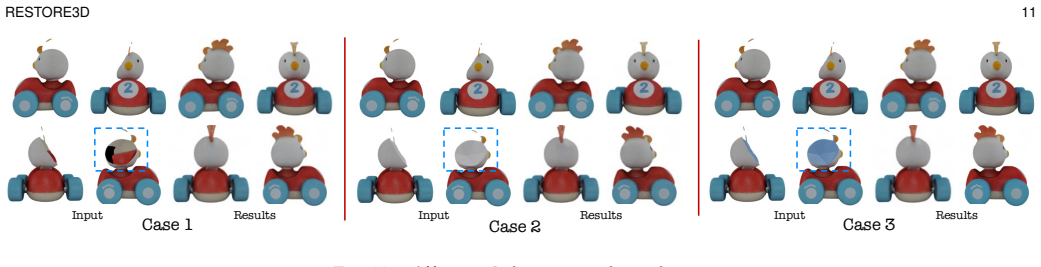
Restore3D is a framework that simultaneously restores shape and texture of broken objects from multi-view images. An automated pipeline synthesizes paired incomplete-complete samples from large-scale 3D datasets to overcome limited training data. Its multi-view model uses a Mask Self-Perceiver module with a Depth-Aware Mask Rectifier whose learned rectified masks guide image integration and enhancement, retaining observed shape and texture while refining generated areas and overcoming low-resolution limits of the base model. Refined multi-view images then support a coarse-to-fine reconstruction that recovers detailed textured 3D meshes, producing higher-quality results than representative ba
What carries the argument
Mask Self-Perceiver module with Depth-Aware Mask Rectifier that learns rectified masks to guide image integration and enhancement while retaining observed patterns.
If this is right
- Higher-quality multi-view restoration on both synthetic and real broken-object benchmarks.
- Improved textured-mesh reconstruction compared with inpainting, completion, and reconstruction baselines.
- Better handling of relatively complex and diverse objects.
- Direct applicability to cultural heritage preservation, occluded object reconstruction, and artistic design.
Where Pith is reading between the lines
- The data synthesis pipeline could be adapted for other 3D modalities such as point clouds if similar paired data can be generated.
- Adding temporal consistency terms might allow extension to video or dynamic scene restoration.
- The mask rectifier could be tested as a plug-in module inside existing multi-view diffusion models for broader use.
- Fine-tuning on domain-specific real broken-object photographs might further close the synthetic-to-real gap.
Load-bearing premise
The automated data generation pipeline that synthesizes paired incomplete-complete samples from large-scale 3D datasets produces training data whose distribution matches real-world broken objects sufficiently for the model to generalize.
What would settle it
Apply Restore3D and the baselines to a collection of real broken objects that have known complete ground-truth versions, then check whether restoration quality and mesh accuracy metrics show no improvement.
Figures

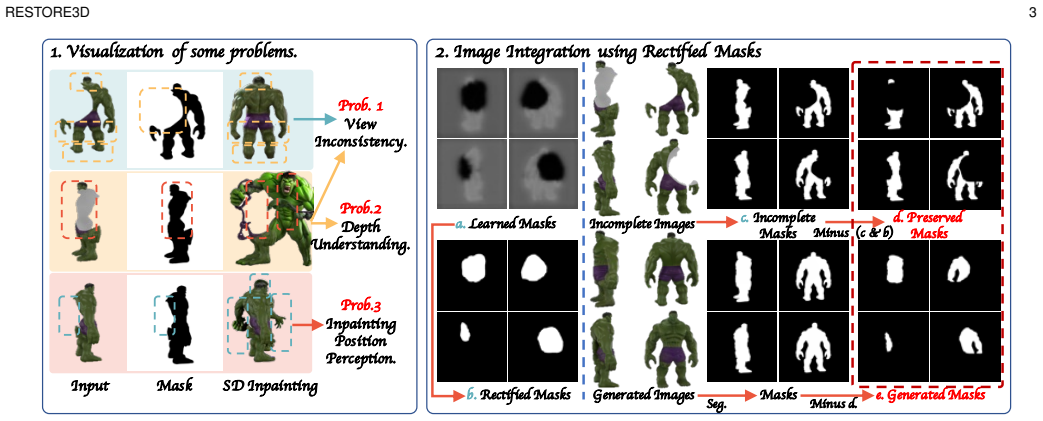
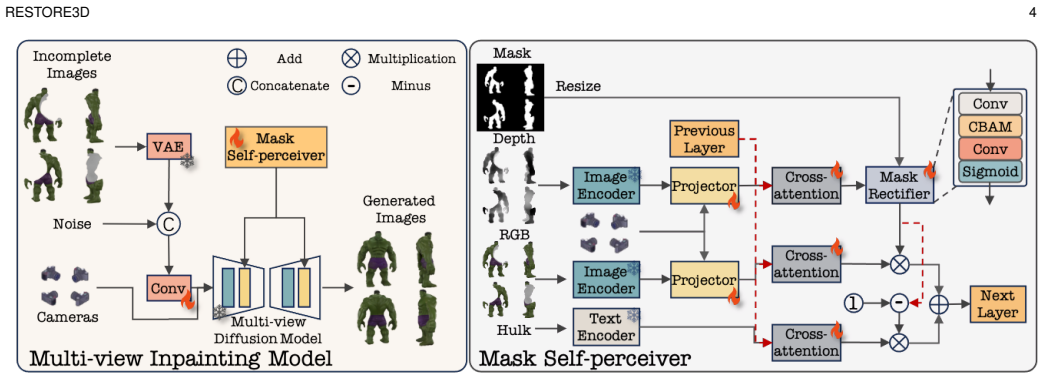
