PARTREP: Learning What to Repeat for Decoder-only LLMs
Pith reviewed 2026-07-03 15:12 UTC · model grok-4.3
The pith
Selective repetition of high-NLL tokens retains most gains from full prompt repetition while using 59 percent of the KV cache.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
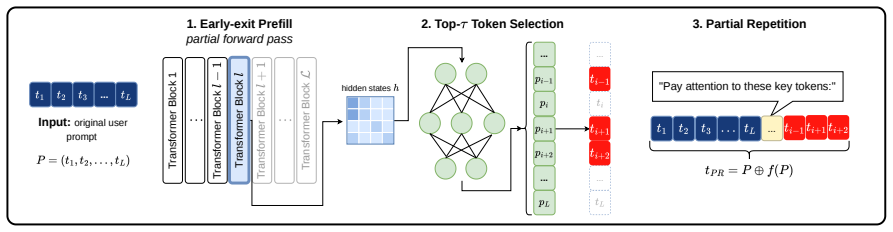
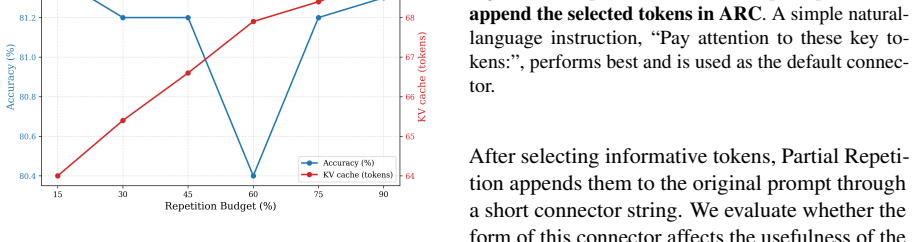
PartRep appends only the tokens with highest token-wise negative log-likelihood to the prompt, where those tokens are chosen by a lightweight gate trained to predict them from early-layer hidden states via early exit. This selective repetition preserves most of the performance improvement of full prompt repetition across eight benchmarks and three model families while consuming 59.4 percent of the KV cache and 79.0 percent of the prefill FLOPs.
What carries the argument
A lightweight gate that predicts high negative log-likelihood tokens from early-layer hidden states to enable mid-prefill selection of tokens for repetition.
If this is right
- Longer prompts become feasible because the added length is only a fraction of the original prompt rather than a full duplicate.
- The same early-exit gate can be reused across different model sizes and families without retraining the base LLM.
- Reasoning tasks that currently rely on full repetition, such as multi-step math or long-context retrieval, can run with lower memory overhead.
- Prefill compute drops enough that the technique can be applied at inference time without dedicated hardware changes.
Where Pith is reading between the lines
- The gate's early-layer features might also predict tokens worth caching or compressing in other efficiency methods.
- If the selection criterion generalizes, similar lightweight predictors could decide which tokens to attend to more heavily during generation.
- Testing the method on sequences much longer than the current benchmarks would reveal whether the savings scale linearly.
Load-bearing premise
High negative log-likelihood tokens are exactly the ones that gain the most from appearing again in a later position.
What would settle it
An ablation in which repeating the lowest-NLL tokens instead of the highest-NLL tokens produces equal or larger accuracy gains on the same benchmarks would show the selection signal does not work.
Figures


read the original abstract
While decoder-only LLMs excel at a vast array of natural language tasks, it suffers from an asymmetric information flow induced by causal attention: later tokens are richer in contextual grounding than earlier ones. A simple and effective remedy is prompt repetition -- just appending a second copy of prompt before generation can redistribute grounding across positions and improve reasoning performance. However, full repetition of the original prompt doubles the KV cache footprint and quadruples attention cost during prefill, making it impractical for long-context settings. We propose PartRep, a selective augmentation method that appends only the most informative tokens -- rather than the entire prompt. We use token-wise negative log-likelihood (NLL) as a selection signal, motivated by the hypothesis that less predictable tokens are less recoverable from surrounding context and therefore benefit more from late-position repetition. To avoid the heavy cost of a full forward pass for scoring, we train a lightweight gate that predicts high-NLL tokens from early-layer hidden states, enabling token selection during mid-prefill via early exit. Across eight benchmarks (including MMLU, GSM8K, and RULER) and three model families (Qwen2.5, Llama3.2, Gemma4), PartRep retains most of the gains of full repetition while using only 59.4\% of its KV cache and 79.0\% of its prefill FLOPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PartRep, a method for selective prompt repetition in decoder-only LLMs to mitigate asymmetric information flow from causal attention. It selects tokens via token-wise negative log-likelihood (NLL) under the hypothesis that high-NLL tokens benefit most from late-position repetition, and uses a lightweight gate trained on early-layer hidden states to enable mid-prefill selection without a full forward pass. Across eight benchmarks (MMLU, GSM8K, RULER and others) and three model families (Qwen2.5, Llama3.2, Gemma4), the method is claimed to retain most performance gains of full repetition while using 59.4% of the KV cache and 79.0% of the prefill FLOPs.
