MoVA: Learning Asymmetric Dual Projections for Modular Long Video-Text Alignment
Pith reviewed 2026-07-02 14:22 UTC · model grok-4.3
The pith
Dual asymmetric projections align long videos with texts by separating global semantics from frame-specific details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
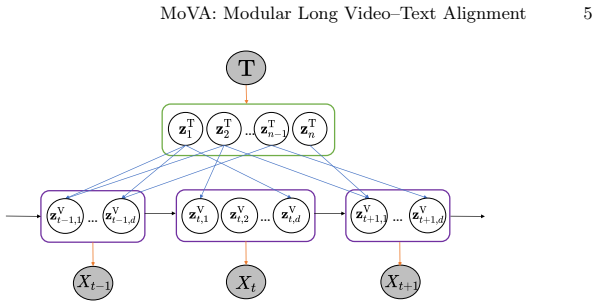
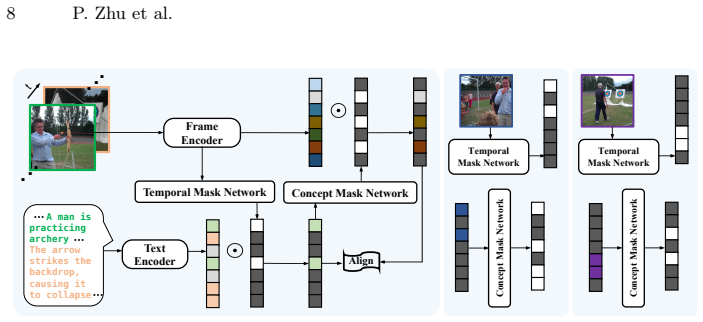
MoVA learns dual asymmetric projections: a text-side projection that adaptively selects frame-aware subspaces of the caption and a video-side projection that disentangles text-relevant visual concepts, based on conditions for alignment across temporal dimensions and granularity, so that global semantics are preserved while frame-specific concepts are separated and the approach scales to long videos and captions.
What carries the argument
Dual asymmetric projections, with the text projection selecting frame-aware caption subspaces and the video projection disentangling relevant visual concepts.
If this is right
- Global cross-modal semantics remain preserved while frame-specific concepts are disentangled.
- The method scales naturally to long captions and videos without increased entanglement.
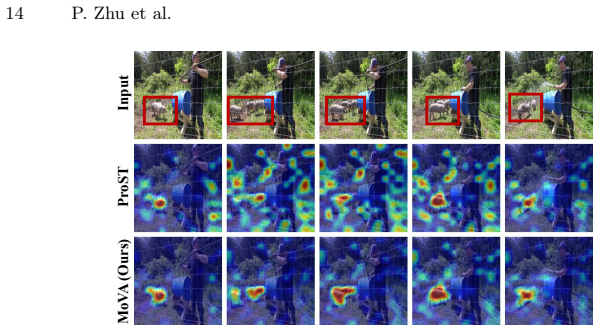
- Performance improves on multiple video-text alignment tasks compared with prior methods.
- Text-irrelevant frames can be handled without forcing full-caption equivalence.
Where Pith is reading between the lines
- Similar dual-projection logic could be tested on tasks like video question answering where only portions of a clip are relevant.
- The separation of global and local concepts might reduce error propagation in downstream video generation models.
- Applying the asymmetry handling to multi-shot or multi-scene videos could expose whether the projections generalize beyond single continuous clips.
Load-bearing premise
Theoretical conditions exist that enable flexible alignment between video and text representations across the temporal dimension and at varying levels of granularity.
What would settle it
A controlled test on video-text pairs with known temporal mismatch and semantic asymmetry where MoVA shows no accuracy gain over standard contrastive baselines would falsify the claim.