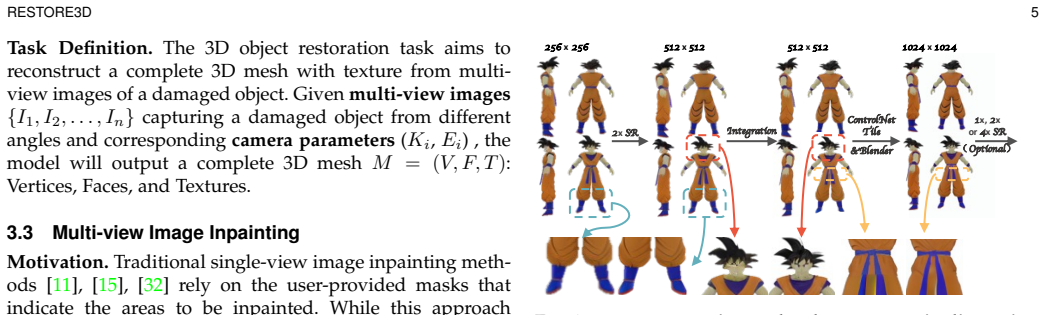
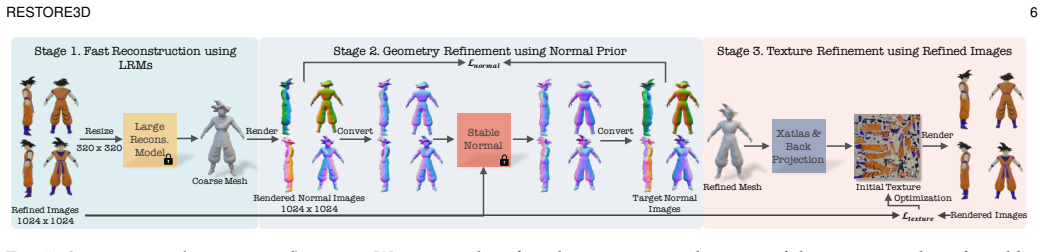





read the original abstract
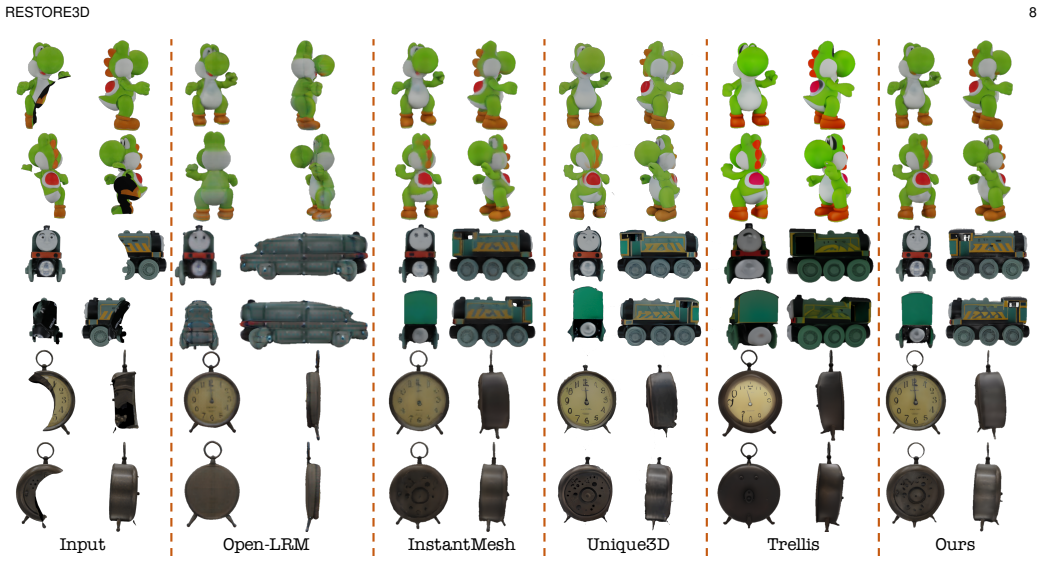
Restoring incomplete or damaged 3D objects is crucial for cultural heritage preservation, occluded object reconstruction, and artistic design. Existing methods primarily focus on geometric completion, often neglecting texture restoration and struggling with relatively complex and diverse objects. We introduce Restore3D, a novel framework that simultaneously restores both the shape and texture of broken objects using multi-view images. To address limited training data, we develop an automated data generation pipeline that synthesizes paired incomplete-complete samples from large-scale 3D datasets. Central to Restore3D is a multi-view model, enhanced by a carefully designed Mask Self-Perceiver module with a Depth-Aware Mask Rectifier. The rectified masks learned by the self-perceiver guide an image integration and enhancement phase, helping retain observed shape and texture patterns while refining the generated regions and mitigating the low-resolution limitations of the base model, yielding high-resolution, semantically coherent, and view-consistent multi-view images. A coarse-to-fine reconstruction strategy is then employed to recover detailed textured 3D meshes from refined multi-view images. Experiments on synthetic and real broken-object benchmarks show that Restore3D improves multi-view restoration quality and textured-mesh reconstruction over representative inpainting, completion, and reconstruction baselines in the evaluated settings. Project Page: restore3dx.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Restore3D, a novel framework for simultaneous shape and texture restoration of broken 3D objects using multi-view images. It addresses data scarcity with an automated pipeline generating paired incomplete-complete samples from large-scale 3D datasets. The core is a multi-view model with a Mask Self-Perceiver module incorporating a Depth-Aware Mask Rectifier to guide image integration and enhancement for high-resolution, consistent outputs. A coarse-to-fine reconstruction then produces detailed textured meshes. The paper claims superior performance over inpainting, completion, and reconstruction baselines on both synthetic and real broken-object benchmarks.
