EPnG: Adaptive Expert Prune-and-Grow for Parameter-Efficient MoE Fine-tuning
Pith reviewed 2026-07-03 17:23 UTC · model grok-4.3
The pith
EPnG reallocates a fixed LoRA budget in MoE models by pruning under-used experts and expanding important ones to match full fine-tuning results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
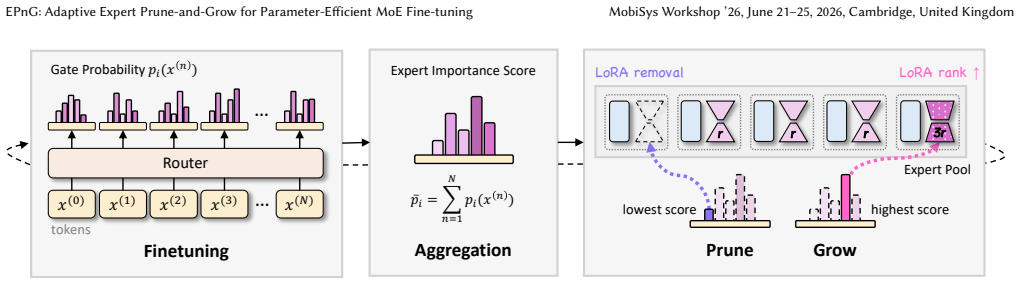
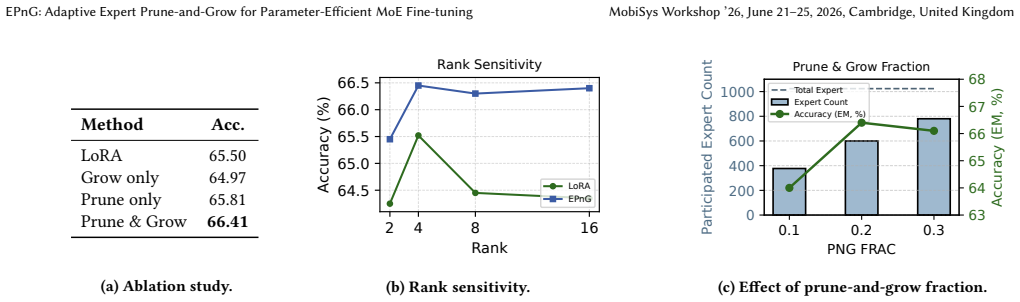
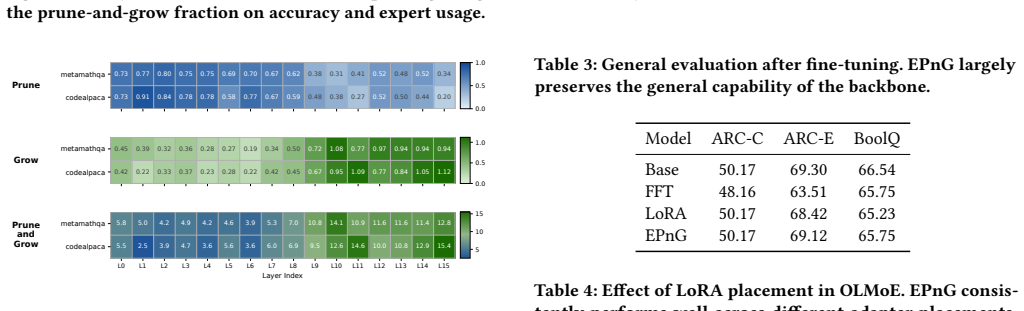
EPnG reallocates LoRA capacity across experts according to router gate probabilities, pruning under-utilized experts and expanding high-importance experts via rank growth with orthogonal initialization while holding the total parameter budget fixed, producing results comparable to full fine-tuning on OLMoE and Qwen1.5-MoE with only 0.55%-0.72% of parameters updated.
What carries the argument
The prune-and-grow allocation rule that measures expert importance from router gate probabilities and shifts LoRA rank accordingly to keep the updated parameter count constant.
