TurnNat: Automatic Evaluation of Turn-Taking Naturalness in Dyadic Spoken Dialogue
Pith reviewed 2026-07-03 21:20 UTC · model grok-4.3
The pith
TurnNat scores turn-taking naturalness by negative log-likelihood of observed voice-activity states under a model trained on natural conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
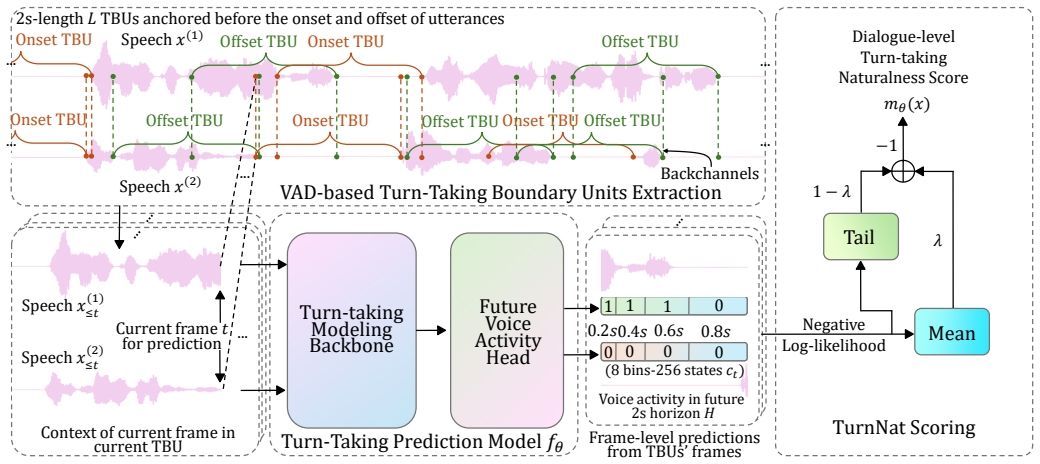
TurnNat is a likelihood-based framework that trains a causal turn-taking prediction model on natural conversations, computes the negative log-likelihood of observed future two-speaker voice-activity states to quantify timing atypicality, pools the values over turn-taking boundary units extracted from utterance boundaries, and aggregates mean and tail scores into a dialogue-level naturalness score; experiments on a controlled perturbation benchmark validated by human judgments show that the resulting scores identify unnatural turn-taking across heterogeneous timing failures.
What carries the argument
A causal turn-taking prediction model trained on natural conversations that estimates future two-speaker voice-activity states, with negative log-likelihood of the observed states serving as the measure of timing atypicality.
If this is right
- Dialogue systems can be compared and improved on turn-taking quality using a single automatic score instead of separate human studies for each timing issue.
- Overlaps, gaps, and other timing perturbations can be evaluated and ranked on the same numerical scale.
- Training or fine-tuning of full-duplex dialogue models can incorporate the TurnNat score as a direct optimization target.
- The approach can be applied to any new two-channel dialogue corpus once the prediction model is retrained on its natural examples.
Where Pith is reading between the lines
- If the underlying prediction model generalizes well, the same scoring procedure could be transferred to new languages or domains by retraining only the voice-activity predictor.
- TurnNat scores could be combined with other automatic dialogue metrics such as semantic appropriateness to produce a broader evaluation suite.
- Real-time computation of the likelihood during live conversations might allow a system to adjust its own turn-taking behavior on the fly.
Load-bearing premise
That negative log-likelihood of future voice-activity states under a model trained on natural conversations measures timing atypicality in a way that aligns with human naturalness judgments.
What would settle it
A collection of dialogue clips in which human raters judge the timing as natural yet TurnNat assigns high atypicality scores, or clips in which perturbed timing receives lower scores than the corresponding natural versions.
