MapDreamer: Aerial Imagery Conditioned Latent Diffusion for Lane-Level Map Generation
Pith reviewed 2026-07-03 21:06 UTC · model grok-4.3
The pith
A diffusion model generates lane-level vector maps with explicit topology directly from aerial images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
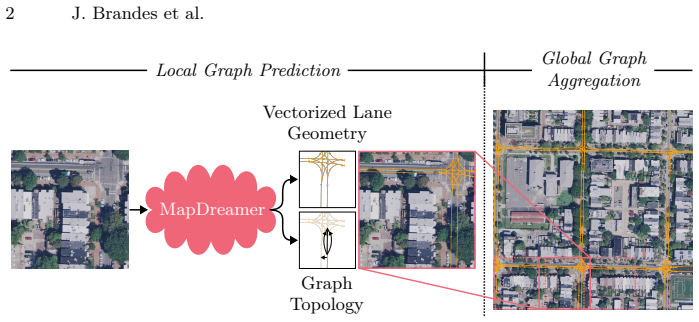
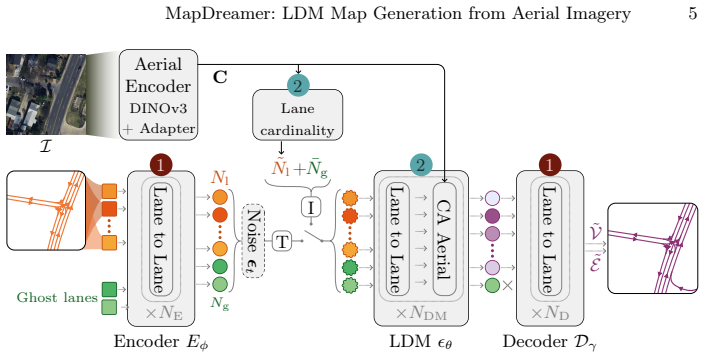
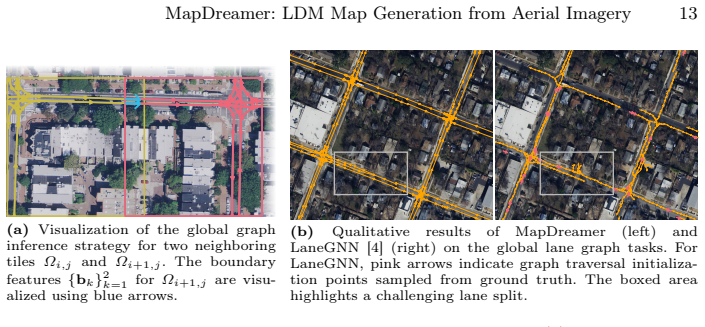
MapDreamer is a generative diffusion model that synthesizes lane-level vector maps with explicit topology directly from a single aerial image. It learns a compact latent representation of lane centerlines and their topological relations using a variational autoencoder and predicts graphs with a transformer-based latent diffusion model. Dense aerial features are injected through cross-attention at every denoising step. A lane cardinality module paired with background ghost lane latents handles varying lane counts without slot collapse. A sliding-window global graph aggregation strategy stitches local tiles into city-scale maps while preserving connectivity.
What carries the argument
The transformer-based latent diffusion model that predicts graphs from a VAE latent space, conditioned at each step by cross-attention on dense aerial image features, together with the lane cardinality module and ghost lane latents that stabilize variable lane counts.
If this is right
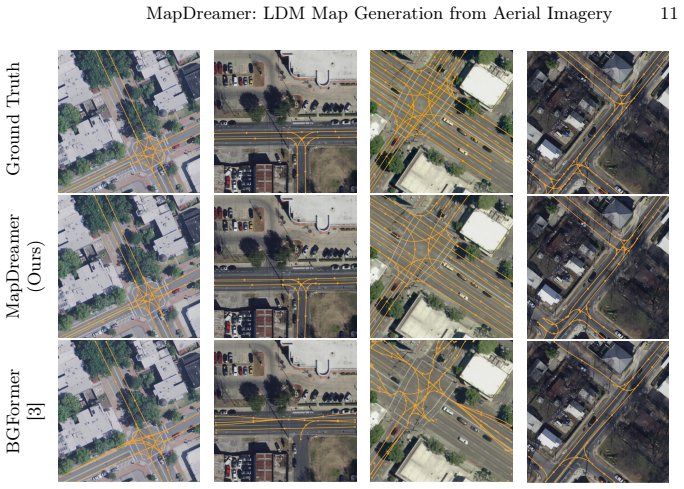
- The generated maps exhibit higher geometric accuracy and better preservation of lane connections than non-generative baselines on the UrbanLaneGraph dataset.