If this is right
- EPnG outperforms LoRA at identical parameter budgets on the tested MoE models.
- The method reaches performance levels comparable to full-parameter fine-tuning while updating 140x to 180x fewer weights.
- The same prune-and-grow logic works across different MoE architectures such as OLMoE and Qwen1.5-MoE.
- Aligning the allocation of PEFT capacity with existing routing dynamics improves efficiency over methods that ignore router behavior.
Where Pith is reading between the lines
- The same importance signal could be used to guide other forms of capacity reallocation beyond LoRA ranks.
- If gate probabilities prove reliable, similar prune-and-grow logic might apply to non-MoE sparse models that have internal routing or activation patterns.
- Orthogonal initialization during rank growth may allow the method to start from smaller initial budgets and scale up without retraining from scratch.
Load-bearing premise
Router gate probabilities give a stable enough signal of which experts matter most for the current task that pruning and growing based on them does not reduce overall model capability.
What would settle it
A controlled comparison on the same tasks and models where LoRA ranks are allocated uniformly or randomly instead of by gate probability, and the gate-based version shows no advantage or lower final accuracy.
Figures


read the original abstract
Mixture-of-Experts (MoE) models scale efficiently but remain costly to adapt due to redundant experts and uniform parameter allocation. Existing parameter-efficient fine-tuning (PEFT) methods such as LoRA ignore MoE routing dynamics, leading to suboptimal resource use. We propose EPnG, an adaptive prune-and-grow framework that reallocates LoRA capacity based on expert importance derived from router gate probabilities. EPnG prunes under-utilized experts and expands high-importance experts via rank growth with orthogonal initialization, while maintaining a fixed parameter budget. Across OLMoE and Qwen1.5-MoE, EPnG consistently outperforms LoRA under the same budget and achieves performance comparable to full fine-tuning while updating only 0.55%-0.72% of parameters (up to 140x-180x fewer). These results demonstrate that aligning PEFT with MoE routing yields a more effective and scalable fine-tuning strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EPnG, a prune-and-grow framework for parameter-efficient fine-tuning of MoE models. It derives expert importance from average router gate probabilities over a calibration set, prunes LoRA adapters on low-importance experts to free budget, and expands high-importance experts via rank growth initialized orthogonally, while enforcing a fixed total parameter count. Experiments on OLMoE and Qwen1.5-MoE reportedly show consistent gains over LoRA at the same budget and performance comparable to full fine-tuning while updating only 0.55-0.72% of parameters (140-180x reduction).
Significance. If the empirical claims hold under rigorous validation, the work would be significant for scalable adaptation of large MoE models: it demonstrates that routing-aware reallocation of a fixed PEFT budget can outperform standard LoRA and approach full fine-tuning, with potential for broader application in resource-constrained settings.
major comments (3)
- [Method (pruning/growth criterion)] The central methodological claim (router gate probabilities as a stable, sufficient statistic for expert utility) is load-bearing for both pruning and growth decisions, yet the manuscript provides no correlation analysis, ablation on tail-case experts, or comparison against loss-based importance metrics to substantiate that low-probability experts can be safely removed without capability loss.
- [Experiments / Abstract] The abstract asserts performance comparable to full fine-tuning and consistent outperformance of LoRA, but supplies no experimental setup details, number of runs, statistical tests, error bars, or task-specific baselines; this absence prevents verification of the reported gains and is load-bearing for the main empirical claim.
- [Method (rank growth)] The orthogonal initialization for rank growth is presented without derivation or ablation showing that the added directions remain non-interfering under the specific LoRA update rule; if interference occurs, the fixed-budget reallocation could silently degrade rather than improve performance.
minor comments (2)
- [Method] Notation for the fixed parameter budget and the exact mapping from gate probabilities to prune/grow decisions should be formalized with equations for reproducibility.