Significance. If the experimental results are robust, Restore3D could have significant impact in fields requiring 3D object restoration, such as cultural heritage preservation and occluded reconstruction. The approach of jointly handling shape and texture via multi-view consistency is a strength. The automated synthetic data pipeline is a valuable contribution for training such models. The design of the Mask Self-Perceiver and Depth-Aware Mask Rectifier offers a specific mechanism for retaining observed patterns while refining generated regions. These elements, if validated, position the work as an advance over separate inpainting and completion methods.
major comments (2)
- Abstract: The abstract states that Restore3D 'improves multi-view restoration quality and textured-mesh reconstruction over representative ... baselines in the evaluated settings' but provides no quantitative metrics, specific numbers, error analysis, or dataset details. This absence makes it difficult to evaluate the magnitude of the claimed improvements, which is load-bearing for the central experimental claim.
- Data generation pipeline (methods section): The generalization to real broken-object benchmarks depends on the automated synthetic data pipeline producing break geometries, surface statistics, and texture discontinuities that match real-world distributions. No quantitative validation, such as distribution distances or ablations comparing real vs. synthetic break realism, is mentioned. This is the weakest link in the argument from training to real-benchmark results.
minor comments (2)
- Abstract: The project page URL is given but could be formatted as a hyperlink for accessibility.
- Throughout: Some module names like 'Mask Self-Perceiver' and 'Depth-Aware Mask Rectifier' could benefit from a dedicated notation table or figure for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the presentation of results and the justification for our data pipeline. We address each major comment below.
read point-by-point responses
-
Referee: Abstract: The abstract states that Restore3D 'improves multi-view restoration quality and textured-mesh reconstruction over representative ... baselines in the evaluated settings' but provides no quantitative metrics, specific numbers, error analysis, or dataset details. This absence makes it difficult to evaluate the magnitude of the claimed improvements, which is load-bearing for the central experimental claim.