- Local predictions can be combined into city-scale maps while keeping lane boundaries connected through the encoded topology.
- The approach directly produces vector graphs ready for autonomous driving without post-processing into raster formats.
- The model handles scenes with different numbers of lanes by using the cardinality module and ghost latents during diffusion.
Where Pith is reading between the lines
- The same conditioning and cardinality mechanism could be tested on other overhead imagery sources such as satellite photos to check whether the alignment still holds at lower resolution.
- If the ghost lane latents prove stable, the architecture might extend to generating additional map elements such as traffic signs or crosswalks within the same graph.
- City-scale stitching success suggests the method could support incremental map updates when new aerial images arrive for only part of a road network.
Load-bearing premise
Dense aerial image features can be injected via cross-attention during denoising to keep the generated map aligned with the scene, and the cardinality module plus ghost lanes reliably stop the model from collapsing slots when lane numbers vary.
What would settle it
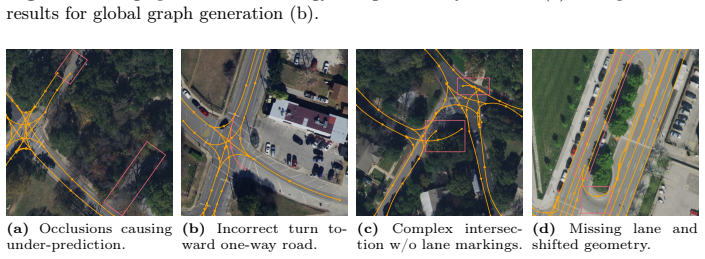
An aerial image containing a clear change in lane count or a visible intersection where the generated map shows the wrong number of lanes or broken connectivity that does not match the image.
Figures
read the original abstract
High definition map generation is essential for autonomous driving, yet remains a labor-intensive process at scale. We present MapDreamer, a generative diffusion model that synthesizes lane-level vector maps with explicit topology directly from a single aerial image. MapDreamer learns a compact latent representation of lane centerlines and their topological relations using a variational autoencoder and predicts graphs with a transformer-based latent diffusion model. To align generated maps with the observed scene, we condition each denoising step on dense aerial features injected through cross-attention. To handle the varying number of lanes across scenes, we propose a lane cardinality module paired with background ghost lane latents, a learned buffer that prevents slot collapse during diffusion. Furthermore, we introduce a sliding-window global graph aggregation strategy that stitches local tiles into city-scale maps while preserving connectivity through encoded lane boundaries. Experiments on UrbanLaneGraph derived from Argoverse 2 show improved geometric and topological fidelity over non-generative baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MapDreamer, a generative diffusion model that synthesizes lane-level vector maps with explicit topology directly from a single aerial image. It learns a compact latent representation of lane centerlines and topological relations via a variational autoencoder, predicts graphs using a transformer-based latent diffusion model, conditions each denoising step on dense aerial features through cross-attention, employs a lane cardinality module with background ghost lane latents to handle varying lane counts, and uses a sliding-window global graph aggregation strategy to stitch local tiles into city-scale maps while preserving connectivity. Experiments on UrbanLaneGraph derived from Argoverse 2 demonstrate improved geometric and topological fidelity over non-generative baselines.
Significance. If the empirical improvements hold under full scrutiny, the work could meaningfully advance automated HD map generation for autonomous driving by providing a generative, topology-aware alternative to deterministic methods. The cross-attention conditioning, ghost-lane cardinality mechanism, and sliding-window aggregation address practical challenges of scene alignment, variable cardinality, and scalability; these components represent targeted innovations in applying latent diffusion to structured graph outputs.
major comments (1)
- Abstract (conditioning and cardinality paragraph): the central claim that cross-attention on dense aerial features plus the lane cardinality module with ghost lane latents reliably prevents slot collapse and produces accurate topology for varying lane counts is load-bearing for the headline result, yet the abstract provides no implementation details, loss terms, or ablation evidence for this mechanism; without those, the support for the fidelity improvement cannot be evaluated.
minor comments (1)
- Abstract: the statement of 'improved geometric and topological fidelity' does not name the specific metrics (e.g., Chamfer distance, topology F1, connectivity error) or list the non-generative baselines, which would be needed to interpret the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the positive assessment of the work's potential impact. We address the single major comment below.
read point-by-point responses
-
Referee: [—] Abstract (conditioning and cardinality paragraph): the central claim that cross-attention on dense aerial features plus the lane cardinality module with ghost lane latents reliably prevents slot collapse and produces accurate topology for varying lane counts is load-bearing for the headline result, yet the abstract provides no implementation details, loss terms, or ablation evidence for this mechanism; without those, the support for the fidelity improvement cannot be evaluated.