Figures



read the original abstract
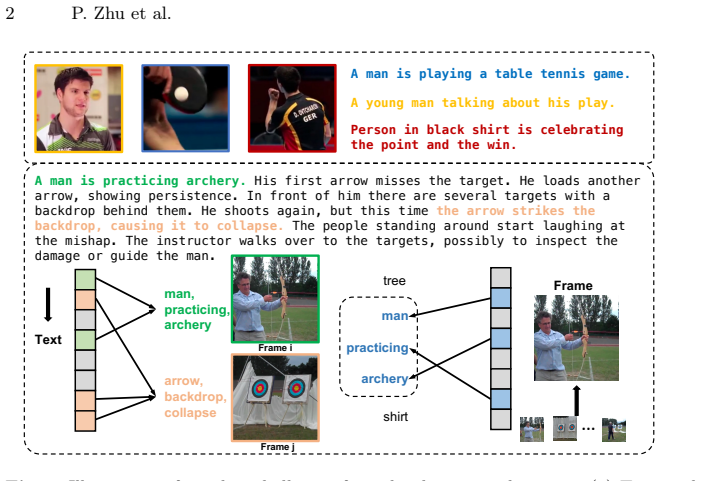
Contrastive pre-training has propelled video-text alignment, yet models often inherit the critical limitations of their image-text predecessors like CLIP, resulting in entangled representations. These challenges are severely exacerbated by two fundamental properties in the video domain: Temporal Misalignment, where textual descriptions often correlate only to specific, constrained temporal windows, leaving other frames text-irrelevant; and Semantic Asymmetry, which dictates a sparse, bidirectional, and non-equivalent relevance between frame-level visual details and caption-level concepts. This failure persists whether captions are short and temporally disjoint, creating ambiguity, or long and detailed, fostering entanglement between static objects and their temporal evolution. In this paper, we establish theoretical conditions that enable flexible alignment between video and text representations across the temporal dimension and at varying levels of granularity. Building on these theoretical insights, we introduce MoVA, Modular Long Video-Text Alignment, which learns dual asymmetric projections: a text-side projection that adaptively selects frame-aware subspaces of the caption, and a video-side projection that disentangles text-relevant visual concepts. Our framework ensures that the model can preserve global cross-modal semantics while disentangling evolving, frame-specific concepts and scale naturally to long captions and videos. Empirical evaluations show that MoVA outperforms existing methods in multiple video-text alignment tasks, demonstrating the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temporal misalignment and semantic asymmetry in video-text data can be addressed by first establishing (unspecified) theoretical conditions for flexible cross-modal alignment across time and granularity, then introducing MoVA, which learns a text-side projection that selects frame-aware caption subspaces and a video-side projection that disentangles text-relevant visual concepts; the resulting model is said to preserve global semantics while scaling to long videos/captions and to outperform prior methods on multiple alignment tasks.
Significance. If the asserted theoretical conditions can be shown to exist, be non-trivial, and directly motivate the dual asymmetric projections, and if the empirical gains are reproducible with proper controls, the work could provide a modular way to mitigate entanglement issues inherited from image-text models like CLIP when applied to video. No machine-checked proofs, parameter-free derivations, or falsifiable predictions are visible in the supplied abstract.
major comments (2)
- [Abstract] Abstract: the central motivation rests on the existence of 'theoretical conditions that enable flexible alignment between video and text representations across the temporal dimension and at varying levels of granularity,' yet the abstract supplies neither equations, assumptions, nor a proof sketch; without these the necessity of the dual asymmetric projections for handling Temporal Misalignment and Semantic Asymmetry cannot be evaluated.
- [Abstract] Abstract: the claim that 'MoVA outperforms existing methods in multiple video-text alignment tasks' is presented without any dataset names, baseline comparisons, quantitative metrics, error bars, or ablation results, rendering it impossible to assess whether the reported gains are attributable to the claimed mechanism rather than implementation details.
Simulated Author's Rebuttal
We thank the referee for their comments on the manuscript. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation rests on the existence of 'theoretical conditions that enable flexible alignment between video and text representations across the temporal dimension and at varying levels of granularity,' yet the abstract supplies neither equations, assumptions, nor a proof sketch; without these the necessity of the dual asymmetric projections for handling Temporal Misalignment and Semantic Asymmetry cannot be evaluated.