Significance. If the empirical results hold under proper statistical controls, PartRep offers a practical route to improved reasoning performance in long-context settings at substantially lower memory and compute cost than full repetition. The multi-family, multi-benchmark evaluation and the early-exit gate design are concrete strengths that could influence efficient inference techniques.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results sections: the central claim that PartRep 'retains most of the gains' at 59.4% KV cache and 79.0% prefill FLOPs is reported as point estimates with no error bars, standard deviations, or statistical significance tests across runs or datasets. This directly affects the reliability of the efficiency-performance tradeoff that constitutes the paper's primary contribution.
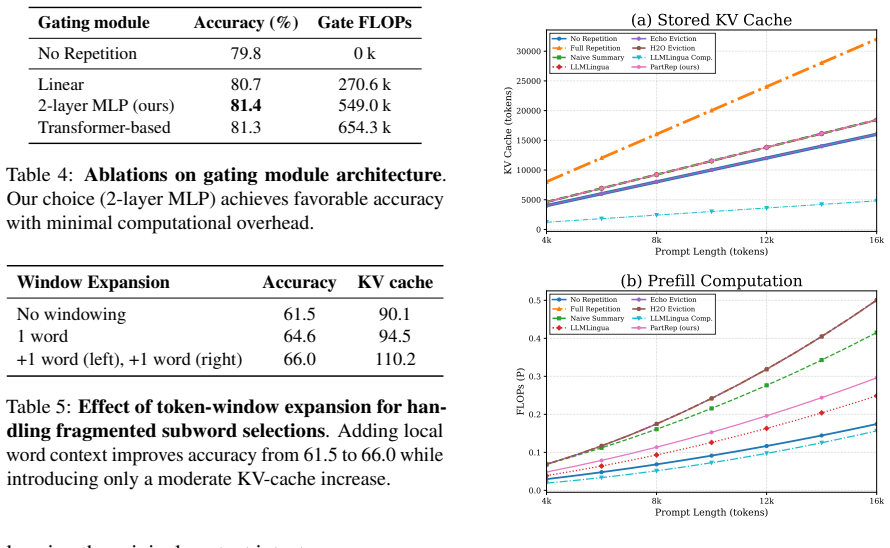
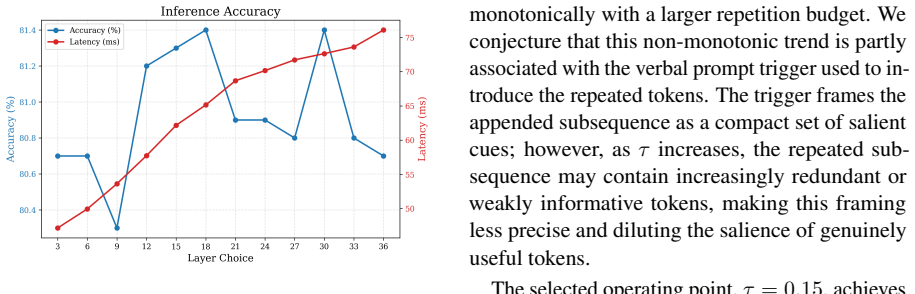
- [Method] Method section describing the NLL-based selection and lightweight gate: while the hypothesis is stated, there is no ablation comparing high-NLL selection against random or low-NLL baselines to isolate whether the NLL signal is load-bearing for the observed gains, or reporting the gate's prediction accuracy/F1 on held-out tokens.
minor comments (3)
- [Abstract and results] Clarify the precise operational definition of 'most of the gains' (e.g., what fraction of the full-repetition delta is considered sufficient) and report per-benchmark retention percentages rather than aggregate statements.
- [Experimental setup] Provide dataset sizes, number of evaluation examples per benchmark, and exact prompt lengths used when measuring KV-cache and FLOPs percentages, as these affect the reported efficiency numbers.
- [Abstract] The abstract lists 'Gemma4'; confirm the exact model variant and cite the corresponding paper or release note.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results sections: the central claim that PartRep 'retains most of the gains' at 59.4% KV cache and 79.0% prefill FLOPs is reported as point estimates with no error bars, standard deviations, or statistical significance tests across runs or datasets. This directly affects the reliability of the efficiency-performance tradeoff that constitutes the paper's primary contribution.