Authors: We agree that the abstract would benefit from quantitative support. In the revised version we will insert concise numerical results (e.g., average PSNR/SSIM gains on the synthetic benchmark and Chamfer-distance reductions on mesh reconstruction) together with the names of the primary datasets used, while remaining within the word limit. revision: yes
-
Referee: Data generation pipeline (methods section): The generalization to real broken-object benchmarks depends on the automated synthetic data pipeline producing break geometries, surface statistics, and texture discontinuities that match real-world distributions. No quantitative validation, such as distribution distances or ablations comparing real vs. synthetic break realism, is mentioned. This is the weakest link in the argument from training to real-benchmark results.
Authors: We acknowledge that explicit distributional comparisons (e.g., Wasserstein distances on break geometry or texture statistics) between synthetic and real breaks are not reported. The pipeline follows physically motivated fracture rules drawn from prior graphics literature, and the competitive results on the real broken-object benchmark provide indirect evidence of transfer. We will expand the methods section with additional qualitative examples and a brief discussion of the design assumptions; a full statistical validation would require new experiments that lie outside the present study. revision: partial
Circularity Check
No circularity: experimental claims rest on external benchmarks, not self-referential fits or derivations.
full rationale
The paper presents a new framework (Restore3D) with an automated synthetic data pipeline and a multi-view restoration architecture (Mask Self-Perceiver + Depth-Aware Mask Rectifier + coarse-to-fine reconstruction). All load-bearing claims are validated via comparative experiments on synthetic and real benchmarks against external baselines. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes are present in the provided text. The synthetic-to-real transfer is an empirical assumption, not a definitional reduction. This is the standard non-circular case for a methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sdfusion: Multimodal 3d shape completion, reconstruction, and generation,
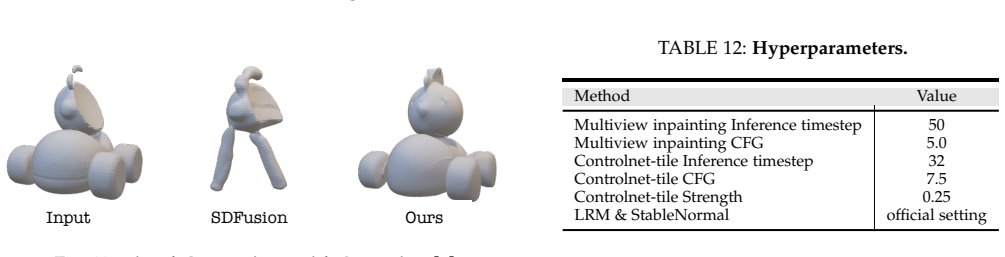
Y.-C. Cheng, H.-Y. Lee, S. Tulyakov, A. G. Schwing, and L.-Y. Gui, “Sdfusion: Multimodal 3d shape completion, reconstruction, and generation,” inCVPR, 2023
2023
-
[2]
DreamFusion: Text-to-3D using 2D Diffusion
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text-to-3d using 2d diffusion,”arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Magic3d: High- resolution text-to-3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y. Liu, and T.-Y. Lin, “Magic3d: High- resolution text-to-3d content creation,” inCVPR, 2023
2023
-
[4]
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model,
J. Li, H. Tan, K. Zhang, Z. Xu, F. Luan, Y. Xu, Y. Hong, K. Sunkavalli, G. Shakhnarovich, and S. Bi, “Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model,” 2023
2023
-
[5]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” 2024
2024
-
[6]
Shape completion using 3d-encoder-predictor cnns and shape synthesis,
A. Dai, C. Ruizhongtai Qi, and M. Nießner, “Shape completion using 3d-encoder-predictor cnns and shape synthesis,” inProceed- ings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5868–5877
2017
-
[7]
Patchcomplete: Learning multi- resolution patch priors for 3d shape completion on unseen cat- egories,
Y. Rao, Y. Nie, and A. Dai, “Patchcomplete: Learning multi- resolution patch priors for 3d shape completion on unseen cat- egories,” 2022
2022
-
[8]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P . Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “Shapenet: An information-rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
LRM: Large Reconstruction Model for Single Image to 3D
Y. Hong, K. Zhang, J. Gu, S. Bi, Y. Zhou, D. Liu, F. Liu, K. Sunkavalli, T. Bui, and H. Tan, “Lrm: Large reconstruction model for single image to 3d,”arXiv preprint arXiv:2311.04400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
MVDream: Multi-view Diffusion for 3D Generation
Y. Shi, P . Wang, J. Ye, M. Long, K. Li, and X. Yang, “Mv- dream: Multi-view diffusion for 3d generation,”arXiv preprint arXiv:2308.16512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” 2022
2022
-
[12]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . Vo, M. Szafraniec, V . Khalidov, P . Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P .-Y. Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P . Labatut, A. Joulin, and P . Bojanowski, “Dinov2: Learning robust visual features withou...