- [Method] The calibration set size, sampling strategy, and averaging window for gate probabilities are not specified; these details are needed to assess stability of the importance scores.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Method (pruning/growth criterion)] The central methodological claim (router gate probabilities as a stable, sufficient statistic for expert utility) is load-bearing for both pruning and growth decisions, yet the manuscript provides no correlation analysis, ablation on tail-case experts, or comparison against loss-based importance metrics to substantiate that low-probability experts can be safely removed without capability loss.
Authors: We agree that further validation of the pruning criterion would strengthen the paper. While router gate probabilities are a standard proxy for expert utilization in the MoE literature because they directly encode the model's routing decisions, we will add a correlation analysis between gate probabilities and per-expert loss contribution, an ablation on tail-case experts, and a comparison against a loss-based importance metric in the revised manuscript. revision: yes
-
Referee: [Experiments / Abstract] The abstract asserts performance comparable to full fine-tuning and consistent outperformance of LoRA, but supplies no experimental setup details, number of runs, statistical tests, error bars, or task-specific baselines; this absence prevents verification of the reported gains and is load-bearing for the main empirical claim.
Authors: Detailed experimental protocols, including the number of runs, statistical tests, error bars, and task-specific baselines, appear in Section 4. The abstract is space-constrained and therefore high-level. We will revise the abstract to note that results are averaged over multiple runs with error bars and will ensure all figures and tables in the revised manuscript explicitly report these quantities. revision: partial
-
Referee: [Method (rank growth)] The orthogonal initialization for rank growth is presented without derivation or ablation showing that the added directions remain non-interfering under the specific LoRA update rule; if interference occurs, the fixed-budget reallocation could silently degrade rather than improve performance.
Authors: Orthogonal initialization is chosen so that newly added rank-1 updates lie in directions orthogonal to the existing LoRA subspace. We will include a short derivation based on the orthogonality property of the update matrices and add an ablation comparing orthogonal versus random initialization under the fixed-budget constraint in the revised manuscript. revision: yes
Circularity Check
No circularity detected in method proposal
full rationale
The paper introduces EPnG as an empirical algorithm that reallocates LoRA ranks using pre-existing router gate probabilities from the base MoE model. No derivation chain, first-principles prediction, or fitted parameter is presented as an independent result; the approach is a heuristic reallocation rule whose performance is evaluated externally on downstream tasks. No self-citations are load-bearing for any uniqueness claim, and no quantity is redefined in terms of itself. The central claims rest on experimental comparisons rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, et al
-
[2]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, et al. 2022. Deepspeed-inference: enabling efficient inference of transformer mod- els at unprecedented scale. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysi...
2022
-
[4]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. 2021. Evaluating Large Lan- guage Models Trained on Code. arXiv:2107.03374 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, et al. 2022. On the repre- sentation collapse of sparse mixture of experts.Advances in Neural Information Processing Systems35 (2022), 34600–34613
2022
-
[7]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res.23, 1, Article 120 (Jan. 2022), 39 pages
2022
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and et al. Yang. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. InProceedings of the IEEE international conference on computer vision. 1026–1034
2015
-
[11]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
- [13]
-
[14]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. {GS}hard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InInternational Conference on Learning Representations
2021
-
[15]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
- [19]
- [20]
-
[21]
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Evan Pete Walsh, et al. 2025. OLMoE: Open Mixture-of- Experts Language Models. InInternational Conference on Learning Representations (ICLR)
2025
-
[22]
Qwen. 2024. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters. https://qwenlm.github.io/blog/qwen-moe/. Accessed: 2025-09-23
2024
-
[23]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed- MoE: Advancing Mixture-of-Experts Inference and Training to Power Next- Generation AI Scale.CoRRabs/2201.05596 (2022). arXiv:2201.05596
-
[24]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, and Yu Wu. 2024. Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architec- tural Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Comp...
-
[26]
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin
-
[29]
Do llms recognize your preferences? evaluating personalized preference following in llms.International Conference on Learning Representations (ICLR) (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.