Authors: Abstracts are high-level summaries and conventionally omit implementation details, equations, and ablation results; these elements appear in the main manuscript. Section 3.2 describes the cross-attention conditioning on dense aerial features within the transformer diffusion backbone. Section 3.3 details the lane cardinality module, including the role of background ghost lane latents as a learned buffer to avoid slot collapse under variable cardinality. The relevant loss terms are given in Equations (3) (VAE) and (5) (diffusion). Ablations quantifying the contribution of both mechanisms to geometric and topological metrics are reported in Section 4.3 and Table 4. The headline fidelity improvements are therefore supported by the full experimental section rather than the abstract alone. We do not believe the abstract requires expansion with these specifics. revision: no
Circularity Check
No significant circularity; standard generative pipeline with empirical claims
full rationale
The paper describes a latent diffusion model (VAE + transformer diffusion + cross-attention + cardinality module) trained end-to-end on UrbanLaneGraph data. No derivation chain reduces a claimed prediction or first-principles result to its own fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no parameter is fitted on a subset then renamed as a prediction. The central claims are empirical improvements in geometric/topological fidelity, which are externally falsifiable on held-out data and do not rely on self-referential definitions. This is the expected outcome for a standard ML architecture paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent dimension size
- ghost lane buffer size
axioms (1)
- domain assumption Aerial imagery contains sufficient visual information to determine lane topology and geometry
invented entities (1)
-
background ghost lane latents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bastani,F.,He, S.,Abbar, S.,Alizadeh, M.,Balakrishnan, H.,Chawla,S., Madden, S., DeWitt, D.: RoadTracer: Automatic extraction of road networks from aerial images. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 4720–4728 (2018).https://doi.org/10.1109/CVPR.2018.00496
-
[2]
Biagioni, J., Eriksson, J.: Inferring road maps from global positioning system traces: Survey and comparative evaluation. Transportation Research Record: Jour- nal of the Transportation Research Board2291(1), 61–71 (2012).https://doi. org/10.3141/2291-08
-
[3]
Blayney, H., Tian, H., Scott, H., Goldbeck, N., Stetson, C., Angeloudis, P.: Bézier everywhere all at once: Learning drivable lanes as bézier graphs. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 15365–15374 (2024).https://doi. org/10.1109/CVPR52733.2024.01455
-
[4]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Büchner, M., Zürn, J., Todoran, I.G., Valada, A., Burgard, W.: Learning and aggregating lane graphs for urban automated driving. In: IEEE Conf. Comput. Vis.PatternRecog.(CVPR).pp.13415–13424(2023).https://doi.org/10.1109/ CVPR52729.2023.01289
-
[5]
Cheng, G., Wang, Y., Xu, S., Wang, H., Xiang, S., Pan, C.: Automatic road detec- tion and centerline extraction via cascaded end-to-end convolutional neural net- work. IEEE Transactions on Geoscience and Remote Sensing55(6), 3322–3337 (2017).https://doi.org/10.1109/TGRS.2017.2669341
-
[6]
Choi, S., Kim, J., Shin, H., Choi, J.W.: Mask2Map: Vectorized HD map con- struction using bird’s eye view segmentation masks. In: Eur. Conf. Comput. Vis. (ECCV). pp. 19–36 (2024).https://doi.org/10.1007/978-3-031-72890-7_2
-
[7]
Gao, W., Fu, J., Shen, Y., Jing, H., Chen, S., Zheng, N.: Complementing onboard sensors with satellite maps: A new perspective for HD map construction. In: IEEE Int. Conf. Robot. Autom. (ICRA). pp. 11103–11109 (2024).https://doi.org/10. 1109/ICRA57147.2024.10611611
-
[8]
ISPRS International Journal of Geo-Information13(6) (2024).https://doi.org/10.3390/ijgi13060203
Gu, X., Zhang, M., Lyu, J., Ge, Q.: Generating urban road networks with con- ditional diffusion models. ISPRS International Journal of Geo-Information13(6) (2024).https://doi.org/10.3390/ijgi13060203
-
[9]
He, S., Balakrishnan, H.: Lane-level street map extraction from aerial imagery. In: IEEE Winter Conf. Appl. Comput. Vis. (WACV). pp. 1496–1505 (2022).https: //doi.org/10.1109/WACV51458.2022.00156
-
[10]