2023
-
[13]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P . Doll ´ar, and R. Gir- shick, “Segment anything,”arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”arXiv:2406.09414, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” 2023
2023
-
[16]
Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang, “Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” 2023
2023
-
[17]
C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi, Y. Shan, and X. Qie, “T2i-adapter: Learning adapters to dig out more control- RESTORE3D 13 lable ability for text-to-image diffusion models,”arXiv preprint arXiv:2302.08453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Zero-1-to-3: Zero-shot one image to 3d object,
R. Liu, R. Wu, B. Van Hoorick, P . Tokmakov, S. Zakharov, and C. Vondrick, “Zero-1-to-3: Zero-shot one image to 3d object,” in ICCV, 2023
2023
-
[19]
J. Xu, W. Cheng, Y. Gao, X. Wang, S. Gao, and Y. Shan, “In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models,”arXiv preprint arXiv:2404.07191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Rethinking inductive biases for surface normal estimation,
G. Bae and A. J. Davison, “Rethinking inductive biases for surface normal estimation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[21]
Stablenormal: Reducing diffusion variance for stable and sharp normal,
C. Ye, L. Qiu, X. Gu, Q. Zuo, Y. Wu, Z. Dong, L. Bo, Y. Xiu, and X. Han, “Stablenormal: Reducing diffusion variance for stable and sharp normal,”ACM Transactions on Graphics (TOG), 2024
2024
-
[22]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. Van- derBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inCVPR, 2023
2023
-
[23]
Google scanned objects: A high-quality dataset of 3d scanned household items,
L. Downs, A. Francis, N. Koenig, B. Kinman, R. Hickman, K. Reymann, T. B. McHugh, and V . Vanhoucke, “Google scanned objects: A high-quality dataset of 3d scanned household items,”
-
[24]
Available: https://arxiv.org/abs/2204.11918
[Online]. Available: https://arxiv.org/abs/2204.11918
-
[25]
Breaking bad: A dataset for geometric fracture and reassembly,
S. Sell ´an, Y.-C. Chen, Z. Wu, A. Garg, and A. Jacobson, “Breaking bad: A dataset for geometric fracture and reassembly,” 2022. [Online]. Available: https://arxiv.org/abs/2210.11463
-
[26]
Fantastic breaks: A dataset of paired 3d scans of real-world broken objects and their complete counterparts,
N. Lamb, C. Palmer, B. Molloy, S. Banerjee, and N. K. Banerjee, “Fantastic breaks: A dataset of paired 3d scans of real-world broken objects and their complete counterparts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 4681–4691
2023
-
[27]
Omniobject3d: Large- vocabulary 3d object dataset for realistic perception, reconstruc- tion and generation,
T. Wu, J. Zhang, X. Fu, Y. Wang, L. P . Jiawei Ren, W. Wu, L. Yang, J. Wang, C. Qian, D. Lin, and Z. Liu, “Omniobject3d: Large- vocabulary 3d object dataset for realistic perception, reconstruc- tion and generation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[28]
Repaint: Inpainting using denoising diffusion probabilistic models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. V . Gool, “Repaint: Inpainting using denoising diffusion probabilistic models,” 2022. [Online]. Available: https://arxiv.org/abs/2201. 09865
2022
-
[29]
Nerfiller: Completing scenes via generative 3d inpainting,
E. Weber, A. Holynski, V . Jampani, S. Saxena, N. Snavely, A. Kar, and A. Kanazawa, “Nerfiller: Completing scenes via generative 3d inpainting,” inCVPR, 2024
2024
-
[30]
Instant3dit: Multiview inpainting for fast editing of 3d objects,
A. Barda, M. Gadelha, V . G. Kim, N. Aigerman, A. H. Bermano, and T. Groueix, “Instant3dit: Multiview inpainting for fast editing of 3d objects,” 2025
2025
-
[31]
Openlrm: Open-source large reconstruction models,