Authors: We agree the abstract omits the mathematical details due to length constraints. The theoretical conditions, including assumptions on temporal and granularity alignment and the derivation motivating the asymmetric projections, are established in Section 3 of the full manuscript. To address the concern, we will revise the abstract to briefly reference the key theoretical result. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'MoVA outperforms existing methods in multiple video-text alignment tasks' is presented without any dataset names, baseline comparisons, quantitative metrics, error bars, or ablation results, rendering it impossible to assess whether the reported gains are attributable to the claimed mechanism rather than implementation details.
Authors: Abstracts are space-limited and provide summaries; full details on datasets, baselines, metrics, error bars, and ablations appear in Sections 4 and 5. We will partially revise the abstract to name representative tasks and note the scale of gains while keeping within length limits. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract asserts theoretical conditions enabling flexible video-text alignment and introduces dual asymmetric projections as a consequence, but supplies no equations, fitted parameters, or derivation steps that reduce to self-defined quantities or self-citations. Claims rest on empirical outperformance rather than a closed loop; the reader's assessment of score 2.0 aligns with absence of inspectable circular reductions in the visible text. The framework is presented as building on stated insights without the patterns of self-definition or imported uniqueness.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE international conference on computer vision
Anne Hendricks, L., Wang, O., Shechtman, E., Sivic, J., Darrell, T., Russell, B.: Localizing moments in video with natural language. In: Proceedings of the IEEE international conference on computer vision. pp. 5803–5812 (2017)
2017
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Journal of machine learning research3(Feb), 1137–1155 (2003)
Bengio, Y., Ducharme, R., Vincent, P., Jauvin, C.: A neural probabilistic language model. Journal of machine learning research3(Feb), 1137–1155 (2003)
2003
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013) 16 P. Zhu et al
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies
Chen, D., Dolan, W.B.: Collecting highly parallel data for paraphrase evaluation. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies. pp. 190–200 (2011)
2011
-
[6]
Advances in Neural Information Processing Systems38(2026)
Chen,G., Deng, Y.,Zhu,P., Li,Y., Shen, Y.,Li, Z., Zhang,K.: Causalverse: Bench- marking causal representation learning with configurable high-fidelity simulations. Advances in Neural Information Processing Systems38(2026)
2026
-
[7]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion mod- els. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7310–7320 (2024).https://doi.org/10.1109/CVPR52733.2024. 00698
-
[8]
In: Eu- ropean Conference on Computer Vision
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. In: Eu- ropean Conference on Computer Vision. pp. 370–387. Springer (2024).https: //doi.org/10.1007/978-3-031-72643-9_22
-
[9]
Advances in Neural Information Processing Systems36, 72842–72866 (2023)
Chen,S.,Li,H.,Wang,Q.,Zhao,Z.,Sun,M.,Zhu,X.,Liu,J.:Vast:Avision-audio- subtitle-text omni-modality foundation model and dataset. Advances in Neural Information Processing Systems36, 72842–72866 (2023)
2023
-
[10]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PmLR (2020)
2020
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Y., Chen, D., Liu, R., Zhou, S., Xue, W., Peng, W.: Align before adapt: Leveraging entity-to-region alignments for generalizable video action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18688–18698 (2024)
2024
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence37(1), 396–404 (2023).https://doi.org/10
Chen, Y., Wang, J., Lin, L., Qi, Z., Ma, J., Shan, Y.: Tagging before alignment: Integrating multi-modal tags for video-text retrieval. Proceedings of the AAAI Conference on Artificial Intelligence37(1), 396–404 (2023).https://doi.org/10. 1609/aaai.v37i1.25113