He,S.,Bastani,F.,Jagwani,S.,Alizadeh,M.,Balakrishnan,H.,Chawla,S.,Elshrif, M.M., Madden, S., Sadeghi, M.A.: Sat2Graph: Road graph extraction through graph-tensor encoding. In: Eur. Conf. Comput. Vis. (ECCV). pp. 51–67 (2020). https://doi.org/10.1007/978-3-030-58586-0_4
-
[11]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Adv. Neural Inform. Process. Syst. (NeurIPS). vol. 33, pp. 6840–6851 (2020)
2020
-
[12]
In: 2022 International Conference on Robotics and Automation (ICRA)
Li, Q., Wang, Y., Wang, Y., Zhao, H.: HDMapNet: An online HD map construction and evaluation framework. In: IEEE Int. Conf. Robot. Autom. (ICRA). pp. 4628– 4634 (2022).https://doi.org/10.1109/ICRA46639.2022.9812383
- [13]
-
[14]
Liao, B., Chen, S., Zhang, Y., Jiang, B., Zhang, Q., Liu, W., Huang, C., Wang, X.: MapTRv2: An end-to-end framework for online vectorized HD map construction. Int. J. Comput. Vis. (IJCV) (2024).https://doi.org/10.1007/s11263- 024- 02235-z MapDreamer: LDM Map Generation from Aerial Imagery 17
-
[15]
Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: VectorMapNet: End-to-end vectorized HD map learning. In: Int. Conf. Mach. Learn. (ICML) (2023)
2023
-
[16]
Monninger, T., Zhang, Z., Mo, Z., Anwar, M.Z., Staab, S., Ding, S.: MapDiffu- sion: Generative diffusion for vectorized online HD map construction and uncer- tainty estimation in autonomous driving. In: IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS). pp. 4099–4106 (2025).https://doi.org/10.1109/IROS60139.2025. 11247744
-
[17]
Máttyus, G., Luo, W., Urtasun, R.: DeepRoadMapper: Extracting road topology from aerial images. In: Int. Conf. Comput. Vis. (ICCV). pp. 3458–3466 (2017). https://doi.org/10.1109/ICCV.2017.372
- [18]
-
[19]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 10674–10685 (2022).https://doi.org/10.1109/CVPR52688. 2022.01042
-
[20]
Rowe, L., Girgis, R., Gosselin, A., Paull, L., Pal, C., Heide, F.: Scenario Dreamer: Vectorized latent diffusion for generating driving simulation environments. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 17207–17218 (2025). https://doi.org/10.1109/CVPR52734.2025.01604
-
[21]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3 (2025),https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: Int. Conf. Learn. Represent. (ICLR) (2021)
2021
-
[23]
Tan, Y.Q., Gao, S.H., Li, X.Y., Cheng, M.M., Ren, B.: VecRoad: Point-based iterative graph exploration for road graphs extraction. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 8907–8915 (2020).https://doi.org/10.1109/ CVPR42600.2020.00893
-
[24]
Umeyama, S.: Least-squares estimation of transformation parameters between two point patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 13(4), 376–380 (1991).https://doi.org/10.1109/34.88573
- [25]
-
[26]
In: Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks) (2021)
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., Ramanan, D., Carr, P., Hays, J.: Argo- verse 2: Next generation datasets for self-driving perception and forecasting. In: Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Be...
2021
-
[27]
Xu, Z., Liu, Y., Gan, L., Sun, Y., Wu, X., Liu, M., Wang, L.: RNGDet: Road network graph detection by transformer in aerial images. IEEE Transactions on Geoscience and Remote Sensing60, 1–12 (2022).https://doi.org/10.1109/ TGRS.2022.3186993
-
[28]
Xu, Z., Liu, Y., Sun, Y., Liu, M., Wang, L.: RNGDet++: Road network graph detection by transformer with instance segmentation and multi-scale features 18 J. Brandes et al. enhancement. IEEE Robotics and Automation Letters8(5), 2991–2998 (2023). https://doi.org/10.1109/LRA.2023.3264723
-
[29]
Ye, J., Paz, D., Zhang, H., Guo, Y., Huang, X., Christensen, H.I., Wang, Y., Ren, L.: SMART: Advancing scalable map priors for driving topology reasoning. In: IEEE Int. Conf. Robot. Autom. (ICRA). pp. 3298–3304 (2025).https://doi. org/10.1109/ICRA55743.2025.11127994
-
[30]
Yin, P., Li, K., Cao, X., Yao, J., Liu, L., Bai, X., Zhou, F., Meng, D.: Towards satellite image road graph extraction: A global-scale dataset and a novel method. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 1527–1537 (2025). https://doi.org/10.1109/CVPR52734.2025.00150
-
[31]
Yuan, T., Liu, Y., Wang, Y., Wang, Y., Zhao, H.: StreamMapNet: Streaming map- ping network for vectorized online HD map construction. In: IEEE Winter Conf. Appl. Comput. Vis. (WACV). pp. 7341–7350 (2024).https://doi.org/10.1109/ WACV57701.2024.00719 MapDreamer: LDM Map Generation from Aerial Imagery 19 Supplementary Material In the supplementary material ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.