Z. He and T. Wang, “Openlrm: Open-source large reconstruction models,” https://github.com/3DTopia/OpenLRM, 2023
2023
-
[32]
Structured 3D Latents for Scalable and Versatile 3D Generation
J. Xiang, Z. Lv, S. Xu, Y. Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang, “Structured 3d latents for scalable and versatile 3d generation,”arXiv preprint arXiv:2412.01506, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V . Lem- pitsky, “Resolution-robust large mask inpainting with fourier con- volutions,”arXiv preprint arXiv:2109.07161, 2021
-
[34]
SPIn-NeRF: Multiview segmentation and perceptual inpainting with neural radiance fields,
A. Mirzaei, T. Aumentado-Armstrong, K. G. Derpanis, J. Kelly, M. A. Brubaker, I. Gilitschenski, and A. Levinshtein, “SPIn-NeRF: Multiview segmentation and perceptual inpainting with neural radiance fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[35]
MVIP-NeRF: Multi-view 3d inpainting on nerf scenes via diffusion prior,
H. Chen, C. C. Loy, and X. Pan, “MVIP-NeRF: Multi-view 3d inpainting on nerf scenes via diffusion prior,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[36]
3DGIC: 3d gaussian inpainting with depth-guided cross-view consistency,
S.-Y. Huang, Z.-T. Chou, and Y.-C. F. Wang, “3DGIC: 3d gaussian inpainting with depth-guided cross-view consistency,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[37]
MVD 2: Efficient multiview 3d reconstruction for multiview diffusion,
X.-Y. Zheng, H. Pan, Y.-X. Guo, X. Tong, and Y. Liu, “MVD 2: Efficient multiview 3d reconstruction for multiview diffusion,” in ACM SIGGRAPH 2024 Conference Papers, 2024
2024
-
[38]
3denhancer: Consistent multi-view diffusion for 3d enhancement,
Y. Luo, S. Zhou, Y. Lan, X. Pan, and C. C. Loy, “3denhancer: Consistent multi-view diffusion for 3d enhancement,” 2025. [Online]. Available: https://arxiv.org/abs/2412.18565
-
[39]
Sharp- It: A multi-view to multi-view diffusion model for 3d synthesis and manipulation,
Y. Edelstein, O. Patashnik, D. Cohen-Bar, and L. Wolf, “Sharp- It: A multi-view to multi-view diffusion model for 3d synthesis and manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[40]
Z. Wang, C. Lu, Y. Wang, F. Bao, C. Li, H. Su, and J. Zhu, “Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,”arXiv preprint arXiv:2305.16213, 2023
-
[41]
Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content cre- ation,
R. Chen, Y. Chen, N. Jiao, and K. Jia, “Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content cre- ation,”arXiv preprint arXiv:2303.13873, 2023
-
[42]
Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation,
H. Wang, X. Du, J. Li, R. A. Yeh, and G. Shakhnarovich, “Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation,” inCVPR, 2023
2023
-
[43]
Sparsefusion: Distilling view- conditioned diffusion for 3d reconstruction,
Z. Zhou and S. Tulsiani, “Sparsefusion: Distilling view- conditioned diffusion for 3d reconstruction,” inCVPR, 2023
2023
-
[44]
S. Tang, F. Zhang, J. Chen, P . Wang, and Y. Furukawa, “Mvd- iffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion,”arXiv preprint arXiv:2307.01097, 2023
-
[45]
Viewset diffusion:(0-) image-conditioned 3d generative models from 2d data,
S. Szymanowicz, C. Rupprecht, and A. Vedaldi, “Viewset diffusion:(0-) image-conditioned 3d generative models from 2d data,”arXiv preprint arXiv:2306.07881, 2023
-
[46]
Diffusion with for- ward models: Solving stochastic inverse problems without direct supervision,
A. Tewari, T. Yin, G. Cazenavette, S. Rezchikov, J. B. Tenenbaum, F. Durand, W. T. Freeman, and V . Sitzmann, “Diffusion with for- ward models: Solving stochastic inverse problems without direct supervision,”arXiv preprint arXiv:2306.11719, 2023
-
[47]
Dmv3d: Denoising multi-view diffusion using 3d large reconstruction model,
Y. Xu, H. Tan, F. Luan, S. Bi, P . Wang, J. Li, Z. Shi, K. Sunkavalli, G. Wetzstein, Z. Xu, and K. Zhang, “Dmv3d: Denoising multi-view diffusion using 3d large reconstruction model,” 2023