2023
-
[13]
arXiv preprint arXiv:2109.04290 (2021)
Cheng, X., Lin, H., Wu, X., Yang, F., Shen, D.: Improving video-text re- trieval by multi-stream corpus alignment and dual softmax loss. arXiv preprint arXiv:2109.04290 (2021)
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Croitoru, I., Bogolin, S.V., Leordeanu, M., Jin, H., Zisserman, A., Albanie, S., Liu, Y.: Teachtext: Crossmodal generalized distillation for text-video retrieval. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11583–11593 (2021)
2021
-
[15]
arXiv preprint arXiv:2303.09166 (2023)
Daunhawer, I., Bizeul, A., Palumbo, E., Marx, A., Vogt, J.E.: Identifiability results for multimodal contrastive learning. arXiv preprint arXiv:2303.09166 (2023)
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Deng, C., Chen, Q., Qin, P., Chen, D., Wu, Q.: Prompt switch: Efficient clip adaptation for text-video retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15648–15658 (2023)
2023
-
[17]
Advances in Neural Information Processing Systems36, 35544– 35575 (2023)
Fan, L., Krishnan, D., Isola, P., Katabi, D., Tian, Y.: Improving clip training with language rewrites. Advances in Neural Information Processing Systems36, 35544– 35575 (2023)
2023
-
[18]
In: Uncertainty in Artificial Intelligence
Gresele, L., Rubenstein, P.K., Mehrjou, A., Locatello, F., Schölkopf, B.: The in- complete rosetta stone problem: Identifiability results for multi-view nonlinear ica. In: Uncertainty in Artificial Intelligence. pp. 217–227. PMLR (2020)
2020
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) MoVA: Modular Long Video–Text Alignment 17
2024
-
[20]
In: Artificial intelligence and statistics
Hyvarinen, A., Morioka, H.: Nonlinear ica of temporally dependent stationary sources. In: Artificial intelligence and statistics. pp. 460–469. PMLR (2017)
2017
-
[21]
Jiang, W., Guan, W., Li, H., Li, Z., Fang, Y., Peng, Y., Zhao, X., Liu, Y.: Text- conditional visual-language alignment for video captioning. IEEE Transactions on Circuits and Systems for Video Technology36(3), 3185–3200 (2026).https:// doi.org/10.1109/TCSVT.2025.3616201
-
[22]
In: Proceedings of the Thirty-Second International Joint Conference on Artificial In- telligence
Jin, P., Li, H., Cheng, Z., Huang, J., Wang, Z., Yuan, L., Liu, C., Chen, J.: Text- video retrieval with disentangled conceptualization and set-to-set alignment. In: Proceedings of the Thirty-Second International Joint Conference on Artificial In- telligence. pp. 938–946 (2023).https://doi.org/10.24963/ijcai.2023/104
-
[23]
Learning Zero-Shot Subject-Driven Video Generation Using 1% Compute
Kim, D., Zhang, J., Jin, W., Cho, S., Dai, Q., Park, J., Luo, C.: Subject- driven video generation via disentangled identity and motion. arXiv preprint arXiv:2504.17816 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
arXiv preprint arXiv:2007.10930 (2020)
Klindt, D., Schott, L., Sharma, Y., Ustyuzhaninov, I., Brendel, W., Bethge, M., Paiton, D.: Towards nonlinear disentanglement in natural data with temporal sparse coding. arXiv preprint arXiv:2007.10930 (2020)
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ko, D., Choi, J., Ko, J., Noh, S., On, K.W., Kim, E.S., Kim, H.J.: Video-text representation learning via differentiable weak temporal alignment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5016–5025 (2022)
2022
-
[26]
In: Proceedings of the IEEE international conference on computer vision
Krishna, R., Hata, K., Ren, F., Fei-Fei, L., Carlos Niebles, J.: Dense-captioning events in videos. In: Proceedings of the IEEE international conference on computer vision. pp. 706–715 (2017)
2017
-
[27]
In: European Conference on Computer Vision
Lai, Z., Zhang, H., Zhang, B., Wu, W., Bai, H., Timofeev, A., Du, X., Gan, Z., Shan, J., Chuah, C.N., et al.: Veclip: Improving clip training via visual-enriched captions. In: European Conference on Computer Vision. pp. 111–127. Springer (2024)
2024
-
[28]
In: Findings of the AssociationforComputationalLinguistics:EACL2024.pp.1487–1500.Association for Computational Linguistics, St