Figures
read the original abstract
Turn-taking naturalness is central to full-duplex spoken dialogue systems, yet its automatic evaluation remains limited. Existing evaluations often rely on human judgments or behavior-specific timing metrics, making it difficult to compare heterogeneous timing failures within a unified framework. We propose TurnNat, a likelihood-based framework for automatic turn-taking naturalness evaluation in two-channel spoken dialogue. A causal turn-taking prediction model trained on natural conversations estimates future two-speaker voice-activity states, and the negative log-likelihood (NLL) of the observed future activity measures timing atypicality. TurnNat pools frame-level NLLs over turn-taking boundary units (TBUs) extracted from utterance onsets and offsets, and aggregates mean and tail TBU scores into a dialogue-level naturalness score. We further construct a controlled perturbation benchmark of paired natural and perturbed dialogue clips, validated by human naturalness judgments. Experiments on this benchmark show that TurnNat successfully identifies unnatural turn-taking perturbations across heterogeneous timing failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TurnNat, a likelihood-based framework for automatic evaluation of turn-taking naturalness in two-channel spoken dialogue. A causal model is trained on natural conversations to predict future two-speaker voice-activity states; negative log-likelihood (NLL) of observed future states, pooled over turn-taking boundary units (TBUs) at onsets/offsets and aggregated into mean and tail scores, serves as the naturalness metric. A controlled perturbation benchmark of paired natural/perturbed clips is constructed and human-validated. The central claim is that experiments on this benchmark demonstrate TurnNat successfully identifies unnatural perturbations across heterogeneous timing failures.
Significance. If the empirical results hold, the work would supply a unified, model-based automatic metric capable of comparing heterogeneous timing failures without task-specific rules or direct human rating at inference time. The human-validated perturbation benchmark itself constitutes a reusable contribution for controlled evaluation of turn-taking models.
major comments (2)
- [Abstract] Abstract: the claim that 'Experiments on this benchmark show that TurnNat successfully identifies unnatural turn-taking perturbations across heterogeneous timing failures' is unsupported by any quantitative results, tables, figures, error analysis, or baseline comparisons in the manuscript description. This absence is load-bearing for the central empirical claim.
- [Abstract / Experiments] The evaluation rests on the assumption that NLL of future VAD states under a model trained on natural data aligns with human naturalness judgments for perturbed dialogues; while a human-validated benchmark is mentioned, no details are supplied on perturbation generation, inter-rater agreement, or correlation between TBU NLL scores and human ratings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below. We agree that the abstract and evaluation sections require strengthening with additional quantitative support and methodological details, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments on this benchmark show that TurnNat successfully identifies unnatural turn-taking perturbations across heterogeneous timing failures' is unsupported by any quantitative results, tables, figures, error analysis, or baseline comparisons in the manuscript description. This absence is load-bearing for the central empirical claim.
Authors: We agree that the abstract claim would be stronger if accompanied by quantitative evidence. The manuscript body contains the relevant experimental results, tables, and figures, but these are not referenced or summarized in the abstract. We will revise the abstract to include key quantitative outcomes (e.g., differences in mean and tail TBU NLL scores between natural and perturbed conditions, along with statistical significance) to directly support the claim. revision: yes
-
Referee: [Abstract / Experiments] The evaluation rests on the assumption that NLL of future VAD states under a model trained on natural data aligns with human naturalness judgments for perturbed dialogues; while a human-validated benchmark is mentioned, no details are supplied on perturbation generation, inter-rater agreement, or correlation between TBU NLL scores and human ratings.
Authors: We acknowledge the need for greater transparency on the benchmark construction and validation. In the revised manuscript we will expand the relevant section to include: (1) the precise procedure used to generate the controlled perturbations, (2) inter-rater agreement statistics from the human validation study, and (3) quantitative correlation results between the aggregated TBU NLL scores and the collected human naturalness ratings. These additions will make the alignment between model likelihood and human judgments explicit. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper defines TurnNat as a likelihood-based scoring method: a causal model is trained on natural two-speaker VAD sequences, after which NLL of observed future states (aggregated over TBUs) serves as the atypicality measure. This score is then tested for its ability to flag artificially perturbed clips on a human-validated benchmark. No derivation chain, equation, or self-citation reduces the central claim to a tautology or fitted input by construction; the evaluation relies on external human judgments rather than internal re-use of the same fitted values. The approach is therefore self-contained against the supplied benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A causal turn-taking prediction model trained on natural conversations can estimate future two-speaker voice-activity states whose negative log-likelihood measures timing atypicality.