2023
-
[48]
One-2-3-45,
H. Face, “One-2-3-45,” https://huggingface.co/spaces/ One-2-3-45/One-2-3-45, 2023
2023
-
[49]
Sparseneus: Fast generalizable neural surface reconstruction from sparse views,
X. Long, C. Lin, P . Wang, T. Komura, and W. Wang, “Sparseneus: Fast generalizable neural surface reconstruction from sparse views,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 210–227
2022
-
[50]
Wonder3d: Single image to 3d using cross-domain diffusion,
X. Long, Y.-C. Guo, C. Lin, Y. Liu, Z. Dou, L. Liu, Y. Ma, S.-H. Zhang, M. Habermann, C. Theobalt, and W. Wang, “Wonder3d: Single image to 3d using cross-domain diffusion,” 2023
2023
-
[51]
Unique3d: High-quality and efficient 3d mesh generation from a single image,
K. Wu, F. Liu, Z. Cai, R. Yan, H. Wang, Y. Hu, Y. Duan, and K. Ma, “Unique3d: High-quality and efficient 3d mesh generation from a single image,” 2024
2024
-
[52]
Direct2.5: Diverse text-to-3d generation via multi-view 2.5d diffusion,
Y. Lu, J. Zhang, S. Li, T. Fang, D. McKinnon, Y. Tsin, L. Quan, X. Cao, and Y. Yao, “Direct2.5: Diverse text-to-3d generation via multi-view 2.5d diffusion,”Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[53]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
A. Nichol, H. Jun, P . Dhariwal, P . Mishkin, and M. Chen, “Point-e: A system for generating 3d point clouds from complex prompts,” arXiv preprint arXiv:2212.08751, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
Lion: Latent point diffusion models for 3d shape generation,
X. Zeng, A. Vahdat, F. Williams, Z. Gojcic, O. Litany, S. Fidler, and K. Kreis, “Lion: Latent point diffusion models for 3d shape generation,” inNeurIPS, 2022
2022
-
[55]
Diffusion probabilistic models for 3d point cloud generation,
S. Luo and W. Hu, “Diffusion probabilistic models for 3d point cloud generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2837–2845
2021
-
[56]
Meshdiffusion: Score-based generative 3d mesh model- ing,
Z. Liu, Y. Feng, M. J. Black, D. Nowrouzezahrai, L. Paull, and W. Liu, “Meshdiffusion: Score-based generative 3d mesh model- ing,” inICLR, 2023
2023
-
[57]
Get3d: A generative model of high quality 3d textured shapes learned from images,
J. Gao, T. Shen, Z. Wang, W. Chen, K. Yin, D. Li, O. Litany, Z. Gojcic, and S. Fidler, “Get3d: A generative model of high quality 3d textured shapes learned from images,”NeurIPS, 2022
2022
-
[58]
Neuralfield-ldm: Scene generation with hierarchical latent diffusion models,
S. W. Kim, B. Brown, K. Yin, K. Kreis, K. Schwarz, D. Li, R. Rombach, A. Torralba, and S. Fidler, “Neuralfield-ldm: Scene generation with hierarchical latent diffusion models,” inCVPR, 2023
2023
-
[59]
Renderdiffusion: Image diffusion for 3d reconstruction, inpainting and generation,
T. Anciukevi ˇcius, Z. Xu, M. Fisher, P . Henderson, H. Bilen, N. J. Mitra, and P . Guerrero, “Renderdiffusion: Image diffusion for 3d reconstruction, inpainting and generation,” inCVPR, 2023
2023
-
[60]
Diffrf: Rendering-guided 3d radiance field diffu- sion,
N. M ¨uller, Y. Siddiqui, L. Porzi, S. R. Bulo, P . Kontschieder, and M. Nießner, “Diffrf: Rendering-guided 3d radiance field diffu- sion,” inCVPR, 2023
2023
-
[61]
Shap-e: Generating conditional 3d implicit functions,
H. Jun and A. Nichol, “Shap-e: Generating conditional 3d implicit functions,” 2023
2023
-
[62]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,
B. Zhang, J. Tang, M. Niessner, and P . Wonka, “3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,” inSIGGRAPH, 2023
2023
-
[63]
Hyperdiffusion: Generating implicit neural fields with weight-space diffusion,
Z. Erkoc ¸, F. Ma, Q. Shan, M. Nießner, and A. Dai, “Hyperdiffusion: Generating implicit neural fields with weight-space diffusion,” arXiv preprint arXiv:2303.17015, 2023. RESTORE3D 14
-
[64]
Single- stage diffusion nerf: A unified approach to 3d generation and reconstruction,