Lewis, M., Nayak, N., Yu, P., Merullo, J., Yu, Q., Bach, S., Pavlick, E.: Does CLIP bind concepts? probing compositionality in large image models. In: Findings of the AssociationforComputationalLinguistics:EACL2024.pp.1487–1500.Association for Computational Linguistics, St. Julian’s, Malta (2024).https://doi.org/10. 18653/v1/2024.findings-eacl.101
2024
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, P., Xie, C.W., Zhao, L., Xie, H., Ge, J., Zheng, Y., Zhao, D., Zhang, Y.: Progres- sive spatio-temporal prototype matching for text-video retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4100–4110 (2023)
2023
-
[30]
Neuro- computing508, 293–304 (2022)
Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., Li, T.: Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neuro- computing508, 293–304 (2022)
2022
-
[31]
In: Proceedings of the 30th ACM international conference on multimedia
Ma, Y., Xu, G., Sun, X., Yan, M., Zhang, J., Ji, R.: X-clip: End-to-end multi- grained contrastive learning for video-text retrieval. In: Proceedings of the 30th ACM international conference on multimedia. pp. 638–647 (2022)
2022
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Materzyńska, J., Torralba, A., Bau, D.: Disentangling visual and written concepts in clip. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16410–16419 (2022)
2022
-
[33]
arXiv preprint arXiv:2310.15709 , year=
Morioka, H., Hyvärinen, A.: Causal representation learning made identifiable by grouping of observational variables. arXiv preprint arXiv:2310.15709 (2023)
-
[34]
In: International con- ference on artificial intelligence and statistics
Morioka, H., Hyvarinen, A.: Connectivity-contrastive learning: Combining causal discovery and representation learning for multimodal data. In: International con- ference on artificial intelligence and statistics. pp. 3399–3426. PMLR (2023) 18 P. Zhu et al
2023
-
[35]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
In: International Conference on Learning Representations (2021)
Patrick, M., Huang, P.Y., Asano, Y., Metze, F., Hauptmann, A.G., Henriques, J.F., Vedaldi, A.: Support-set bottlenecks for video-text representation learning. In: International Conference on Learning Representations (2021)
2021
-
[37]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rasheed, H., Khattak, M.U., Maaz, M., Khan, S., Khan, F.S.: Fine-tuned clip models are efficient video learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6545–6554 (2023)
2023
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rizve, M.N., Fei, F., Unnikrishnan, J., Tran, S., Yao, B.Z., Zeng, B., Shah, M., Chilimbi, T.: Vidla: Video-language alignment at scale. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14043– 14055 (2024)
2024
-
[40]
Sakoe, H., Chiba, S.: Dynamic programming algorithm optimization for spoken word recognition. IEEE transactions on acoustics, speech, and signal processing 26(1), 43–49 (1978).https://doi.org/10.1109/TASSP.1978.1163055
-
[41]
In: Proceedings of the IEEE International Conference on Computer Vision
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 618– 626 (2017)
2017
-
[42]
In: The Fourteenth International Conference on Learning Representations (2026)
Shen, Y., Zhu, P., Li, Z., Xie, S., Deka, N., Liu, Z., Tang, Z., Chen, G., Zhang, K.: Controllable video generation with provable disentanglement. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[43]
ACM Transactions on Multimedia Comput- ing, Communications and Applications19(2), 1–21 (2023)
Shi, Y., Xu, H., Yuan, C., Li, B., Hu, W., Zha, Z.J.: Learning video-text aligned representations for video captioning. ACM Transactions on Multimedia Comput- ing, Communications and Applications19(2), 1–21 (2023)
2023
-
[44]
arXiv preprint arXiv:2411.06518 (2025)
Sun, Y., Kong, L., Chen, G., Li, L., Luo, G., Li, Z., Zhang, Y., Zheng, Y., Yang, M., Stojanov, P., Segal, E., Xing, E.P., Zhang, K.: Causal representation learning from multimodal biomedical observations. arXiv preprint arXiv:2411.06518 (2025)
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Thrush, T., Jiang, R., Bartolo, M., Singh, A., Williams, A., Kiela, D., Ross, C.: Winoground: Probing vision and language models for visio-linguistic composition- ality. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 5238–5248 (2022)