Reference graph
Works this paper leans on
-
[1]
A survey of recent advances on turn-taking modeling in spoken dialogue systems,
G. Castillo-L ´opez, G. de Chalendar, and N. Semmar, “A survey of recent advances on turn-taking modeling in spoken dialogue systems,” inProceedings of the 15th international workshop on spoken dialogue systems technology, 2025, pp. 254–271
2025
-
[2]
Response timing estimation for spoken dialog systems based on syntactic completeness prediction,
J. Sakuma, S. Fujie, and T. Kobayashi, “Response timing estimation for spoken dialog systems based on syntactic completeness prediction,” in 2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 369–374
2022
-
[3]
Wavchat: A survey of spoken dialogue models,
S. Ji, Y . Chen, M. Fang, J. Zuo, J. Lu, H. Wang, Z. Jiang, L. Zhou, S. Liu, X. Chenget al., “Wavchat: A survey of spoken dialogue models,”arXiv preprint arXiv:2411.13577, 2024
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Llama- omni: Seamless speech interaction with large language models,
Q. Fang, S. Guo, Y . Zhou, Z. Ma, S. Zhang, and Y . Feng, “Llama- omni: Seamless speech interaction with large language models,” in International Conference on Learning Representations, vol. 2025, 2025, pp. 57 607–57 624
2025
-
[6]
Mini-omni: Language models can hear, talk while thinking in streaming,
Z. Xie and C. Wu, “Mini-omni: Language models can hear, talk while thinking in streaming,”arXiv preprint arXiv:2408.16725, 2024
-
[7]
Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,
X. Wang, Y . Li, C. Fu, Y . Zhang, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 63 345–63 354
2025
-
[8]
G.-T. Lin, J. Lian, T. Li, Q. Wang, G. Anumanchipalli, A. H. Liu, and H.-y. Lee, “Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities,”arXiv preprint arXiv:2503.04721, 2025
-
[9]
Mitigating response delays in free-form conversations with llm- powered intelligent virtual agents,
M. Maslych, M. Katebi, C. Lee, Y . Hmaiti, A. Ghasemaghaei, C. Pumarada, J. Palmer, E. Segarra Martinez, M. Emporio, W. Snipes et al., “Mitigating response delays in free-form conversations with llm- powered intelligent virtual agents,” inProceedings of the 7th ACM Conference on Conversational User Interfaces, 2025, pp. 1–15
2025
-
[10]
Neural generation of dialogue response timings,
M. Roddy and N. Harte, “Neural generation of dialogue response timings,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 2442–2452
2020
-
[11]
Toward enabling natural conversation with older adults via the design of llm-powered voice agents that support interruptions and backchannels,
C. Liu, M. Su, Y . Xiang, Y . Huang, Y . Yang, K. Zhang, and M. Fan, “Toward enabling natural conversation with older adults via the design of llm-powered voice agents that support interruptions and backchannels,” inProceedings of the 2025 CHI conference on human factors in computing systems, 2025, pp. 1–22
2025
-
[12]
A mixed-methods approach to understanding user trust after voice assistant failures,
A. Baughan, X. Wang, A. Liu, A. Mercurio, J. Chen, and X. Ma, “A mixed-methods approach to understanding user trust after voice assistant failures,” inProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–16
2023
-
[13]
Patient engagement with conversational agents in health applications 2016–2022: a systematic review and meta-analysis,
K. E. Cevasco, R. E. Morrison Brown, R. Woldeselassie, and S. Kaplan, “Patient engagement with conversational agents in health applications 2016–2022: a systematic review and meta-analysis,”Journal of medical systems, vol. 48, no. 1, p. 40, 2024
2016
-
[14]
Empathic conversational agent platform designs and their evaluation in the context of mental health: systematic review,
R. Sanjeewa, R. Iyer, P. Apputhurai, N. Wickramasinghe, and D. Meyer, “Empathic conversational agent platform designs and their evaluation in the context of mental health: systematic review,”JMIR Mental Health, vol. 11, p. e58974, 2024
2024
-
[15]
Talking turns: Benchmarking audio foundation models on turn-taking dynamics,
S. Arora, Z. Lu, C.-C. Chiu, R. Pang, and S. Watanabe, “Talking turns: Benchmarking audio foundation models on turn-taking dynamics,”arXiv preprint arXiv:2503.01174, 2025
-
[16]
Turn-taking in conversational systems and human-robot interaction: a review,
G. Skantze, “Turn-taking in conversational systems and human-robot interaction: a review,”Computer Speech & Language, vol. 67, p. 101178, 2021
2021
-
[17]
Turngpt: a transformer-based language model for predicting turn-taking in spoken dialog,
E. Ekstedt and G. Skantze, “Turngpt: a transformer-based language model for predicting turn-taking in spoken dialog,” inFindings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 2981–2990