H. Chen, J. Gu, A. Chen, W. Tian, Z. Tu, L. Liu, and H. Su, “Single- stage diffusion nerf: A unified approach to 3d generation and reconstruction,” inICCV, 2023
2023
-
[65]
Point-cloud completion with pretrained text-to-image diffusion models,
Y. Kasten, O. Rahamim, and G. Chechik, “Point-cloud completion with pretrained text-to-image diffusion models,” 2023
2023
-
[66]
Unsupervised 3d shape completion through gan inversion,
J. Zhang, X. Chen, Z. Cai, L. Pan, H. Zhao, S. Yi, C. K. Yeo, B. Dai, and C. C. Loy, “Unsupervised 3d shape completion through gan inversion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1768–1777
2021
-
[67]
Scan2mesh: From unstructured range scans to 3d meshes,
A. Dai and M. Nießner, “Scan2mesh: From unstructured range scans to 3d meshes,” 2019
2019
-
[68]
Autosdf: Shape priors for 3d completion, reconstruction and generation,
P . Mittal, Y.-C. Cheng, M. Singh, and S. Tulsiani, “Autosdf: Shape priors for 3d completion, reconstruction and generation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 306–315
2022
-
[69]
Variational relational point completion network,
L. Pan, X. Chen, Z. Cai, J. Zhang, H. Zhao, S. Yi, and Z. Liu, “Variational relational point completion network,” 2021
2021
-
[70]
Diffcomplete: Diffusion-based generative 3d shape completion,
R. Chu, E. Xie, S. Mo, Z. Li, M. Nießner, C.-W. Fu, and J. Jia, “Diffcomplete: Diffusion-based generative 3d shape completion,” 2023
2023
-
[71]
Texture: Text-guided texturing of 3d shapes,
E. Richardson, G. Metzer, Y. Alaluf, R. Giryes, and D. Cohen- Or, “Texture: Text-guided texturing of 3d shapes,”arXiv preprint arXiv:2302.01721, 2023
-
[72]
Texfusion: Syn- thesizing 3d textures with text-guided image diffusion models,
T. Cao, K. Kreis, S. Fidler, N. Sharp, and K. Yin, “Texfusion: Syn- thesizing 3d textures with text-guided image diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4169–4181
2023
-
[73]
Text2tex: Text-driven texture synthesis via diffusion models,
D. Z. Chen, Y. Siddiqui, H.-Y. Lee, S. Tulyakov, and M. Nießner, “Text2tex: Text-driven texture synthesis via diffusion models,” arXiv preprint arXiv:2303.11396, 2023
-
[74]
Paint3d: Paint anything 3d with lighting-less texture diffusion models,
X. Zeng, X. Chen, Z. Qi, W. Liu, Z. Zhao, Z. Wang, B. Fu, Y. Liu, and G. Yu, “Paint3d: Paint anything 3d with lighting-less texture diffusion models,” 2023
2023
-
[75]
Texturify: Generating textures on 3d shape surfaces,
Y. Siddiqui, J. Thies, F. Ma, Q. Shan, M. Nießner, and A. Dai, “Texturify: Generating textures on 3d shape surfaces,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 72–88
2022
-
[76]
A style-based generator archi- tecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator archi- tecture for generative adversarial networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4401–4410
2019
-
[77]
Mesh2tex: Generating mesh textures from image queries,
A. Bokhovkin, S. Tulsiani, and A. Dai, “Mesh2tex: Generating mesh textures from image queries,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8918–8928
2023
-
[78]
Texture generation on 3d meshes with point-uv diffusion,
X. Yu, P . Dai, W. Li, L. Ma, Z. Liu, and X. Qi, “Texture generation on 3d meshes with point-uv diffusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4206–4216
2023
-
[79]
Auv-net: Learning aligned uv maps for texture transfer and synthesis,
Z. Chen, K. Yin, and S. Fidler, “Auv-net: Learning aligned uv maps for texture transfer and synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1465–1474
2022
-
[80]
Learning texture generators for 3d shape collections from internet photo sets,
R. Yu, Y. Dong, P . Peers, and X. Tong, “Learning texture generators for 3d shape collections from internet photo sets,” inBritish Machine Vision Conference, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.