2022
-
[46]
In: Proceedings of the AAAI conference on artificial intelligence
Tian, K., Cheng, Y., Liu, Y., Hou, X., Chen, Q., Li, H.: Towards efficient and effective text-to-video retrieval with coarse-to-fine visual representation learning. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 5207– 5214 (2024)
2024
-
[47]
Advances in neural information processing systems34, 16451–16467 (2021)
Von Kügelgen, J., Sharma, Y., Gresele, L., Brendel, W., Schölkopf, B., Besserve, M., Locatello, F.: Self-supervised learning with data augmentations provably iso- lates content from style. Advances in neural information processing systems34, 16451–16467 (2021)
2021
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing
Wang, J., Wang, C., Huang, K., Huang, J., Jin, L.: Videoclip-xl: Advancing long description understanding for video clip models. In: Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing. pp. 16061–16075 (2024).https://doi.org/10.18653/v1/2024.emnlp-main.898
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, J., Ge, Y., Cai, G., Yan, R., Lin, X., Shan, Y., Qie, X., Shou, M.Z.: Object- aware video-language pre-training for retrieval. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3313–3322 (2022)
2022
-
[51]
arXiv preprint arXiv:2203.07111 (2022)
Wang, Q., Zhang, Y., Zheng, Y., Pan, P., Hua, X.S.: Disentangled representation learning for text-video retrieval. arXiv preprint arXiv:2203.07111 (2022)
-
[52]
Wang, W., Yang, Y.: Vidprom: A million-scale real prompt-gallery dataset for text- to-video diffusion models. Advances in Neural Information Processing Systems37, 65618–65642 (2024).https://doi.org/10.52202/079017-2096
-
[53]
arXiv preprint arXiv:2503.01739 (2025) 4
Wang, W., Yang, Y.: Videoufo: A million-scale user-focused dataset for text-to- video generation. arXiv preprint arXiv:2503.01739 (2025)
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, X., Zhu, L., Yang, Y.: T2vlad: Global-local sequence alignment for text- video retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5079–5088 (2021)
2021
-
[55]
IEEE Transactions on Multimedia25, 6079–6089 (2023).https://doi.org/10.1109/TMM.2022.3204444
Wang, X., Zhu, L., Zheng, Z., Xu, M., Yang, Y.: Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision. IEEE Transactions on Multimedia25, 6079–6089 (2023).https://doi.org/10.1109/TMM.2022.3204444
-
[56]
In: The Twelfth International Conference on Learning Representations (2024)
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., Luo, P., Liu, Z., Wang, Y., Wang, L., Qiao, Y.: Internvid: A large-scale video-text dataset for multimodal understanding and generation. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[57]
In: European Conference on Computer Vision
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Wang, Z., Shi, Y., et al.: Internvideo2: Scaling foundation models for multimodal video un- derstanding. In: European Conference on Computer Vision. pp. 396–416. Springer (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, Z., Sung, Y.L., Cheng, F., Bertasius, G., Bansal, M.: Unified coarse-to-fine alignment for video-text retrieval. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2816–2827 (2023)
2023
-
[59]
In: Proceedings of the 29th ACM international conference on Multimedia
Wu, P., He, X., Tang, M., Lv, Y., Liu, J.: Hanet: Hierarchical alignment networks for video-text retrieval. In: Proceedings of the 29th ACM international conference on Multimedia. pp. 3518–3527 (2021)
2021
-
[60]
In: Forty-second International Conference on Machine Learning (2025)
Xie, S., Kong, L., Zheng, Y., Tang, Z., Xing, E.P., Chen, G., Zhang, K.: Learning vision and language concepts for controllable image generation. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[61]
com- press highlights, lift midtones
Xie, S., Kong, L., Zheng, Y., Yao, Y., Tang, Z., Xing, E.P., Chen, G., Zhang, K.: Smartclip: Modular vision-language alignment with identification guarantees. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 29780–29790 (2025).https://doi.org/10.1109/CVPR52734.2025. 02772
-
[62]
Advances in Neural Information Processing Systems37, 16623–16644 (2024)