2020
-
[18]
V oice activity projection: Self-supervised learning of turn-taking events,
——, “V oice activity projection: Self-supervised learning of turn-taking events,” inProc. Interspeech 2022, 2022, pp. 5190–5194
2022
-
[19]
Predicting turn-taking and backchannel in human-machine conversations using linguistic, acoustic, and visual signals,
Y . Lin, Y . Zheng, M. Zeng, and W. Shi, “Predicting turn-taking and backchannel in human-machine conversations using linguistic, acoustic, and visual signals,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 15 310–15 322
2025
-
[20]
Turn-taking and backchannel prediction with acoustic and large language model fusion,
J. Wang, L. Chen, A. Khare, A. Raju, P. Dheram, D. He, M. Wu, A. Stol- cke, and V . Ravichandran, “Turn-taking and backchannel prediction with acoustic and large language model fusion,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 121–12 125
2024
-
[21]
Dualturn: Learning turn-taking from dual-channel generative speech pretraining,
S. Rajaa, “Dualturn: Learning turn-taking from dual-channel generative speech pretraining,”arXiv preprint arXiv:2603.08216, 2026
-
[22]
Q. Wang, Z. Meng, W. Cui, Y . Zhang, P. Wu, B. Wu, I. King, L. Chen, and P. Zhao, “Ntpp: Generative speech language modeling for dual- channel spoken dialogue via next-token-pair prediction,”arXiv preprint arXiv:2506.00975, 2025
-
[23]
From reaction to prediction: Experiments with compu- tational models of turn-taking,
D. Schlangen, “From reaction to prediction: Experiments with compu- tational models of turn-taking,”Proceedings of Interspeech 2006, Panel on Prosody of Dialogue Acts and Turn-Taking, 2006
2006
-
[24]
Data-driven models for timing feedback responses in a map task dialogue system,
R. Meena, G. Skantze, and J. Gustafson, “Data-driven models for timing feedback responses in a map task dialogue system,”Computer Speech & Language, vol. 28, no. 4, pp. 903–922, 2014
2014
-
[25]
Opportunities and obligations to take turns in collaborative multi-party human-robot interaction,
M. Johansson and G. Skantze, “Opportunities and obligations to take turns in collaborative multi-party human-robot interaction,” inProceed- ings of the 16th annual meeting of the special interest group on discourse and dialogue, 2015, pp. 305–314
2015
-
[26]
Towards a general, continuous model of turn-taking in spoken dialogue using lstm recurrent neural networks,
G. Skantze, “Towards a general, continuous model of turn-taking in spoken dialogue using lstm recurrent neural networks,” inProceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, 2017, pp. 220–230
2017
-
[27]
Multi- lingual turn-taking prediction using voice activity projection,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Multi- lingual turn-taking prediction using voice activity projection,” inPro- ceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (lrec-coling 2024), 2024, pp. 11 873–11 883
2024
-
[28]
Prompt-guided turn-taking prediction,
K. Inoue, M. Elmers, Y . Fu, Z. H. Pang, D. Lala, K. Ochi, and T. Kawahara, “Prompt-guided turn-taking prediction,” inProceedings of the 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 2025, pp. 146–151
2025
-
[29]
Real-time and continuous turn-taking prediction using voice activity projection,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Real-time and continuous turn-taking prediction using voice activity projection,” arXiv preprint arXiv:2401.04868, 2024
-
[30]
Visual cues enhance predictive turn-taking for two-party human interaction,
S. O. Russell and N. Harte, “Visual cues enhance predictive turn-taking for two-party human interaction,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 209–221. [Online]. Available: https://aclantholo...
2025
-
[31]
Full-duplex-bench v1. 5: Evaluating overlap handling for full-duplex speech models,
G.-T. Lin, S.-Y . S. Kuan, Q. Wang, J. Lian, T. Li, S. Watanabe, and H.-y. Lee, “Full-duplex-bench v1. 5: Evaluating overlap handling for full-duplex speech models,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 19 447–19 451
2026
-
[32]
Seamless inter- action: Dyadic audiovisual motion modeling and large-scale dataset,
V . Agrawal, A. Akinyemi, K. Alvero, M. Behrooz, J. Buffalini, F. M. Carlucci, J. Chen, J. Chen, Z. Chen, S. Chenget al., “Seamless inter- action: Dyadic audiovisual motion modeling and large-scale dataset,” arXiv preprint arXiv:2506.22554, 2025
-
[33]
Krippendorff,Content analysis: An introduction to its methodology
K. Krippendorff,Content analysis: An introduction to its methodology. Sage publications, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.