Authors: We agree that reporting variability would strengthen the primary efficiency claim. In the revision we will add standard deviations for all experiments that were run with multiple random seeds (GSM8K, MMLU subsets) and include paired statistical significance tests against the no-repetition baseline. For the remaining benchmarks we will report per-model consistency across the three families as additional robustness evidence. These changes will be reflected in both the abstract and the experimental results section. revision: yes
-
Referee: [Method] Method section describing the NLL-based selection and lightweight gate: while the hypothesis is stated, there is no ablation comparing high-NLL selection against random or low-NLL baselines to isolate whether the NLL signal is load-bearing for the observed gains, or reporting the gate's prediction accuracy/F1 on held-out tokens.
Authors: We will add the requested ablations to the revised Method and Experiments sections. Specifically, we will compare high-NLL selection against (i) random token selection at the same budget and (ii) low-NLL selection, measuring downstream accuracy on the eight benchmarks. We will also report the gate's token-level accuracy and F1 on a held-out validation split of the training data used to train the gate, together with the early-exit layer chosen. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents PartRep as an empirical method: NLL is used as a selection signal for tokens to repeat, a lightweight gate is trained to predict high-NLL tokens from early hidden states, and performance is measured directly on eight benchmarks across three model families. No equations, derivations, or predictions reduce the reported gains (or the cost savings of 59.4% KV cache / 79.0% prefill FLOPs) to quantities defined by the method itself. The motivating hypothesis is stated as a testable design choice rather than a self-referential premise, and results are framed as external measurements rather than outputs forced by fitting or self-citation. The derivation chain is therefore self-contained against the reported empirical evidence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Less predictable tokens (high NLL) benefit more from late-position repetition because they are less recoverable from surrounding context
invented entities (1)
-
lightweight gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lost in the Prompt Order: Revealing the Limitations of Causal Attention in Language Models
Lost in the Prompt Order: Revealing the Limitations of Causal Attention in Language Models , author=. arXiv preprint arXiv:2601.14152 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2024 , eprint=
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders , author=. 2024 , eprint=
2024
-
[4]
arXiv preprint arXiv:2311.12351 , year=
Advancing transformer architecture in long-context large language models: A comprehensive survey , author=. arXiv preprint arXiv:2311.12351 , year=
-
[5]
arXiv preprint arXiv:2402.08939 , year=
Premise order matters in reasoning with large language models , author=. arXiv preprint arXiv:2402.08939 , year=
-
[6]
Prompt Repetition Improves Non-Reasoning LLMs , author=. arXiv preprint arXiv:2512.14982 , year=
-
[7]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Re-reading improves reasoning in large language models , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[8]
arXiv preprint arXiv:2402.15449 , year=
Repetition improves language model embeddings , author=. arXiv preprint arXiv:2402.15449 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
arXiv preprint arXiv:2505.23416 , year=
Kvzip: Query-agnostic kv cache compression with context reconstruction , author=. arXiv preprint arXiv:2505.23416 , year=
-
[11]
arXiv preprint arXiv:2601.17668 , year=
Fast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction , author=. arXiv preprint arXiv:2601.17668 , year=
-
[12]
arXiv preprint arXiv:2601.07891 , year=
KVzap: Fast, Adaptive, and Faithful KV Cache Pruning , author=. arXiv preprint arXiv:2601.07891 , year=
-
[13]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[15]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
Crowdsourcing multiple choice science questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
-
[17]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[18]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
5 technical report , author=
Qwen2. 5 technical report , author=. arXiv preprint , year=
-
[21]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Unified Deployment-Aware Evaluation of Open Reasoning Language Models
Gemma 4, Phi-4, and Qwen3: Accuracy-Efficiency Tradeoffs in Dense and MoE Reasoning Language Models , author=. arXiv preprint arXiv:2604.07035 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in neural information processing systems , volume=
Speakers optimize information density through syntactic reduction , author=. Advances in neural information processing systems , volume=
-
[25]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning , author=. arXiv preprint arXiv:2507.00432 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2505.13811 , year=
Context-free synthetic data mitigates forgetting , author=. arXiv preprint arXiv:2505.13811 , year=
-
[27]
RL's Razor: Why Online Reinforcement Learning Forgets Less
Rl's razor: Why online reinforcement learning forgets less , author=. arXiv preprint arXiv:2509.04259 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2407.05483 , year=
Just read twice: closing the recall gap for recurrent language models , author=. arXiv preprint arXiv:2407.05483 , year=
-
[29]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[30]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Large language models sensitivity to the order of options in multiple-choice questions , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[31]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Unveiling selection biases: Exploring order and token sensitivity in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[32]
arXiv preprint arXiv:2510.05381 , year=
Context length alone hurts LLM performance despite perfect retrieval , author=. arXiv preprint arXiv:2510.05381 , year=
-
[33]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Llmlingua: Compressing prompts for accelerated inference of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[34]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Gemma 4 Model Card , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.