Xiong, T., Wang, Y., Zhou, D., Lin, Z., Feng, J., Liu, X.: Lvd-2m: A long-take video dataset with temporally dense captions. Advances in Neural Information Processing Systems37, 16623–16644 (2024)
2024
-
[63]
arXiv preprint arXiv:2403.08335 (2024) 20 P
Xu, D., Yao, D., Lachapelle, S., Taslakian, P., Von Kügelgen, J., Locatello, F., Magliacane, S.: A sparsity principle for partially observable causal representation learning. arXiv preprint arXiv:2403.08335 (2024) 20 P. Zhu et al
-
[64]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xue, H., Hang, T., Zeng, Y., Sun, Y., Liu, B., Yang, H., Fu, J., Guo, B.: Advancing high-resolution video-language representation with large-scale video transcriptions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16456–16466 (2022)
2022
-
[65]
In: The Eleventh International Conference on Learning Representations (2023)
Xue, H., Sun, Y., Liu, B., Fu, J., Song, R., Li, H., Luo, J.: Clip-vip: Adapting pre-trained image-text model to video-language representation alignment. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[66]
arXiv preprint arXiv:2506.13691 , year=
Xue, Z., Zhang, J., Hu, T., He, H., Chen, Y., Cai, Y., Wang, Y., Wang, C., Liu, Y., Li, X., et al.: Ultravideo: High-quality uhd video dataset with comprehensive captions. arXiv preprint arXiv:2506.13691 (2025)
-
[67]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, X., Zhu, L., Wang, X., Yang, Y.: Dgl: Dynamic global-local prompt tun- ing for text-video retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6540–6548 (2024)
2024
-
[68]
arXiv preprint arXiv:2311.04056 (2023)
Yao, D., Xu, D., Lachapelle, S., Magliacane, S., Taslakian, P., Martius, G., von Kügelgen, J., Locatello, F.: Multi-view causal representation learning with partial observability. arXiv preprint arXiv:2311.04056 (2023)
-
[69]
arXiv preprint arXiv:2202.04828 (2022)
Yao, W., Chen, G., Zhang, K.: Learning latent causal dynamics. arXiv preprint arXiv:2202.04828 (2022)
-
[70]
arXiv preprint arXiv:2110.05428 (2021)
Yao, W., Sun, Y., Ho, A., Sun, C., Zhang, K.: Learning temporally causal latent processes from general temporal data. arXiv preprint arXiv:2110.05428 (2021)
-
[71]
Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., Zou, J.: When and why vision-language models behave like bags-of-words, and what to do about it? In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[72]
In: European conference on computer vision
Zhang, B., Zhang, P., Dong, X., Zang, Y., Wang, J.: Long-clip: Unlocking the long- text capability of clip. In: European conference on computer vision. pp. 310–325. Springer (2024)
2024
-
[73]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, W., Wan, C., Liu, T., Tian, X., Shen, X., Ye, J.: Enhanced motion-text alignment for image-to-video transfer learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18504–18515 (2024)
2024
-
[74]
Advances in neural information processing systems35, 16411–16422 (2022)
Zheng,Y.,Ng,I.,Zhang,K.:Ontheidentifiabilityofnonlinearica:Sparsityandbe- yond. Advances in neural information processing systems35, 16411–16422 (2022)
2022
-
[75]
Zheng, Y., Zhang, K.: Generalizing nonlinear ica beyond structural sparsity. Ad- vances in Neural Information Processing Systems36, 13326–13355 (2023) MoVA: Modular Long Video–Text Alignment 21 Supplementary Material A Proof Our identification analysis shows that the selective, mask-based alignment ob- jective in (3) recovers caption-conditioned semantic ...
2023
-
[76]
Equivalently, PT ˆzT is independent ofϵT
(Nuisance invariance on the text active block) For every coordinateiwith [PT ]ii = 1and every text-nuisance coordinatej, ∂[ˆzT]i ∂[ϵT]j = 0 . Equivalently, PT ˆzT is independent ofϵT. 22 P. Zhu et al
-
[77]
↑” denotes that higher is better. “↓
(Blockwise invertible reparameterizations) There exist smooth, locally invert- ible mapsh T andh V (defined on the respective active blocks) such that PT ˆzT =P T hT(zT), P V ˆzV t =P V hV(zV t ). Proof.Step A: Fix projectors and use alignment.Because mask supports are locally constant,PT andP V are fixed binary projectors in the neighborhood. By optimali...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.